Показването на резултатите за търсената фраза за части от секундата е само върхът на айсберга. В «черната кутия» на търсачките са сканирани и добавени в специална база данни милиарди страници, които се подбират за показване след отчитане на множество фактори.
Страницата с резултати от търсене се формира вследствие на извършване на три процеса:
- сканиране;
- индексиране;
- показване на резултати (състои се от търсене в индекса и класиране на страниците).
Как работи сканирането (краулингът) на сайта?
Накратко, краулинг (сканиране, crawling) е процес на откриване и събиране на нови и обновени страници от бота на търсачката (краулера), които добавя в индекса на системите за търсене. Сканирането е началният етап, данните се събират само за бъдеща вътрешна обработка (създаване на индекс) и не се показват в резултатите от търсенето. Сканираната страница невинаги е индексирана.
Ботът на търсачката (той е crawler, краулер, паяк, бот) е програма за събиране на съдържание в интернет. Краулерът се състои от множество сървъри, обхождащи и избиращи страници значително по-бързо, отколкото потребител с помощта на неговия уеб-браузер. Фактически краулерът може да обходи хиляди различни страници едновременно.
Какво още прави ботът-краулер:
- Постоянно проверява и сравнява списък с URL-адреси за сканиране с URL-адреси, които вече се намират в индекса на Google.
- Премахва дубликатите от списъка, за да предотврати повторно изтегляне на една и съща страница.
- Добавя за повторно индексиране променените страници, за получаване на актуални резултати.
При сканирането паяците преглеждат страниците и извършват преход по съдържащите се на тях препратки по същия начин, както и обикновените потребители. При това различният контент се изследва от ботовете с различна последователност. Това позволява едновременно да се обработват огромни масиви от данни.
Например, в Google съществуват ботове за обработка на различен тип контент:
- Googlebot — основен бот на търсачката;
- Googlebot News — бот за сканиране на новини;
- Googlebot Images — бот за сканиране на изображения;
- Googlebot Video — бот за сканиране на видео.
Именно с robots.txt започва процесът на сканиране на сайта — краулерът опитва да намери ограниченията за достъп до контента и връзките от картата на сайта (Sitemap). В картата на сайта трябва да се намират препратките към важните страници на сайта. В някои случаи ботът на търсачката може да игнорира този документ и страниците да попаднат в индекса, затова конфиденциалната информация трябва да се заключва с парола направо на сървъра.
Как краулерът вижда сайта
Ако искате да проверите как ботът-краулер вижда страницата на сайта, изключете обработката на JavaScript при включен дебъгер в браузера. Да вземем например Google Chrome:
- Натискаме F12 — викаме прозореца на дебъгера, отиваме в настройки.
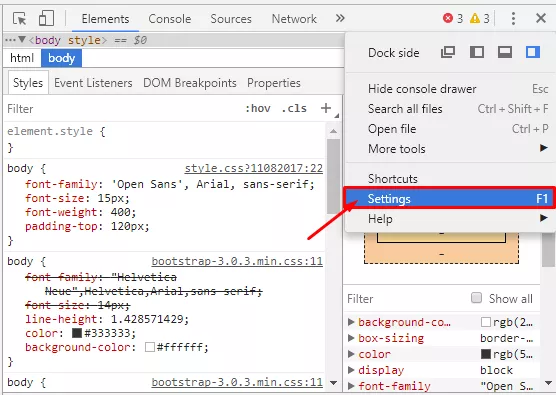
- Изключваме JavaScript и презареждаме страницата.
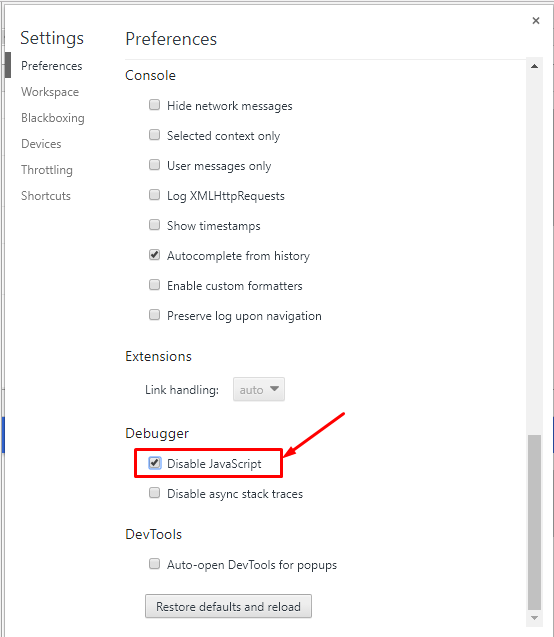
Ако в самата страница се е съхранила основната информация, заедно с линковете към другите страници от сайта и изглежда приблизително по същия начин, както и с включен JavaScript, проблеми при сканирането не би трябвало да има.
Втори начин — използване на Google инструмента «Извличане като Google» в Search Console.
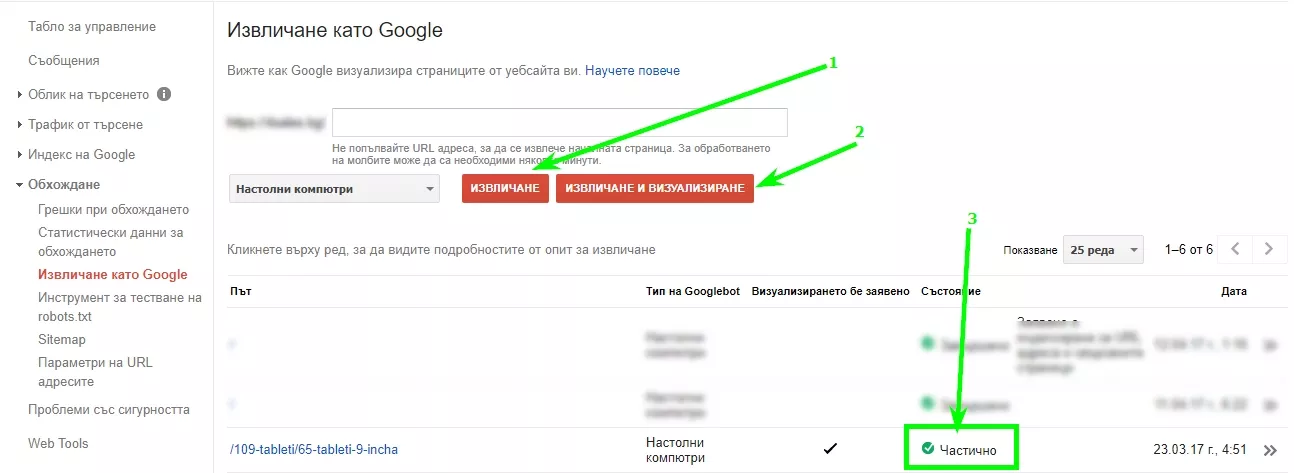
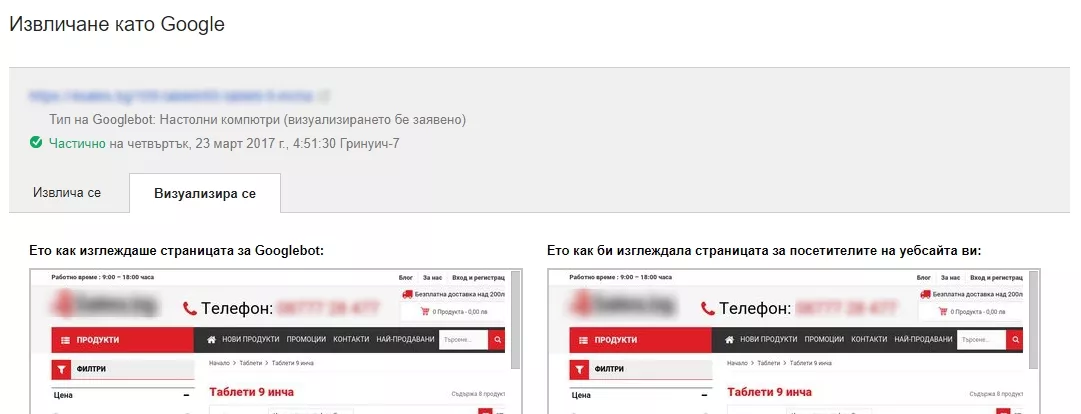
Ако краулерът вижда Вашата страница така както и Вие, проблем със сканирането няма.
Трети метод — специален софтуер. Например https://pr-cy.ru/simulator/ показва програмния код, който ботът вижда на страницата, а Netpeak Spider показва над 50 различни видове грешки, намерени при сканиране и ги подрежда по степен на важност.
Ако страницата не се показва така, както сте очаквали, е добре да проверите, достъпна ли е тя за сканиране: не е ли блокирана в robots.txt, във файла .htaccess.
Проблеми със сканирането могат да възникват, ако сайтът е създаден с помощта на технологии
Как да управляваме сканирането на страници
Стартиране и оптимизация на сканирането на сайта
Съществуват няколко метода да се покани паяка на сайта:
- Разрешете сканирането на сайта, ако е бил заключен с парола на сървъра, и предайте информация за URL c помощта на HTTP-заглавие «referer» при преход към друг ресурс.
- Поставете препратка към Вашия сайт на друг ресурс, например в социалните мрежи.
- Регистрирайте го в панелите за уебмастери на Google и Яндекс.
- Съобщете за сайта на търсачката направо през профила на уебмастера в търсачката:
- Използвайте вътрешни препратки на страниците за подобряване на навигацията и сканирането на ресурса, например, “хлебни трохички”.
- Създайте карта на сайта с нужния списък от страници и добавете линк към картата в robots.txt.
Забрана за сканиране на сайта
- За да ограничите сканирането на контента, трябва да защитите папките на сървъра с парола. Това е лесен и ефективен начин за защита на конфиденциална информация от ботове.
- Сложете ограничения в robots.txt.
- Използвайте метатаг <meta name=”robots”/>. С помощта на директивата “nofollow” добре е да се забрани прехода чрез линкове на други страници.
- Използвайте HTTP-заглавие X-Robots tag. Забраната за сканиране от страна на сървъра става с помощта на HTTP заглавие X-Robots-tag: nofollow. Директиви, които се прилагат за robots.txt, са подходящи за X-Robots tag.
Повече информация за използване на http-заглавия има в справочника за разработчици.
Управляване на честотата на сканиране на сайта
Googlebot използва алгоритмичен процес за да определи какви сайтове да сканира, колко често и колко страници да извлича. Уебмастерът може да даде спомагателна информация на краулера с помощта на файла sitemap, тоест с помощта на атрибути:
- <lastmod> — дата на последната промяна на файла;
- <changefreq> — вероятна честота на промяна на страниците;
- <priority> — приоритетност.
За съжаление, стойностите на тези атрибути се разглеждат от ботовете като подсказване, а не като команда, затова в Google Search Console съществува инструмент за ръчно изпращане на заявка за сканиране.
Изводи
- Различният контент се обработва от ботовете с различна последователност. Това позволява едновременно да се обработват огромни масиви от данни.
- За подобряване на процеса на сканиране, трябва да се създават карти на сайтове и да се прави вътрешно линкване — за да може ботът да намери всички важни страници.
- Заключването на информация срещу индексиране е най-добре да се прави с помощта на метатага <meta name="robots" content="nofollow"/> или http-заглавие X-Robot tag, тъй като файлът robots.txt съдържа само препоръки за сканиране, а не директни команди за действие.
Четете още

 13
13
 2
2
 3
3