JavaScript vs. SEO: какво ги свързва и разделя
В тази статия ще се постараем да ви запознаем с доста голяма част от методите за оптимизация на JavaScript за SEO. Ще обясним какво е важно да се направи и защо.
Ще ви дадем допълнителни препоръки за това как ботовете да могат да обхождат сайта Ви коректно и ефективно.
Въпросът, който ни тормози от години, е “Можем ли да класираме добре сайт, който е изграден на JavaScript” и като цяло отговора на Google е “Може, но има много фактори, от които това зависи.”.
Терминология и типове съдържание
Разбира се, преди да задълбаем в тази тема трябва да отделим време и на някои от основните термини, които ще използваме. Всеки ден ги чуваме, но голяма част от хората не знаят точно какво означават или представляват. Затова нека да започнем със следното...

Какво е JavaScript?
Накратко ще кажем, че това е скриптов език за уеб програмиране, който ви позволява да създавате динамично съдържание. Той се използва предимно за подобряване на уеб страници, за да осигури по-добро потребителско изживяване. Също така JavaScript не трябва да се бърка с Java. Пример за сайт изграден на React.js е, да кажем, Facebook. Ползва се също така и на много други места (дори и на сървърно ниво - Node.js), като се е превърнал в един от най-използваните езици за програмиране.
Извадка от анкети в чуждестранни сайтове:
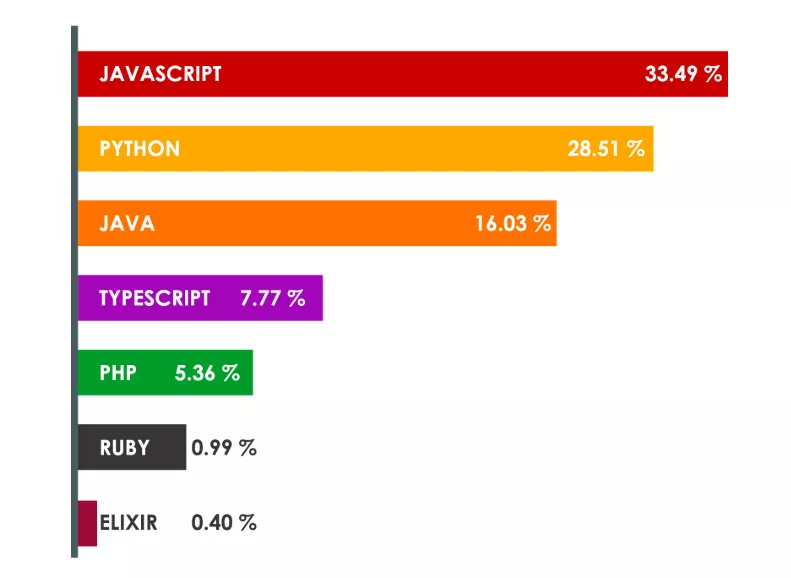
Какво е HTML?
Hypertext Markup Language или HTML е езикът, който създава статичното съдържание. Или по-просто казано - организира съдържанието, като осигурява структурата на уеб сайта (заглавия, подзаглавия, абзаци и т.н.).
Ако работите в тази сфера е нормално да знаете, че описанието му става чрез специални елементи, които се състоят от тагове или така наречените HTML tags. Тук няма да изпадаме в подробности, за да не изместваме темата. Пример за сайт изграден само на HTML тук.

Какво е AJAX?
AJAX е съкращение за асинхронен JavaScript и XML. Аджакс, Аякс или Ейджакс (IT жаргони) отново се използва за изграждане на уеб сайтове и уеб приложения. Неговата работа е свързана с обмен на малки порции данни “зад кадър”, които могат да променят само частично информация от страницата. По този начин се намалява количеството информация, която се трансферира между сървъра и клиента. Пример за такъв сайт може да се види тук. Най-големите предимства са, че:
- няма нужда от презареждане на страницата;
- времето за отговор се скъсява;
- броят заявки към сървъра намалява, защото скриптовете и CSS-файловете се зареждат само веднъж;
Трябва да бъде отбелязан и фактът, че от началото на второто тримесечие на 2018г. Google вече не използва старата схема за обхождане на AJAX. Но това не трябва да ви притеснява, защото не означава, че сайта ви ще спре да се индексира. Старите AJAX адреси използват “ #!” в URL адреса си. Когато, обаче, ботът дойде да обхожда сайта, трябва да предостави статичен адрес чрез фрагмента “?_escaped_fragment=”. Това така или иначе не се използваше толкова много от програмистите, защото има много варианти, които се използват за превръщането в нормални URL адреси като pushState, но затова по-надолу в статията.
Пълната информация относно официалното становище на Google можете да откриете тук.
Битката на SEO специалистите

Постоянно променящата се информация за алгоритмите на търсачките, както и други фактори, често поставят SEO специалистите в ситуация на постоянно обучение. Те трябва да знаят винаги актуалните новини, както и да се усъвършенстват и в разбирането на други дисциплини, които могат да им помогнат в работата. Естествено, трябва да се има предвид, че понякога Google излиза с много обща информация (без технически обяснения) и затова понякога трябва да придобиваме знания и опит на принципа проба / грешка. Но нека да поговорим малко и за DOM.
Какво е DOM?
Основните познания за DOM са част от работата на един специалист. Трябва да знаем какво представлява и как можем да го използваме. Най-просто казано това е набор от функционалности, които самия браузър осигурява, за да бъде позволено на разработчиците да достъпват и манипулират уеб страниците.
Когато една уеб страница се зарежда, браузърът създава D ocument O bject M odel на страницата.
В HTML модела му има дървовиден стил:
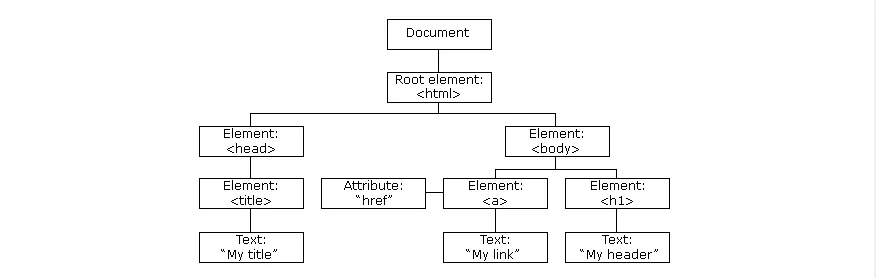
Трябва да се знае, че JavaScript има пълната сила да променя DOM в реално време, за да създадем динамичен код. Фантастично нали? Чрез него JavaScript може да:
- променя всички HTML елементи в страницата;
- променя всички стилове на CSS;
- премахва съществуващи HTML елементи и атрибути;
- добавя нови HTML елементи и атрибути;
- създава нови HTML събития, както и да реагира на вече съществуващи такива.

DOM е W3C (World Wide Web Consortium) стандарт. Той определя стандарта за достъп до документи. Официалното определение е:
"Моделът за документи на W3C (DOM) е платформен и езиков неутрален интерфейс, който позволява на програми и скриптове да осъществяват динамичен достъп и актуализиране на съдържанието, структурата и стила на документа".
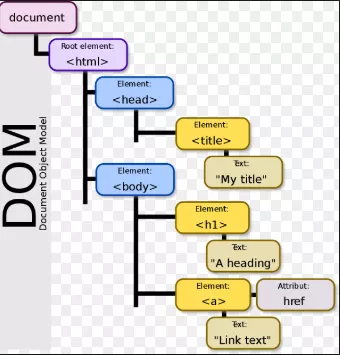
Стандартът W3C DOM е разделен на три различни части:
- Core DOM - стандартен модел за всички типове документи;
- XML DOM - стандартен модел за XML документи;
- HTML DOM - стандартен модел за HTML документи.
Как да го открием?
Със сигурност не в парка или някъде на улицата. Дървовидният изглед на DOM можем да видим в панела на Chrome DevTools. Там се вижда структурата на DOM на текущата страница. Единият вариант е като натиснем десен бутон и Inspect Element, а другия чрез клавишната комбинация Ctrl+Shift+C (за потребители на Windows) или Cmd+Shift+C (Mac)
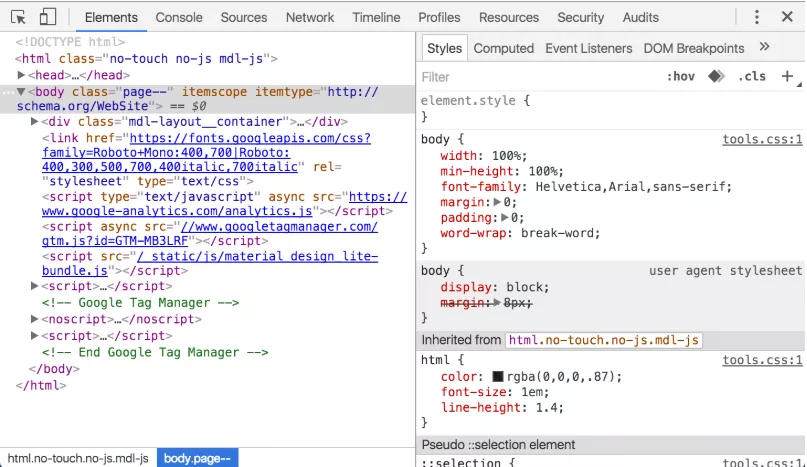
Как да позволим на търсачките да видят JavaScript
Чрез файла Robots.txt вие предоставяте на търсещите машини възможност за обхождане. Ако блокирате видимостта на JavaScript, страницата ще се покаже по различен начин на роботите, сравнено с потребителите.
Добавете нужните редове във вашия robots.txt файл и това ще позволи на Google бота да обходи всички CSS и JavaScript файлове на вашия сайт. Използвайте robots.txt tester. Този инструмент ще ви даде конкретна информация дали файлът блокира ботовете от конкретни URL адреси в сайта или цели директории.
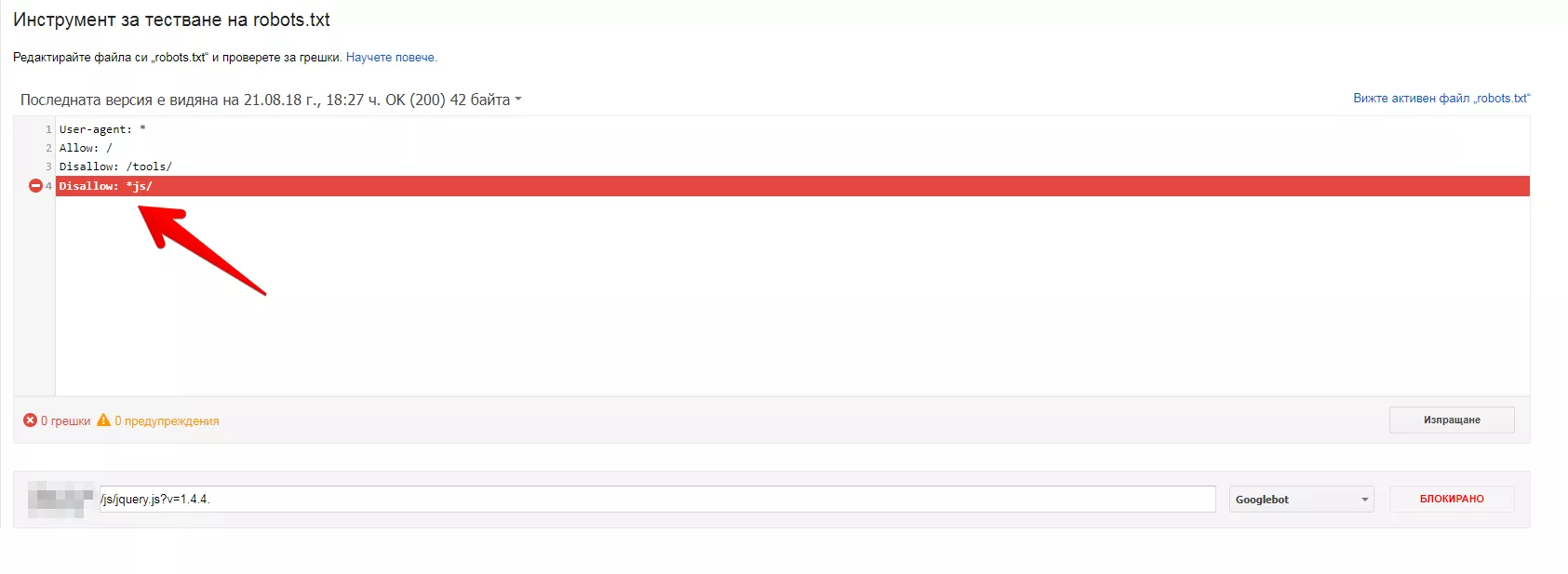
Също така имайте предвид, че Google не индексира .css и .js в резултатите от търсенето. Не е нужно да се притеснявате за тези файлове, като си причинявате ненужни проблеми, свързани с SEO. Всъщност може да се случи обратното, тъй като блокирането на тези файлове може да доведе до ниско класиране.
В такива случаи е препоръчително организиране на среща с програмистите по съответния сайт, за да се реши кои файлове трябва да бъдат скрити от търсачките и кои трябва да станат достъпни.
Проблеми при обхождането на JavaScript
Преди да започнем да си изясняваме какъв е проблемът при обхождането на JavaScript, има няколко технически точки, които трябва да се пояснят:
- отнема твърде много ресурси на бота, за да обходи подобно съдържание;
- съществуват различни frameworks за JavaScript, както и за SEO оптимизацията им. Трябва да има задълбочен анализ на това как е изграден вашият уеб сайт и да си направите различни изводи за това нещо.
- ако вашият сайт все още разчита на старата схема за обхождане с AJAX, трябва да го промените. Google спира използването на escaped фрагментите, което е описано в статията по-горе. Вместо URL адресите да съдържат _escaped_fragment_ , ще се обхождат и индексират #! URL адреси. Трябва да се постараете да сте в крак с последните новини;
- връзките, както и елементите за кликване, трябва да имат атрибут ng-href (не ng-click), ако използвате Angular.js framework.
- href атрибута ще бъде разбран от роботите, само ако съдържа анкор връзка.
Ограничения при обхождането на JS
В случай на традиционен HTML, всичко е лесно и видимо:
- Google ботът изтегля HTML файла;
- извлича връзките от изходния код и ги посещава;
- изтегля CSS файловете;
- изпраща всички изтеглени ресурси до индексиращата система (caffeine);
- страницата се индексира.
Като цяло този процес е доста бърз. Нещата обаче се променят, когато става въпрос за уеб сайт, базиран на JavaScript:
- Google ботът изтегля HTML файла;
- изтегля CSS и JS файловете;
- след това трябва да използва услугата Google Web Rendering Service (част от caffeine индексатора), за да анализира и изпълни JS кода;
- след това WRS извлича данните от външни програмни интерфейси (API), от базата данни и т.н.
- накрая индексаторът може да индексира съдържание;
- сега Google може да открие нови връзки и да ги добави към опашката за обхождане на бота.
Разглеждането, анализирането и стартирането на JS файловете отнема много време. В случай на богат на JavaScript уеб сайт, Google трябва да изчака, докато се завършат всички стъпки, преди да може да индексира съдържание. При JavaScript основните трудности се базират на:
- трудно сканиране и обхождане;
- некоректно разпределение на вътрешната тежест;
- трудно дефиниране и разграничаване на важни и маловажни страници;
- трудности при определянето на канонични адреси.
Google и техническите им ограничения
Google използва почти 4-годишен браузър!

Логично би било да си помислим, че всеки от нас използва най-новата версия на браузъра си. Последната актуализация на Chrome (която използвам, докато пиша статията) е 69.
Google ботът използва Chrome 41, за да рендира уеб сайтовете. Това е версия на браузъра, която е пусната през март 2015г. Това са повече от 3 години, а само като се замислим колко много неща се случиха през това време.
Има много съвременни функции, които просто не са достъпни за Googlebot. Някои от основните ограничения включват:
- Chrome 41 поддържа само съвременния ES6 JavaScript синтаксис и то частично. Например, тя не поддържа конструкции като "let" извън "strict mode".
- интерфейси като IndexedDB и WebSQL са деактивирани.
- бисквитките и локалното съхранение, и съхранението на сесии, се изчистват между заредените страници.
- и все пак това е браузър на повече от 3 години.
Що се отнася до техническите ограничения на Chrome 41, можете да видите разликите между Chrome 41 и Chrome 68 (най-новата версия на Chrome в момента на писане на тази статия) е тук. Вътре може да бъде открита изключително ценна информация за програмистите ви. Естествено няма да изпадаме в дълбоки обяснения на всяка една част от разликите, но ако пратите този линк към един добър developer, определено той ще разбере всичко.
Сега, след като се знае, че Google използва Chrome 41 (официално становище тук), можете да отделите нужното време, за да изтеглите този браузър и да проверите някои от уеб сайтовете си, за да видите дали те могат да бъдат правилно показани.
Как да откриваме проблемите?
Докато правехме нужното проучване, попаднахме на един много интересен експеримент направен от колеги в сферата. Става въпрос за сайта https://jsseo.expert/
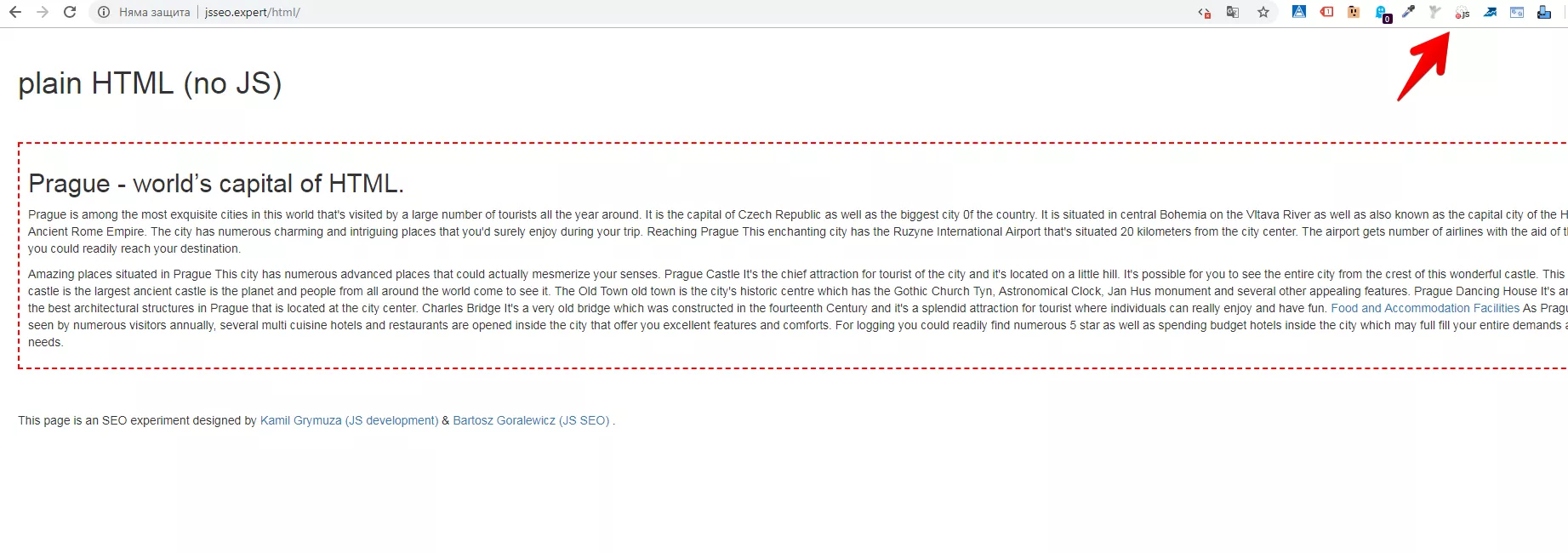
Всяка подстраница има съдържание, което е генерирано от различни frameworks на JavaScript. Можем да видим как нашия браузър ги вижда и дали когато изключим JavaScript ще виждаме съдържанието вътре. Например, ако влезем в страницата, където се съдържа само HTML код, и изключим JS с JavaScript Switcher може да видим, че съдържанието си остава същото:
Ако обаче влезем в подстраницата, която е изградена на React.js, ще видим следния резултат:
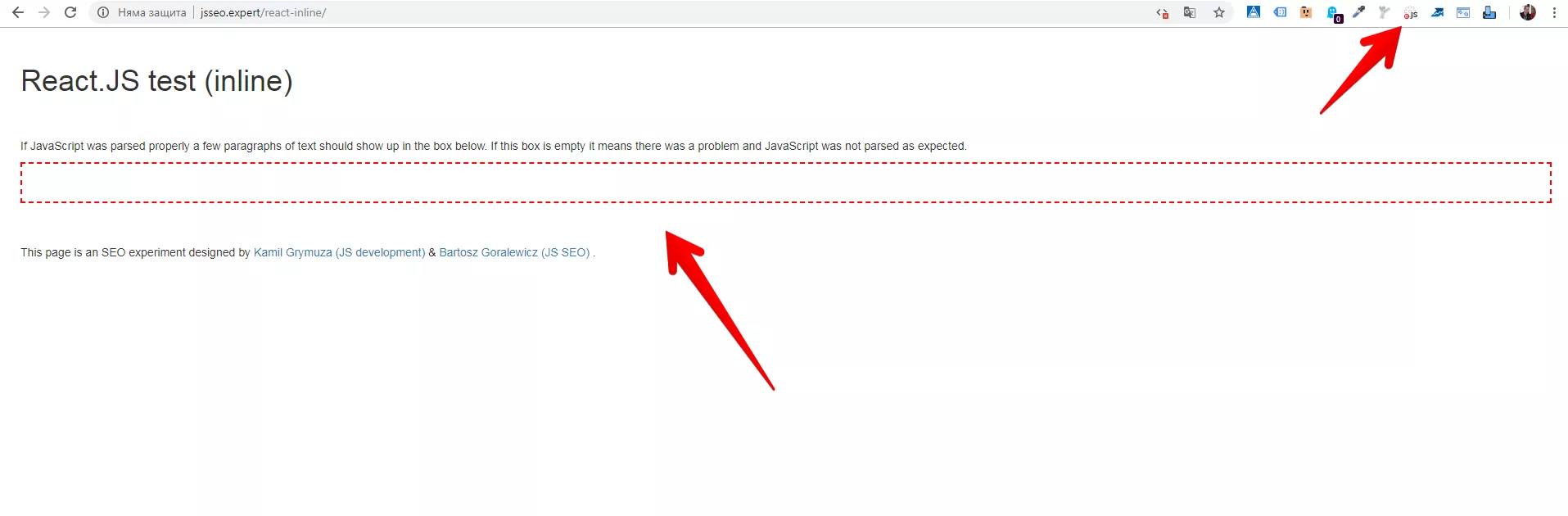
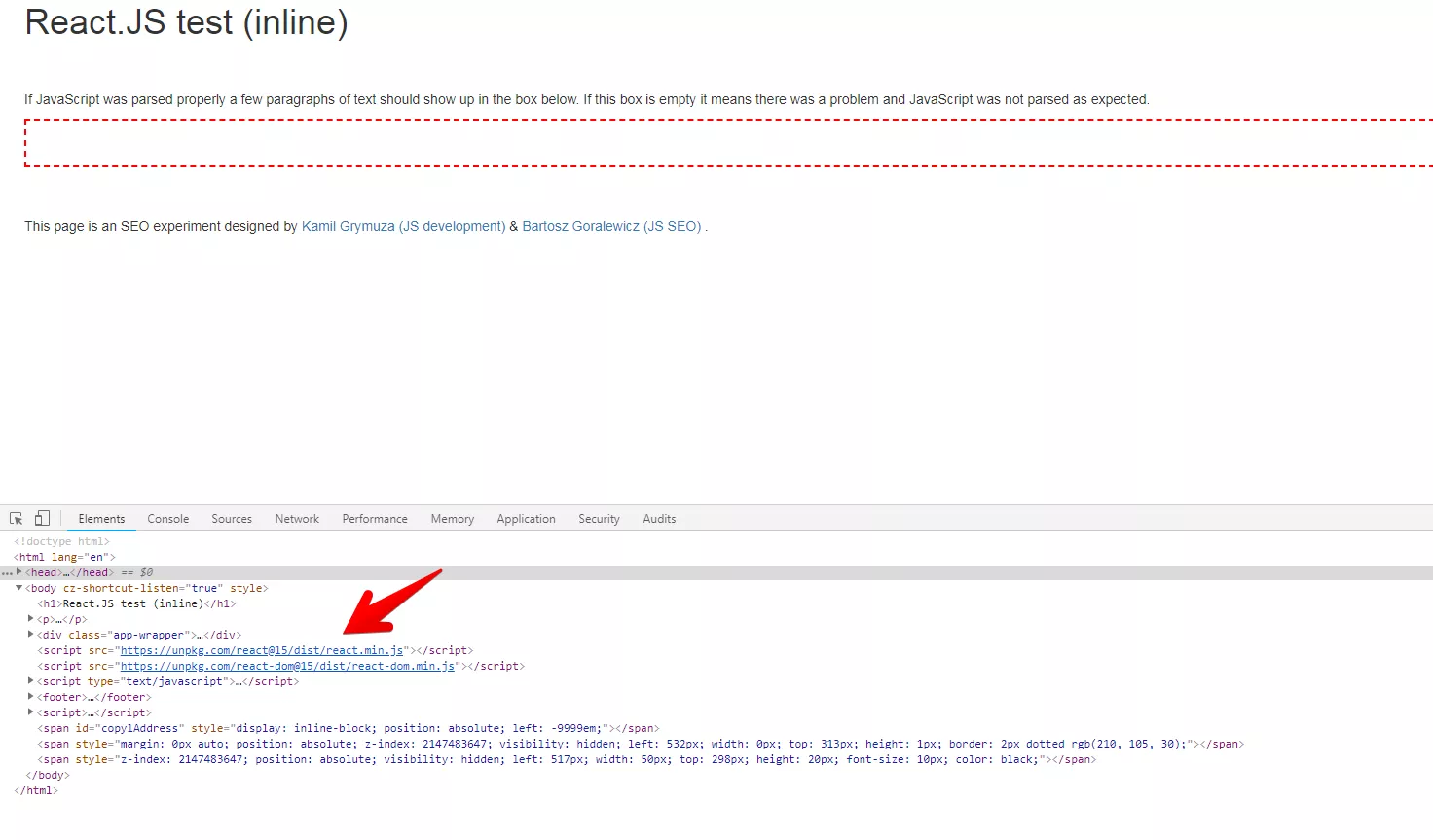
А какво се случва, когато включим JavaScript?
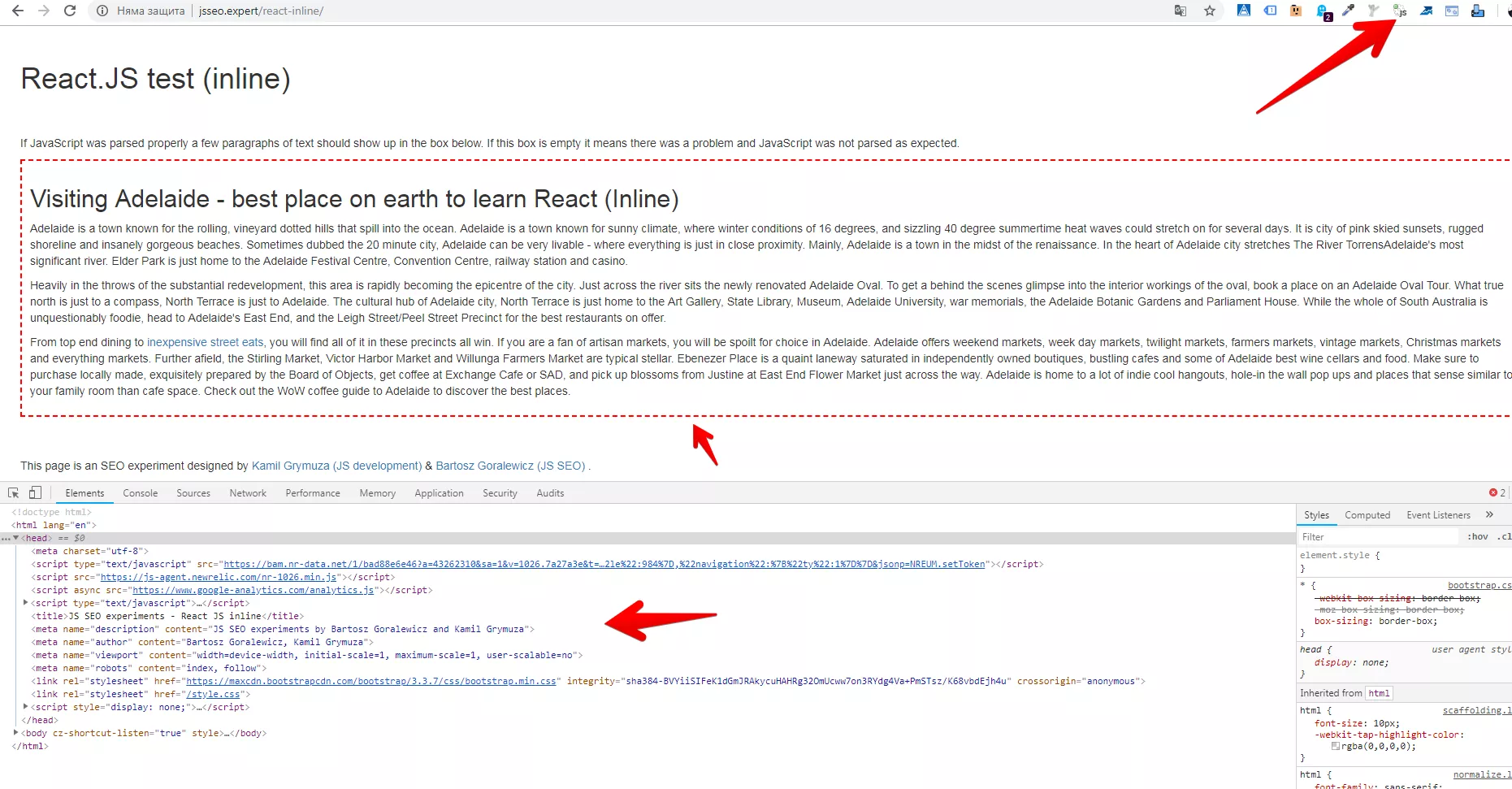
Можем да си направим изводите, че е много важно да намерим начини за рендиране на JS съдържание. Много лесно можем да проверим как бота вижда нашето съдържание с дясно копче и Inspect element. Друг пример с реален сайт можем да видим тук:
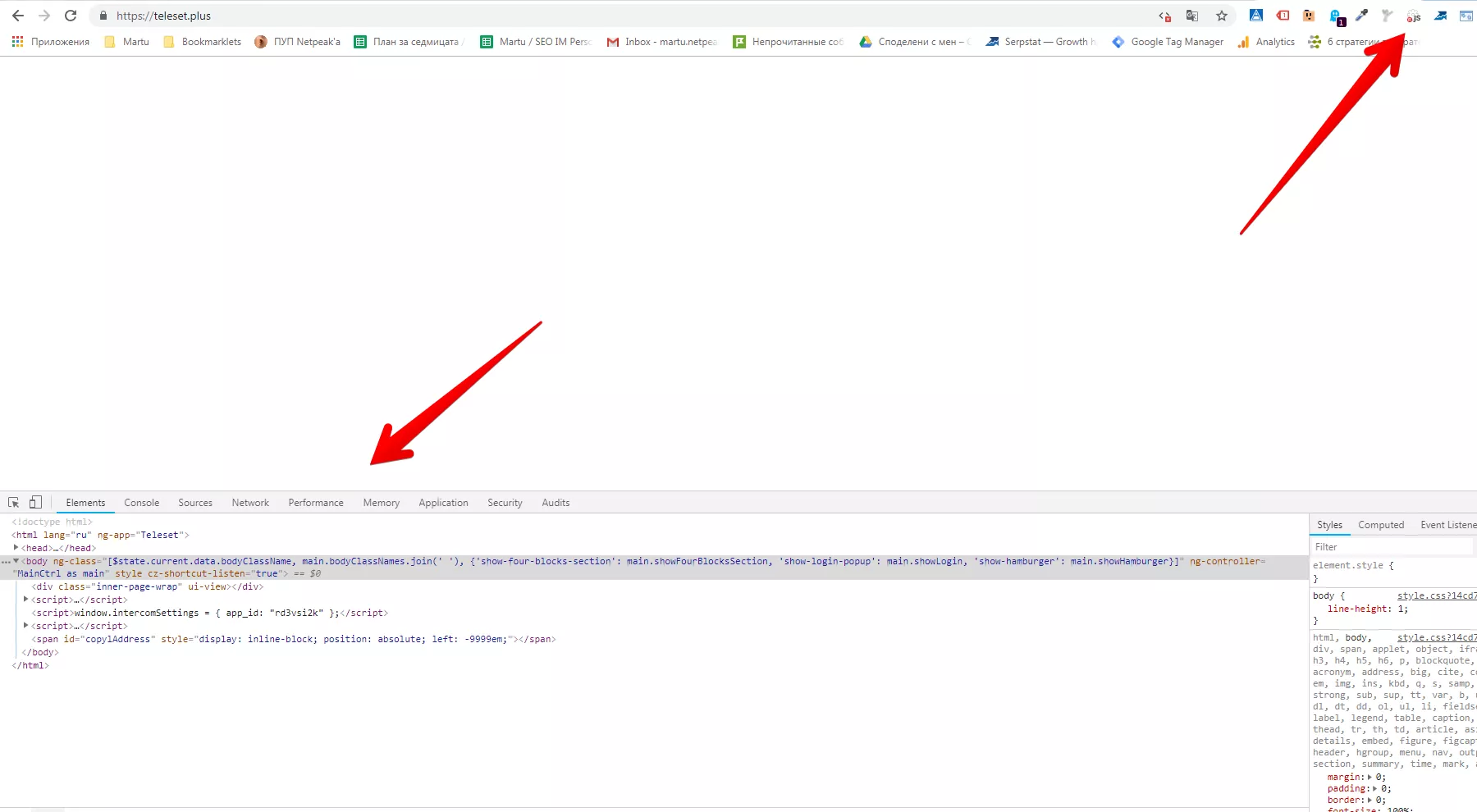
Така можем да видим какво ботът вижда като изключим JavaScript от страницата. Т.е. това е нещо, което не трябва да допускаме, за да имаме добро класиране.
Структуриране на URL адресите
Базираните на JavaScipt уеб сайтове използват идентификатори на фрагменти в рамките на URL адреса си. Но hash(#), както и hashbang(#!), не се препоръчват от Google.
Препоръчителен метод е API за pushState History. Това актуализира URL адреса в адресната лента и позволява на уеб сайтовете на JS да използват чисти адреси.
Чист URL адрес е такъв адрес, който е разпознаваем и удобен за търсачките, и се състои от обикновен текст, лесно разбираем за хора, които не са специалисти.
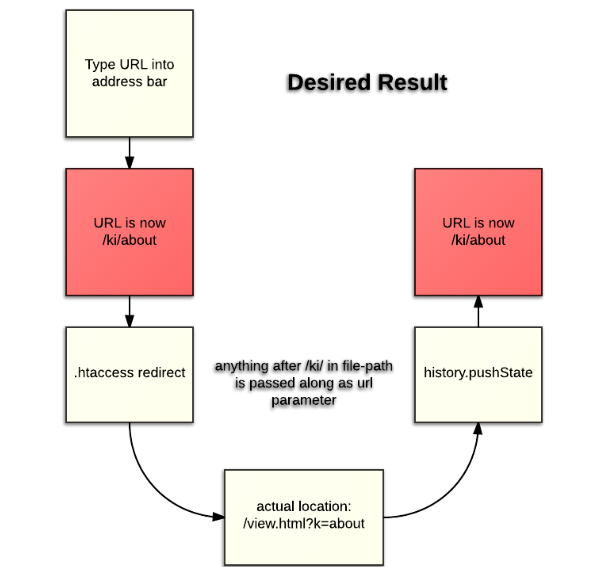
Обмислянето на използването на pushState infinity scroll е добър вариант. По този начин да се направи така, че URL адресът да се актуализира всеки път, когато потребителят докосне нов елемент от страницата. Пример за такъв уеб сайт можете да видите тук.
При най-добрият сценарий потребителят може да опреснява страницата, но да остане на същото място.
6 метода за оптимизация на JavaScript сайт
Ще групираме част от методите за оптимизация на JavaScript сайт. Това са методи, използвани от специалисти и даващи реални резултати.
Server-side rendering
Попринцип това е функционалност, която не е с особено голям приоритет при изграждането на уеб сайта, но е от значение, ако се планира SEO оптимизация на сайта.

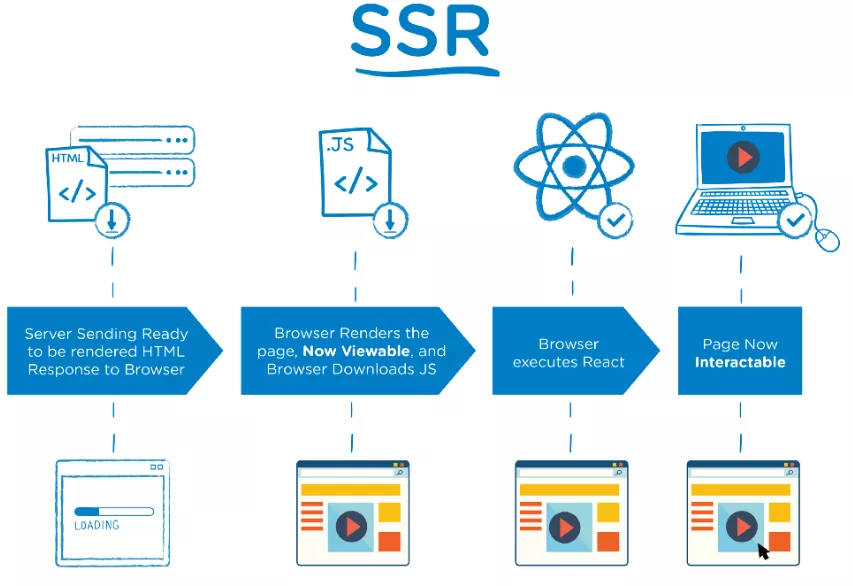
Как работи Server-side rendering
Работи на принципа да преобразува HTML файловете в сървъра в използваема и правилно изобразяваща се информация за браузъра.
Когато се използва Front end js framework, възниква проблем. Когато ботът на Google достъпи сайта, той не чака изпълнението на framework-а и съответно не може да достъпи съдържанието на дадената уеб страница. Това налага използването именно на това рендиране.
Когато ботът достъпи адреса на сайта, на сървъра се изпълнява front end javascript-а и се връща като html заявка, която е вече с цялото съдържание на страницата и бота индексира успешно съдържанието. Допълнителна информация за имплементирането му тук.
Оптимизиране на заявките от сървъра към клиента
Препоръчително е да се оптимизират всички заявки от сървъра към клиента, така че всяка заявка, която се връща към клиента, да има точния набор от данни, които са му нужни, без никакви допълнителни данни.
Кеширане на данните на потребителя
Имплементиране на алгоритми за кеширане на данните на потребителя. Така не е нужно при всяко следващо отваряне на вече заредена страница, отново да се изпълняват заявки към сървъра, а да работи с данните, които вече е взел след първата заявка.
Също така на сървъра е препоръчително да се имплементират кеширащи алгоритми, с цел по-рядко обръщане към базата данни с различни заявки, тъй като всяко обръщане на сървъра към базата данни изисква време и забавя времето на отговор към потребителя.
Load Balancer
На сървъра да се имплементира Load Balancer (повече информация тук) с цел “разтоварване”. В зависимост от трафика се подкарват две или повече инстанции на сървъра с цел равномерно разпределяне на заявките.
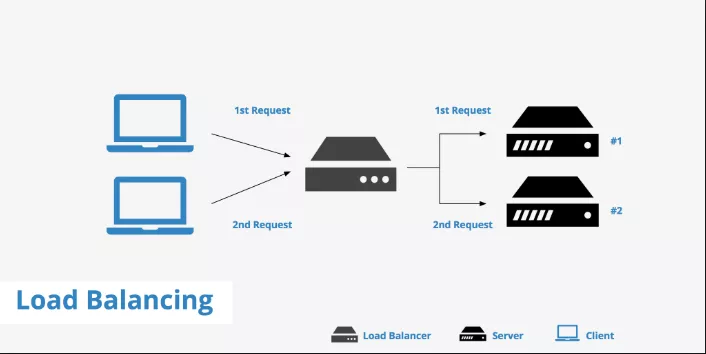
Общо взето това представлява един разпределител на натоварването. Това се налага най-вече за големи сайтове, когато в един момент сървърът не е достатъчен за натоварването, което прави самият сайт. В такива случай самият уеб сайт се разпределя на два сървъра, съответно и натоварването спада.
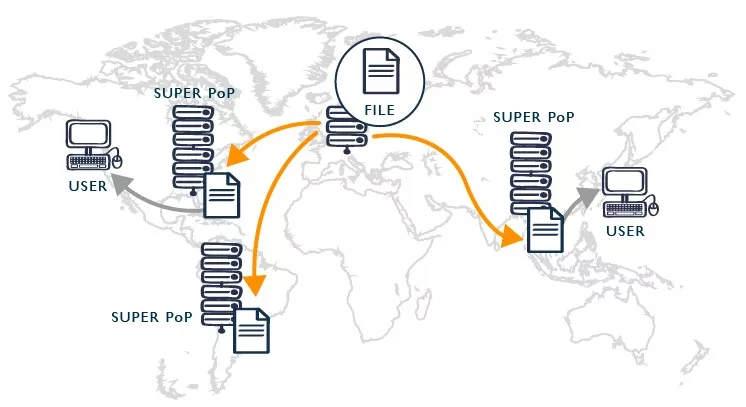
Content Delivery Network
Да се използва мрежа за доставяне на съдържание CDN за статичните файлове на клиента (js, img, css). Функционалността и е свързана с това, че съхранява кешираната версия на файла в многобройни географски локации на различни сървъри. Това е удобно, ако например сте в Ню Йорк и искате да достъпите някакво съдържание от България. CDN позволява да достъпите тази кеширана версия на сървър, базиран в САЩ, и по този начин времето ви за достъп намалява значително.
Минифициране на CSS и JS
Препоръчваме компресиране на размера на CSS и JavaScript файловете, което ще допринесе за по-бързото доставяне към клиента. Минимизирането се отнася за премахването на ненужни или излишни данни, без да се засяга ресурсът от браузъра.
Официалните препоръки от Google за минимизирането на HTML,CSS и JavaScript ресурсите са:
- За да минимизирате HTML, опитайте HTMLMinifier
- За да минимизирате CSS, опитайте CSSNano и csso .
- За да минимизирате JavaScript, опитайте UglifyJS .
Допълнителна информация тук.
Заключение
Търсачките непрекъснато се развиват, така че те несъмнено ще интерпретират JavaScript по-добре и по-бързо в бъдеще.
Засега трябва просто да се уверите, че вашето сегашно съдържание може да се обхожда и да се класира добре. Надяваме се тази статия отчасти да ви е помогнала за оптимизацията на уеб сайта Ви. Ще продължаваме с подобен тип статии за JS и SEO, защото това определено е доста актуална тема от години насам.

 55
55
 33
33
 20
20