Как да спестим часове работа с автоматизирано клъстеризиране на семантичните ядра
В обширния свят на дигиталния маркетинг и оптимизацията за търсачки (SEO) събирането на семантично ядро заема централно място, като основа за изграждането на ефективна стратегия за съдържание.

Въпреки че много е писано и говорено по темата, действителната стойност и приложимост на тази информация се разкрива единствено когато разполагаме с уменията и знанията за правилното групиране (клъстеризиране) на ключови думи и фрази.
Този процес не само улеснява структурирането на вашето семантично ядро, но и е ключът към създаването на перфектната структура на сайта ви, оптимизирана за търсачките и потребителите.
Семантичното ядро представлява съвкупност от ключови думи и фрази, тясно свързани с продукта или услугата, която предлагате. То е основата, върху която се изгражда вашата SEO стратегия, и служи като пътеводител за разпределението на съдържанието по страниците на сайта. Клъстеризацията, или сегментацията на това семантично ядро на групи по общи признаци, е следващата стъпка, която позволява на сайта ви да се развива и класира успешно в търсачките.
Например, в рамките на клъстера "кредити" могат да се обособят подкатегории като "потребителски кредити", "ипотечни кредити", "кредити за пенсионери" и др., които са директно свързани с основната тема, но същевременно достатъчно специфични, за да задоволят конкретни потребности.
Повече по темата може да видите в статиите
От ръчна към автоматизирана клъстеризация
В ерата на дигиталното пространство, където информацията расте с експоненциална скорост, ефективността и прецизността в организацията на данни стават все по-важни.
Поради тази причина се заехме с предизвикателството да създадем скрипт за автоматизирано клъстеризиране, който трансформира начина, по който обработваме и структурираме ключовите думи и фрази в рамките на семантичното ядро. Нашата цел беше ясна – да спестим ценно време и усилия.
Този скрипт автоматизира задачата за клъстеризиране на ключови думи – задача, която досега изискваше значително количество време и ръчна работа. Използвайки съвременни технологии и алгоритми за обработка, скриптът анализира и групира заявки на базата на тяхната семантична близост, позволявайки по-голяма точност и съответствие с потребителските намерения.
Как работи скриптът?
Скриптът, който разработихме, преобразува комплексния процес на структуриране на семантичното ядро в управляема и автоматизирана задача, като по този начин осигурява значителни предимства пред традиционните методи.
Използвайки различни техники за обработка на данни и анализ, скриптът автоматично анализира ключовите думи и фрази, извлечени от вашето семантично ядро, и ги групира в клъстери на базата на семантична близост и релевантност. Това се постига чрез детайлно разглеждане на всяка фраза, отделяйки тези, които не трябва да бъдат клъстеризирани, и чрез идентифициране на ключовите думи, които служат като основа за формиране на клъстерите.
Скриптът внимателно премахва нерелевантните или изключените думи и прави така, че всяка ключова дума, и свързаната с нея честота, да са точно отразени в крайния резултат. Това позволява на SEO специалистите бързо да идентифицират и организират своите ключови думи в структурирани клъстери.
Освен това скриптът предвижда автоматично създаване на нови листове в рамките на електронната таблица за всеки клъстер, като по този начин организира данните в леснодостъпна и разбираема форма. С тази автоматизация процесът на оптимизация на сайта става по-гъвкав и целенасочен, като същевременно се намалява времето за ръчна обработка и анализ на данни.
Скриптът не само повишава ефективността и точността на обработката на семантичното ядро, но и открива нови възможности за усъвършенствано планиране и реализация на SEO стратегии.
Поглед отвътре
Направете копие на следната таблица. В нея ще видите кратка клъстеризация при семантично ядро “кредити”.
Най-важното нещо е да се запознаете с инструкциите от таб “Information”.
Таблицата е направена да работи само със семантика на български език.
За всички останали езици направете копие на следната таблица.
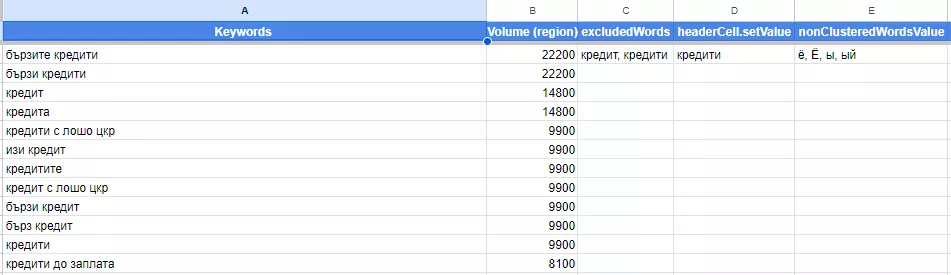
Таб “Data”
Тук е важно да имате цялата семантика за дадена ключова дума/фраза и честотността (средно месечно търсене) на тези думи.
Също така, в клетка C2 трябва да сложите думи, които да не се взимат под внимание при клъстерите, защото ще дублирате цялата семантика.
В клетка D2 сложете главната ключова - по този начин ще се казват отделните клъстери т.е ако сме сложили “кредити”, то всеки клъстер ще започва с “кредити + [клъстер]”.
В клетка E2 сме сложили най-често използваните руски букви с цел такъв тип ключови думи да не влизат в клъстеризацията - може да сложите и определени думи, които да не влизат в клъстеризацията (спазвайте формата в клетката).
Да клъстеризираме!
След като имаме всички данни в таб “data”, остава само да стартираме скрипта, което става, когато сте в таб Clustering (ще ви иска достъп и трябва да му дадете):
Следващата функция е намирането на теми за статии или друг тип текстове - трябва да кликнете на Questions и скриптът ще обходи цялата семантика и ще търси теми/заглавия за текстове (работи, когато семантиката е на български език):
Таб Custom Searching ще ви помогне да намерите по-бързо къде се намира даден клъстер (това може да ви спести още време, когато семантиката е огромна):
Функцията Clear изчиства всички стойности от таблицата:
Заключение
Чрез внедряване на автоматизацията значително се повишават скоростта и ефективността на обработката на семантичните ядра. Това, от своя страна, допринася за подобряване на организацията на съдържанието, увеличава релевантността му и, най-важното, спестява значително количество време. Въпреки автоматизацията, системата все още изисква лека човешка намеса за финални корекции на определени клъстери, за да се гарантира максимална точност и качество на обработеното съдържание.

 2
2
 2
2
 0
0