Как да възстановим трафика към важни страници на онлайн магазин с помощта на Web Archive
Какво е Web Archive и как ни помага в работата?
Web Archive е услуга, която позволява да проследим историята и промените във всеки сайт. Например, можем да проследим причините за различни отклонения в показателите на Google Analytics, трафик или потребителско поведение.
С този архив можете да видите стария дизайн на ваш или чужд сайт, да проверите мета данни, текстове, местоположение на бутони или да копирате дизайна на всеки един “мъртъв” сайт.
Интернет архивът е нестопанска организация, основана от Брустър Кале през 1996 г. в Сан Франциско. Услугата събира копия на уеб страници, графични материали, видео, аудио и софтуер, като предоставя събраните материали с дългосрочно архивиране и безплатен достъп до данни.
Съхранените материали станаха наистина достъпни за широката публика през 2001 г., когато стартира уебсайтът на Wayback Machine. Съдържанието на сайтове периодично се записва с помощта на бот на уеб архива. Също така, потребителите могат ръчно да посочат адреса на страницата, за да създадат копие от нея.>>
Web Archive е почти единствената възможност за възстановяване на сайт, освен ако не сте направили копие на базата данни (back-up).
В работата ни като SEO специалисти, ние използваме уеб архива с цел да възстановим URL адресите на категории и други важни страници.
Факт е, че собствениците или мениджърите на сайтове, които попълват каталога на онлайн магазин, не следят промяната на адресите на важните страници от сайта. В резултат на това те изчезват от индекса на търсачките, губят натрупаното доверие и тежест на връзката.
Как да възстановите адресите на страниците с помощта на Web Archive
Разбира се, можете да опитате да изтеглите страници от кеш-паметта на Google, но ако ресурсите не са налични от много дълго време, тогава мъртвите връзки се отварят само в archive.org.
Истината е, че има шанс да не успеем и там: ботовете на уеб архивите имат ограничени ресурси. Вероятността и честотата на обхождане на сайт с нисък трафик е изключително ниска. Но все пак си заслужава да се опита.
Алгоритъм за действие
Отворете уеб архива (archive.org) и въведете адреса на сайта в лентата за търсене.
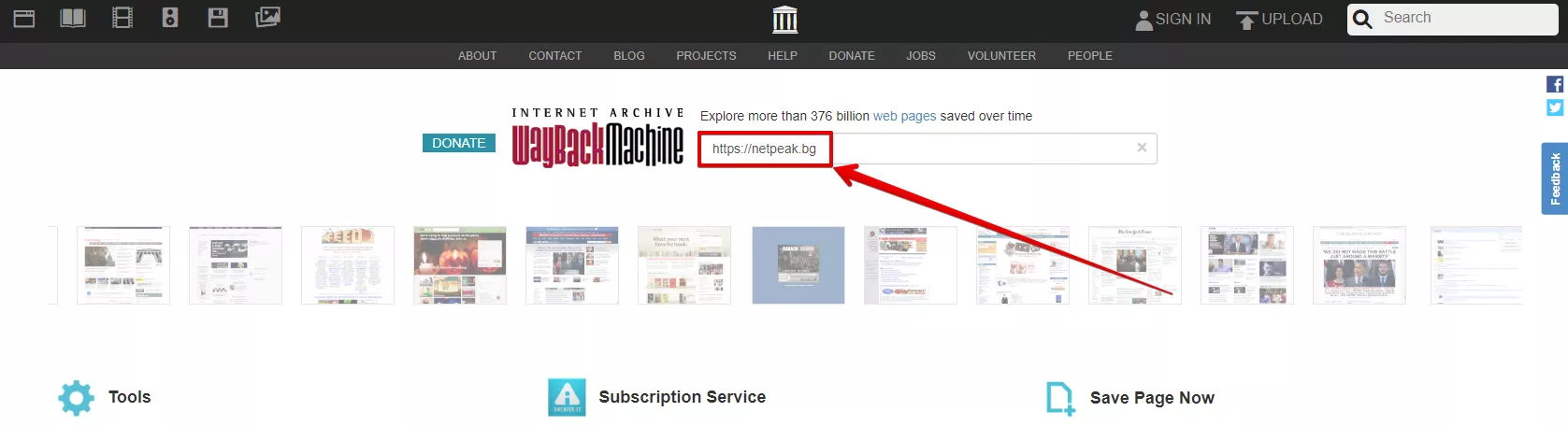
Ако сайтът е в уеб архива, препоръчваме ви да изберете няколко копия на сайта за различни дати в рамките на две години.
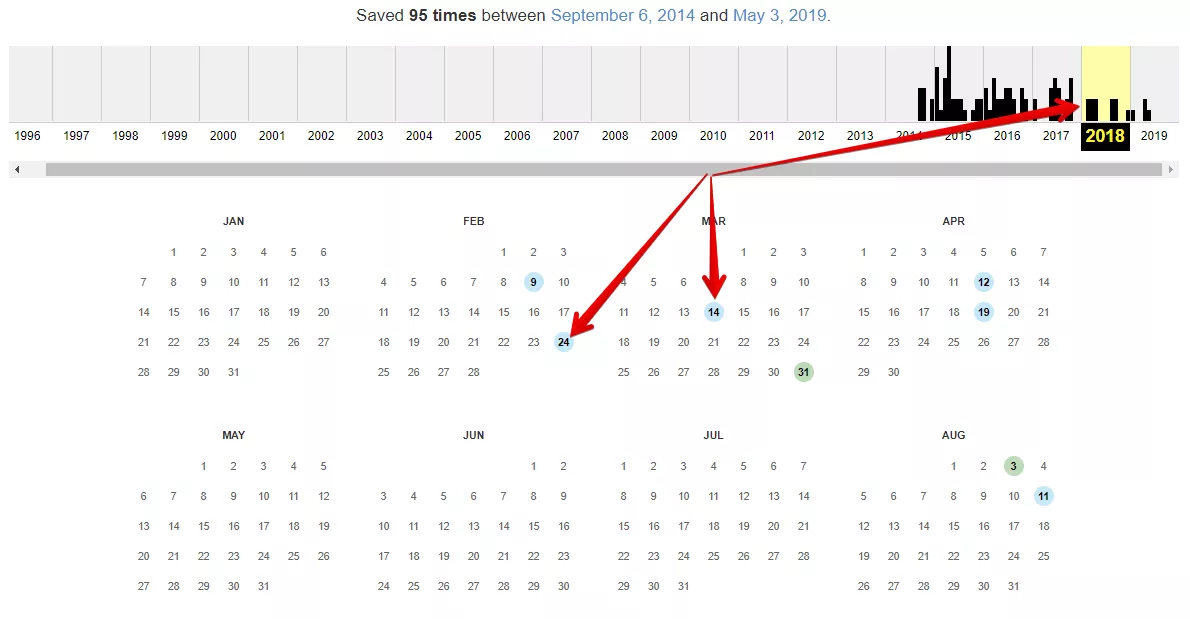
След като изберем дати, трябва да изтеглим адресите с помощта на Netpeak Spider или Web Scraper.
Как да изтеглите URL адреси с помощта на Netpeak Spider
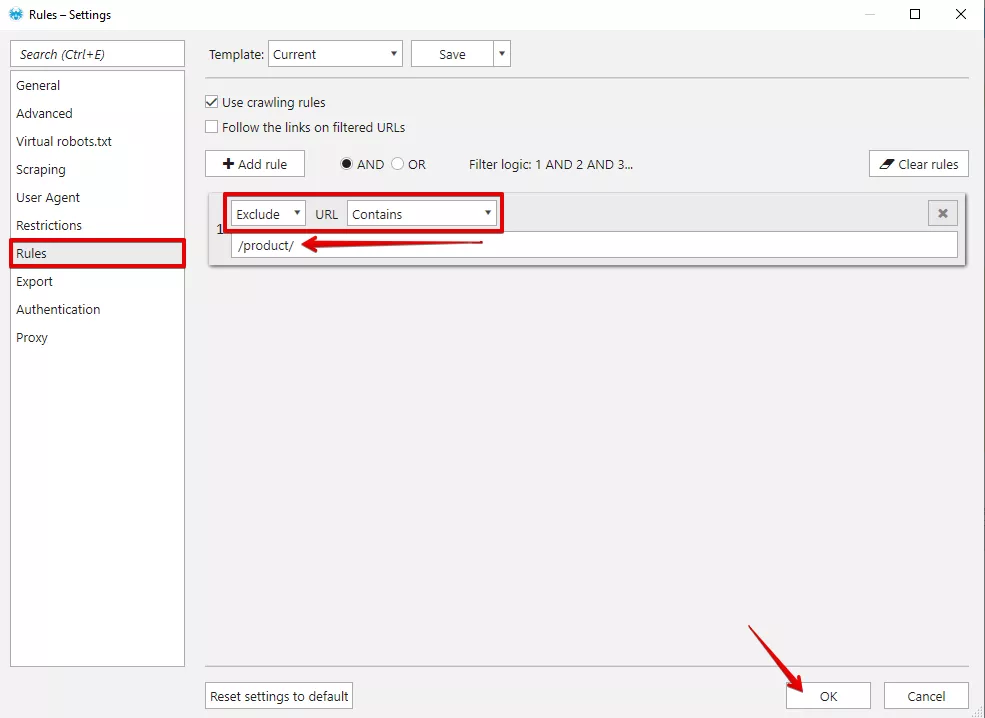
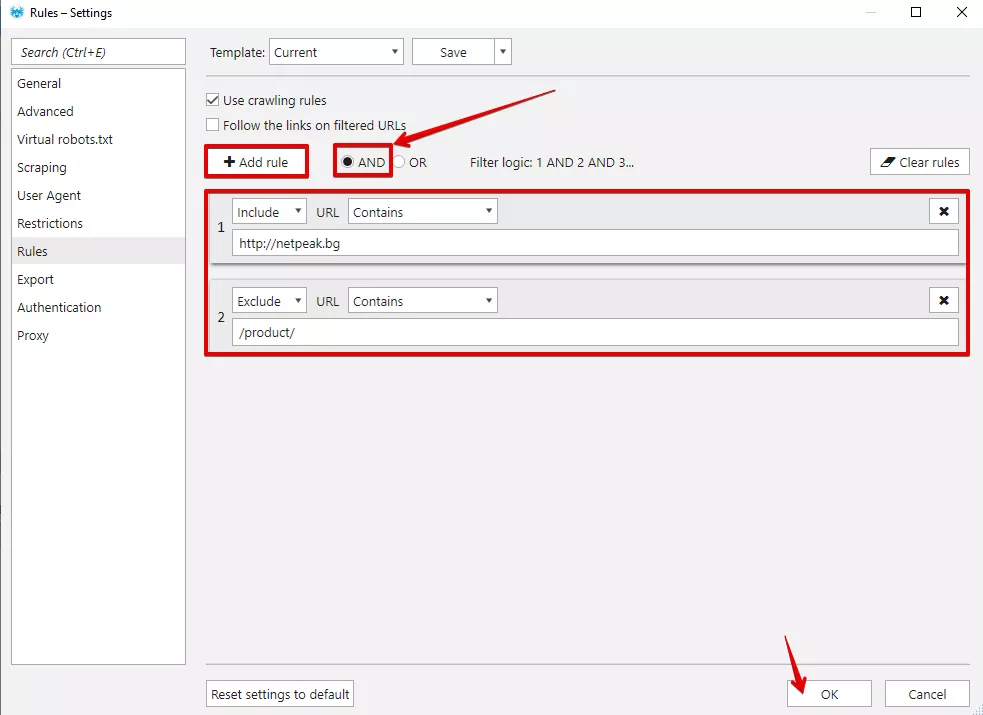
Посочете в Netpeak Spider директорията, която искате да сканирате. Необходимо е да зададем правила при обхождането. Правила задаваме от меню “Settings” - “Rules”. С тези правила можем да изключим възможността за обхождане на различни типове страници, например продукти.
Нека предположим, че всеки продукт от вашия сайт е с URL адрес, формиран по следния начин: https://domain.bg/product/url. В този случай задаваме следното правило:
Идва ред да сканираме и свалим URL адресите в табличен вид. Правим това за всяка дата отделно.

Ако посочите URL във формат http://web.archive.org/web/20140920235329/http://netpeak.bg/ в Netpeak Spider, трябва да посочите домейна на сайта, чийто URL адрес трябва да получите. Това се прави, за да не сканираме целия уеб архив и неговите страници за услуги:
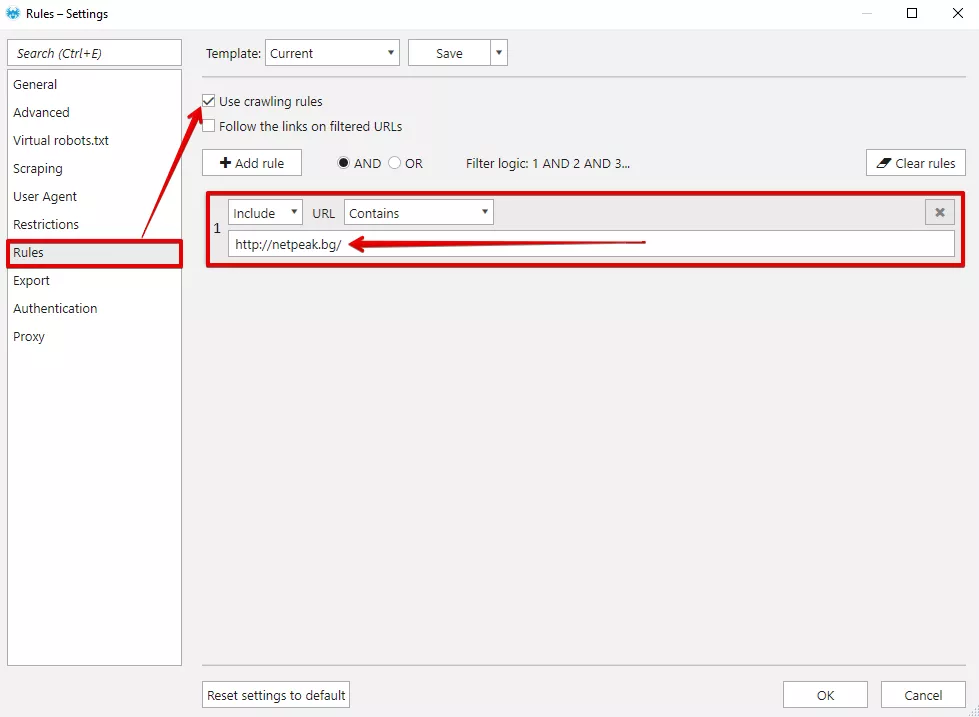
Скрийншотът съдържа настройки, с които ще обходим всички страници от стария сайт.
Ако желаем да изключим продуктовите страници е необходимо да комбинираме 2 правила с логика на филтъра “AND” - това означава, че при сканирането на дадения сайт ще се обходят страници, съдържащи http://netpeak.bg, но в които не се съдържа /product/.
След сканиране получаваме таблицата:
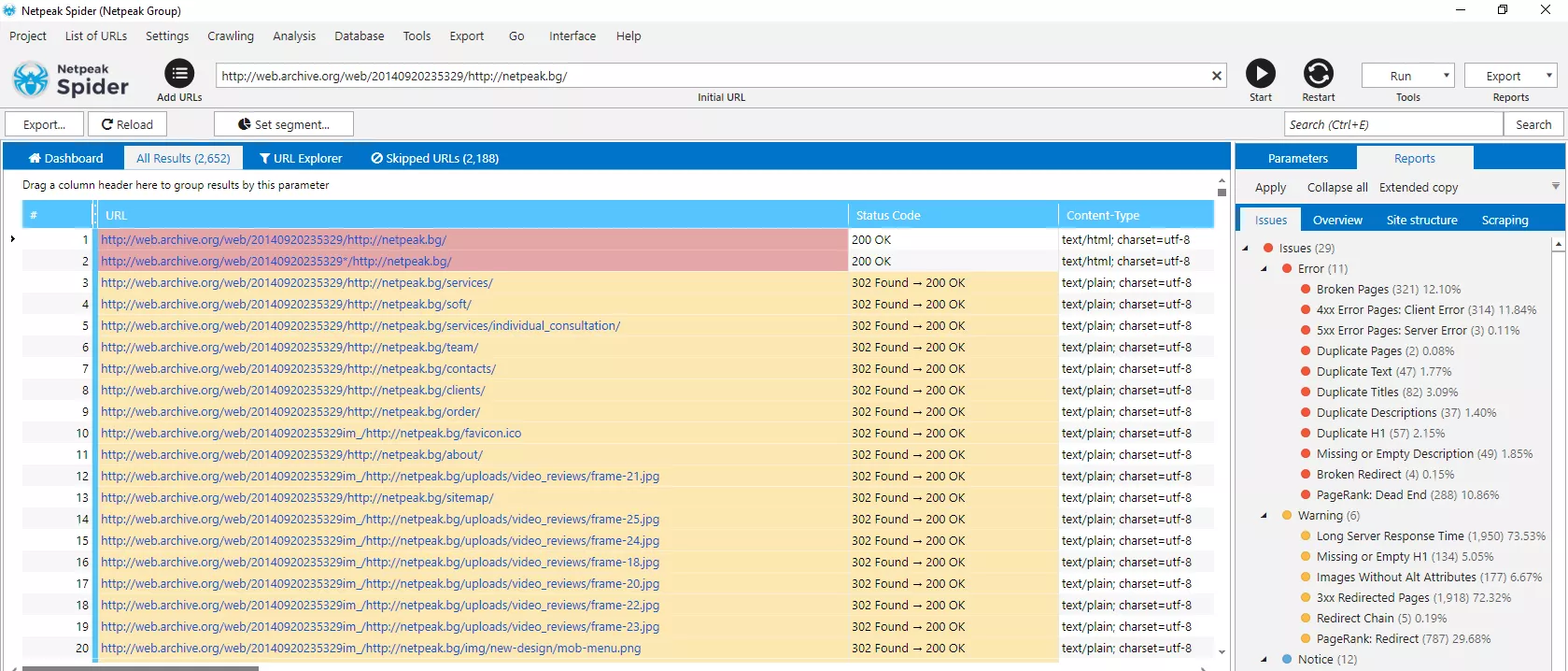
Вече разполагате с всички важни адреси от старата версия на даден сайт.
Как да изтеглите URL адреси с помощта на Web Scraper
Изтеглете приставката за Chrome - Web Scraper. Отворете уеб архива, изберете желаните дати и намерете HTML картата на сайта (обикновено се намира във footer частта).
Натиснете Ctr + Shift + I, за да се покаже конзолата за програмисти. Това се прави целенасочено на страница, при която кодът на сайта съдържа всички необходими URL адреси. След това изберете Web Scraper - “Create Sitemap”.
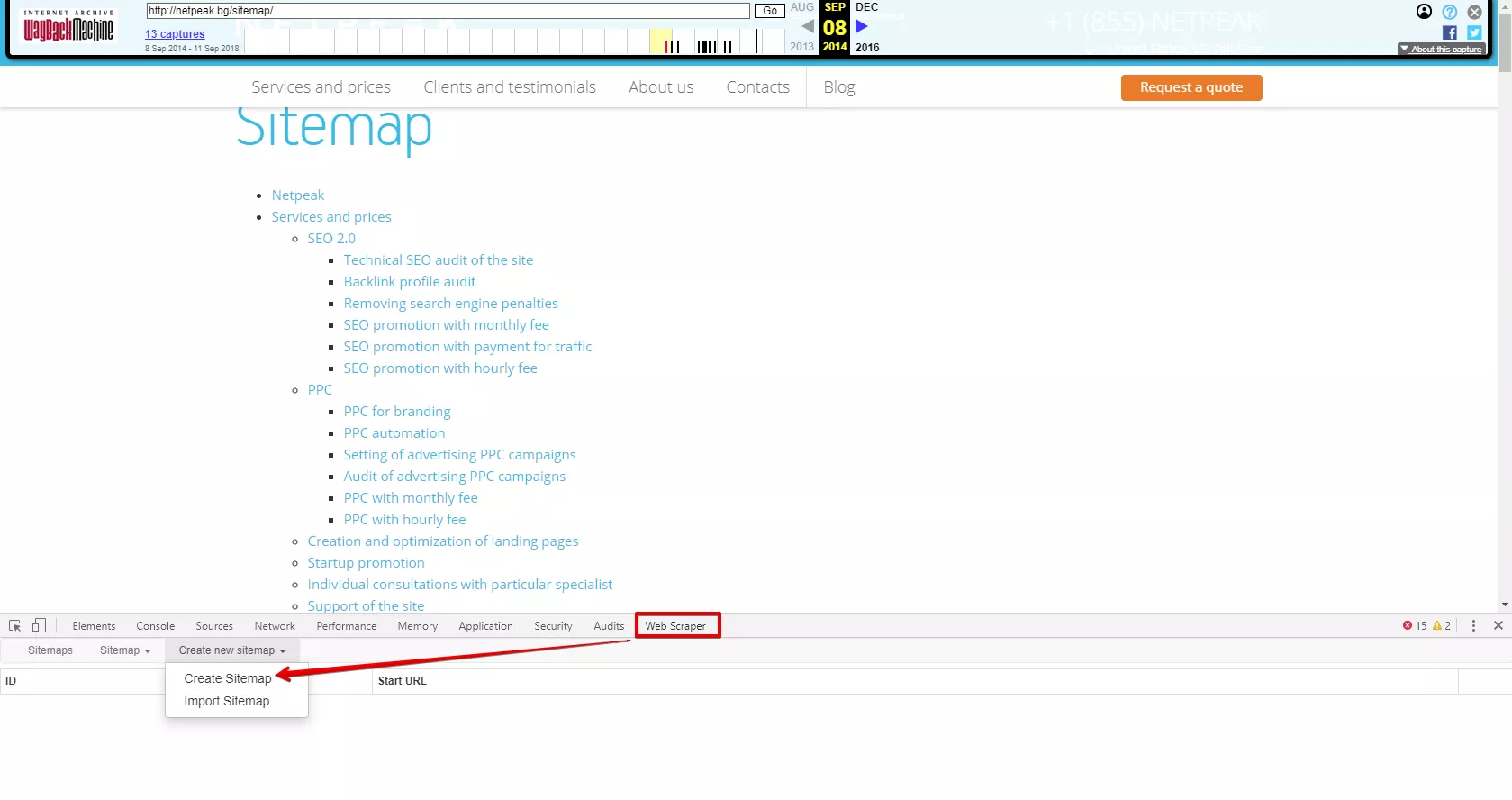
Задайте наименование и началния URL адрес на сканирането:

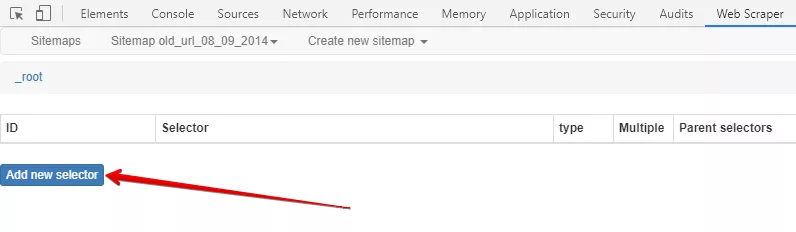
Добавете нов селектор:
За селектора посочете име (Id), изберете типа селектор (Type) - Link, щракнете върху "Select" и маркирайте всички необходими линкове. Ако изберете повече от две връзки, автоматично се генерира общ селектор.
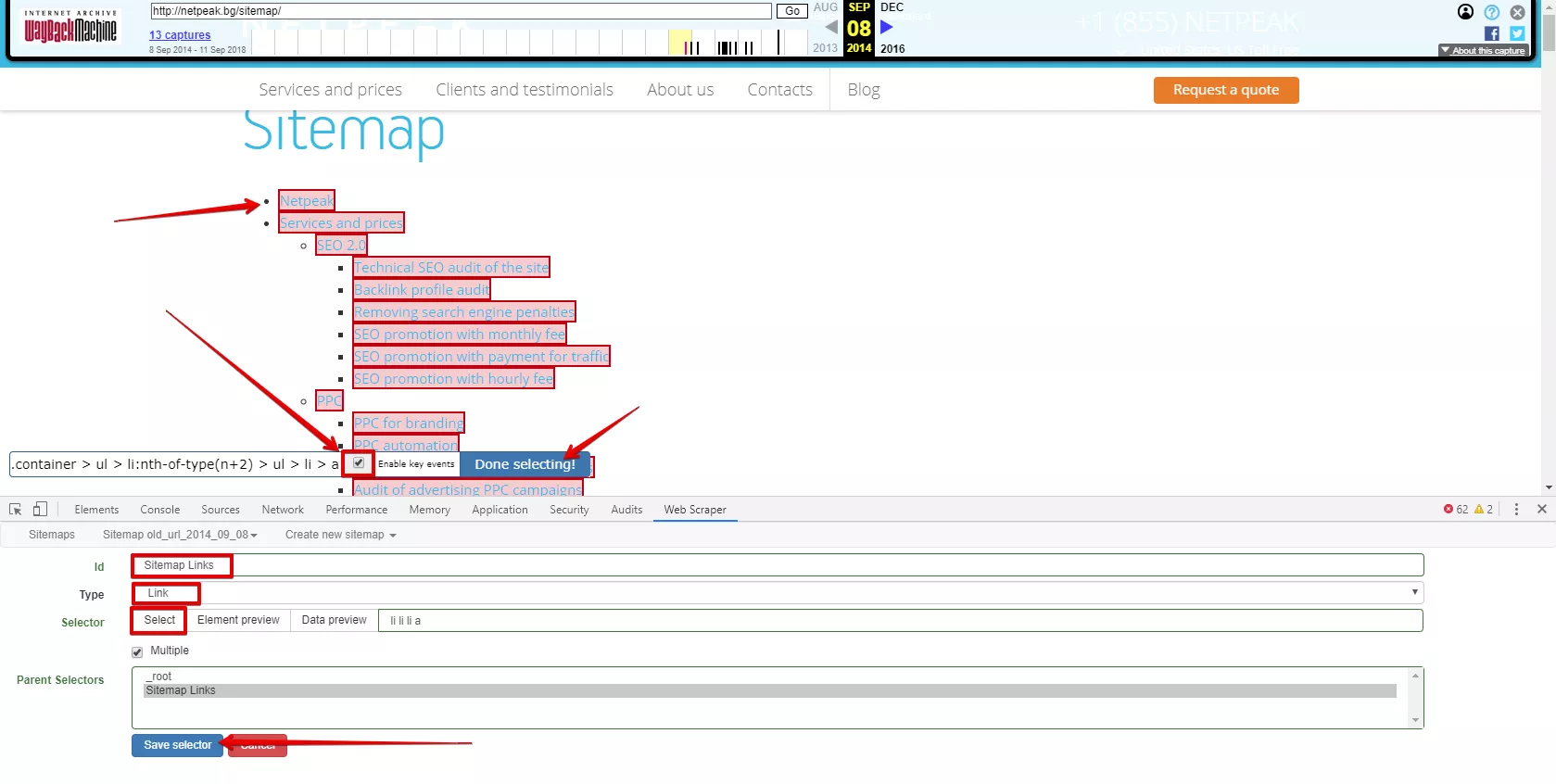
Кликнете върху „Done Selecting“ и „Save Selector“. Когато всички необходими селектори са създадени, стартирайте Web Scraper:

Свалете полученият списък с резултати:
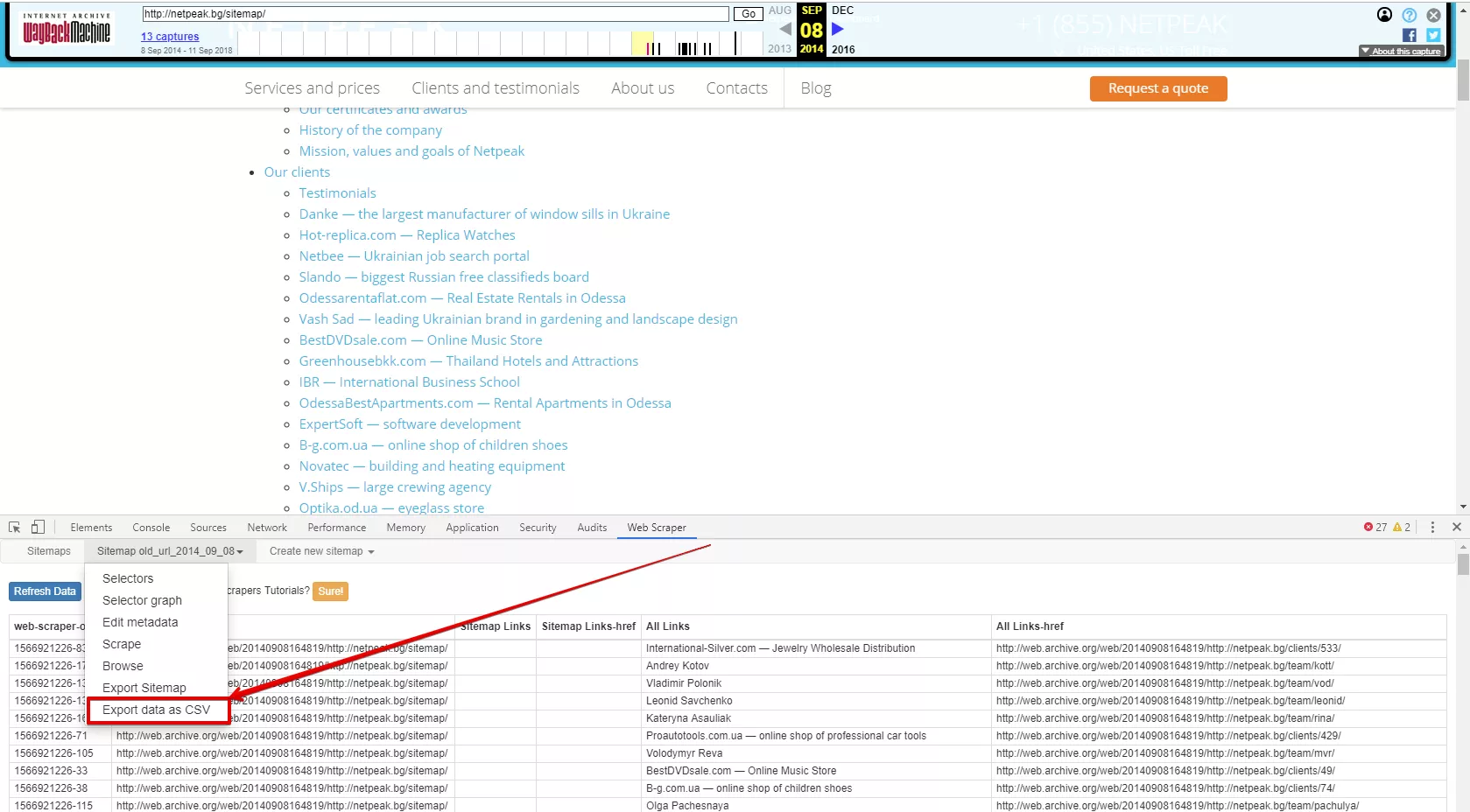
Важно: ако не се заредят резултати е необходимо да натиснете “Refresh”.
След получаване на списък с URL адреси е необходимо да премахнем ненужната информация, използвайки заместване или регулярни изрази. Препоръчваме да го направите с Google Sheets, Excel или Notepad++.
Защо: защото в списъка получаваме URL адреси във формат - https://web.archive.org/web/*/http://netpeak.bg/url . Трябва да ги приведем във вид - http://netpeak.bg/url .
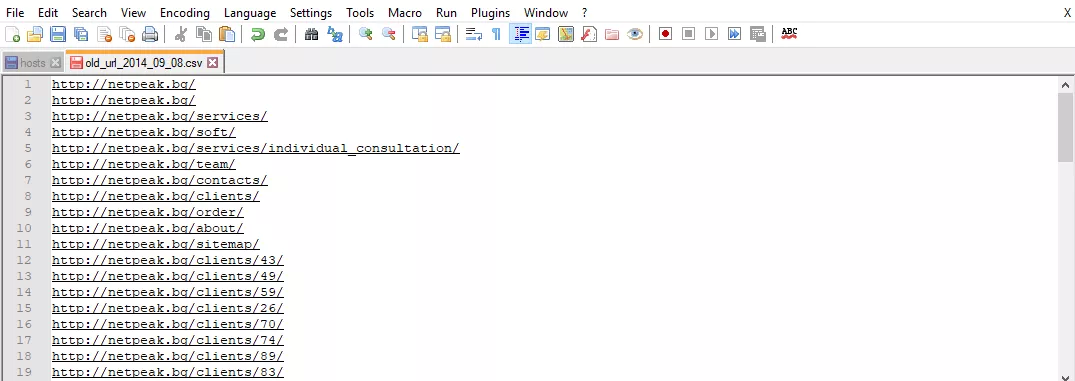
Подготовка на URL адреси за пренасочвания
Необходимо е да заредим получената база данни в Netpeak Spider или негов аналог. След това сканираме URL адресите, за да проверим техния код на отговор на сървъра. Ако страницата връща код 200 OK или пренасочва към страницата с код 200 OK, всичко е наред и нищо не трябва да се прави с този URL адрес.
При наличие на страници връщащи код 404, проверете дали всички URL адреси в този списък са уникални и не се повтарят. Има възможност да са били изтеглени URL адреси за няколко дати и да се получат дублажи.
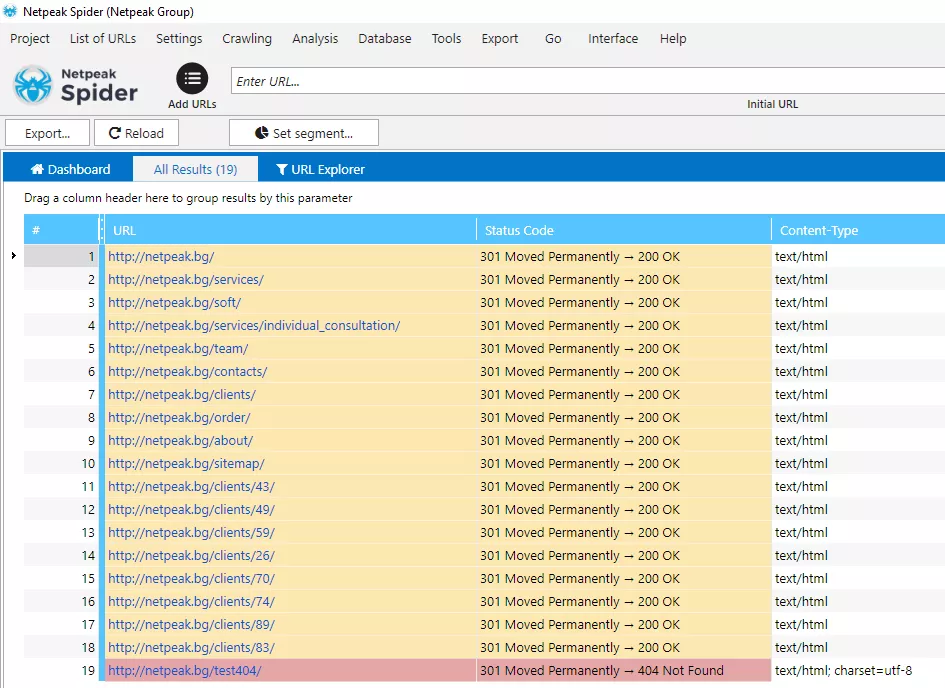
Вече можем да изпратим списъка с URL адреси към програмистите, за да настроят пренасочванията.
Ако не разполагате със софтуер за обхождане на URL адреси, можете да се възползвате от безплатния инструмент за проверка на отговора на сървъра - Soft.Galinov. Единственият недостатък е, че трябва да извършите проверка на всеки URL адрес поотделно.
Заключение
Често трафикът претърпява спад поради премахването на важни страници или промяна на URL адресите. Анализът на данните от уеб архива не отнема много време, но ви позволява да запазите или възстановите трафика.
Алгоритъмът е прост:
- Откриваме сайта в уеб архив.
- Подбираме няколко копия на сайта за различни дати в период 2 години.
- Сваляме адресите чрез Netpeak Spider или Web Scraper.
- Подготвяме базата данни с URL адреси за настройка на пренасочвания.
- Предоставяме на програмиста списък със стари и нови URL адреси, които са готови за настройка на пренасочвания.

 42
42
 3
3
 5
5