
Продължаваме с нашите статии от поредицата за Machine Learning API-тата на Google.
Тук можете да си припомните статията ни за
Преди нея пък ви разказахме повече за това как функционира и може да се прилага в обозримо бъдеще
Дойде ред и на анализа на изображения. В статията
Продължавайки сюжетната линия на Google API-тата, последно ви дадохме полезна информация за видео съдържанието, а именно -
В настоящата статия ще разгледаме Google Cloud Speech API и неговите основни характеристики и функционалности.
Съдържание:
1. Какво представлява Google Cloud Speech-to-Text API
2. Основна документация и характеристики
3. Направете вашите сайтове още по-достъпни
4. Разпознаване на реч в контактните центрове
1. Какво представлява Google Cloud Speech-to-Text API
Google Cloud Speech-to-Text ви позволява да конвертирате аудио в текст с помощта на мощни модели на невронни мрежи в API.
API-то на този етап разпознава над 120 езика. Можете да активирате гласово управление и да презаписвате аудио от контакт центрове за обаждания и други. То може да обработва вашата информация поточно или при предварително записано аудио в реално време, като се използват отново технологиите за машинно обучение на Google.
Основни характеристики и възможности:
- Автоматично разпознаване на речта;
- Разпознава над 120 езика (и вариации) с много голям речник;
- Поддръжка в реално време;
- Многоканално разпознаване;
- Работи с шумен звук от много среди.
Можете да изгледате и официалното видео разяснение на Google:
2. Основна документация и характеристики
Приложенията тук отново са много и от най-различно естество. Ще разгледаме основните характеристики:
- Конвертиране на кратки аудио файлове - тук се обработват заявки на кратки аудио файлове (по-малко от 1 минута) и превръщане на речта в текст. Тук трябва да се вземе предвид, че име определени звукови ограничения за тези заявки. Допълнителна информация тук.
- Конвертиране на дълги аудио файлове - тук с помощта на асинхронно разпознаване на речта могат да се конвертират аудио файлове по-дълги от минута. Аудио съдържанието може да се изпраща директно като текст и да се запазва в Google Cloud Storage. Допълнителна информация тук.
- Обработка на аудио в реално време - поточното разпознаване на речта ще ви позволи да получавате резултати от обработката на речта в реално време, докато аудиото се обработва. Малко по-трудно е за имплементация, но е нещо, което със сигурност е доста интересно и ще получи голямо приложение в бъдеще. Допълнителна информация тук.
Тук също се осигурява поддръжка на широк спектър от езици като Go, C#, Java, PHP, Node.js, Python, Ruby.
3. Направете вашите сайтове още по-достъпни
Google Text-to-Speech превръща в текст всяка една дума. Може да използвате API-то и неговите човешки гласове WaveNet.
Text-to-Speech създава сурови аудио данни от естествена човешка реч. Т.е. eдин вид се създава аудио, което звучи като човек, който говори. На разположение е богат избор от персонализирани гласове, които можете да избирате от “Текст в реч”. Гласовете могат да се различават пo език, пол и акцент. Някои езици имат дори и няколко гласа за избор. Можете да видите списък с поддържаните гласове, но на този етап все още няма български език.
Cloud Speech-to-Text също предлага гласове, които се генерират с помощта на модела WaveNet. Това е същата технология, която се използва за създаване на реч за Google Assistant, Google Search и Google Translate. Технологията WaveNet осигурява повече от просто серия синтетични гласове: тя представлява нов начин за създаване на синтетична реч.
WaveNet генерира реч, която звучи по-естествено от другите системи за текст в реч.
Независимо дали сте автор или някоя компания, когато пишете, вашата цел е да създадете стойност за своите потребители и да изградите връзки с аудиторията си. Благодарение на това API можете да създадете различно приложение в зависимост от ситуацията. Можете да правите аудио записи на публикациите във вашия блог. По този начин можете да разпространявате съдържание в множество формати. Прочетете допълнително тук.
4. Разпознаване на реч в контактните центрове
Контактните центрове са от решаващо значение за много предприятия и правилните технологии играят много важна роля, като им помагат да предоставят изключителни грижи за клиентите. Google все повече насърчава предприятията да използват изкуствен интелект в тяхната работа (допълнителна информация тук).
Редица актуализации са в основата на AI и по-специално в Dialogflow и Cloud Speech-to-Text . Те са:
- Автоматично адаптиране на речта в диалогов поток - все още е в бета версия. Това подобрява точността на разпознаване на говора чрез използване на информацията за говорителя и състоянието на разговора като подсказва контекста на речта. Допълнителна информация тук.
- Подобрения в разпознаването на реч - тук се има предвид ефективно изграждане на висококачествени интерактивни инструменти за гласово реагиране (IVR), което всъщност е част от плана на Google да предоставя услугите си на Call центровете. Допълнителна информация тук.
- По-богато адаптиране на речта - когато се използва Cloud Speech-to-Text, се прилагат допълнителни параметри, за да се предоставя повече информация, която да направи транскрипцията по-точна. Това е процес, който може да помогне за разпознаването на фрази, които са най-често употребявани. Допълнителна информация тук.
- Безкраен стрийминг от реч в текст - трябва да се има предвид, че тази функционалност все още е в бета версия. API-то позволява на разработчиците да започват нова сесия за стрийминг веднага след прекъсването на предишната т.е. ефективно да се превръща в автоматична транскрипция на живо с безкрайна дължина. Допълнителна информация тук.
- Поддръжка на MP3 файлове - на този етап се поддържат седем различни файлови формата (списък тук). Cloud Speech-to-Text вече поддържа MP3, така че няма да има нужда от допълнителни преобразувания.
5. Как да активираме Cloud Speech-to-Text API
Преди да започнете да използвате API-то на Cloud Vision, трябва да го активирате за вашия проект в Google Cloud платформата:
1. Изберете вашия проект или създайте нов тук.
2. Добавете валиден метод за таксуване във вашия Google Cloud акаунт. Допълнителна информация тук.
Забележка:
Трябва да се има предвид, че всяко едно от ML API-тата на Google се заплаща в зависимост от това каква информация извличате. Цените са символични, но все благодарение на това тези API-та се развиват.

3. Активирайте API на Speech-to-Text тук.
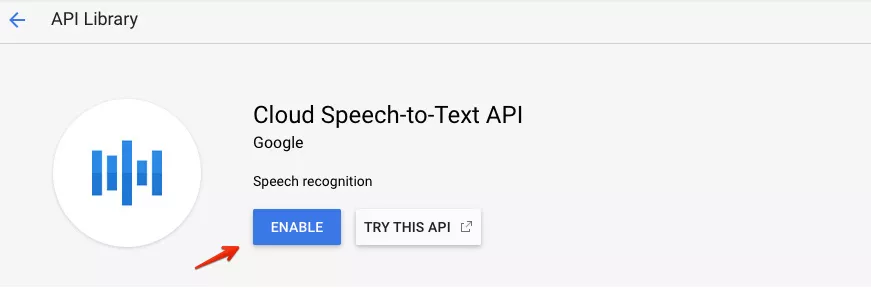
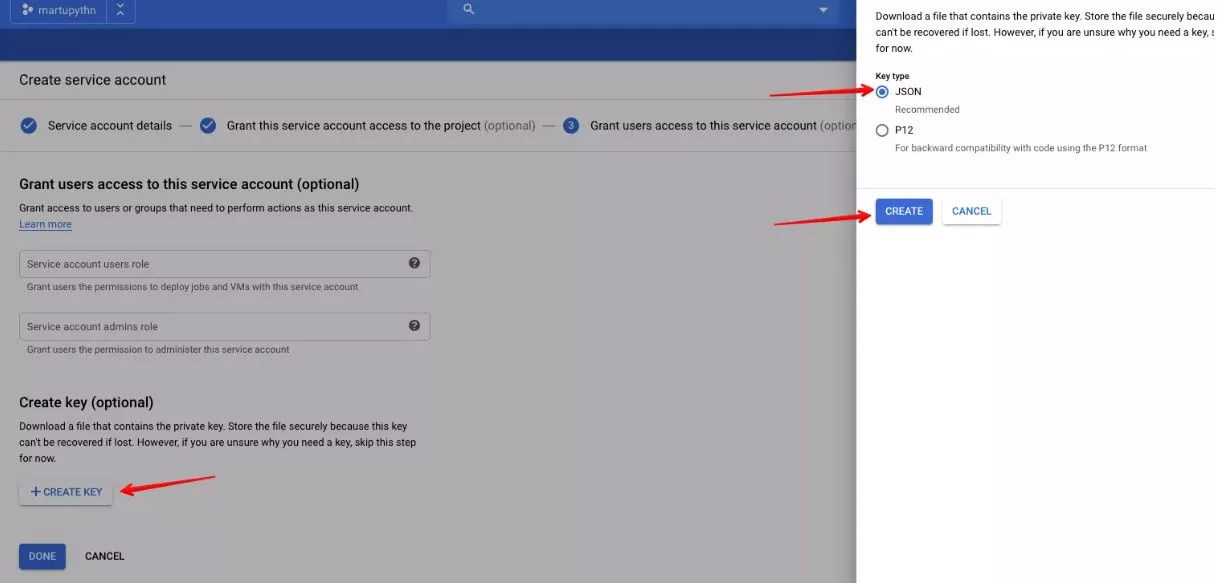
4. Настройте си удостоверяване:
- В Cloud конзолата отидете на Creative service account key страницата тук;
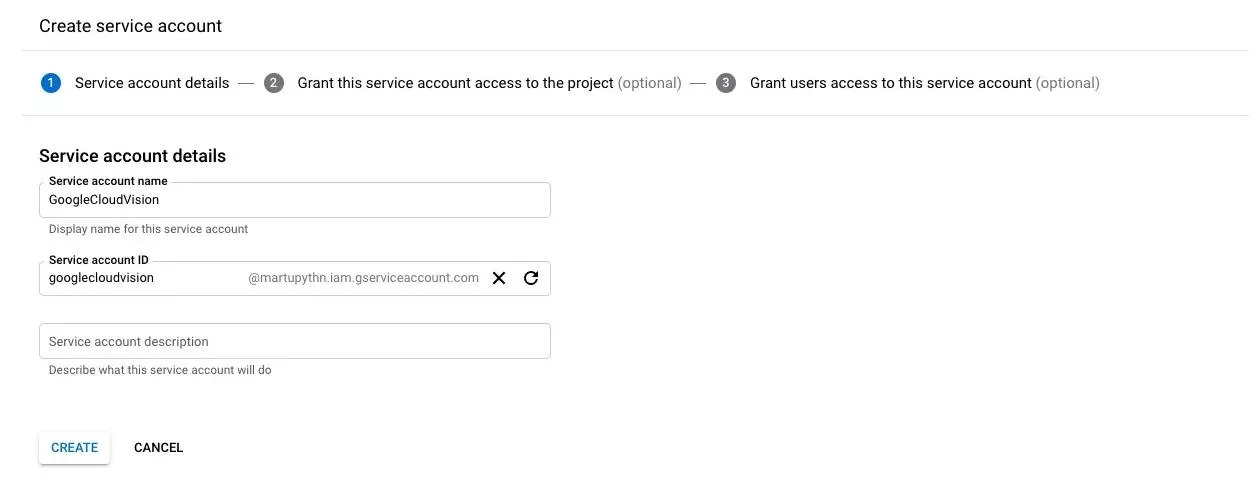
- Кликнете на Create и продължете напред;
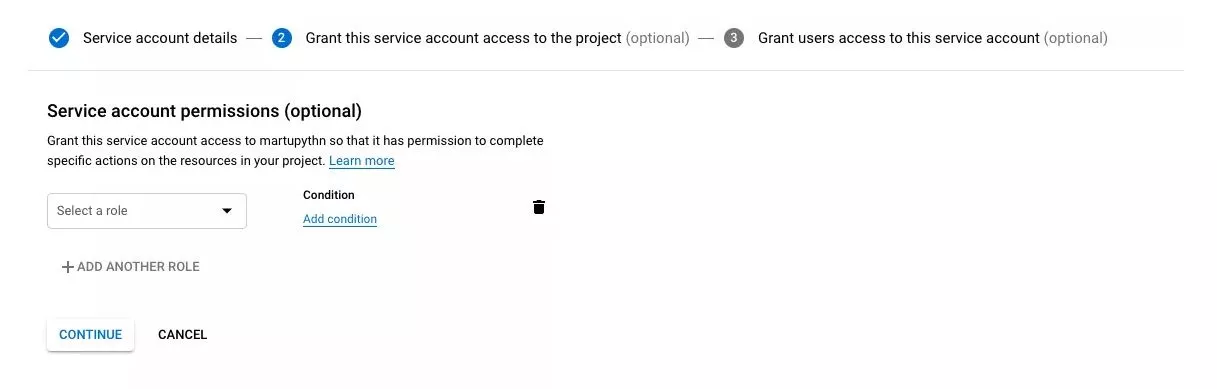
- След това въведете някакво име (нещо, което ще е разпознаваемо) в Service account name полето и от Role менюто изберете Project>Owner;
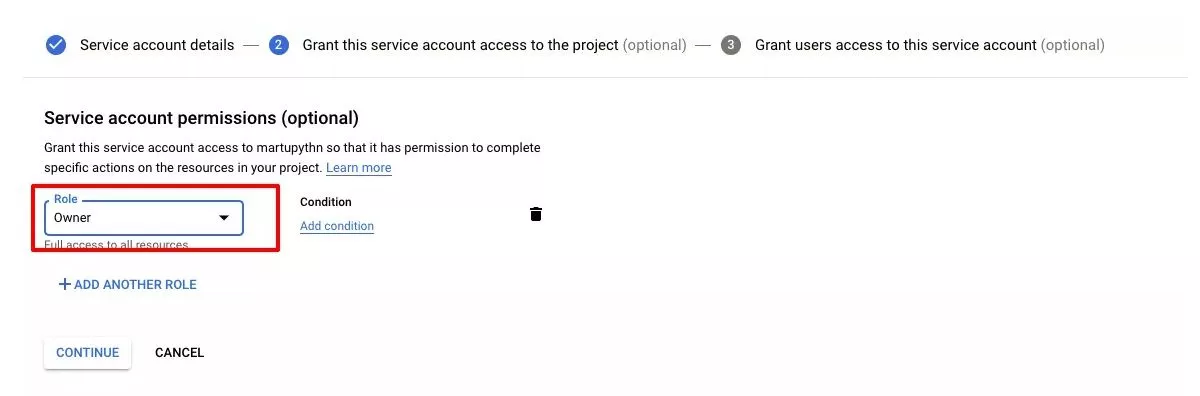
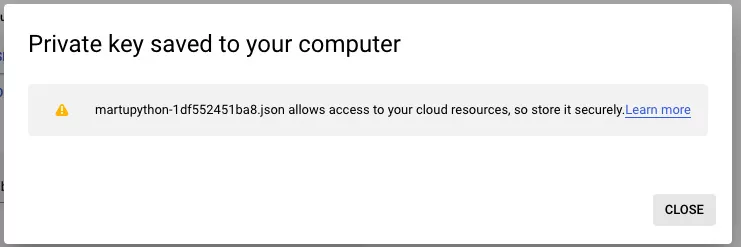
- Накрая кликнете върху Continue и после на Create на .JSON файла, който ще съдържа вашите ключове на вашия компютър.
Както казахме, Speech-to-Text API осигурява поддръжка за широк спектър от езици като Go, C#, Java, PHP, Node.js, Python, Ruby.
6. Заключение
Трябва да се има предвид, че много голяма част от функционалностите на Cloud Speech-to-Text API-то все още са в бета версия. Приложение може да е наистина голямо, но “инструмента” може да претърпи голямо развитие в бъдеще.
Вече се правят най-различни опити и експерименти за внедряването на AI в контакт центровете. Най-интересният опит, на който попаднахме, е възможността за записването на текст от телефонно обаждане на живо в браузъра ви с помощта на Twilio и Google Speech-to-Text с Node.js. Повече за експеримента тук.
Допълнителни източници на информация:

 31
31
 4
4
 4
4