Преди да започна пътя си в SEO и Netpeak, никога не бях чувал за регулярните изрази. Но след няколко дни работа с голям обем от данни, разбрах че без тяхна помощ е НЕВЪЗМОЖНО да се справим. За това в следващите редове ще ви запозная с тях и за какво ги използваме ние, SEO специалистите от Netpeak.
Регулярен израз или Regular Expression е последователност от знаци, която дефинира шаблон за търсене.
Тестване на регулярни изрази
В сайта regexr.com можете много удобно да се упражнявате в използването на регулярни изрази. В този сайт има информация за всеки един регулярен израз и пример как той работи.
Запознанство с интерфейса на сайта
Сайта е много лесен и удобен за използване. В горната лява част от менюто RegEx Reference ще откриете меню с всички групи регулярни изрази.
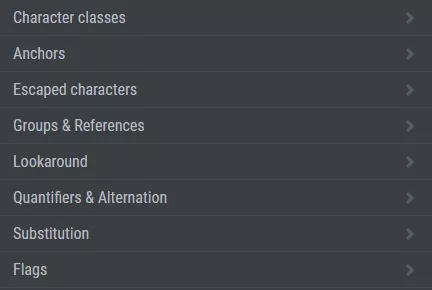
Избирайки група и регулярен израз в долната лява част на интерфейса ще се появи обяснение и прост пример как работи израза
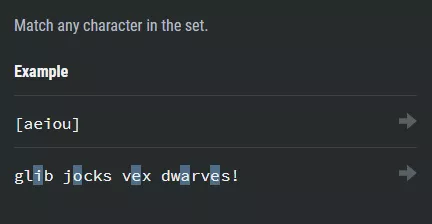
След натискането на стрелкичката срещу дадения пример
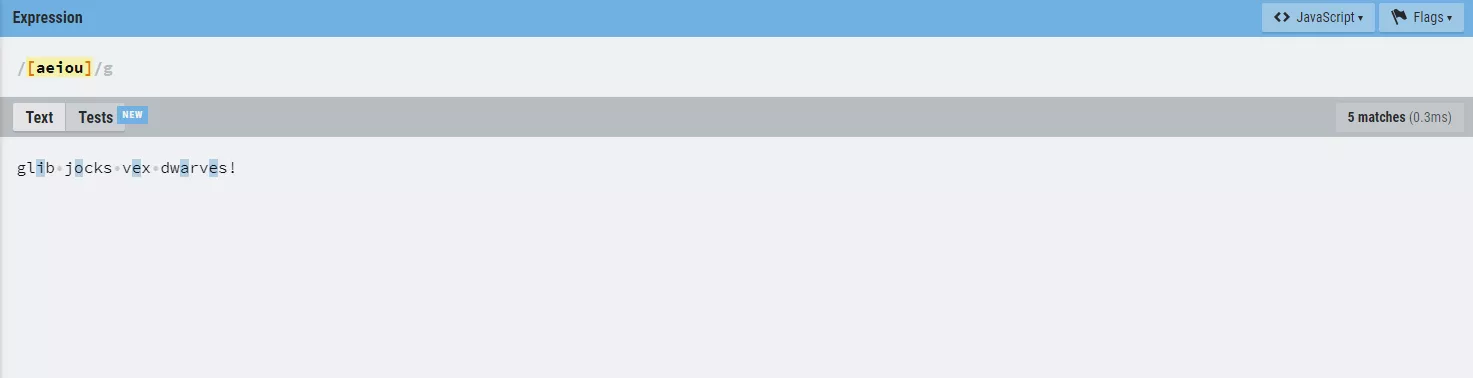
Последното нещо, което трябва да знаем за момента, са флаговете в горната дясна част на екрана:
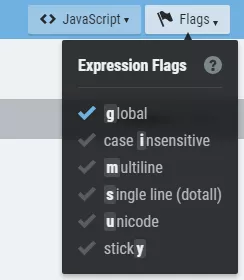
Тук най-важен е флага multiline. Ако работим с голяма база от редове, то с този флаг ще можем да приложим регулярният израз за всеки ред поотделно.
Какво правят регулярните изрази
След като вече сме запознати с интерфейса на сайта, можем да видим и какво правят основните типове регулярни изрази.
1. Character classes - селектира определен набор от знаци
За тези регулярни изрази ще използваме средни скоби [ ].
Най-простият пример е регулярният израз [aeiou].
Като резултат ще имаме селектирани само гласните букви от определен текст
Пример: glib jocks vex dwarves!
Ако обаче поставим символа Caret ^ пред набора от букви [^aeiou] резултатът, който ще върне регулярния израз, е всички останали букви от текста, но не и тези, които са в скобите.
Пример: glib jocks vex dwarves!
Следващият регулярен израз, който трябва да знаем, е Range (Диапазон) [a-z]
По този начин ние му казваме да селектира всички малки букви от азбуката от a до z
Пример: glib Jocks Vex dwasRves!
Ако искаме да селектираме и големите букви в текста, изразът ще изглежда по следния начин [a-zA-Z]
В резултат получаваме тази селекция:
Пример: glib Jocks Vex dwasRves!
Друг начин да селектираме всички букви от текста е да използваме регулярния израз word \w
Пример: glib Jocks Vex dwasRves!
Обратният вариант е not word \W
Резултатът е всички символи, включително и разстояние, които не са букви.
Пример: glib Jocks Vex dwasRves!
Съответно имаме и за числа digit \d
Селектира всички числа от текста.
Пример: +1-(444)-555-1234
И обратното not digit \D
Селектира всичко което не е число.
Пример: +1-(444)-555-1234
2. Anchors - те са уникални с това, че селектират дадена позиция в поредица от текст а не определен символ
Тук започваме с израза beginning ^. Ако го приложим в комбинация с още няколко регулярни израза ^\w+ ще получим като резултат, селекция на първата дума от даден текст.
Пример: she sells seashells
Обратното на beginning е end $. Знака долар се различава с това ,че се поставя в края на регулярният израз \w+$, като по този начин получаваме селекция на последната дума от изречението.
Пример: she sells seashells
Друг израз от тази група е word boundary \b. Той селектира определен символ спрямо неговата позиция в думата. Така например ако използваме буквата s\b ще селектираме всяко “s”, което е в края на дума.
Пример: she sells seashells cat dogs
Обратният израз, както вече се досещате, е not word boundary \B. Както при другите изрази, така и тук, той прави обратното.
Например s\B
Пример: she sells seashells cat dogs
3. Lookaround - позволява да търсим преди или след дадена група от символи без да ги включим в резултата
Тук ще използваме израза positive lookahead, който изглежда по следния начин \d(?=px)
Резултатът е всички числа (Digits), които са пред групата от символи “px”.
Пример: 1pt 2px 3em 4px
Обратното е negative lookahead, който изглежда така \d(?!px)
Резултатът е всички числа, които са пред група от символи, различна от “px”.
Пример: 1pt 2px 3em 4px
Ако искаме да селектираме числа след група от изрази, то тогава ще използваме positive lookbehind, който изглежда по следния начин (?<=px)\d
В резултат селектираме числа (Digits), които се намират след групата от символи “px”
Пример: 1pt3 2px3 3em3 4px3
Синтаксис на регулярните изрази
Повечето символи в регулярните изрази представляват самите себе си, изключение правят групите от специални символи [ ] \ / ^ $ . | ? * + ( ) { }. Ако тези символи трябва да се представят като символи в текста, те трябва да се заградят с обратно наклонена черта \.
Така например, ако искаме да селектираме въпросителен знак от едно изречение, то не може просто да поставим ? в регулярния израз, а ще трябва да изглежда така \?
Пример: she sells seashells ?
Но ако тези изрази се срещат без наклонена черта в регулярния израз, то те имат специално значение:
- ^ — каретка (caret), коректорски знак. Начало на реда;
- $ — знак долар. Край на реда;
- . — точка. Всеки символ;
- * – знак за умножение, звездичка. Произволен брой предишни символи;
- + – плюс. Един или повече предишни символи;
- ? – въпросителен знак. 0 или 1 предишни символи;
- ( ) – кръгли скобки. Групиране на конструкции;
- | – вертикална линия. Оператор ИЛИ;
- [ ] – средни скоби. Всеки от изброените символи, диапазон. Ако първият символ в тази конструкция е ^, то масива работи наобратно – проверяваният символ не трябва да съвпада с това, което е изброено в скобите;
- { } – големи скобки. Повторение на символа няколко пъти;
- \ – обратен слеш, обратно наклонена черта. Екраниране на служебни символи.
Всичко за
Изводи
Регулярните изрази са мощен, полезен и напълно безплатен инструмент за обработка на огромно количество данни.
Доста сложно е да се усвои, но без тях е невъзможно да се справим. Как точно ги използваме всекидневно в работата си ще може да научите от следващата ни статия и примерите в нея.

 68
68
 12
12
 21
21