Мы уже писали, как самостоятельно
1. Чистка семантического ядра по словам-маркерам
Открываем Key Collector и с помощью фильтра отсеиваем все неподходящие слова. Например, для категории «серебряные кольца» основными маркерными словами будут «серебряные», «кольца», а также их словоформы. Вписываем только часть слова, чтобы охватить все словоформы.
В первую очередь отберем все запросы без «кол-» в Key Collector.
Для этого переходим на вкладку с выбором условий фильтраций:
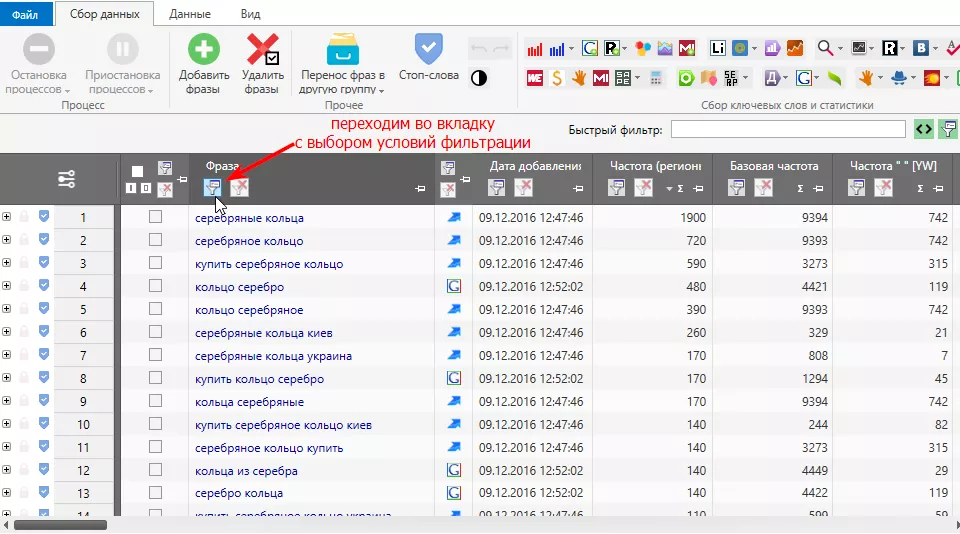
И выбираем соответствующие условия (фраза не содержит «кол-»):
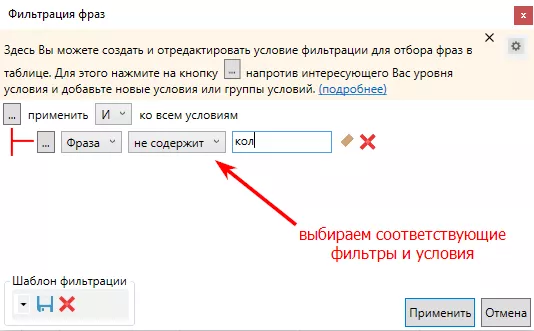
Отмечаем все отфильтрованные фразы и отправляем в «корзину».
Дальше по такому же алгоритму отфильтруем запросы по слову «серебр-».
Чтобы охватить больше фраз с одинаковым значением, в Key Collector существует возможность создавать вложенные фильтры.
Для чего это нужно? Например, возьмем запросы «кулоны» и «подвески». Оба варианта в выдаче будут показывать идентичные результаты.
В данном примере мы выполнили поиск информационных запросов, содержащих слова «кулон» и «подвеска».
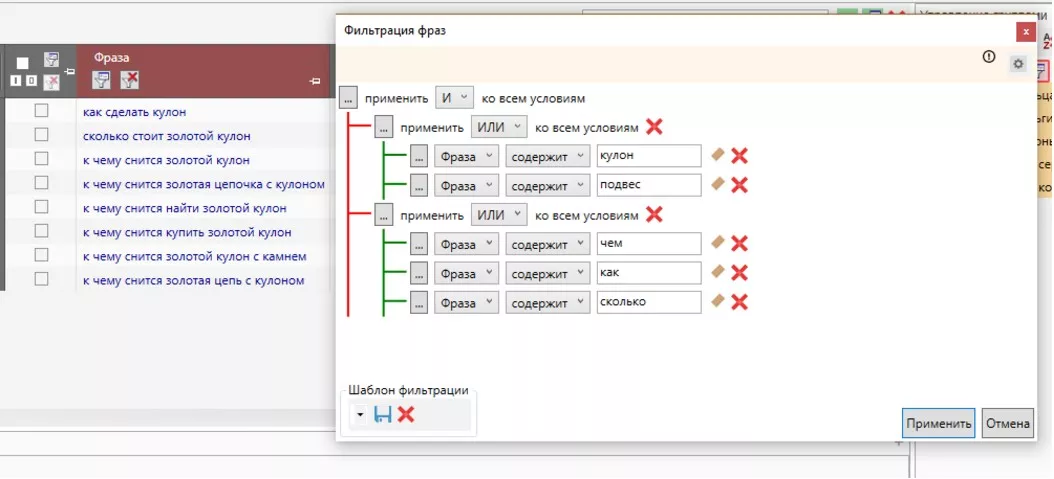
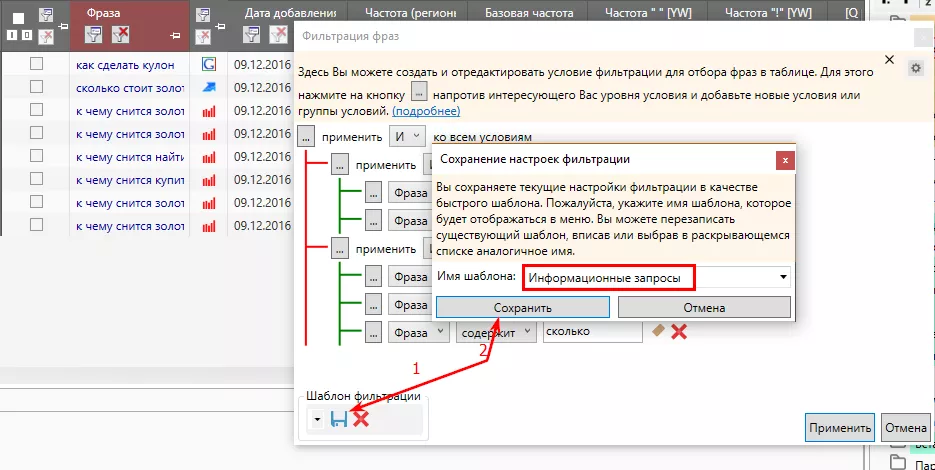
Все созданные фильтры по заданным условиям можно сохранять и использовать в других проектах.
Как это сделать:
2. Удаление повторяющихся слов
Фразы с повторами зачастую мусорные, поэтому имеет смысл удалить их уже на первых этапах чистки семантики. Для этого выбираем расширенный фильтр и настраиваем правило: «Фраза» — «Содержит повторы слов»:

3. Удаление латинских букв, специальных символов, запросов с цифрами
Удалить латинские буквы и спецсимволы можно с помощью:
- расширенного фильтра;
- регулярных выражений.
С помощью расширенного фильтра можно выбрать сразу несколько параметров:
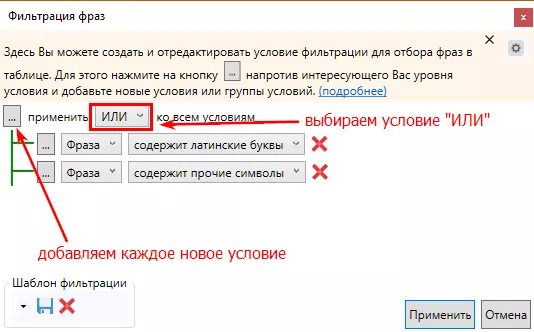
Фильтр по условию «содержит прочие символы» выберет фразы с украинскими символами «і», «ї».
Не забывайте применить правило ИЛИ/И ко всем условиям.
Другой метод — изучить регулярные выражения и очистить семантическое ядро с их помощью.
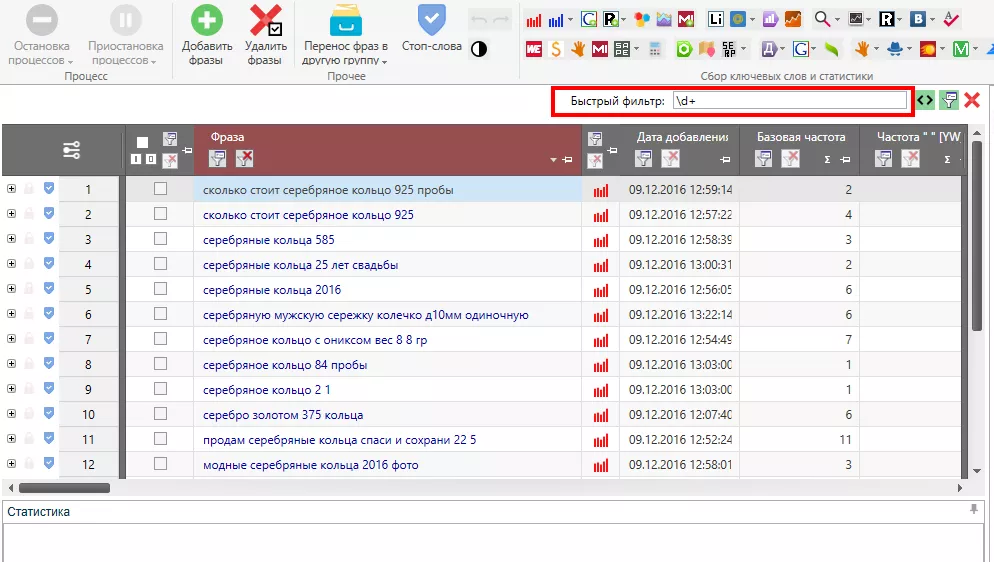
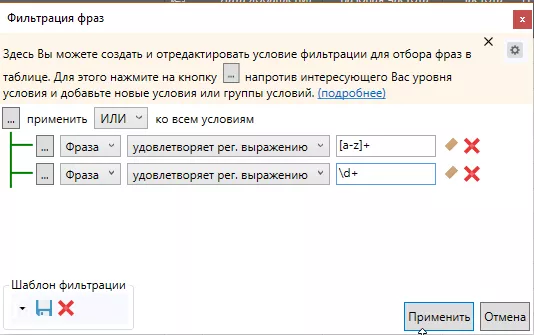
Регулярное выражение \d+ помогает избавиться от цифр.
Например, в случае семантического ядра по серебряным кольцам я оставляла все запросы, содержащие значение пробы металла и веса изделия, но удаляла год выпуска.
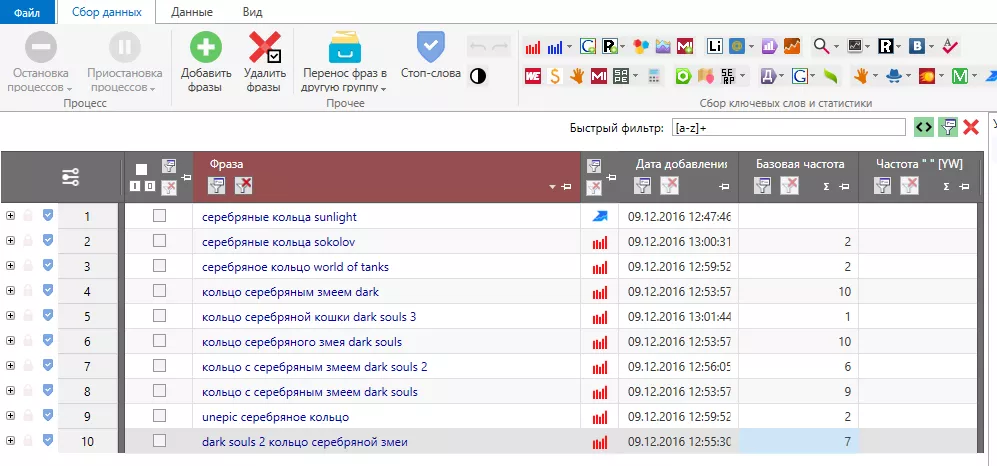
Регулярное выражение [a-z]+ нужно для фильтрации букв латинского алфавита.
Буквы латинского алфавита могут быть в названиях брендов, коллекций или других элементов карточек товаров. Перед удалением таких запросов советую внимательно их просмотреть.
Фильтрацию с помощью регулярных выражений можно проводить и с помощью быстрого фильтра (как на примере выше), и с помощью расширенного фильтра:
{kind=link}
4. Чистка с помощью стоп-слов
Переходим на вкладку «Стоп-слова»:
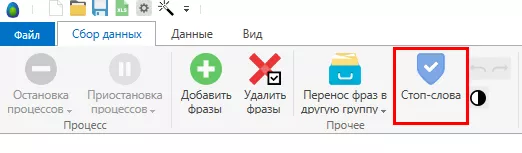
Добавляем слова, которые нам не нужны. Обычно я делю все стоп-слова на несколько групп:
- информационные;
- города (которые не соответствуют маркетинговым целям);
- все, что относится к бесплатным способам получения товара: бесплатно, недорого, дешево, дорого, на/под заказ (не для всех сайтов) и так далее.
- субъективные понятия: самый, лучший, красивый, необычный, прикольный, оригинальный.
- названия сайтов с объявлениями: «пром юа», «олх», «клумба», «бигль юа».
- визуализация: изображения, фото, видео, скачать, смотреть, чертежи, инструкции, схемы.
- очень часто встречаются запросы с приставкой «своими руками», их тоже добавляем в стоп-слова.
Список групп может варьироваться в зависимости от тематики сайта, но приведенные выше примеры работают практически во всех случаях.
Так выглядит чистка с помощью списка стоп-слов в Key Collector:
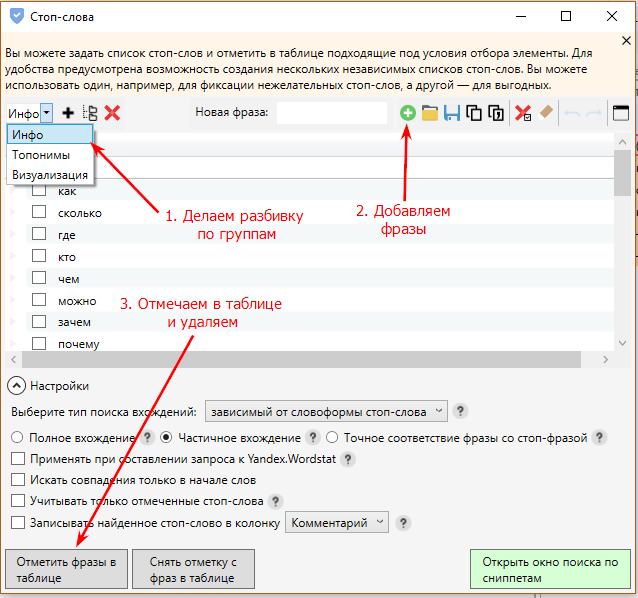
Важно! Информационные запросы с приставками «как», «где», «что» советую не удалять. Лучше перенести их в отдельную папку и в будущем использовать для разработки
Также можно все ненужные слова добавлять непосредственно из полного списка запросов. В таком случае создаем отдельную группу — специально для таких стоп-слов.
Алгоритм действий:
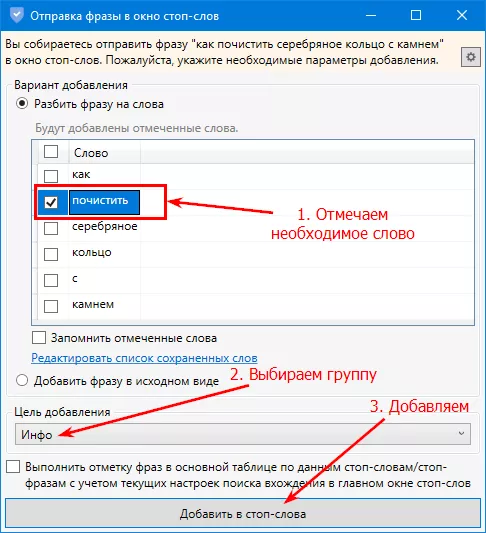
1. Кликаем на значок слева от нерелевантного запроса:

2. В открывшемся окне выбираем, что добавить в список стоп-слов:
5. Чистим ядро с помощью функции анализа группы слов
В KeyCollector переходим на вкладку «Данные» — «Анализ групп».
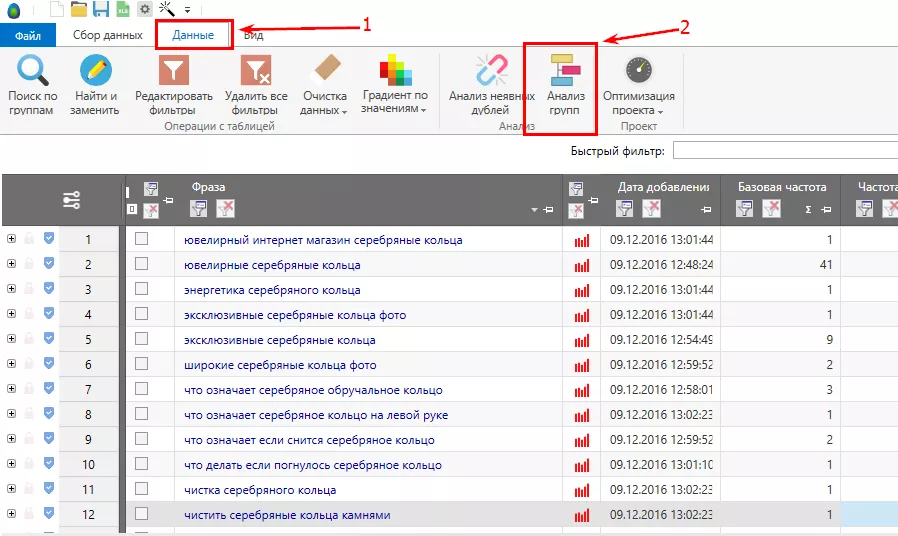
Отмечаем группы со словами, которые не подходят:
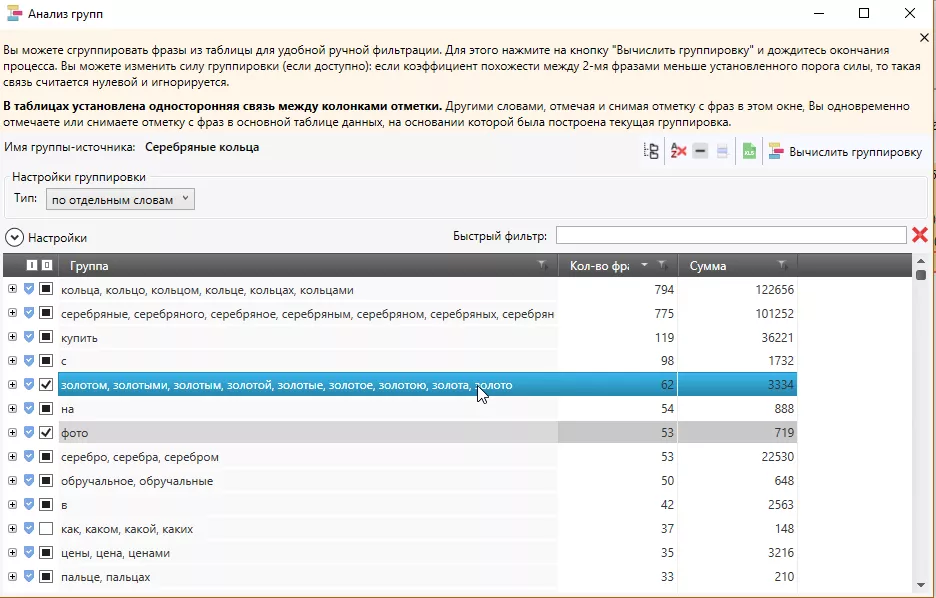
Группы, отмеченные в таблице, автоматически отмечаются в основном списке запросов. После того как были отмечены все неподходящие слова, закрываем таблицу и удаляем все ненужные запросы.
6. Ищем и удаляем неявные дубли
Для использования данного метода необходимо сначала собрать информацию о частотности запросов. После этого переходим на вкладку «Данные» — «Анализ неявных дублей»:

Выделяем необходимые настройки:
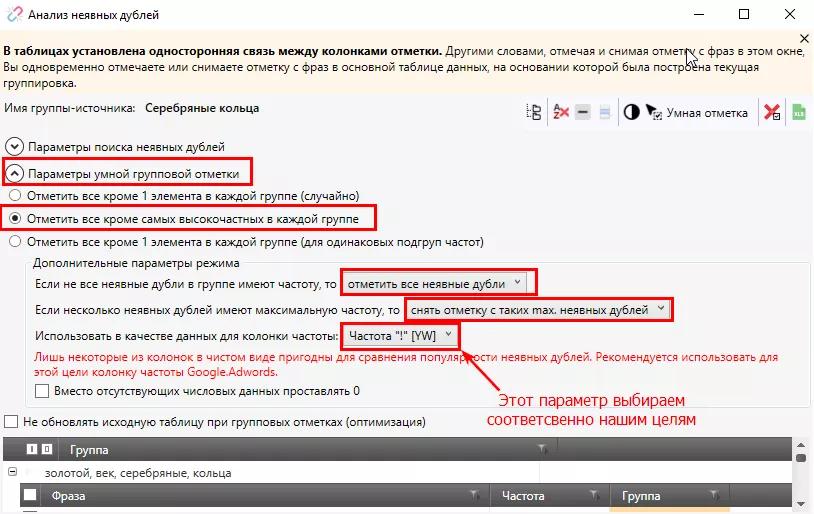
Нажимаем кнопку «Умная отметка»:
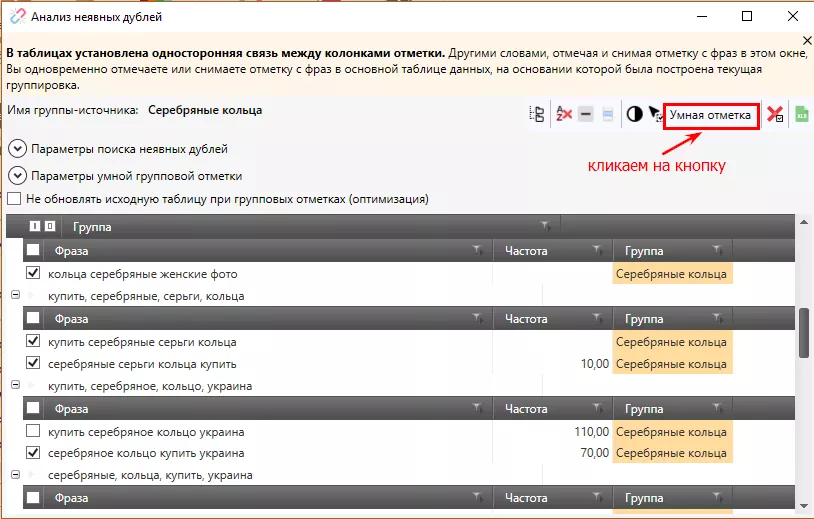
Программа автоматически отметит все неявные дубли, частотность которых меньше в указанной поисковой системе.
7. Ручной поиск по группе запросов
Наконец можно отметить вручную все ненужные слова в семантическом ядре: сленг, слова с ошибками и так далее. Основной массив нерелевантных запросов уже был очищен ранее, так что ручная чистка не займет много времени.
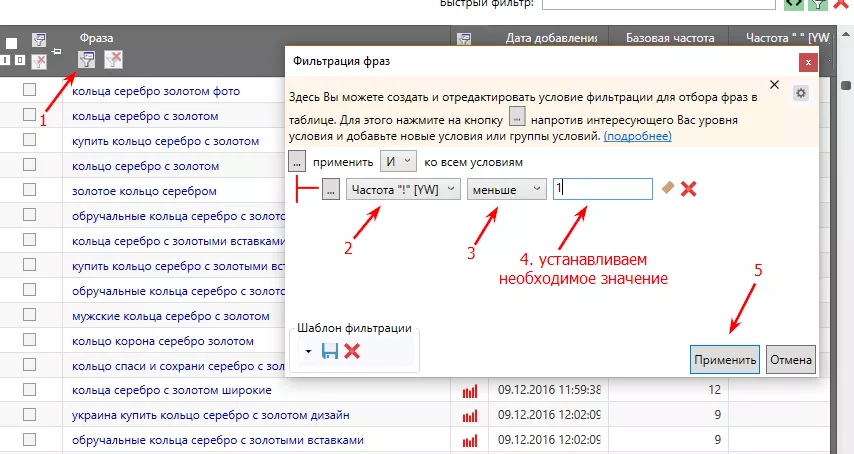
8. Очистка запросов по частотности
С помощью расширенного фильтра в KeyCollector устанавливаем параметры частоты запросов и отмечаем все низкочастотные фразы. Этот этап нужен
Используйте альтернативный инструмент для работы с ключевыми словами — Кластеризацию от Serpstat. Его преимущество в том, что вы загружаете все ваши ключевые фразы, задаете настройки и Кластеризация самостоятельно их группирует и распределяет по страницам сайта. Те слова, которые не подходят ни в один кластер формируют отдельный список. Также вы сами можете редактировать и чистить уже готовые кластеры.
Выводы
Чтобы качественно очистить семантическое ядро от мусора, следует выполнить восемь шагов в KeyCollector:
- Чистка семантического ядра по словам-маркерам.
- Удаление повторяющихся слов.
- Удаление латинских букв, специальных символов, запросов с цифрами.
- Чистка с помощью стоп-слов.
- Очистка ядра с помощью функции анализа группы слов.
- Поиск и удаление неявных дублей.
- Ручной поиск по группе запросов.
- Очистка запросов по частотности.
На каждом этапе желательно просмотреть слова, помеченные для удаления, так как существует риск удалить качественные и релевантные запросы.
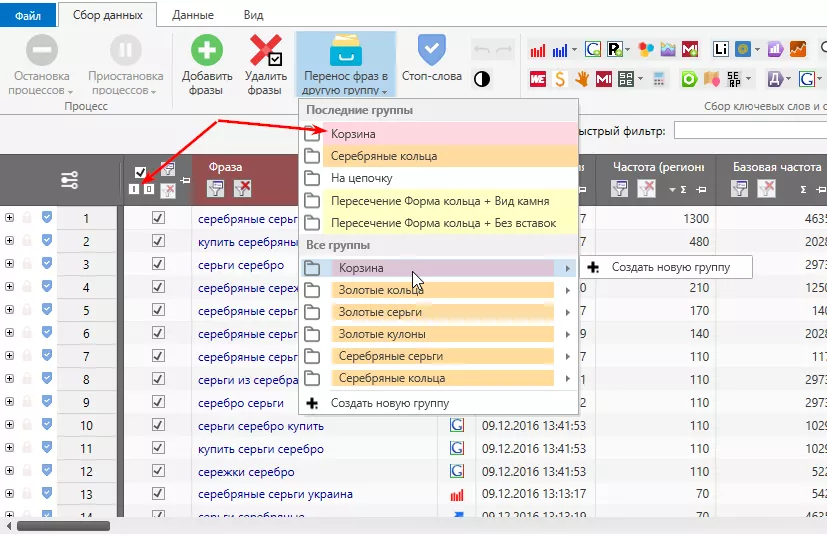
Вместо удаления ненужных запросов лучше создать отдельную группу и переносить их туда. В свежих обновлениях Key Collector появилась соответствующая группа по умолчанию — «Корзина».
После тщательной чистки семантического ядра можно переходить к следующему этапу — кластеризации и группировке запросов.
Отмечу, что всегда существует риск упустить парочку нерелевантных запросов во время чистки ядра. Их как раз очень легко выявить и удалить на этапе группировки, но об этом — в следующий раз.

 110
110
 9
9
 5
5
Свежее
Что такое домен верхнего уровня (TLD)
Вы получите шпаргалку, по которой правильно выберете доменное имя и не допустите коварных ошибок. А также узнаете, где купить ценные и известные TLD
Как настроить специальные параметры в Google Analytics 4: пошаговая инструкция
Когда необходимо получить дополнительные данные стоит настроить специальные параметры и показатели
Чувствуете на себе влияние презентеизма? Исследование редакции Netpeak Journal
Ответьте на несколько вопросов, чтобы внести вклад в исследование этой важной темы.