Оптимизирането на уебсайт до голяма степен включва комуникация с ботовете, които обхождат уеб пространството, и правят съдържанието ни достъпно и откриваемо за потребителите.
Това се осъществява чрез даване на препоръки и инструкции за обхождане и индексиране към роботите. Robots.txt, Meta robots tags, X-robots-tag - какво представляват, кога ги използваме и каква е разликата между тях?
Ще ги разгледаме подробно поотделно, но първо нека споменем накратко как функционира...
Mетодът на работа на Google Search и как съдържанието ни попада в резултатите при търсене

Обхождането на сайтовете се извършва от Crawlers, още познати като Spiders, роботи или просто ботове. Тяхната функция е да обхождат уеб пространството чрез сканиране на препратки, да търсят нови и ъпдейтнати страници и да ги включват в индекса на Google. Основният crawler на Google е Googlebot. Когато ботовете обхождат URL адреси, анализират тяхното съдържание и значение, и ги вкарват в индексната база. Индексираните страници се показват в резултатите на търсачката - SERP - Search Engine Result Page.
При подаване на заявка (Query) от потребител в търсачката Google се обръща към индексната си база и чрез редица алгоритми и фактори резултатите се пренареждат в SERP-а, с цел показване на възможно най-релевантните резултати, които да отговарят на
Google обработва множество заявки, които представляват огромно количество информация, и за да не се извършват тези сложни изчисления за пренареждане на резултатите при всяка една заявка, запазва копие - кеш / cache, което предоставя за определен период от време в SERP. Освен това резултатите, които виждаме, са персонализирани спрямо нашите локация, интереси и поведение.
Обхождащите ботове се нуждаят от ясни инструкции относно съдържането, което могат да посещават и да вкарват в индекса. Чрез контролирането им влияем на краулинг бюджета и на крайното класиране в органичните резултати. Възможните начини за това ще разгледаме в статията.

Robots.txt - това е текстови файл, който се използва за контролиране на обхождането - задава препоръки как ботовете да сканират страниците от уебсайта.
При обхождане краулерите първо поглеждат инструкциите, зададени в Robots.txt. Поставя се в главната директория на сайта и може да се провери наличието му на всеки един уебсайт при изписване на името на домейна/robots.txt.
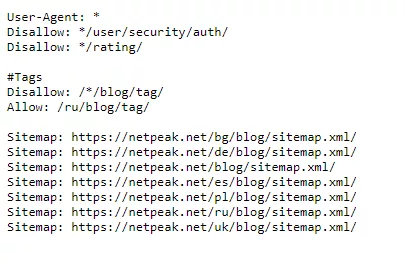
Чрез User-agent директивата се посочват конкретни краулери, до които се отнасят препоръките, а чрез използването на * показваме, че искаме всички ботове да ги видят и следват.
Наличието на robots.txt не е задължително, но е силно препоръчително.
Чрез инструкции в него можем:
1. Да затваряме за обхождане страници, скриптове, файлове и изображения с цел оптимизиране на краулинг бюджета. Имайте предвид, че забраненото обхождане няма да предотврати влизането на страниците в индекса на Google и по-надолу в статията ще разгледаме защо.
2. Да подаваме
3. Има възможност за контролиране на обхождането от Google ботовете чрез Google Search Console и Crawl Rate репорта. Google сам определя колко често и какво количество страници от уебсайта ни да обхожда, но така можем да му зададем граници, за да не претоварва сървъра.
Няколко съвета при използването на Robots.txt файл
- Доброто съдържание не трябва да се затваря за обхождане - съдържание, което би носило посещения и би било полезно за потребителите е препоръчително да бъде достъпно за сканиране.
- Трябва да се прави разлика между Disallow и Noindex. При използване на Disallow предотвратяваме обхождането, но е важно да знаем, че ако към страницата има други външни и вътрешни препратки, ботовете все пак ще я намерят и вкарат в индекса. Преди години ботовете вземаха предвид директивата Noindex в robots.txt файла на уебсайта, но днес има други по-надеждни и правилни начини за предотвратяване на индексацията.
- Robots.txt файлът е case sensitive - бъдете сигурни, че го създавате с малки букви, в противен случай няма да се прочете от ботовете, за които е предназначен.

Не всяко съдържание трябва задължително да бъде индексирано. В онлайн магазини, например, адреси като количка, страници с включено сортиране, преплитане на филтри (има изключения), чувствително съдържание или дублиращи се адреси, няма смисъл да влизат в индексната база, а последните могат да създадат сериозни проблеми и да повлияят отрицателно на класирането.
Докато robots.txt файлът дава препоръки как да бъде обхождано съдържанието, Meta Robots директивите дават ясни и конкретни инструкции, относно обхождането и индексирането му. Важно е да знаем, че това са два отделни процеса и че неправилната употреба на robots.txt файла и Meta Robots директивите няма да доведе до желаните ефекти.
Мета директивите се делят на два вида - Meta robots tags - малки тагове, намиращи се в HTML кода на страниците и X-Robots-Tags - тези, които сървърът изпраща като HTTP хедъри.
Какво представляват и как изглеждат Meta Robots таговете?
Познати още като Meta tags, те са малки парчета между <head></head> частта в HTML кода:

Специфични са за всяка страница поотделно и с тях можем:
- да посочваме дали страницата да влиза или не в индекса;
- да посочваме дали ботовете да обхождат връзките, които се намират на страницата;
- да забраняваме показване на кешираната версия;
- да забраняваме показването на “snippet” в страницата с резултати.

Съставени са от два атрибута: name и content.
Name= показва за кой бот / user agent се отнася инструкцията. В най-общия случай name= “robots” означава, че важи за всички ботове. Можем да отбележим специфичен краулер, който искаме да следва инструкциите, като заместим “robots”:
< meta name="googlebot" content="noindex" >
Content частта съдържа параметрите - самите инструкции, които даваме към краулерите.
Най-често използваните варианти са следните:
index / noindex- индексиране на страницата;follow / nofollow- следване на връзките от страницата. Nofollow започва да се използва през 2005 за контролиране на спам в секцията с коментари, като по този начин предотвратява изтичането на тежест или така наречения “link juice” към линкове от коментарите. Днес се използва често и при вътрешното налинкване в сайтове с цел оптимизиране на бюджета за обхождане;none = noindex,nofollow;all = index, follow;Nocache / noarchive- забрана за показване на кеширана версия;nositelinkssearchbox- забрана за показване на полето за търсене в SERP;nopagereadaloud- не позволява гласови услуги да четат съдържанието;notranslate- не позволява превеждане на страницата в SERP;unavailable_after- задава конкретна дата и час, след които съдържанието вече няма да се индексира.
Можем да използваме няколко на брой инструкции за страница, стига те да се отнасят за един и същ краулер:
< meta name="googlebot" content="noindex , nofollow , noimageindex" >
Нека разгледаме и другия начин за задаване на инструкции.
Какво представляват X-Robots-Tags?

Използването на X-Robots-tag е начин за даване на инструкции за специфични страници и елементи. Всяка една директива, която може да бъде използвана при meta robots tag, може да бъде имплементирана и при X-robots-tag. Това е един малко по-сложен начин за задаване на инструкции, но пък дава повече възможности и е най-сигурният и надежден вариант. За да го прилагаме е нужно да имаме достъп до php, .htaccess, или server access файла.
Докато Robots Meta таговете задават инструкциите на ниво страница, маркерът X-robots-tag прави това на сървърно ниво, като част от HTTP отговора.

Едно от предимствата му е, че допуска използването на регулярни изрази, което го прави значително по-гъвкав.
Кога се използва?
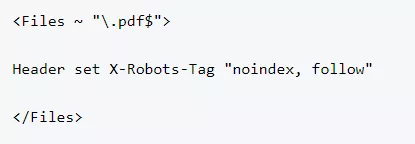
- За контролиране на начина на обхождане и индексиране на различни от HTML файлове и елементи - изображения, PDF файлове и други;
- Когато имаме нужда да зададем инструкциите на глобално ниво, вместо на ниво страница;
- Когато нямаме достъп до HTML кода на уебсайта или ако сайта използва global header, който не може да бъде сменен.
Излишно е използването на Meta Robots tag и X-Robots-tag едновременно, необходимо е да се избере по-оптималният вариант за конкрентия уебсайт.
Ето и няколко варианта за прилагане на X-Robots-Tag:
Инструкцията в php изглежда по следния начин и се добавя в head частта на header.php файла:

За използване при Apache се добавя следното в .htaccess или в httpd.config файла:
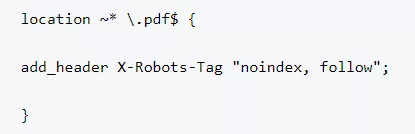
При Nginx се добавят следните редове в .conf файла:
Какви са често срещаните грешки при употребата на Meta Robots директивите?
1. Meta Robots директиви на страници, блокирани за обхождане в robots.txt файла - всички мета директиви се прочитат при обхождане. Ако то е блокирано, мета директивите на страницата в HTML кода или HTTP хедъра, няма да се прочетат от ботовете и на практика ще бъдат игнорирани.
2. При затваряне за индексация чрез някой от възможните методи много често се избързва и страниците се премахват от XML картата на сайта. Шансът желаният URL да бъде по-бързо сканиран и изваден от индекса е по-голям, ако присъства в нея.
3. По време на процеса на миграция на сайт от стара към нова версия, се правят тестове в демо среда. Правенето на технически промени онлайн е рисковано и непрепоръчително. Демо варианта трябва да бъде затворен за потребители, но използването на robots.txt файла и Disallow директивата не са надежден вариант - те спират обхождането, но потребителите все още имат достъп до съдържанието. Много често след миграция препоръките във файла остават и това пречи на обхождането на вече мигриралия сайт. По-добрият и сигурен начин е използването на HTTP Authentication в демо средата до минаването онлайн.

Извод
За да постигнем добри позиции в органичните резултати и съответно ръстове в органичния трафик, трябва да сме запознати с методите на работа на обхождащите роботи и да знаем как да комуникираме с тях. Имайки контрол над обхождането и индексирането, помагаме значително на краулинг бюджета и честотата на обхождане.

 62
62
 5
5
 21
21