Just yesterday Netpeak Software team released
Let’s go over the major updates you can try for free during the week (until April 4th inclusive).
By the way, a code name for
And now let’s focus on the key new features.
1. Up to 30 Times Faster Crawling, Compared to 2.1
We have significantly optimized crawling speed in Netpeak Spider 3.0. We conducted tests to compare crawling 100,000 URLs with Netpeak Spider 3.0 and the previous version, Netpeak Spider 2.1, with the same conditions and got great results. The new version shows up to 30 times increase in speed.

2. Optimized RAM Usage
When analyzing medium sites (10K pages), we reduced RAM consumption by 3 times and accelerated crawling by 8 times.
Large websites crawling (100K pages) highlights strengths of the new version – RAM consumption has decreased even more (4 times), and data analysis took 30 times less time.
3. Option to Resume Crawling After Opening the Project
Now you can stop scanning, save the project and
- For example, the next day → you just need to open the project and click on the ‘Start’ button.
- On another computer → to do so, just transfer the entire folder with the project to the necessary computer (for example, if your device reaches RAM limit and you want to continue crawling on more powerful one), open the project there and click again on the treasured ‘Start’ button.
4. Rescanning a URL or a List of URLs
Previously, to check whether previously found issues were properly fixed, you had to scan the entire website or the URLs list onceagain. Now you can select an issue in
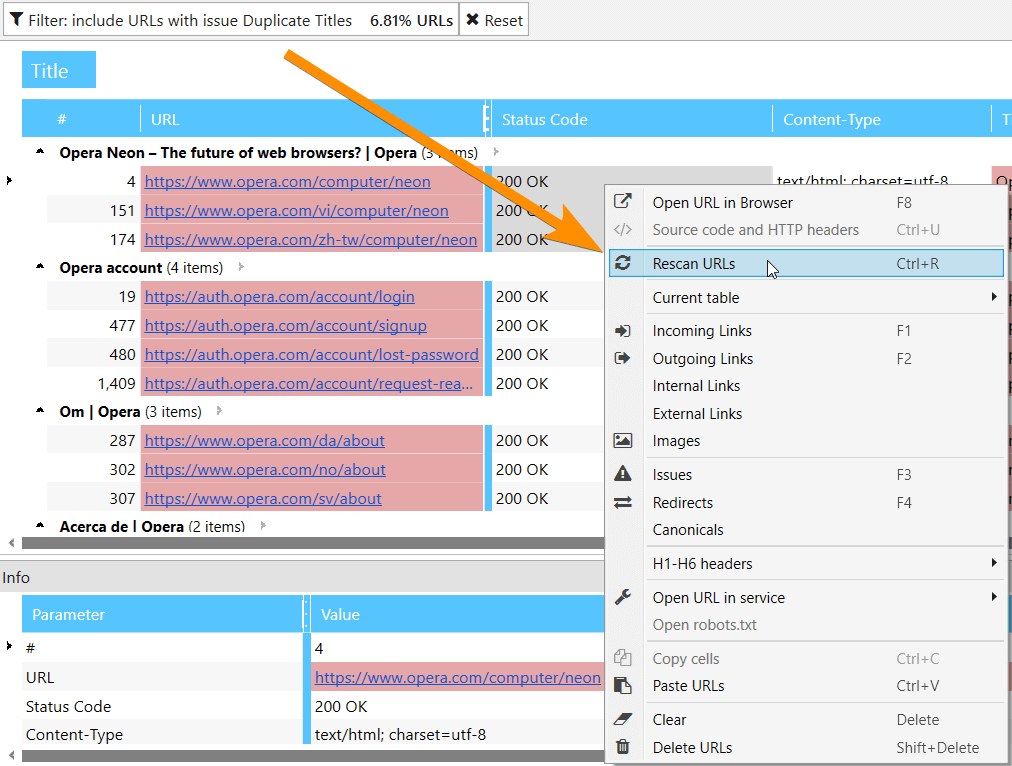
You can also rescan both single URL and URL list on ‘All Results’ or ‘URL Explorer’ tabs.
5. Deleting URLs from Report
If you’ve crawled some extra data and it made your report too heavy, now you can easily delete this information, and all your basic reports will be updated.

Moreover, at this stage you can just clear the results without deleting URLs. It is very useful when you need to rescan same pages with new parameters.
6. Changing Parameters During Crawling
Option to change parameters during crawling is one of the most awaited features of Netpeak Spider. This is what it allows to do:
-
If you’ve started crawling and then realized that you forgot to include some significant parameters or parsing of necessary HTML fragment, now you can stop crawling, enable necessary parameters and then continue scanning. In this case, scanned pages will not be recrawled and included parameters will be applied only for new pages.
-
If you’ve started crawling and understood that there is too much data (that is blowing your RAM), you can stop scanning, turn off unnecessary parameters, and resume it. And, voila, you freed up RAM and now can parse more data. By the way, the good news is that received data is not deleted, but just hidden. It means that if you turn these parameters back on, the data will appear in the table and be in all reports.
7. Data Segmentation
Segmentation is a unique feature on the market allowing you to change data view using a certain filter. Segments affect all reports in the program, including ‘Issues’, ‘Overview’, ‘Site Structure’, ‘Dashboard’, etc.
8. Site Structure Report
We’ve implemented a new report with the full site structure in the tree view, where you can filter pages at any level.

Try to select a category and press ‘Advanced copy’ button. Results will be copied to
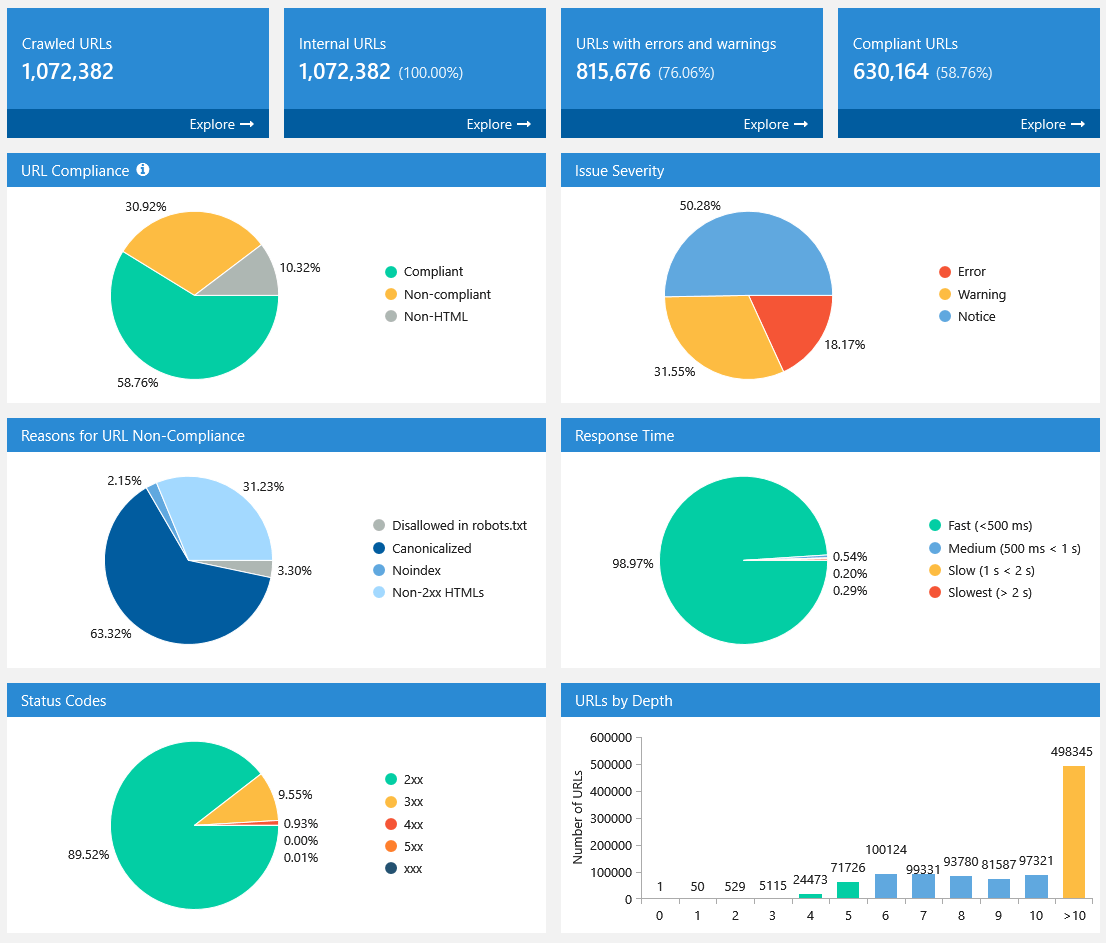
9. Dashboard (Information about Crawling Process and Diagrams After It’s Complete)
In a new version of Netpeak

When crawling is complete or paused, settings take a back seat and diagrams with useful insights about crawled pages take first place. All diagrams are interactive: you can click on any part of the chart or any value near it and go to results filtered for that value. Also, you can download
10. Exporting 10+ New Reports and 60+ Issue Reports in Two Clicks
In Netpeak Spider
- All issues → exporting all issue
reports into one folder; - Custom issue reports → here are reports with convenient current data view on certain issues:
- Broken links
- Missing images ALT attributes
- Redirect chain
- Redirect blocked by Robots.txt
- Bad URL format redirects
- Canonical chain
- Canonical blocked by Robots.txt
- Links
with bad URL format
- All links → export external and internal links on scanned pages separately;
- All unique URLs and anchors → in the same way, export separately all external and internal links. Data in the first report is grouped by URL, in the second one – by URL and anchor.

11. Determining Compliant URLs
Now Netpeak Spider determines 3 types of page compliancy:
- Compliant — HTML files with 2xx status code, not disallowed in indexation instructions (robots.txt, Canonical, Meta Robots, etc.). They are the most important pages on your
website, because they can potentially lead organic traffic. - Non-compliant — HTML files with
non -2xx status code or disallowed by indexation instructions. These pages usually do not lead traffic from search engines and also waste crawling budget. - Non-HTML — other documents with lower chances for high ranking in SERP.
Compliance becomes a unified concept for tools and analytics inside the program, most issues can be detected only for compliant URLs.
12. Special Reports for Every Issue
To filter pages with some issues in more in the most convenient way we created
- Broken images
- Bad URL format
- Redirect blocked by robots.txt
- Canonical blocked by robots.txt
- Missing images ALT attributes
- Internal Nofollow links
- External Nofollow links
13. Rebuilt Tools ‘Internal PageRank Calculation’, ‘XML Sitemap Validator’, ‘Source Code and HTTP Header Analysis’, and ‘Sitemap Generator’
Internal PageRank Calculation
- Added ‘Internal PR’ parameter for each link.
- Internal PageRank calculation is processed only for compliant URLs. Thus, images and other content types different from HTML will not be accounted for.
- We added ‘Link Weight’ parameter to show (you won’t believe it) how much link equity is distributed across the website. It helps you optimize internal link weight distribution if you use this structure on your website after
simulation in our tool. - We created new ‘PageRank changes’ table. During each
iteration program calculates the ratio of internal PageRank on current iteration to PR on zero iteration.

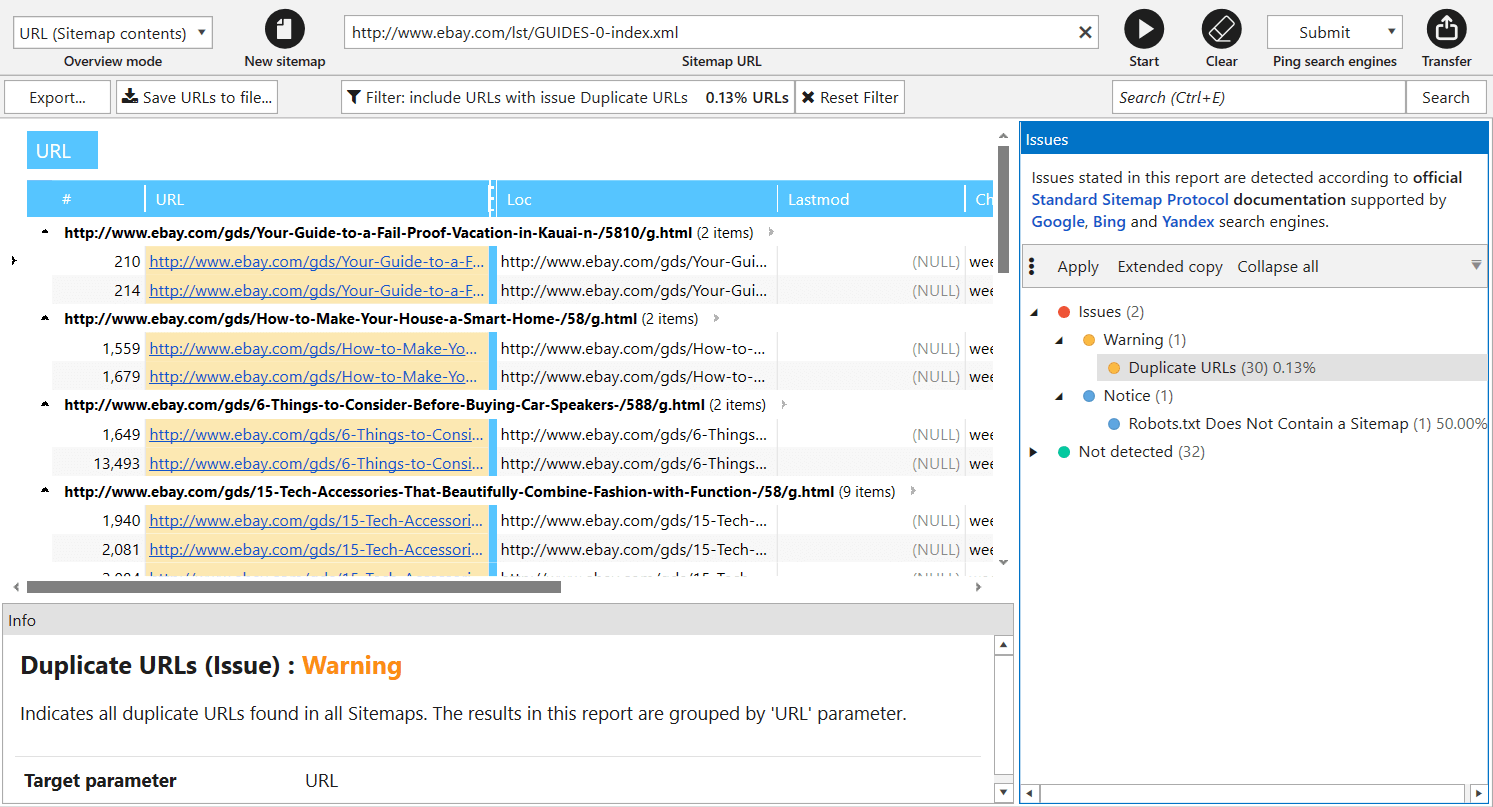
XML Sitemap Validator
In
- Parsing links from Sitemap and importing them to the main table for further analysis.
- XML Sitemap validation → we completely updated all issues (now there are 34 of them) according to main Google recommendations.
- Ping XML Sitemap to search engines to draw their attention to changes in it.
Note that crawling rules also work for link parsing from XML Sitemaps. For comfortable use, we save your previous requests here: start entering URL, and
Source Code and HTTP Headers Analysis
We also improved
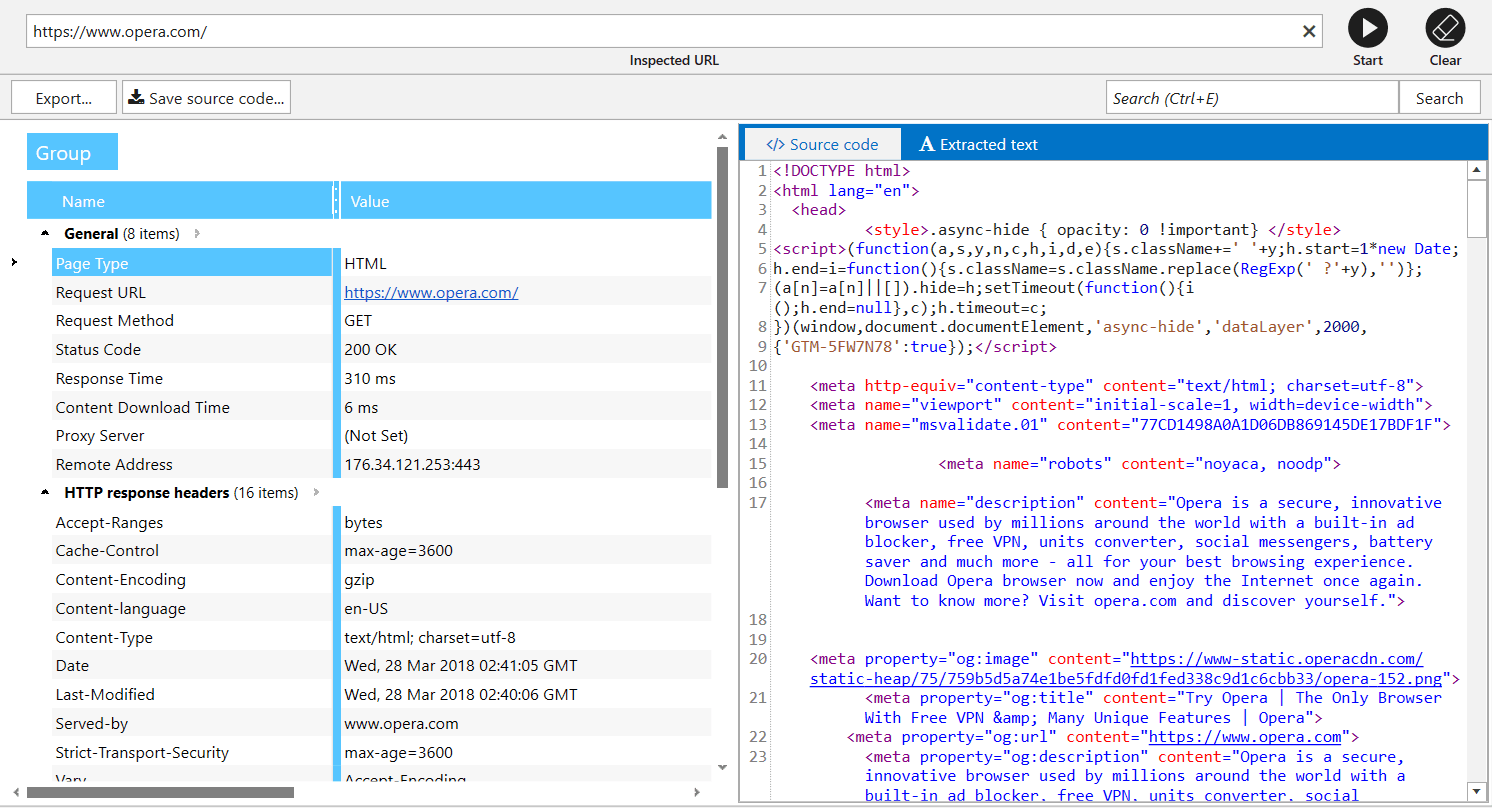
Sitemap Generator
In addition to the interface changes of this tool, it now creates Sitemaps only for compliant URLs. You no longer have to worry about disallowed pages being added to Sitemap by mistake.

14. Custom Templates for Settings, Filters / Segments, and Parameters
In Netpeak Spider
- Settings → These templates save information about all crawling settings tabs (except for ‘Export’, ‘Authentication’, and ‘Proxy’) and allow you to switch between them in 2 clicks. Note that we have default templates you can use for various tasks.
- Filters and Segments → Create your own templates if you often use the same conditions for data segmentation and filtering.
- Parameters → You can find these templates on ‘Parameters’ tab of
sidebar .
15. Virtual robots.txt
If you need to test new robots.txt file and check how search engine robots will understand it, you can try ‘Virtual robots.txt’ setting. Netpeak Spider will use this virtual file instead of the file in root directory of your website.
16. Combining All of the Crawling Modes into One
In a new program version you can add URLs for crawling in the following ways:
- By crawling the website → simply add a URL
into the ‘Initial URL’ field and press ‘Start’ button: pages will be added according to the crawling progress. - Manually → this way a separate window with text input will be opened for you to add URLs list with each URL on a new line.
- From file → we significantly modified this function and added URL import from files with such extensions: .xlsx (Microsoft Excel), .csv (comma-separated values), .xml (Extensible Markup Language), .nspj (Netpeak Spider project) and .ncpj (Netpeak Checker project).
- From XML Sitemap → XML Sitemap validator will be opened, so that you can import URLs for crawling in the main table.
- From clipboard → simply use Ctrl+V combination with program’s main table opened, URL list from clipboard will be added to the table and notification with brief summary information will appear (what is successfully added, what is already in the table, what is not added because of bad URL format).
- Drag and Drop → you can simply transfer project or any other file with extensions mentioned above from file straight to the main table: Netpeak Spider will analyze files and upload necessary data.
17. List of URLs, Skipped by Crawler
For the cases when your site can’t be properly crawled, we’ve released the following features:
-
URL you’ve entered to ‘Initial URL’ field will be always added to the table. This way, you will know if this URL redirects to another website or simply unavailable at the moment.
-
‘Skipped URLs’ tab will appear only if some pages were ignored while crawling. Here you will see URLs and the reason why they were skipped: for example, you’ve enabled considering indexation instructions from
robots.txt file, applied crawling rules or disabled checking some ofcontent types.

18. Quick Search in Tables
- Ctrl+F → filter settings
- Ctrl+Shift+F → segment settings
19. Delaying Comprehensive Data Analysis
All comprehensive data arrays were moved to a single module – one more unique feature of new Netpeak Spider. Using this module, you can view massive lists of:
- incoming, outgoing, internal, and external links
- images
- issues
- redirects
- Canonical,
- H1-H6 headers
20. New ‘Parameters’ Tab with Search and Scrolling to Parameter in Table
Parameters setting has been moved from crawling settings to ‘Parameters’ tab in
If you have already got results in the main table, you can click on a parameter (or use ‘Scroll to’ button on this panel) to quickly reach the corresponding parameter in the current table.
21. Monitoring memory limit for data integrity
Summary
Netpeak Spider 3.0 has transformed into a super fast tool, allowing you to work with huge websites and conduct comprehensive SEO analytics without any setbacks. Compared to the previous 2.1 version, we've improved memory consumption by 4 times and 30 times reduced crawling time (by the example of a large sites scanning). And of course, you can find information about all Netpeak Spider improvements and crawling comparison by technical specifications between Netpeak Spider 3.0 and its main competitors in a detailed post on Netpeak Software blog.

 9
9
 3
3
 6
6
Related Articles
How to Set Up Consent Mode in GA4 on Your Website with Google Tag Manager
Let's explore how to properly integrate consent mode in GA4, configure it for effective data collection, and at the same time comply with GDPR and other legal regulations
Display Advertising Effectiveness Analysis: A Comprehensive Approach to Measuring Its Impact
In this article, I will explain why you shouldn’t underestimate display advertising and how to analyze its impact using Google Analytics 4
Generative Engine Optimization: What Businesses Get From Ranking in SearchGPT
Companies that master SearchGPT SEO and generative engine optimization will capture high-intent traffic from users seeking direct, authoritative answers