Направи си сам: фийд за Facebook динамични реклами
Какво е динамичен ремаркетинг във Facebook
Динамичният ремаркетинг във Facebook ви позволява да напомняте на потребителите за вашия онлайн магазин и за продуктите, които преди това са ги интересували.
Според проучване на The Global State of Digital през 2019 г. около 3,7 милиона потребители в България са регистрирани във Facebook. Следователно, една ремаркетинг реклама ще има шанс да мотивира половината от населението на държавата ни да купуват разгледаните продукти.
Динамичният ремаркетинг е един от най-ефективните начини за продажба, но всички знаем, че за да настроите този инструмент, трябва да включите в процеса програмисти.
Първо трябва да настроите проследяване на целите и да създадете продуктов фийд.
За какво е тази статия?
В нашия блог вече сме ви разказвали
Ще използваме само Google Sheets/Таблици, т.е. ще можем да създадем feed-а абсолютно безплатно, използвайки само формулите от самите Google Sheets.
Важно!
Тези формули ще бъдат полезни, за да правим “малки фийдове” до 1000 продукта поради ограниченията на синтактичния анализ на Google Sheets.
Ще парсим данните в различни таблици - поради ограничените възможности на таблиците, парсенето на голямо количество данни води или до дълго време за получаване на резултати, или до грешки във формулите. А най-често и до двата резултата. Затова ще събираме данни в отделни таблици и след това ги добавяме в една окончателна.
Целият процес ще отнеме 2-4 часа, в зависимост от уменията за работа в Google Sheets и времето за парсенето на данни в сайта. На мен ми отне 1 час за подготовка и въвеждане на формули и 2 часа за сканиране на сайта за получаване на необходимите данни.
Защо разписвам тази статия:
- Защото наличните модули за изграждане на продуктов каталог за конкретния CMS биха могли да създадат конфликт с други функционалности на сайта;
- Защото собственикът на онлайн магазина не вярваше в “магията” на динамичния ремаркетинг. Съответно, не искаше да заплати дори и за външна услуга за Фийд мениджмънт.
Етапи на създаване на продуктов фийд за Facebook
Фийдът във Facebook е таблица с продукти, които трябва да отговарят на определени изисквания. Форматите на файловете за Facebook са CSV, TSV и XML (RSS / ATOM).
Следните полета са задължителни за продукти:
- id;
- title;
- description;
- availability;
- condition;
- price;
- link;
- image_link;
- brand, mpn or gtin (добавете поне едно).
Запазване на оригиналните линкове към продукти:
1. Трябва ни списък с линкове към продуктите. Те могат да бъдат взети от sitemap xml.
2. Запазваме xml картата.
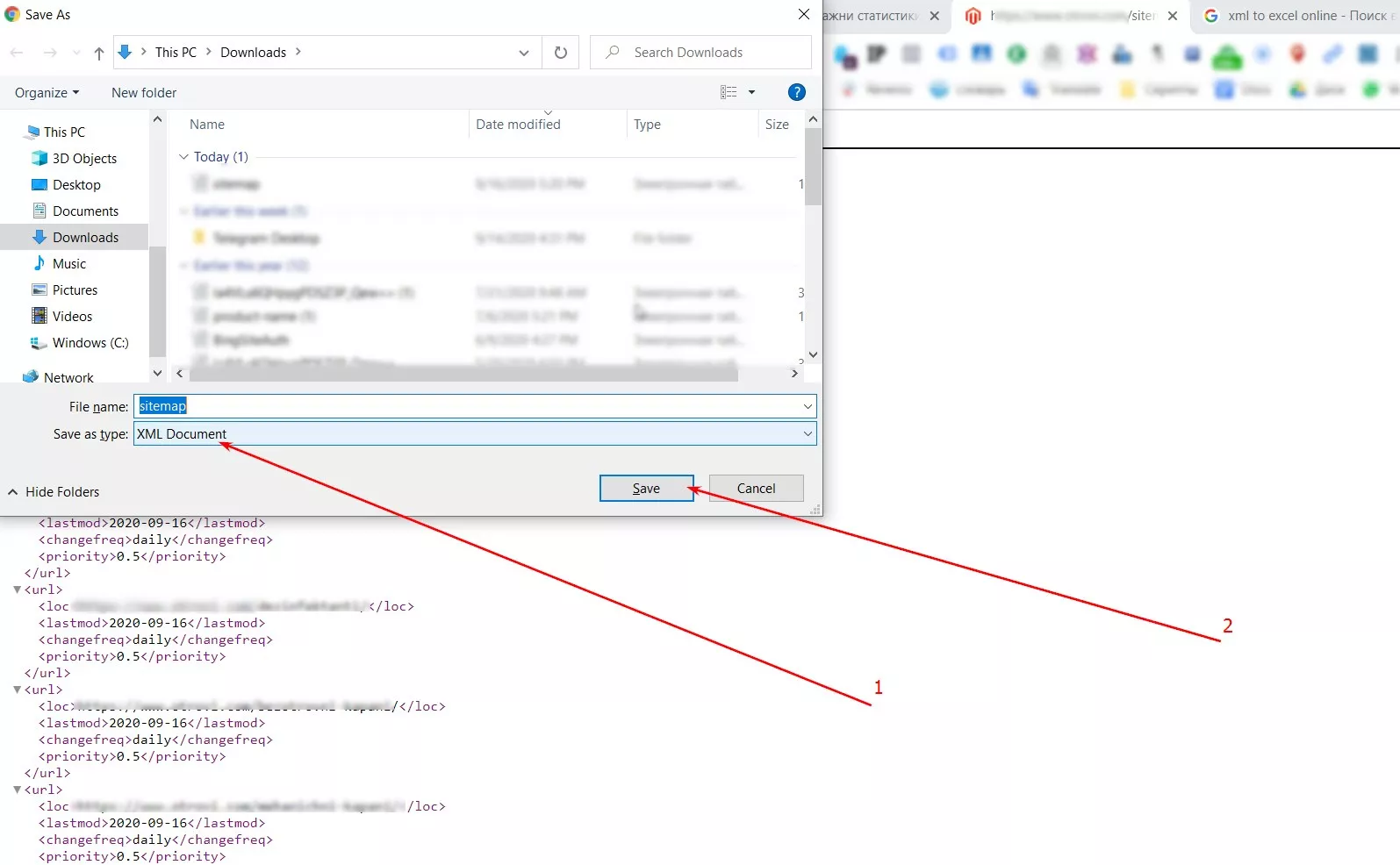
3. Конвертираме xml в xlsx формат.
Има много безплатни инструменти за конвертиране, аз например използвах този.
4. След това копираме линковете в таблицата в Google Sheets.
За парсинг на данни ще използваме Xpath.
1. Какво е Xpath?
Xpath (XML Path Language) е език за запитвания на xml или xhtml елементи на документ. Използва се за навигация в елементите и атрибутите на XML документи. Изразите в езика за запитвания са много сходни с пътищата, които виждате при работа с файловата система на компютъра.
XPath използва изрази за път, за да избере "възлите" в даден XML документ.
Най-полезните изрази по пътя са:
Израз | Описание |
node_name | Избира всички възли с име node_name |
/ | Избира от коренов възел |
// | Избира възли в документа от текущия възел, които съответстват на избора, независимо къде се намират |
. | Избира текущия възел |
.. | Избира родителя на текущия възел |
@ | Избира атрибути |
2. Парсинг на заглавието на продукта
ImportXML (Url; XPath) е формула в Google Spreadsheets, която импортира данни от източници във формат XML, HTML, CSV, TSV по URL, използвайки езика за заявки XPath.
Като използвате ImportXML, можете удобно да парсите елементи от метаданни (h1, заглавие, описание). Удобен е, защото е подходящ за всеки сайт.
Нека да разгледаме примера със заглавието на страница. Намерете <h1> в кода на страницата:
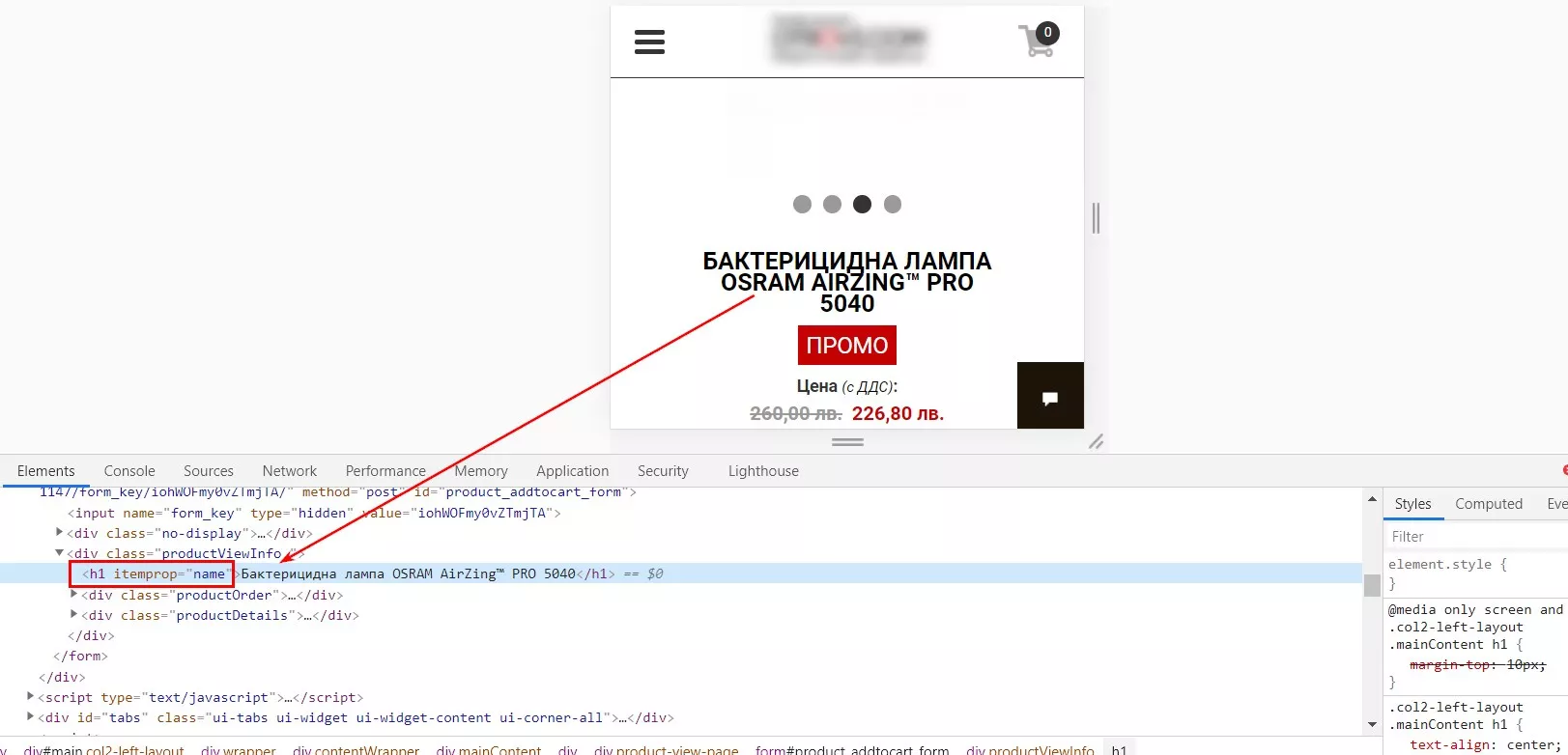
По този начин XPath за страница на сайта ще изглежда като "// h1".
// h1 - показва относителната пътека към таг h1. Тоест, ние не се интересуваме на каква дълбочина е заглавието от корена.
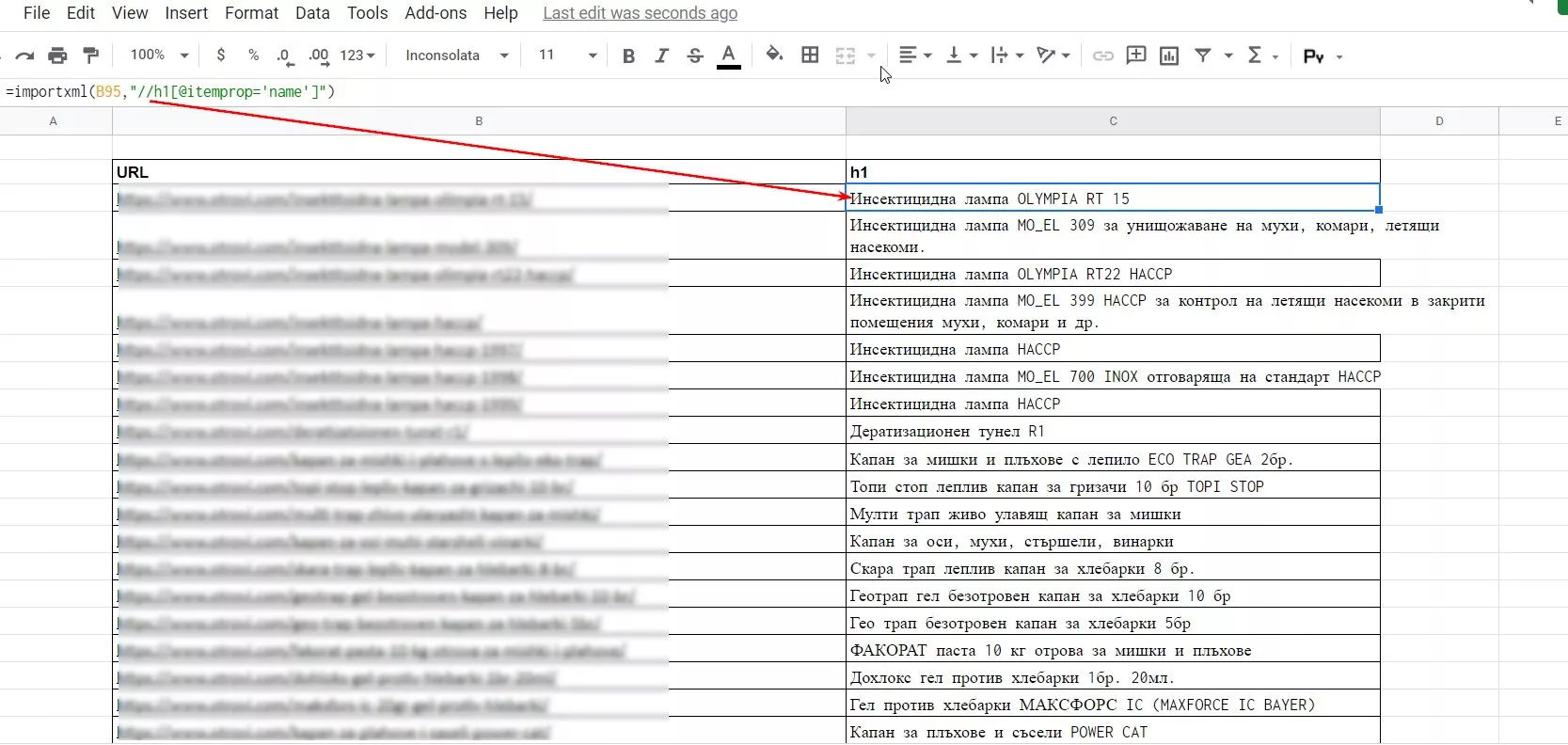
Цялата функция за Google Spreadsheets ще изглежда така:
= importxml (URL, "// h1 [@ itemprop = 'name']")Използване за страници:
Допълнително използване на Xpath
Xpath е декларативен език за заявки към елементи на xml или (x)html документ и xslt трансформации. XPath може да се използва за навигация по елементи и атрибути в XML документ. Това означава, че можете да изберете всеки елемент или съдържанието на който и да е елемент, атрибут, таблица или мета-обект в източника на HTML документа, или визуализиран документ.
3. Парсинг на цените / наличието на продукта
В този пример беше по-удобно да се анализира цял блок от цени (стара / нова цена + наличност), но има моменти, когато трябва да парсите поотделно.
Да разгледаме конкретен случай, когато ценовият блок е описан по следния начин:
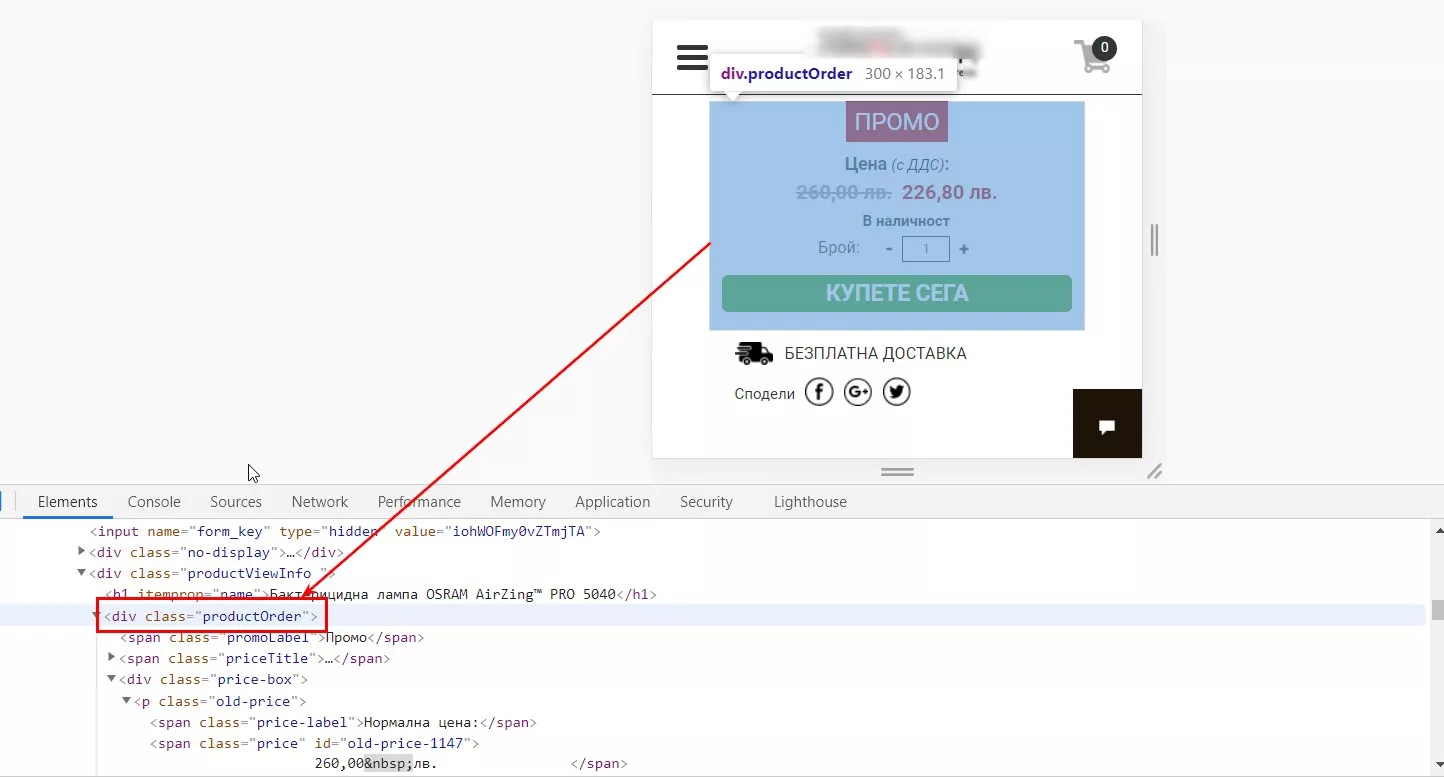
=importxml(URL,"//div[@class='productOrder']")Има минус и таблицата придобива нечетлива форма, но с това ще се справим малко по-късно.
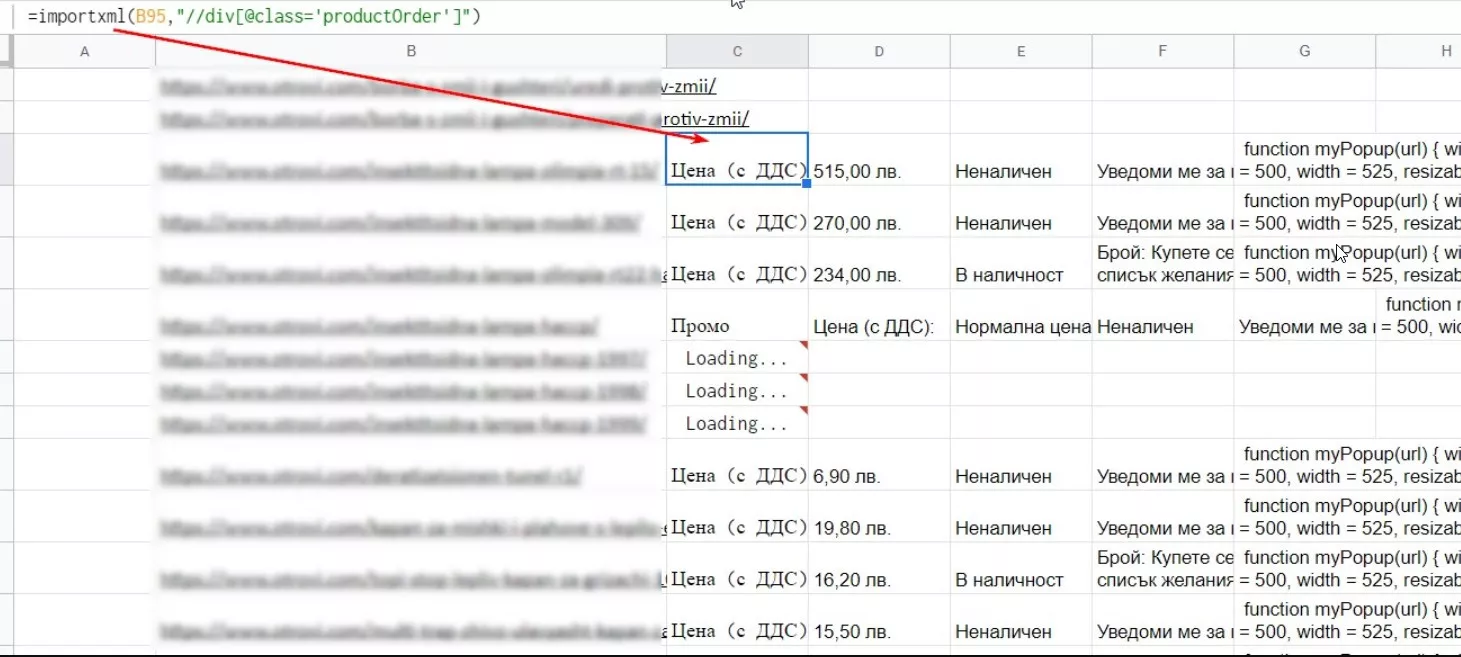
Използваме обикновената функция IF - ако описанието на продукта съдържа „В наличност“ - показваме In stock, в противен случай - Out of stock.
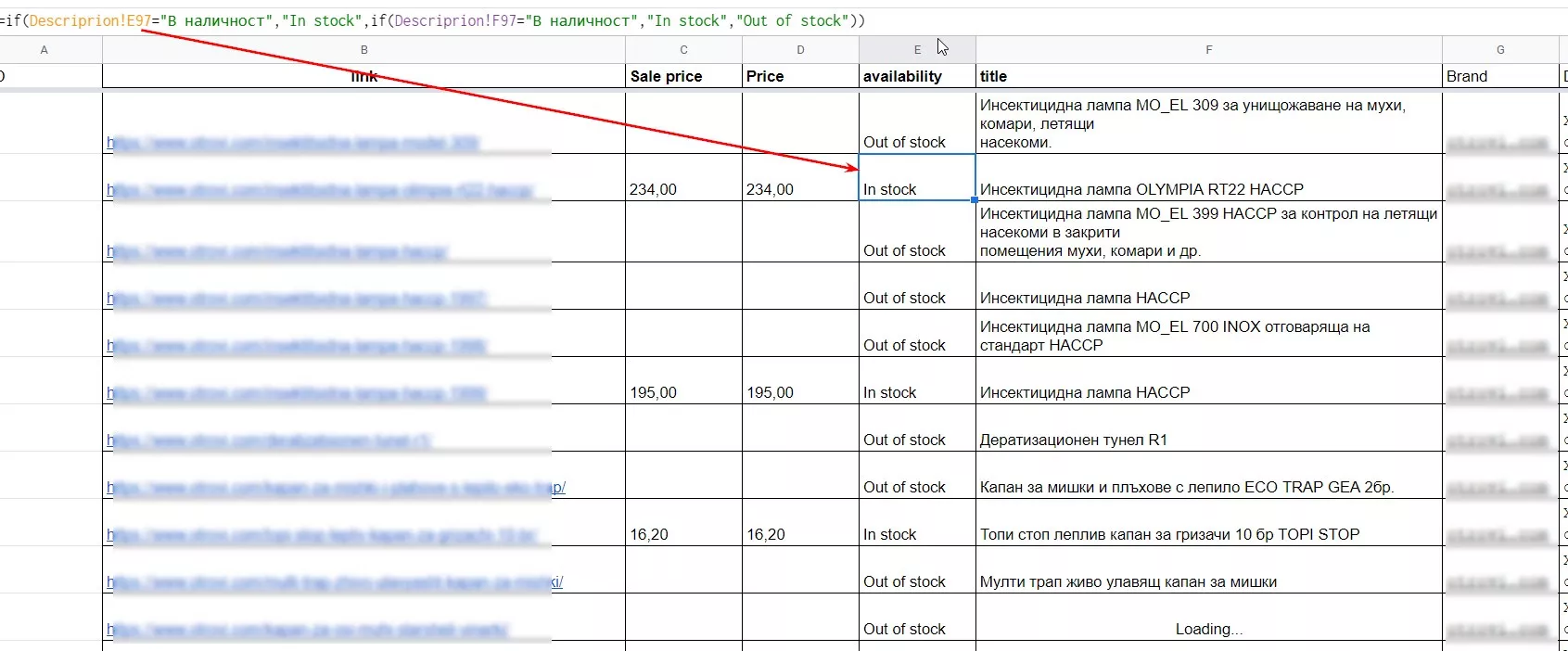
Цена:
Показваме цената в отделна клетка само ако продуктът е наличен, за продукти, които не са налични, няма смисъл да се занимаваме с това.
В нашия случай цената на сайта се показва без посочване на валутата и валутата трябва да бъде посочена в фийда.
Затова използваме функцията CONCATENATE (комбиниране на текст от различни клетки).
Цената се изважда по формулата:
=if(Isblank(Data2!C96),,CONCATENATE(Data2!C96,Data2!I96))Ако клетката с цената е празна - покажете празна клетка, ако има цена - покажете цената + добавете идентификатора на валутата (BGN) към цената.
Isblank - проверка дали клетката съдържа число, текстова стойност, формула или нищо.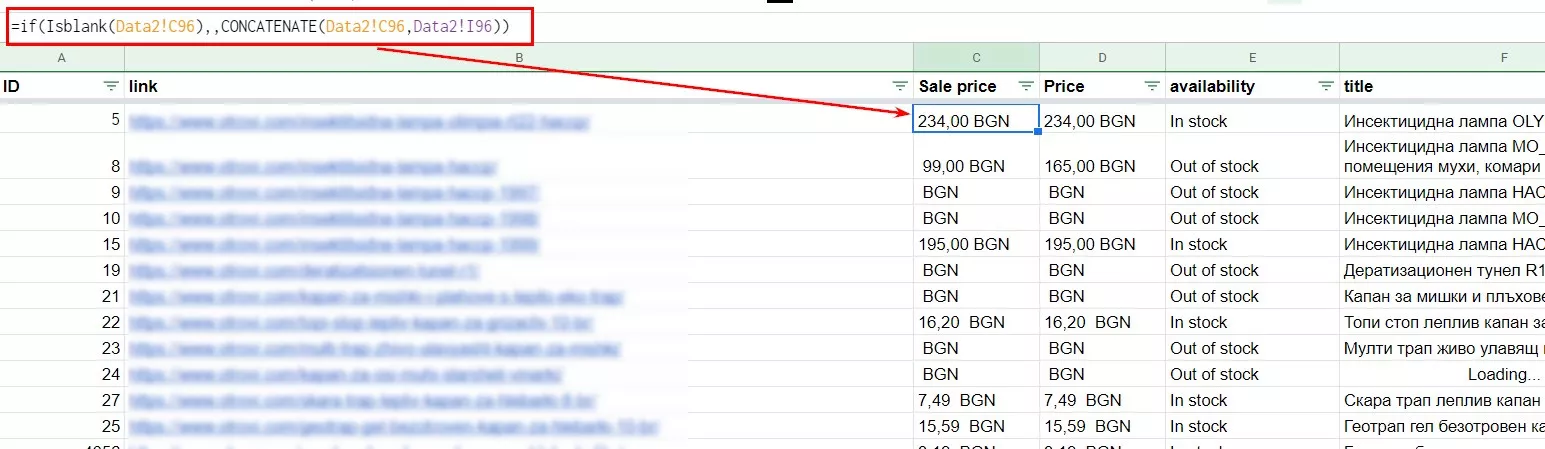
4. Парсене на ID на продукта
В нашия случай можем да идентифицираме продукта по sku:
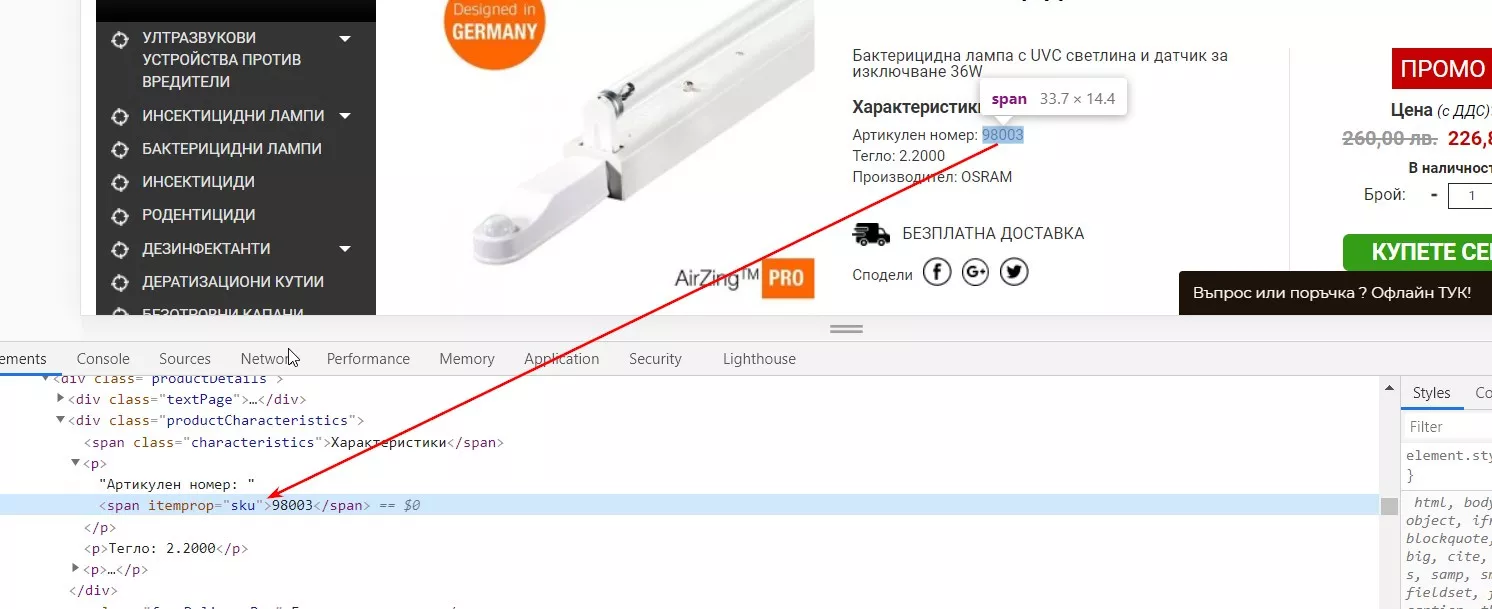
=importxml(URL,"//span[@itemprop='sku']")Резултат: 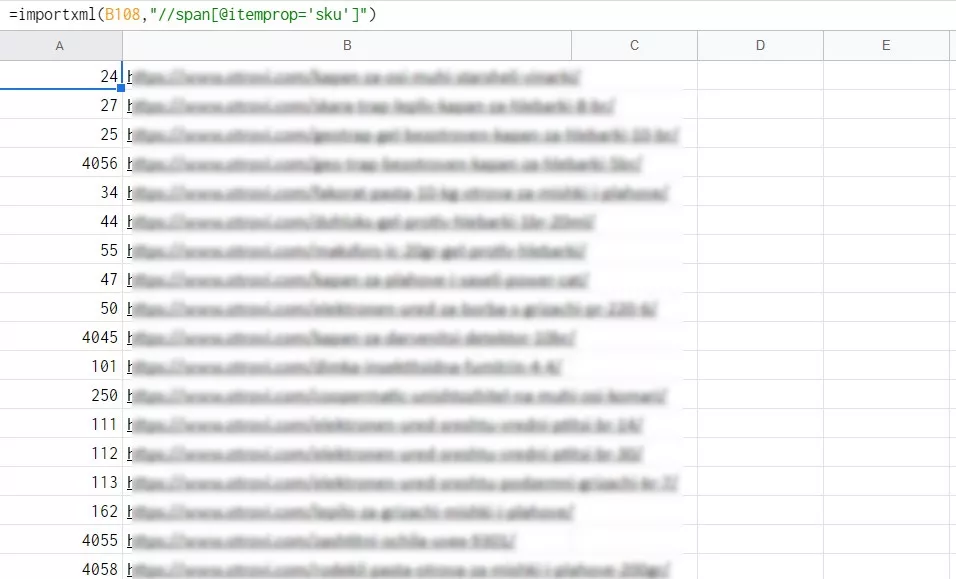
5. Парсене на URL на изображенията
В този конкретен случай най-лесният начин беше да вземем URL адреси на изображенията от микроформатите на Open Graph (може да е различно за други сайтове).
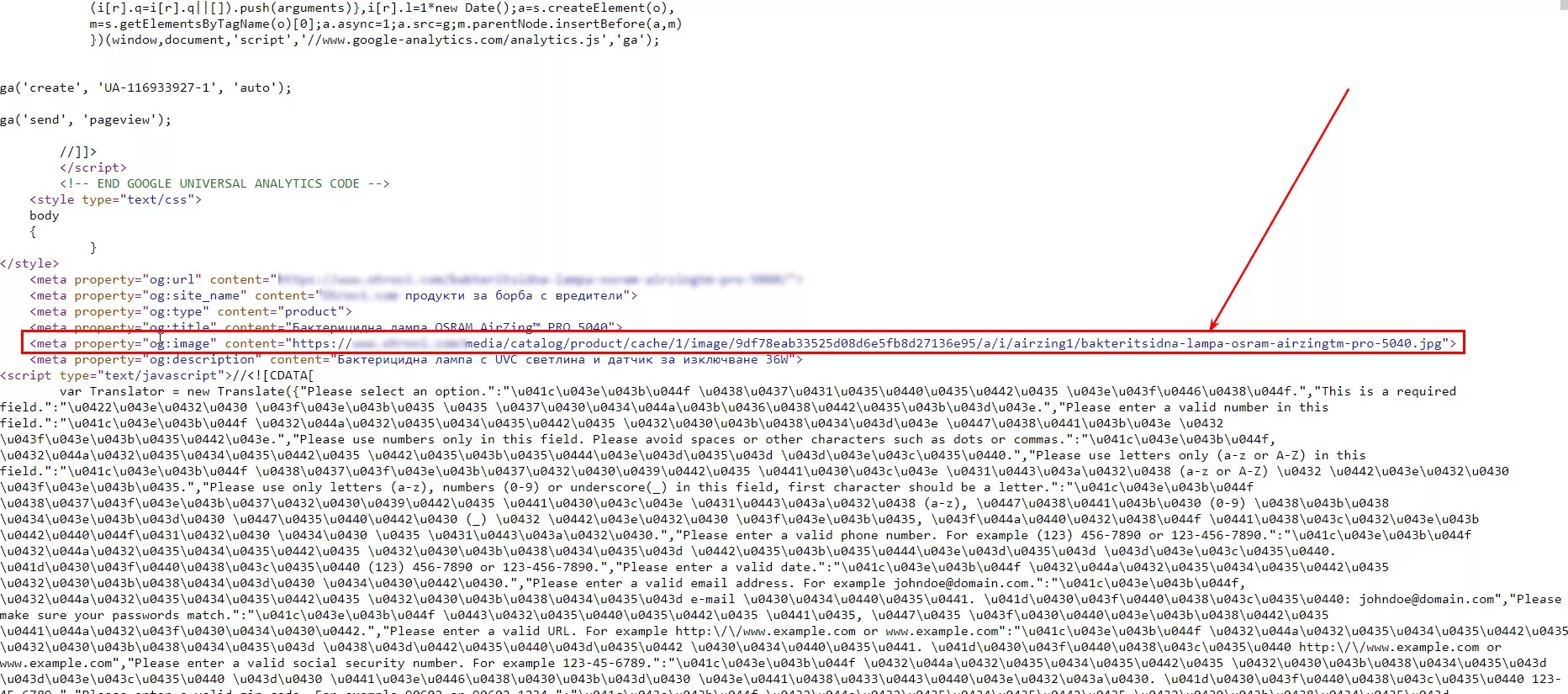
Формула:
=importxml(URL,"//meta[@property='og:image']/@content")6. Събиране на данни в една таблица
Google Sheets използва функцията IMPORTRANGE за прехвърляне на данни от един файл в друг.
Формула:
=IMPORTRANGE( "URL таблица","Sheet1!C3:C853")Sheet1!C3:C853 - тук се намират елементите, които ни трябват.
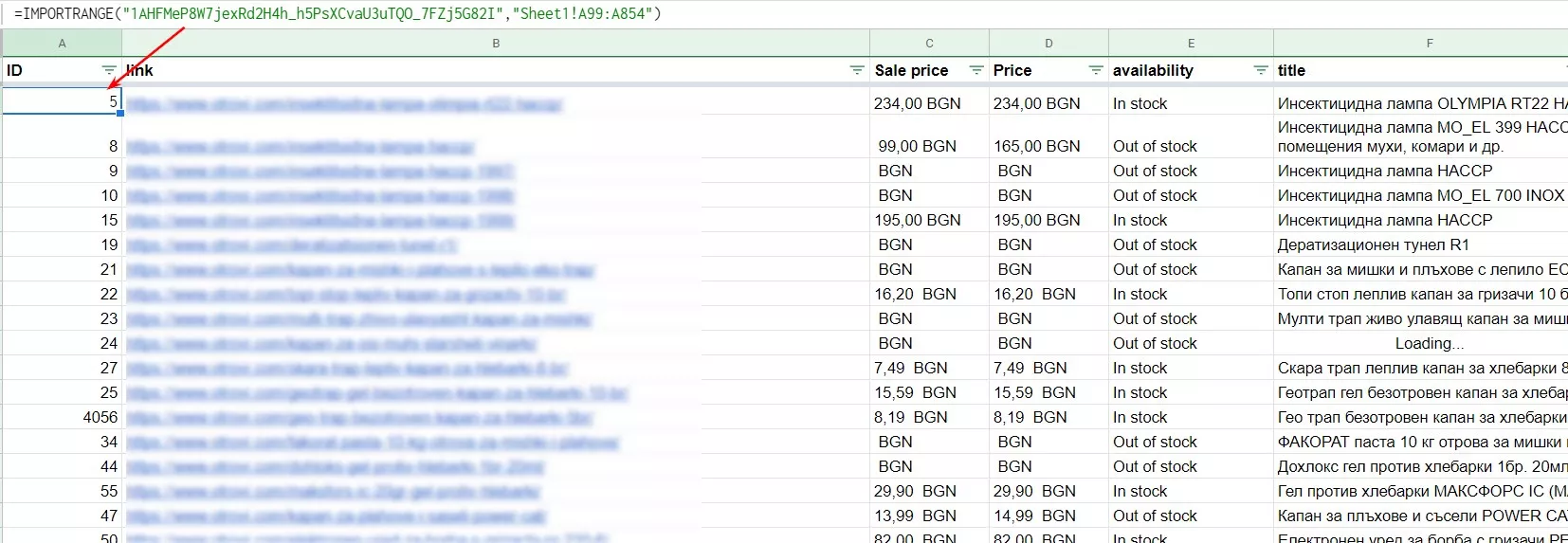
За липсващите колони Brand, Description, Condition копираме същите данни:
- Brand - име на сайта;
- Description - Обща фраза, в нашия случай „Хубав продукт от известни производители“
- Condition - new.
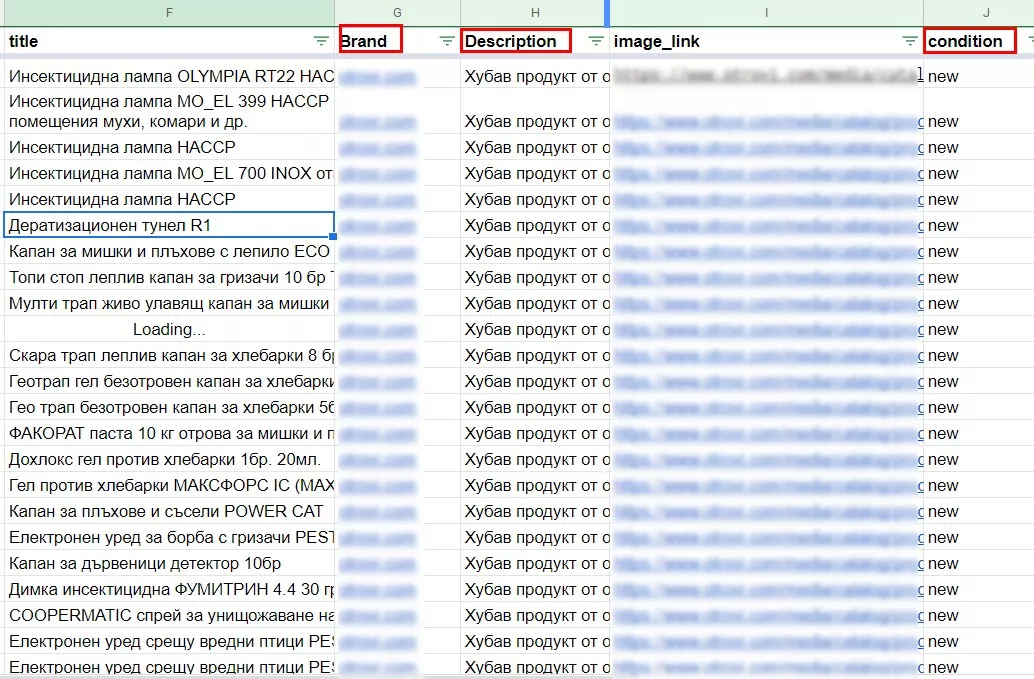
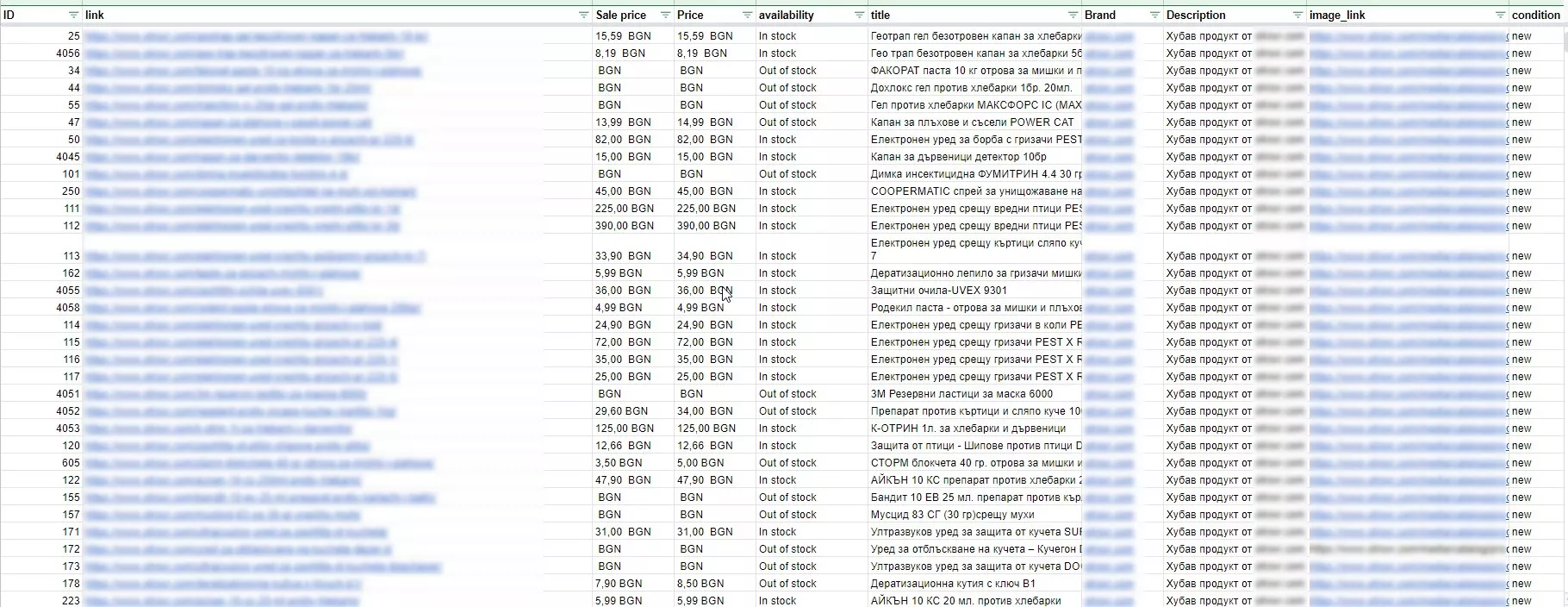
7. Фийд
Като резултат от нашата работа получаваме следната таблица:
8. Качване на файла във Facebook
Качваме таблицата във Facebook и получаваме следния резултат:
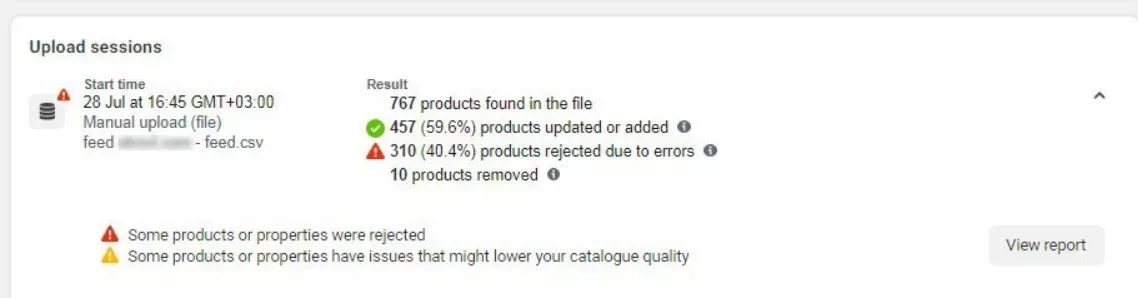
310-те отхвърлени продукта са Out of stock, така че правим извода, че фийдът работи.
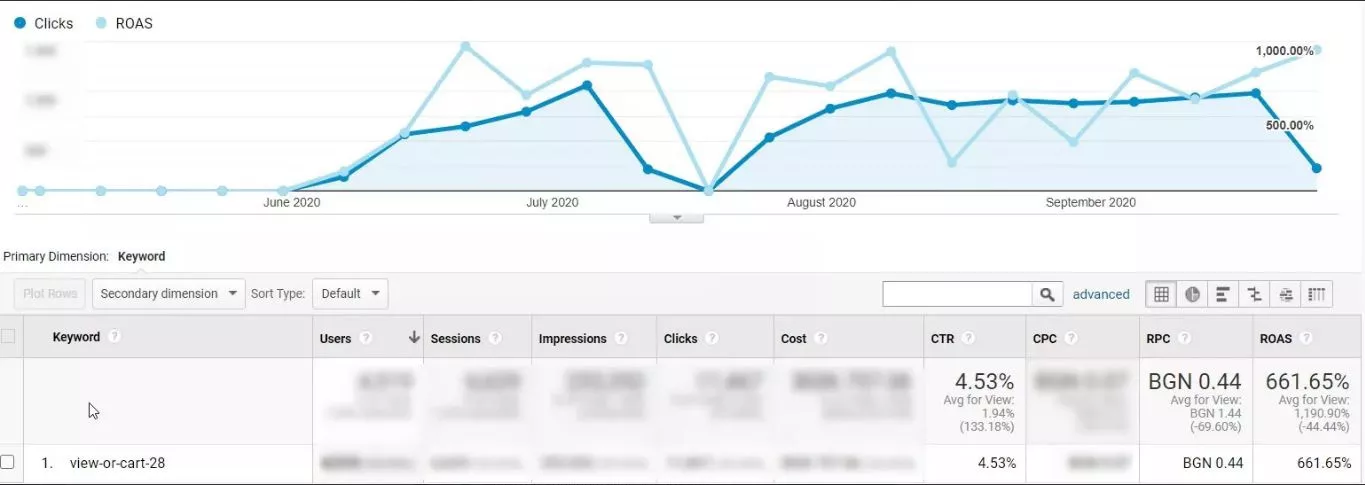
А ето и малко цифри - резултатите от кампанията с този фийд за период от 4 месеца:
Обобщение
Предимства:
- Намаляване на разходите. Безплатен аналог на продуктов фийд, ако сте в самото начало на развитието на онлайн магазин, вие инвестирате само във времето си.
- Безопасност. Не е необходимо да давате достъпи до сайта на трети лица.
- Скорост. Възможността за бързо стартиране на динамичен ремаркетинг и връщане на потенциални потребители на сайта
- Универсалност. По същия начин можете да направите парсинг на цените на конкурентите си безплатно и да сте наясно с промените в ценовата политика на техните сайтове.
Недостатъци:
- Подходящ само за малки бази на данни.
- Парсингът отнема доста дълго време.
- Понякога могат да възникват грешки, ако даден сайт блокира много запитвания към сайта.
- Промените във фийда трябва да се правят ръчно - при добавянето на продукти или промяна на URL адреси.
Като цяло този начин има хем плюсове, хем минуси, дали да го използвате зависи от вас :)

 77
77
 16
16
 12
12