Как организирахме SEO текстове за почти 1000 категории
Дали животът на проект мениджърите би могъл да бъде обобщен в таблица? Вероятно да. А ние в Netpeak просто сме пристрастени към тях. В следващите редове ще ви покажем още нещо, което успяхме да систематизираме чрез таблица: организацията на близо 1000 категорийни текста. Идеята беше с един поглед да може да се разбере за колко категории има написан и качен текст, за колко няма и за колко предстои. В статията ще научите и как да:
- Обходите сайт с Netpeak Spider, така че инструментът да покаже резултати само за определен тип страници.
- Как да изключите от резултатите страници с get параметри.
- Как да извлечете заглавията/подзаглавията от дадените страници.
- Как да филтрирате и организирате тази информация в таблица.
Казусът
През последните няколко години сме написали стотици SEO текстове за наш клиент, както и още няколкостотин задания за текстове, за които все още нямаме написани текстове. За съжаление нямахме събрана и структурирана информация в кои категории имаме качен текст, за кои имаме задание за текст и за кои нито едно от двете. Тази информация беше разхвърляна в десетки задачи и таблици, а нашата цел беше да я имаме синтезирана занапред, и да може да следим този процес по-ефикасно.
Как го направихме
1. Намерихме и организирахме страниците със задание за SEO текст
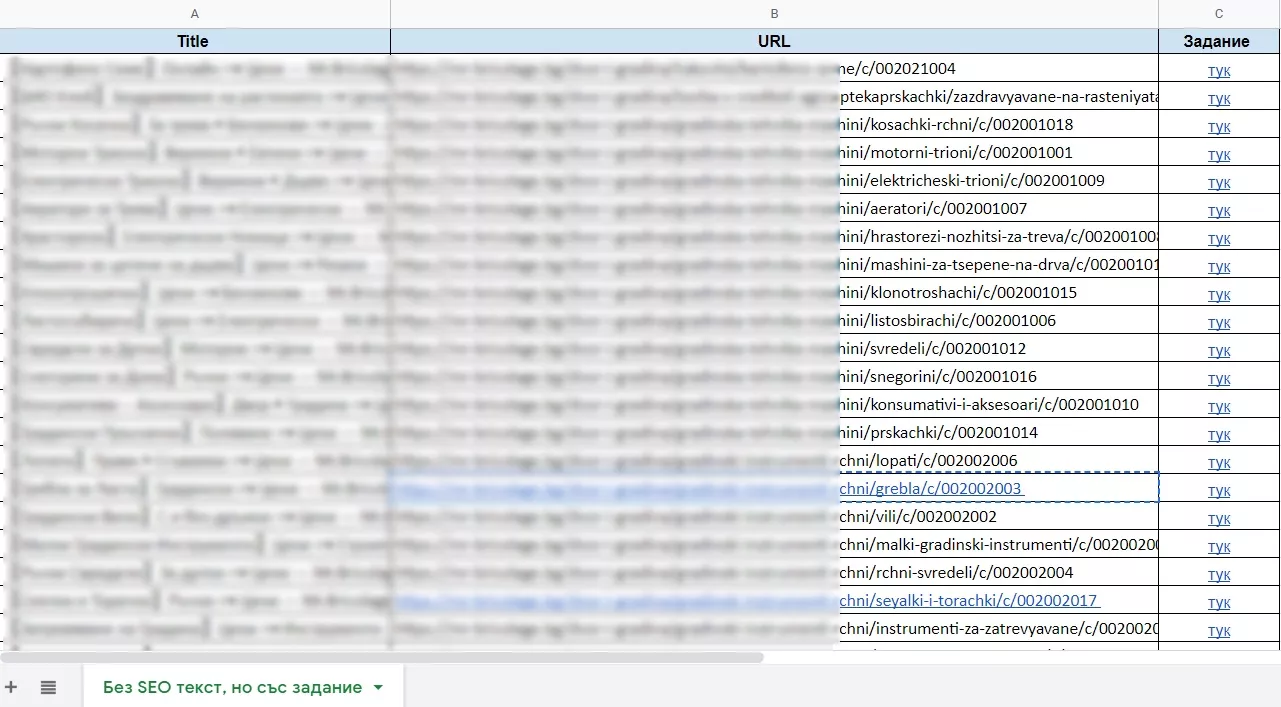
Първо, започнахме с намирането на всички готови задания, по които няма написани текстове, от различните задачи и таблици, които са изготвени през годините. След намирането им започнахме да ги организираме в таблица, в която изкарахме title (за по-лесно ориентиране коя е категорията), URL и линк към заданието за текст:
2. Намерихме и извлякохме категориите със и без SЕО текст
Тук стъпките са няколко:
2.1. Искахме инструментът да ни изкара информация само за определен тип страници, а не за всички типове. В случая - само категорийни страници от 1-во, 2-ро и 3-то ниво на вложеност. В този сайт всички категорийни страници съдържат “/c/” в своя URL, което ние използвахме. Настройките са следните:
Отваряме Netpeak Spider или друг crawling инструмент и достъпваме опциите за обхождане, които в случая са в раздел “Rules”.
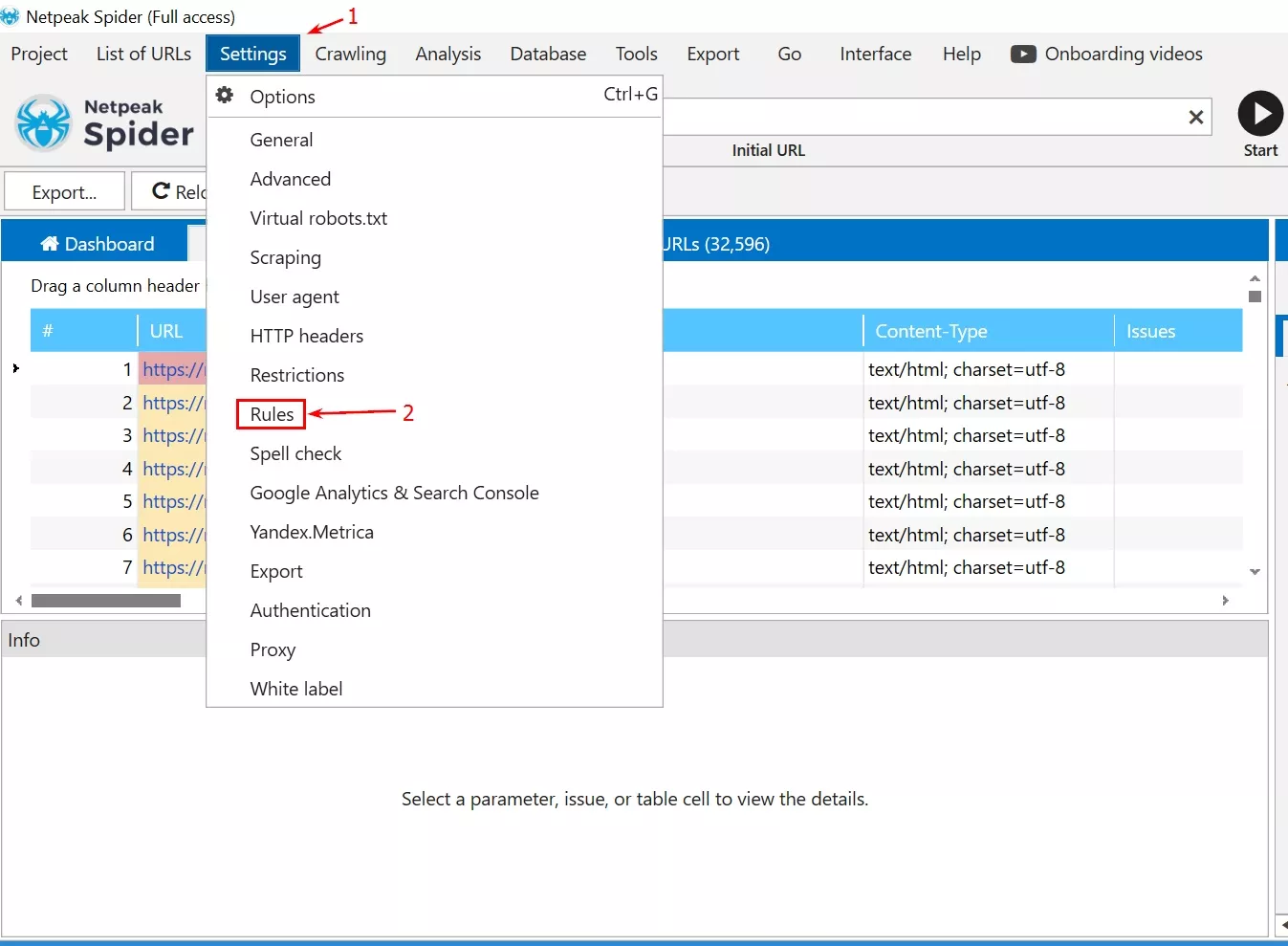
Важно е избраните опции за правилото да са:
- Include - за да включва/визуализира исканите от нас адреси, а не да изключва (exclude);
- Matching RegExp - за да ориентираме инструмента, че това е регулярен израз, а не Xpath например;
- логика на филтър “AND” - така инструментът ще спазва и двете правила, които ще въведем.
2.2. Въвеждаме регулярен израз - .*/c/.* - , за да може инструментът да ни изкара резултати само за страници, които съдържат “c” в своя URL адрес. По този начин ще се сдобием с адресите на всички категории.
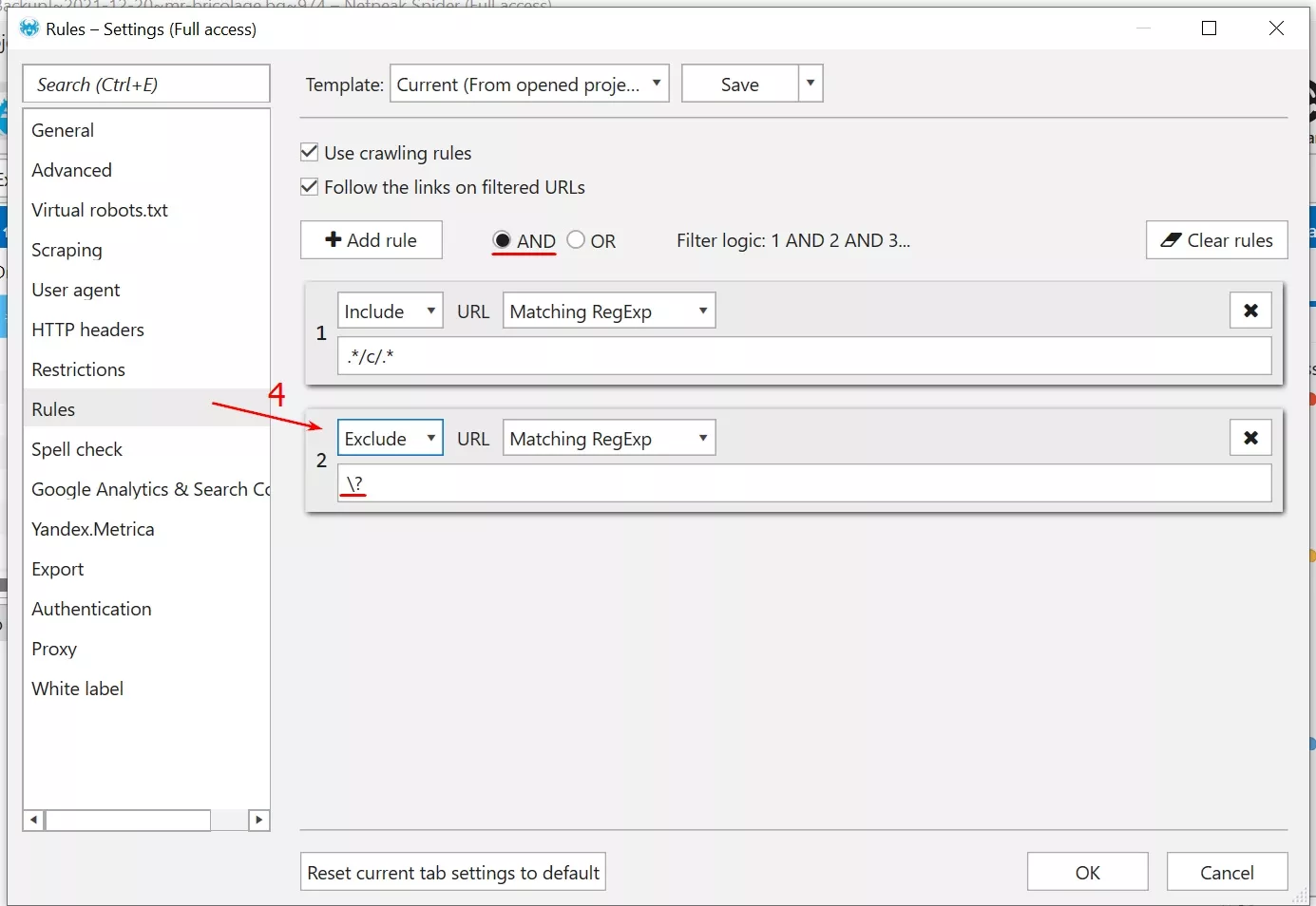
3. Добавяме второ правило от “Add rule” и въвеждаме регулярен израз - \? -, за да изключим всички категорийни страници с get параметри от сортиране, странициране, UTM и други. Тук е важно избраното правило да е - Exclude - за да изключва, а не да включва въпросните адреси. Всички останали стъпки остават същите.
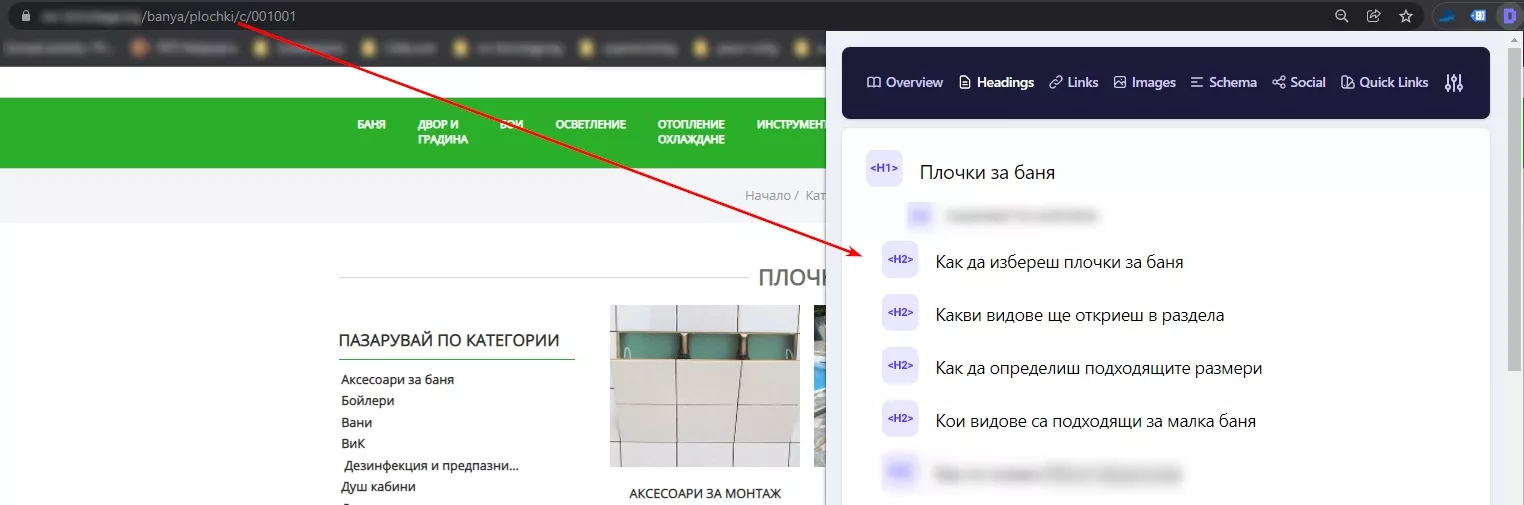
След като въведем правилата за обхождане на исканите от нас страници, идва ред и на въпроса как да разберем дали на тези страници има SEO текст или не? Това ще направим с помощта на XPath* и филтър в Netpeak Spider. В нашия случай на страниците, на които имаме SEO текст, присъстват минимум два елемента H2, а на категорийните страници без SEO текст този елемент пръства само веднъж - във футъра (не е по наше задание/желание :D).
Категорийна страница с SЕО текст
*XPath се определя като XML път. Това е синтаксис или език за намиране на всеки елемент в уебстраницата чрез използването на XML път.
XPath се използва за намиране на местоположението, на който и да е елемент в уебстраницата, като се използва DOM (Document Object Model) структурата на HTML. Той съдържа пътя до елемента, разположен в уеб страницата.
Категорийна страница без SEO текст
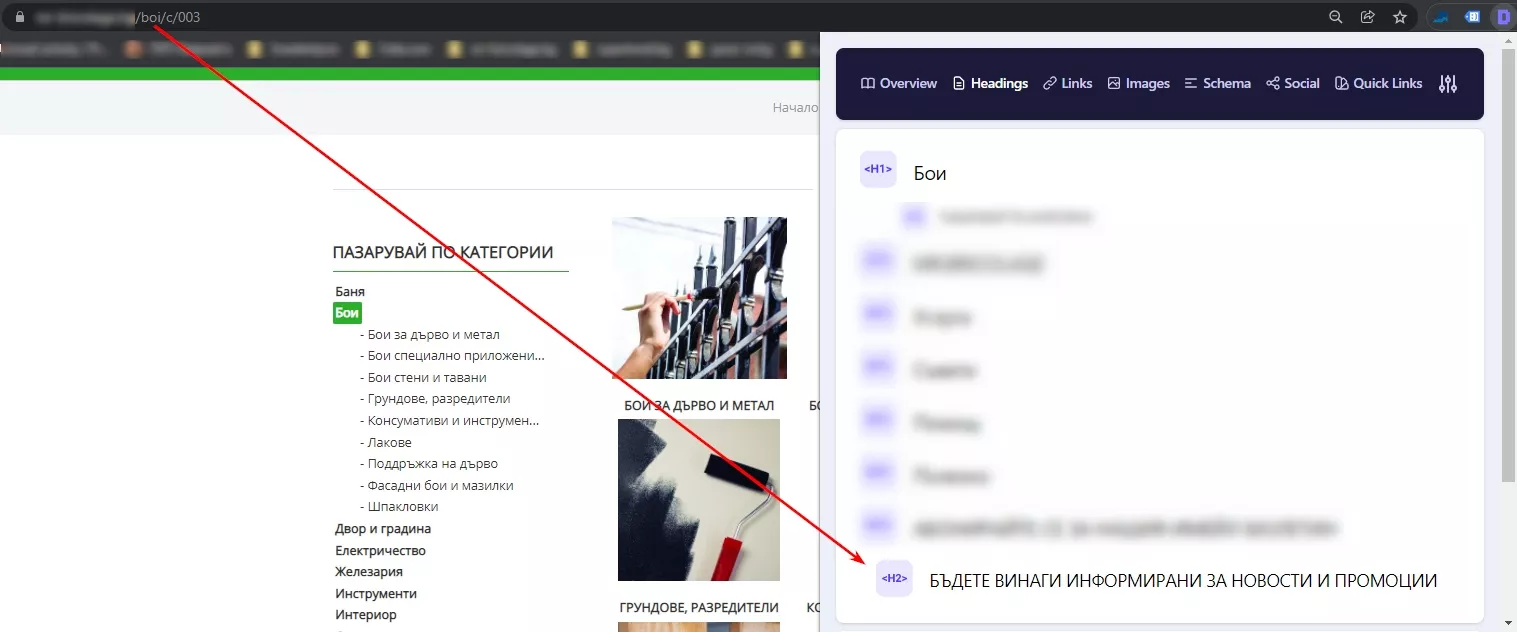
Поради тази причина избрахме подход с извличането/парсенето на всички H2 на страницата и филтрирането им след това. Правим го по следния начин:
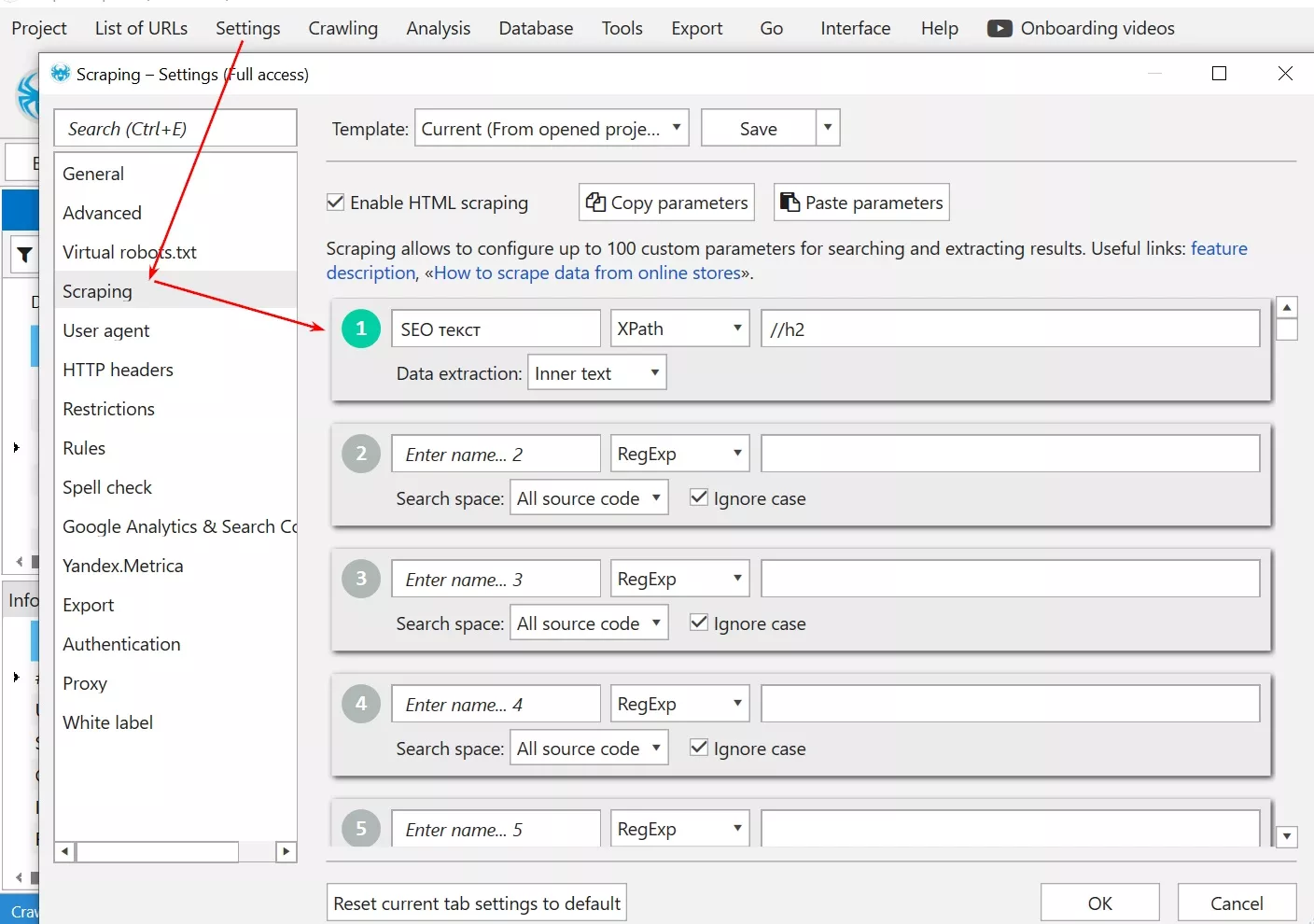
- Поставяме универсален Xpath - //h2 - за извличане на всички H2 в Settings > Scraping на Netpeak Spider и потвърждаваме промените, натискайки “ok”.
2. Вече сме готови с всички настройки и можем да поставим домейна на уеб сайта и да започнем обхождането на сайта.
3. След като обхождането на сайта приключи, отиваме в блок “Scraping” и натискаме два пъти върху “Found”.
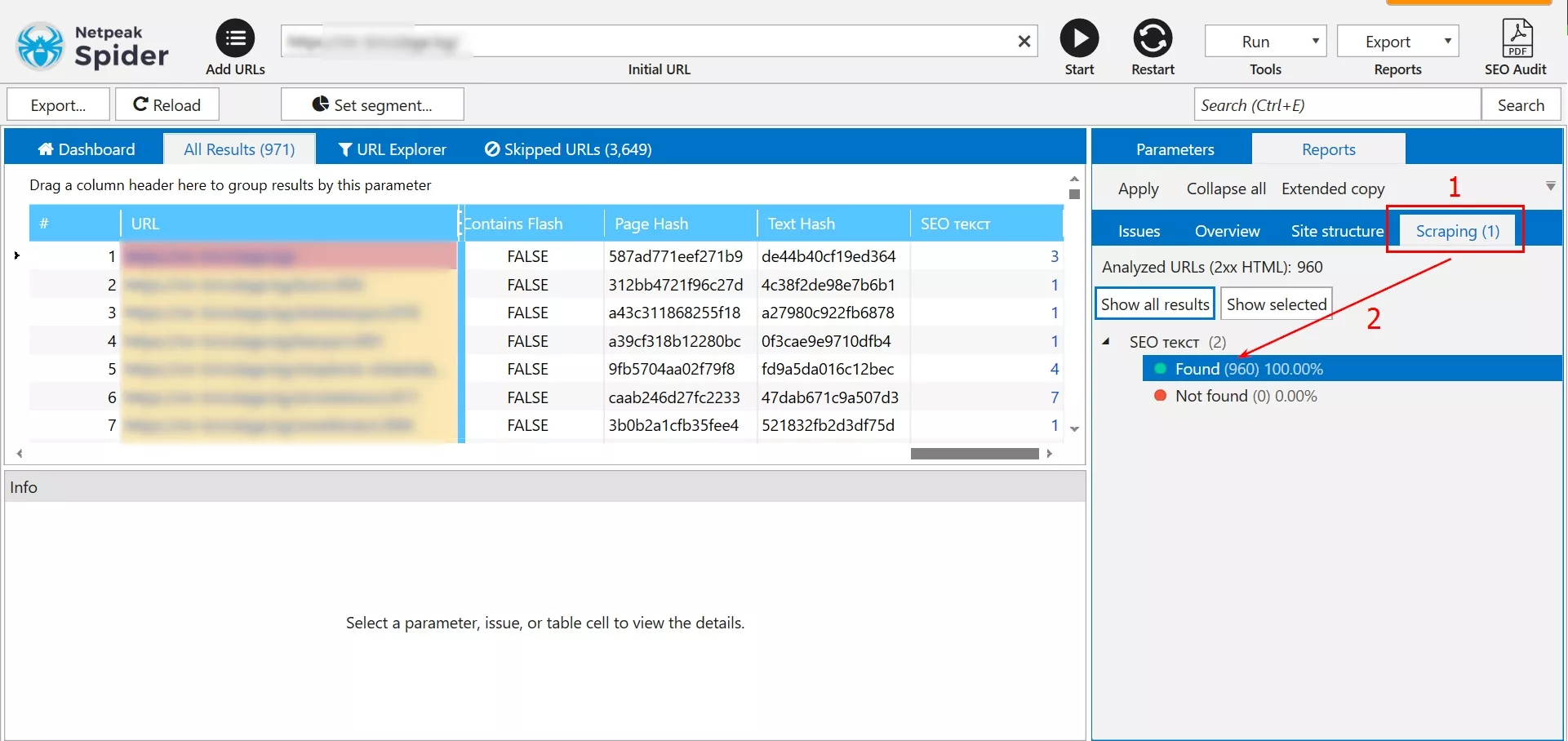
4. Редактираме филтъра по подразбиране, за да извлечем адреси, които имат повече от един H2. Тази филтрация може да бъде направена и в Google Sheets, но ще покажем как се прави в Netpeak Spider.
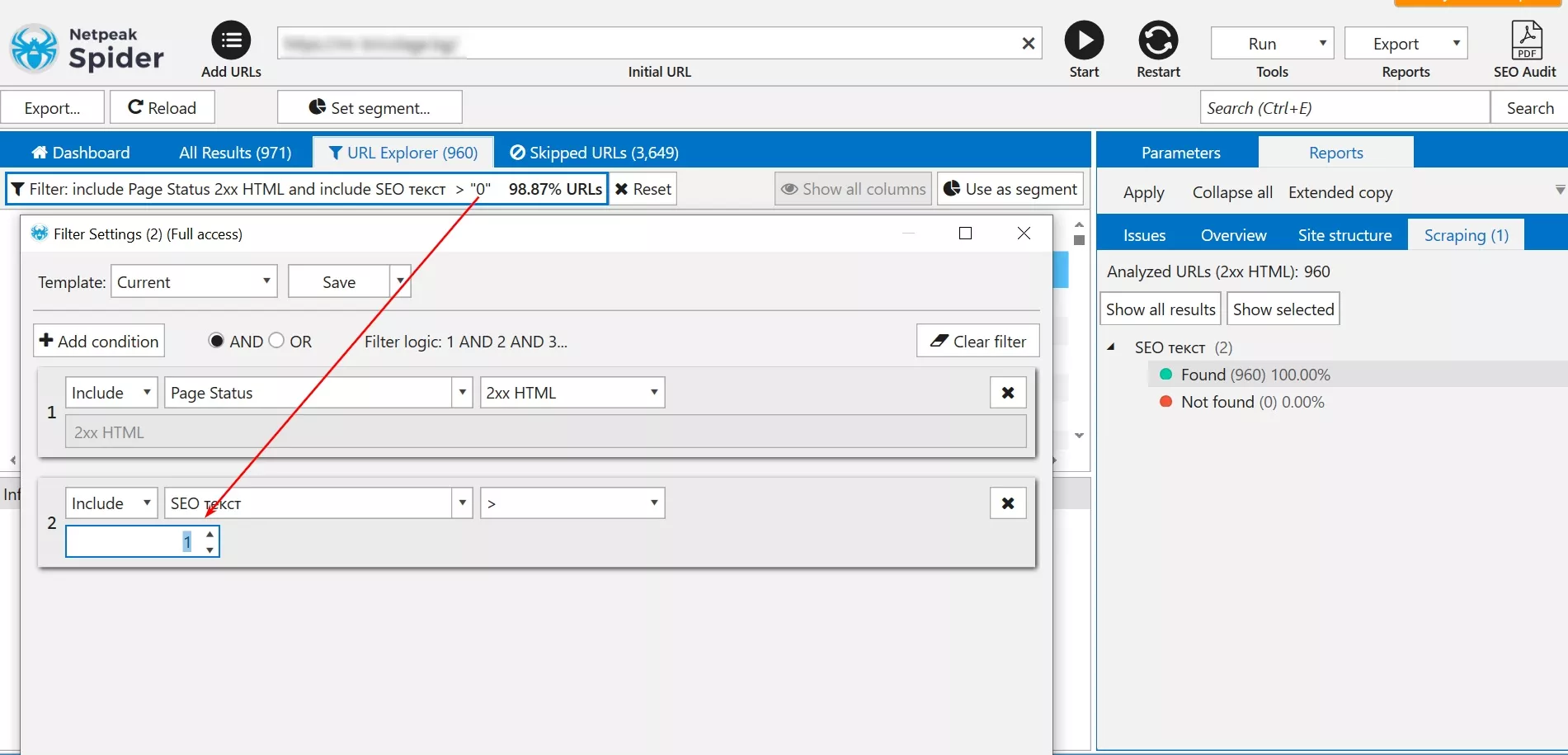
5. Както можем да видим, адресите намаляха драстично и сме готови да ги извлечем, за да продължим организирането им в таблица.
6. В таблицата вече имаме един таб за текстовете без SEO текст, но с готово задание за такъв. Сега следва да направим втори таб “С SEO текст”. Копираме адресите + title от файла/таблицата, която изтеглихме от Netpeak Spider, и ги поставяме в таб “С SEO текст” на главната таблица. Трябва да изглежда така:
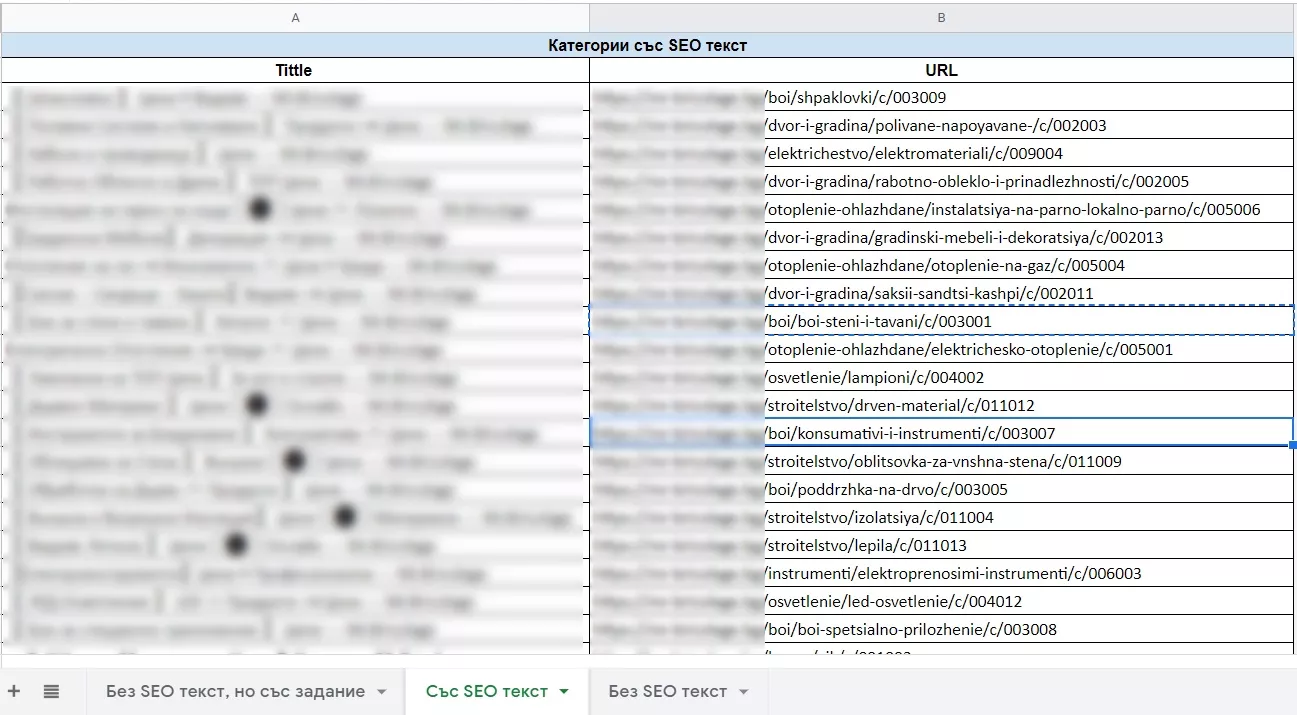
Вече имаме всички категорийни страници с текст и без текст, но със задание.
Остава да организираме категорийните страници без текст и без задание. Това ще направим по следния начин:
- Връщаме се в Netpeak Spider. Филтрираме и изтегляме всички адреси с по-малко от два H2:
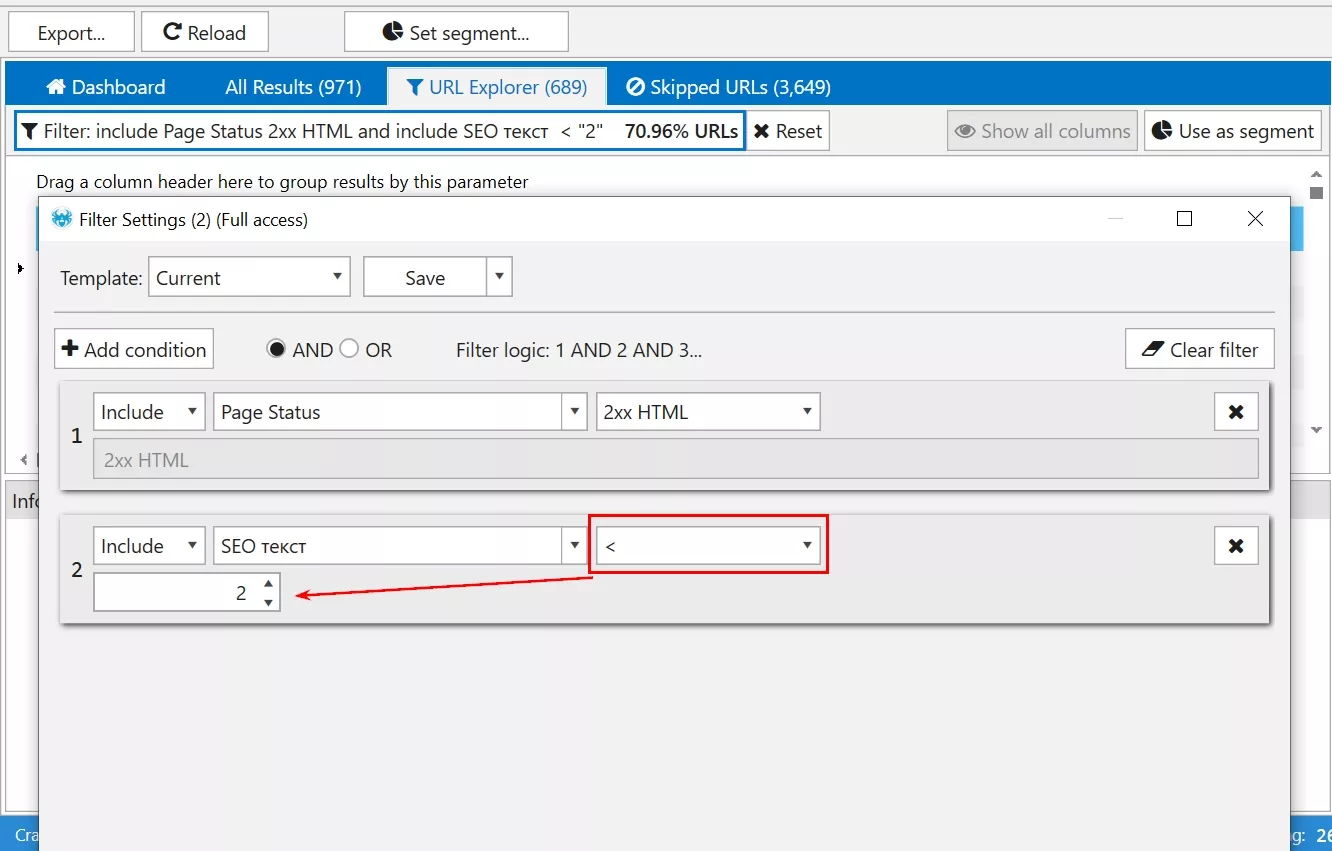
2. Поставяме адресите + title в таб “Без SEO текст” на първоначалната таблица:
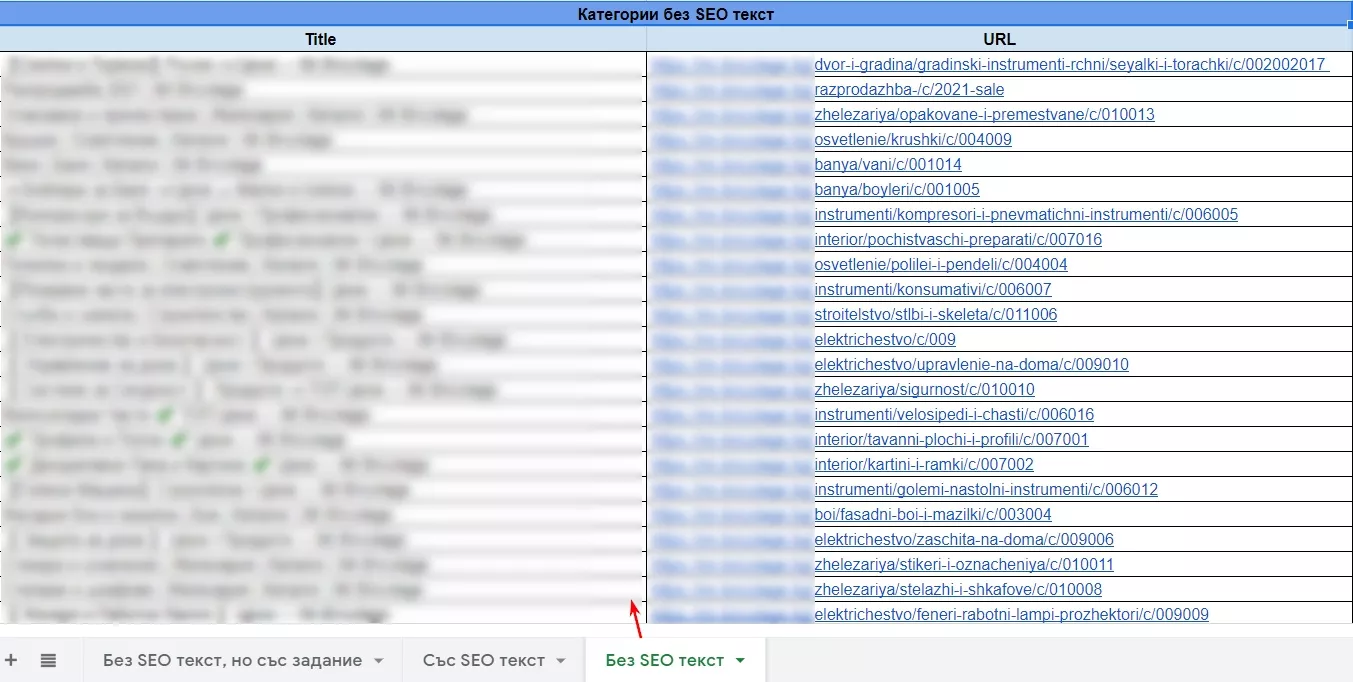
Вече имаме 3 таба в таблицата и сме почти готови - остава само един малък детайл. Адресите в таб “Без SEO текст, но със задание” присъстват и в таб “Без SEO текст” и трябва да ги изчистим. Правим го по следния начин:
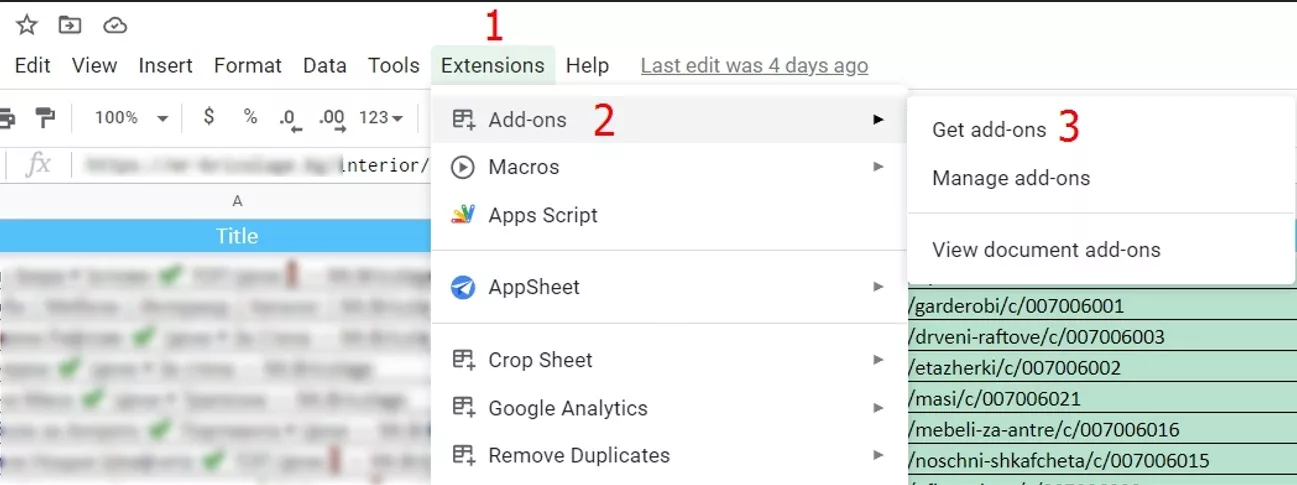
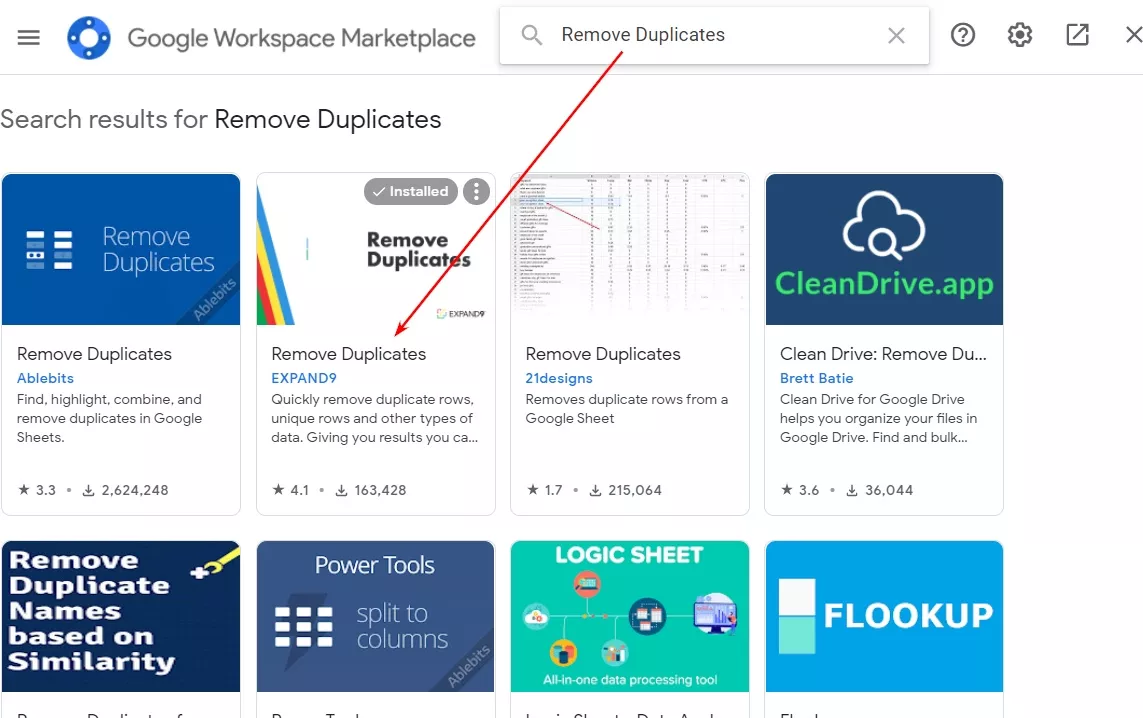
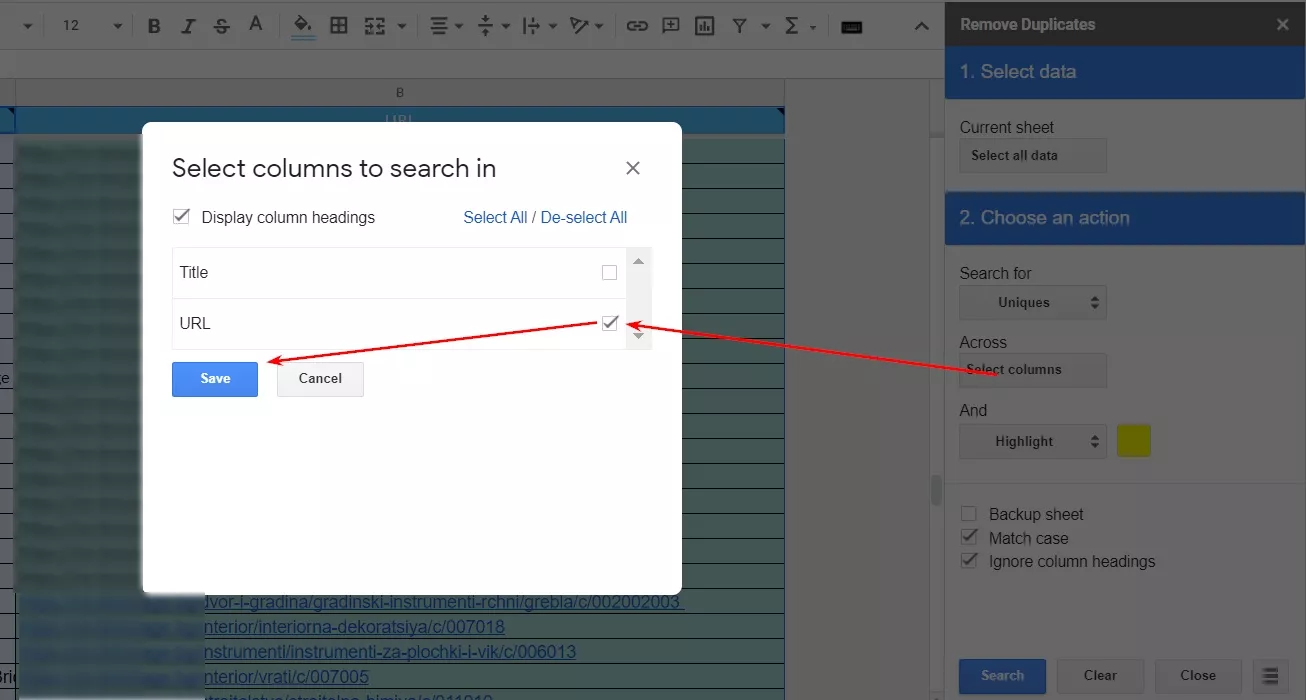
2.1. Инсталираме адон (add-on) за премахване на дубликати. В този случай ще покажем как да се премахват дубликати с адона на “EXPAND9”. Няма значение кой точно ще изберете, тъй като всички са доста интуитивни и лесни за работа. Съветваме ви да изберете от тези с най-висок рейтинг и изтегляния.
2.2. Копираме всички адреси от таб “Без SEO текст, но със задание” и ги поставяме в таб “Без SEO текст” под адреси, които вече имаме в този таб.
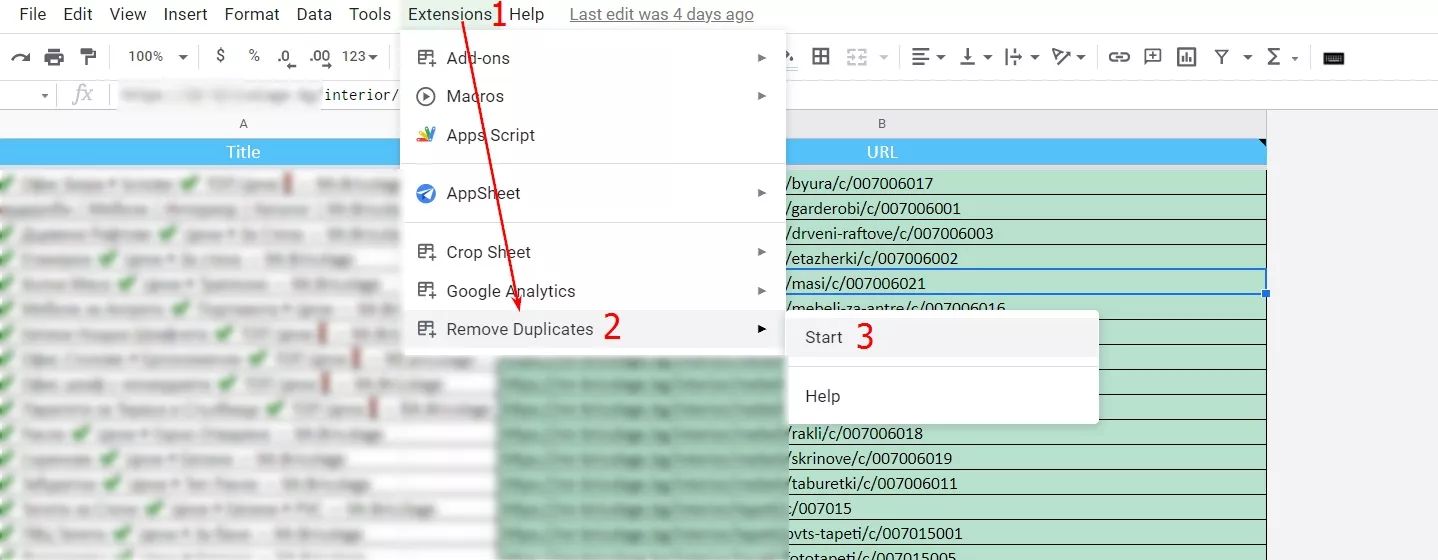
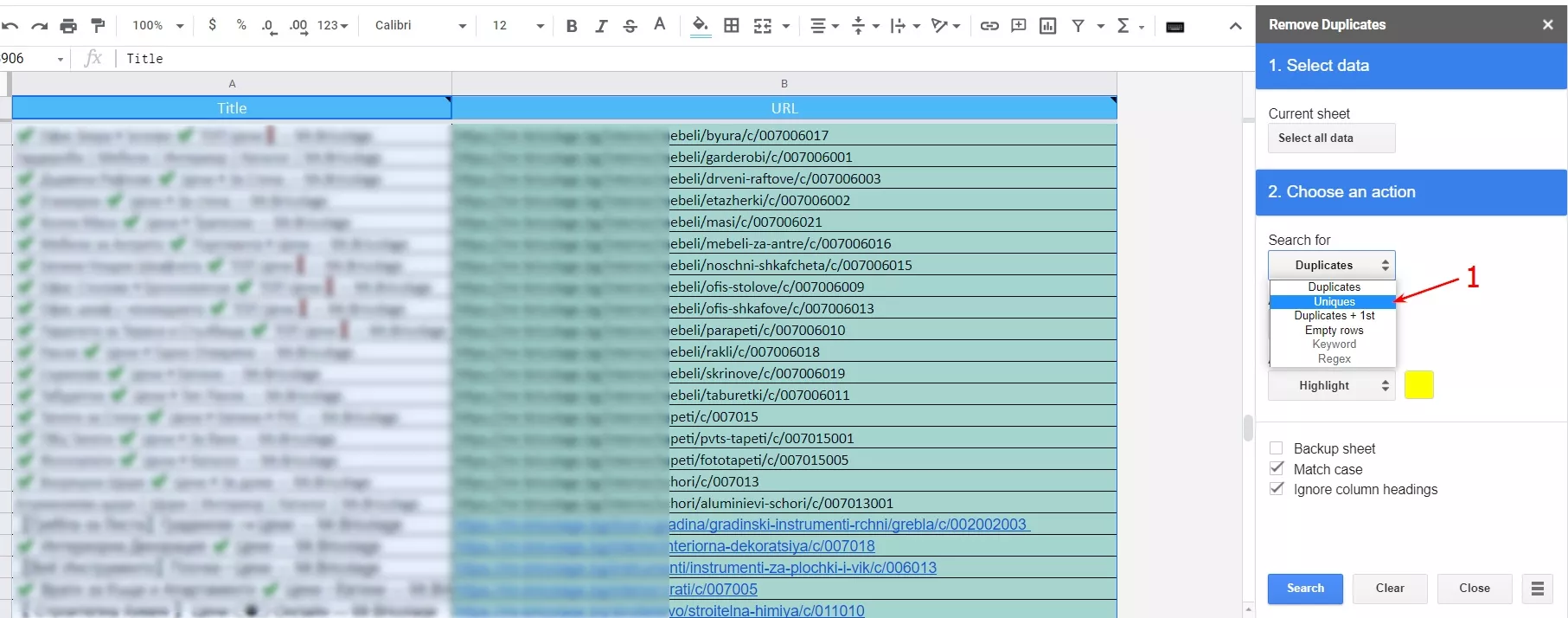
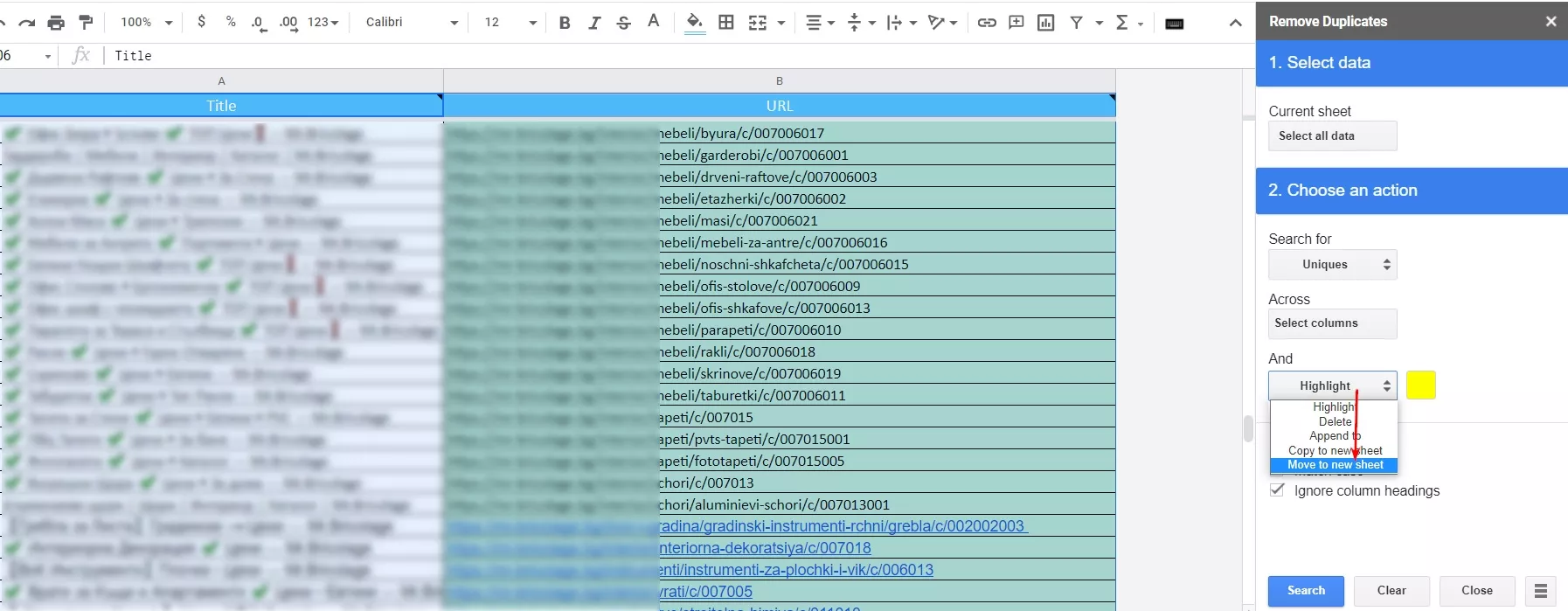
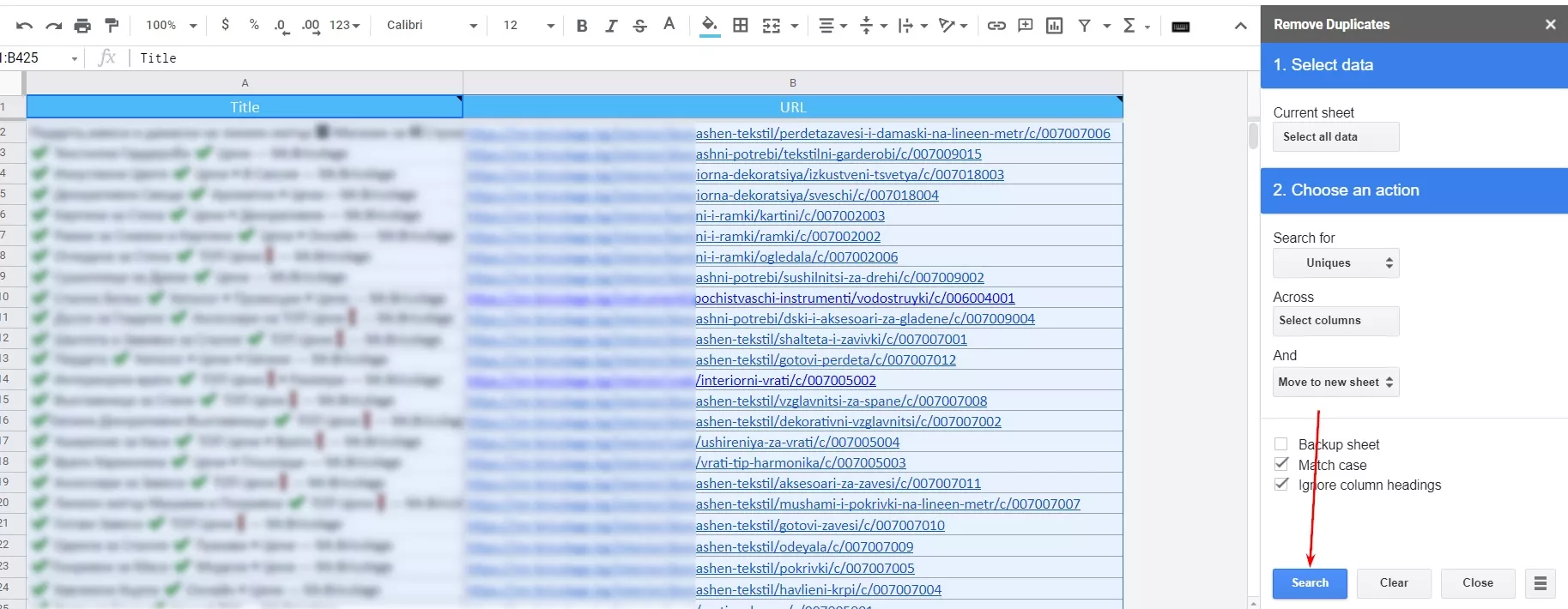
2.3. Активираме адона и в настройките задаваме да ни изкара всички уникални адреси от колона “URL” в нов таб.
И сме готови!
Можем да изтрием стария таб “Без SEO текст” и да преименуваме така новия таб, който създадохме, с всички уникални категорийни страници без SEO текст.
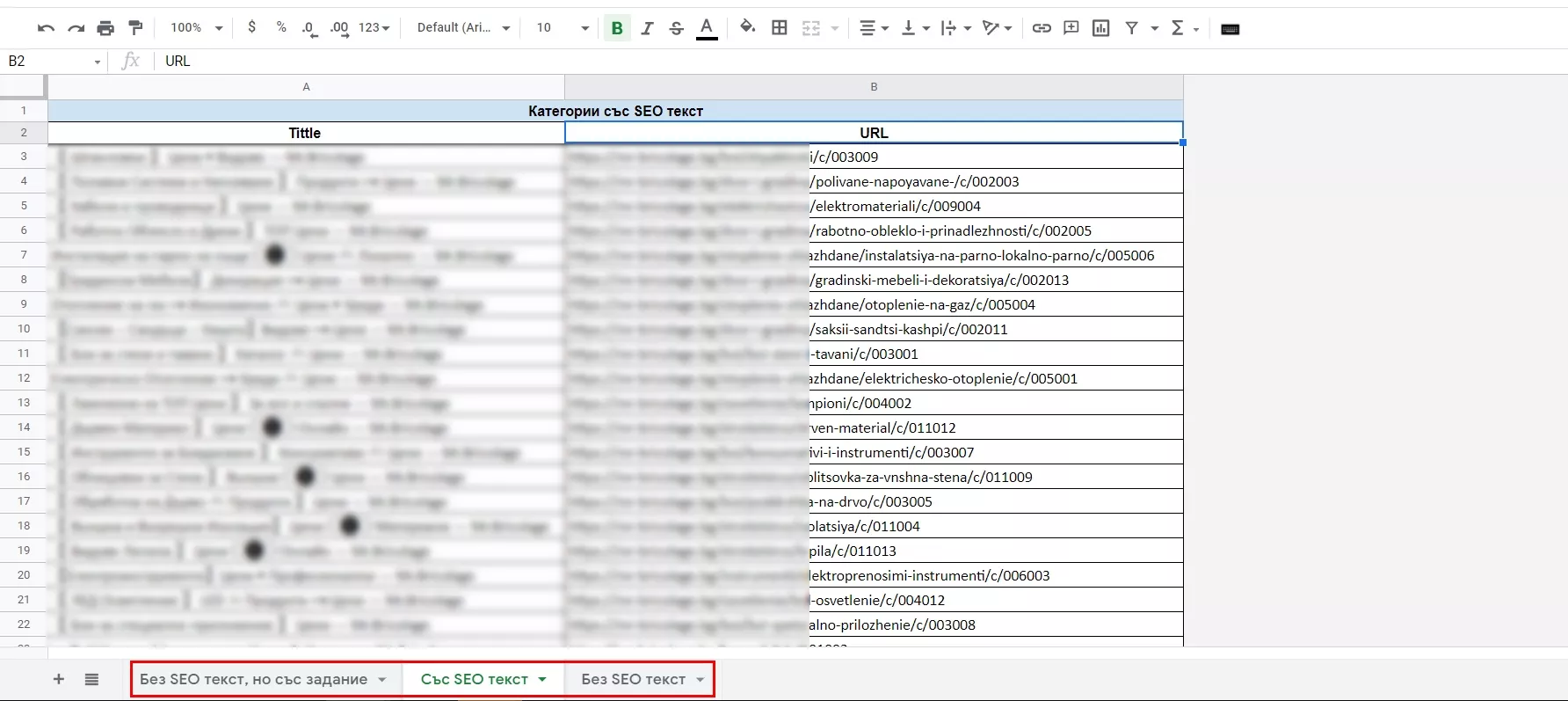
Вече имаме 3 таба с нужната информация и задачата е изпълнена.
Ще се радваме да ни споделите в коментар по статията дали сте използвали някога този метод, сработил ли е и бихте ли го изпробвали за систематизиране на съдържанието си, след като прочетохте статията ни. Надяваме се да сме ви били полезни. Успех!

 52
52
 11
11
 21
21