Big Data SEO — големите данни в полза на вашия бизнес
Big Data в сферата на маркетинга означава работа с голям обем данни. С тях не може да се работи в Google Docs, те не се събират и на хард диска на вашия компютър. Днес бизнесът събира максимум данни за потребителите: от IP-то и браузъра до вкусовите предпочитания. Тази информация се използва, за да направи интернет рекламата по-персонализирана. Съществуват варианти за оптимизиране на целия сайт и всяка отделна страница от него, като е възможно това да се извърши масово с помощта на Big Data SEO.
Big Data SEO: на кого е нужно и защо
С времето се появяват все по-опитни потребители, които могат ясно да формулират своето търсене и само по името на сайта и снипета да определят може ли да се доверят на информацията в източника. Има и изключително много хора, които са готови дълго да проучват, премислят и формулират дълги фрази, за да намерят именно това, което търсят.
Големите проекти (над 300 000 страници) има какво да предложат на тези потребители, но невинаги нужните категории и продукти се намират на първите страници в резултатите. Тази ситуация е възможна, дори когато SEO задачи се извършват систематично, и опитни експерти постоянно оптимизират всичко по сайта.
В един момент проектът спира да расте бързо. Маркетинговите активности и рекламите биха могли да доведат до раздвижване около празниците и другите традиционни сезонни пикове, но като цяло започва да се губи усещането, че проектът се развива. Собствениците на бизнеси и маркетинг екипите започват да се тревожат, че SEO дейностите вече не дават резултат.

Във всички тези категории са вложени множество подкатегории и филтри.
Средният годишен ръст на трафика при проектите е 20-30%. При по-големите проекти този показател се снижава и дори ръст под 10% на година се счита за приемлив.
Елена Воскобойник, ръководител SEO департамент в Netpeak
За повечето проекти практиката да се оптимизират поотделно всяка страница и категория работи добре. Това най-често включва дейности като:
- подбиране на релевантни ключови думи;
- включването им в метаданните и съдържанието;
- използването им за вътрешно налинкване;
- използването им при оптимизация на външната линк маса;
- оформяне на планове за работа за всички раздели на сайта.
Постепенно резултатът от всички тези комплексно приложени действия започва да става видим. Този подход обаче е трудно приложим при големи проекти, имащи стотици хиляди страници, тъй като е свързан с огромен разход на труд и средства. Наред с това, постигането на резултати отнема значително повече време.
Значителен ръст в трафика и увеличаване на обема на продажбите дори и при проекти с голям обем, е възможно да бъдат постигнати чрез скалиране на класическите SEO процеси. По своята същност това скалиране включва в голяма степен споменатите вече дейности, но извършването им е много по-трудоемко - изисква се изтегляне на милиони ключови думи, тяхното сортиране и масова оптимизация на страници.
Big Data SEO е алтернативен начин за разрешаване на проблема. Чрез него взимаме за основа един от най-важните параметри във вътрешната оптимизация — налинкването, и масирано обработваме огромна база изчистени и подбрани нискочестотни (и не само) ключови думи. Можем да оценим конкуренцията и да наблегнем на ключовите думи, които ще донесат максимален трафик при минимални разходи.
Защо използваме вътрешно налинкване?
Съществуват множество начини да се подобри класирането на страници в резултатите от търсенето и все още неоптимизираните проекти могат активно да се възползват от тях. Когато обаче вече е направено всичко (или почти всичко), трябва да се търсят нови способи за ръст. Подходът на Netpeak се гради на работата със семантиката, а нейните възможности са безгранични.
Нашите продукти са създадени за работа със семантика — инструменти и услуги, които помагат да се извлекат огромни обеми от данни, да се подредят, да се филтрират от ненужното, и да се структурират. След това тези данни се използват за оформяне на технически задания към SEO специалистите, разработчиците и аналитиците в екипа на клиента. Тези продукти са Serpstat, Netpeak Spider и Netpeak Checker, от чиито огромни възможности се възползват много професионалисти в бранша.
Ето и част от ползите, които носи вътрешното налинкване:
- Прехвърляне на тежест между страниците. Ако към дадена страница има линкове от много други страници вътре в сайта, това дава сигнал на търсачките, че тази страница е действително значима. Така началната страница винаги е с най-голяма тежест, защото към нея има линкове от всички останали страници на сайта. Сходна е и ситуацията с категориите в онлайн магазините - ако на всяка страница има линк към релевантна категория, то ботовете на търсещите машини ще разберат, че категорийната страница е значима.
По този начин роботите придобиват представа за йерархията на страниците в рамките на сайта. Чрез налинкването ние даваме така нареченото “статично тегло” на страниците, което само по себе си е важно за класирането. Подходящи за целта са линкове към страниците, които потенциално може да търсят посетителите — услуги, продукти и т.н.
- Предаване на анкорна тежест (даване на информация за тематиката на страницата). Линкът присъства в текста чрез анкорен таг <а> в HTML кода на страницата. Анкорният текст всъщност е ключовата дума (например «пералня»), чрез която ние поясняване на търсещите машини за какво е страницата, към която води линкът.
Анкорният текст може да бъде различен - «перални», «цени на перални», «перални в София». Колкото по-добре ботът разбира за какво е страницата, толкова по-силен сигнал получава той за нейната релевантност.
- Удобство за посетителя. Чрез този тип връзки на посетителите се предлагат продукти и страници, които биха могли да ги интересуват. Те изпълняват функции както за навигиране, така и за помощ при избор — представляват предложение за стока/услуга/страница, които са максимално близки до търсенето на потребителя.
Защо е толкова важно вътрешното налинкване при големите проекти? Защото структурата на този тип сайтове е толкова обширна, че е възможно посетителите и ботовете да не достигат до страниците с по-дълбока вложеност.
Идеята в менюто на проекта да се показват хилядите линкове към тези страници не е добра и е на практика неприложима. Нужно е да се намери друг вариант, чрез който те да бъдат включени във вътрешното налинкване.
Защо използваме нискочестотни ключови думи?
Използването на нискочестотни ключови думи има две огромни предимства — те конвертират добре и за тях конкуренцията е малка. Факт е, че при масово вливане в проекта, сред тях ще има и такива, които по-трудно биха генерирали ползи, но когато процесът е автоматизиран, това няма особено голямо значение.
Например, когато влезем в онлайн магазин за дрехи и търсим конкретно «лилави рокли на цветя», такава категория по всяка вероятност ще липсва на начална страница, но е възможно магазинът да предлага такъв тип продукти. Вариациите на търсенията за видове рокли са десетки хиляди - по цвят, стил, модел, материя… Всички те могат да бъдат обхванати именно чрез използването на нискочестотни ключови думи в проекта.
Потребителите имат конкретна представа, на база на която формулират заявката си за търсене, и очакват да видят резултати, които отговарят именно на нея. Задачата на оптимизатора е да покаже страница, която е релевантна на тази заявка.
Етапи в Big Data Seo
Независимо от обема и тематиката на сайта, работата върху проекта се разделя на шест етапа (итерации):
За всеки проект подбираме източници на данни, както и методи, принципи и алгоритми, чрез които те ще бъдат обработени. На старта подготвяме техническо задание, в което подробно описваме етапите и междинните стъпки за всяка итерация.
Работа със семантика (съвкупност от всички ключови думи, релевантни на проекта)
Първо изтегляме цялата семантика на нишата, релевантна както за нашия сайт, така и за сайтовете на конкурентите ни (преки и косвени) във всяка една категория.
Откъде вземаме данните:
- Google Search Console;
- Serpstat;
- Google Ads;
- Google Analytics и други.
Тези данни се събират както за текущия сайт, така и за сайтовете на конкуренти. Тоест, ние получаваме цялата семантика на нишата. След това събраната информация автоматично се изчиства от нерелевантните и ненужни ключови думи.
Следващата стъпка е разширяване на списъка от запитвания с помощта на скрипт за генериране на семантика — за всяка ключова дума, която сме открили на предходния етап, автоматично се подбират подобни ключови думи. Обемът отново се увеличава, след което се извършва повторно почистване.
При него се филтрират ключовите думи от нерелевантни писмени системи на използвания в проекта език (за кирилица - латиница и обратно, йероглифи). Също така се определя и нерелевантна дължина на ключовата дума. Количеството думи във фразата се избира на база обема данни и личната оценка на Data Science специалиста.
Какви инструменти използва Data Science отделът
Собствени скриптове на езиците R и Python, както и разработки като Serpstat и Netpeak Spider. С помощта на тези инструменти е възможно да бъдат събрани и изтеглени стотици хиляди (дори милиони!) думи и да се отсеят нерелевантните от тях.
Събиране на Топ 100 на класираните страници по всички думи
За всяка ключова дума, събрана на предишния етап, изтегляме класираните резултати в Топ 100, за да определим типа страници, които най-често се срещат сред конкурентите. В резултат получаваме милиони редове от данни.
След това тази информация ще ни послужи за автоматична съпоставка на страници от проекта и ключови думи.
Формиране на скоринг модел
Целта на този етап е от цялата събрана семантика да се изберат ключовите думи, от които ще имаме полза при използване за вътрешно налинкване. Правим това с помощта на скоринг модел.
Скоринг — това е «оценка». А скоринг модел — алгоритъм за оценка. В нашия случай той се състои в определяне на ефективните ключови думи, които потенциално могат да ни донесат трафик с най-малко разходи.
С помощта на невронни мрежи се формира скоринг модел, който помага да се оцени всяка ключова дума от гледна точка на конкурентност, релевантност и потенциал за трафик. Всяка дума се оценява с точки, които показват ефективността й.
След оценката избираме сегмент от ключови думи, които ще донесат максимална полза.
Ако няма реклама в резултатите, ключовата дума печели две точки. Ако присъства думата «купи» — добавяме още три точки. При наличие на дума «безплатно» — вадим шест точки. Ако по ключовата дума почти липсва конкуренция — добавяме пет точки. Накрая използваме само тези ключови думи, които са събрали достатъчно точки.
Денис Стадник, SEO Tech Lead в Netpeak
Скорингът е нужен, за да се определят ключовите думи, които най-точно подхождат на конкретния сайт.
На този етап използваме собствен скрипт за определяне на показателя за качество на думите. Скоринг моделът и скриптът се модифицират, за да са приложими за всяка конкретна тематика и нейните особености.
Автоматично клъстеризиране на подходящите ключови думи
Целта тук е да се съпоставят страниците в сайта и ключовите думи в нишата, които сме получили въз основа на двете предишни итерации.
За клъстеризирането (групирането) на ключовите думи използваме Machine learning алгоритми, в чиято основа лежат методите на йерархичните и k-means клъстеризации, както и данните от резултатите на търсенето (SERP).
На изхода получаваме комбинация от URL от сайта + клъстер (група) от ключови думи. Оценяваме за кои ключови думи трябва да има повече входящи линкове и за кои — по-малко.
Създаване на връзки за налинкване
Целта на този етап е да се определят страниците-донори от сайта, в които ще бъдат вложени линковете и които ще бъдат свързани с вече създадените на предишния етап комбинации от «URL+клъстер».
Извършва се оценка на «тежестта» и «тематичността» на всяка страница в сайта за максимален ефект.
Ние вземаме решение какви страници-донори ще имат вложени линкове към страниците-акцептори. Важно е на страница с таблети да има връзка към страница с телефони, а не към такава с пелени, например (параметър «тематичност»). След това преценяваме дали по тази ключова дума има голяма конкуренция. Ако това е така, значи на акцептора ще бъдат нужни линкове от 20 страници на сайта. В случай на ниска конкуренция, достатъчно е да се постави и един линк.
Денис Стадник, SEO Tech Lead в Netpeak
В резултат получаваме бази данни със списък от анкори, донори и акцептори. Пример:
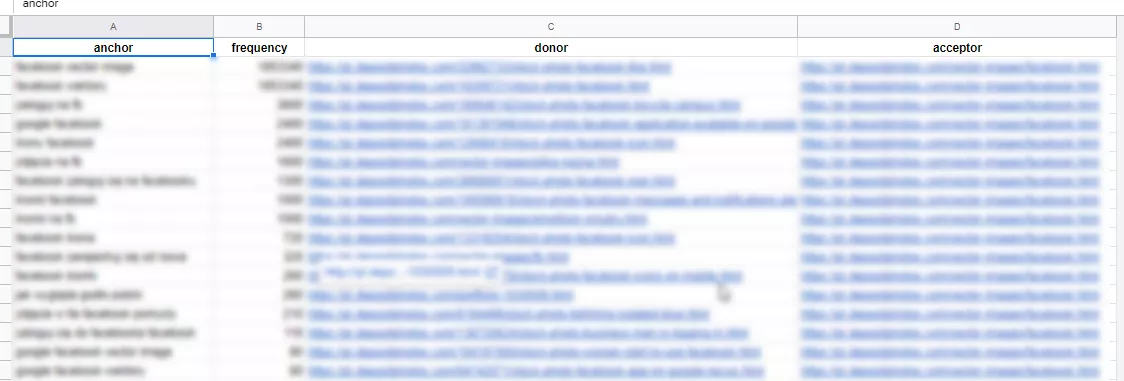
На този етап се използват скриптове, разработени от Netpeak за клъстеризация и свързаност на клъстерите към текущата структура на сайта, както и Serpstat.
Създаване на формули за title, h1 и description
На финалния стадий от процеса се генерират нови
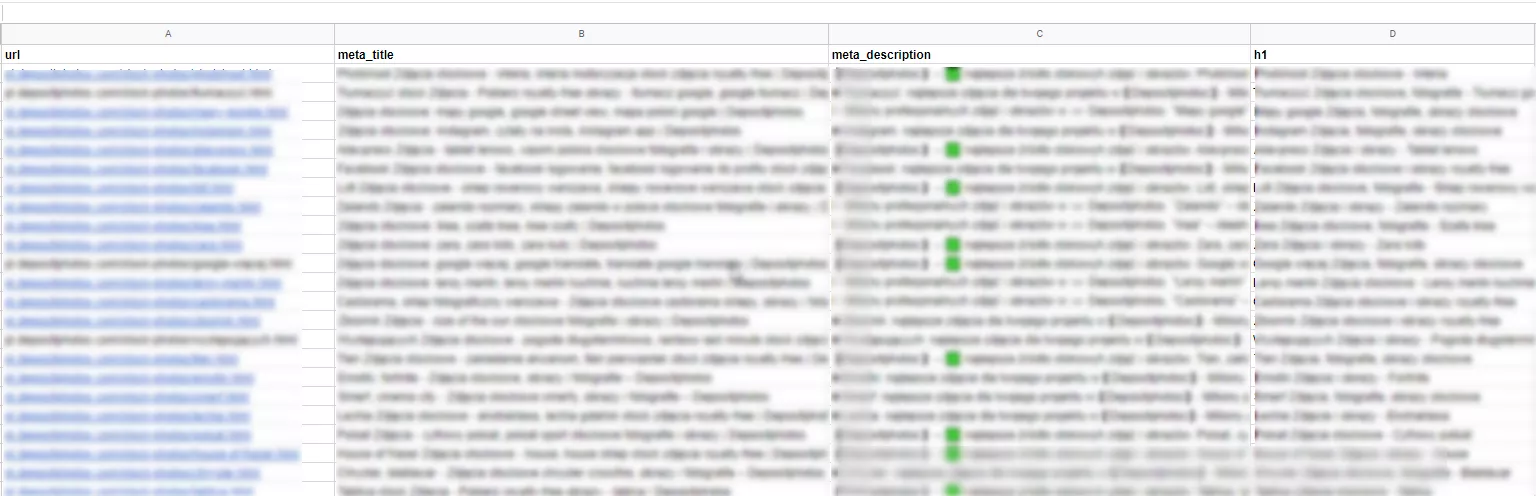
Впоследствие нашите специалисти подпомагат процесите по имплементиране на вътрешното налинкване и новите мета данни, проследяват резултатите, и консултират клиента през целия процес на оптимизация.
Резултатите от този тип дейности могат да се очакват в кратки срокове, като всъщност за тях имат принос не само екипите от опитни специалисти. Големите проекти, които имат добра онлайн история и за които е била осъществявана редовна SEO дейност, са достоверни ресурси за търсещите машини и това също помага за популяризирането на оптимизираните страници.
Обобщение
Съществува огромно количество данни за потребителите, за техните предпочитания, за поведението им онлайн, както и информация за начина, по който те търсят в интернет. Всички тези данни са всъщност Big Data.
Използването на Big Data за популяризиране на страници и проекти в търсачките се нарича Big Data SEO. Подходът на Netpeak се състои в скалиране на
Налинкването помага да се предаде тежест между страниците и анкорна тежест, като същевременно подобрява навигацията в сайта. В резултат той става по-разбираем за търсещите машини. Увеличението на тежестта на отделните страници води до увеличение на тяхната ценност за ботовете. Такъв сайт ще бъде удобен за потребителите, което от своя страна поражда лоялност в тях и води до нисък Bounce Rate.
Употребата на нискочестотни ключови думи допринася за повишаване на конверсиите. Друго голямо тяхно предимство е, че по правило конкуренцията за тях не е голяма. Намирането, тегленето и филтрирането от нерелевантни ключови думи за големи проекти в никакъв случай не е лесна задача.
Етапи в Big Data SEO:
- Събиране на семантика, за да се разшири максимално обемът от ключови думи. Изтегляне на цялата семантика на нишата, обхващаща както нашият сайт, така и сайтовете конкуренти (преки и косвени) във всяка категория.
- За всяка ключова дума, събрана на предишния етап, се изтеглят Топ 100 страниците в SERP, за да бъде определен типа страница, която най-често се среща сред конкурентите. Резултатът е милиони редове от данни.
- Формиране на скоринг модел: намиране на ключови думи, които ще донесат позитиви за проекта при използването им за вътрешно налинкване.
- Клъстеризация на подходящите ключови думи — съпоставяне на страници от проекта и релевантни на тях ключови думи от нишата.
- Създаване на връзки за вътрешно налинкване (определяне на релевантни донори).
- Създаване на формули за title, h1, description за страниците, които участват във вътрешното налинкване.

 31
31
 5
5
 2
2