There is a serious amount of tasks for search optimization can be and have to be automatized. For example, gathering information, creating lists of products, analysing competitors’ price, checking implementation of technical tasks. An advanced automatization of usual everyday tasks through parsing helps to avoid headache and save hundreds of hours of routine work.
Parsing is the process of automatic gathering and extraction of information from online resources.
First, I have to remind you: learning and competent configuration of parsing tools will take a lot of time: it will be much longer than doing it manually. However, it’s a common problem when you start to use some new tools. So the main thing is just to make a first step!
During the whole period of work at Netpeak, I’ve got acquainted with many parsing techniques. In this post, I want to tell you about the tools I use for site optimization and what problems they can solve, moving from easy to complicated decisions.
1. Google Spreadsheet
Google Spreadsheet implementation can help you to extract simple elements of site for comparison and composing, but for small amounts of data only. In particular, these are: title, description, keywords, h1 headers, product codes, prices, texts, data spreadsheets. This free tool is approached for low volume tasks. For example, creation of file for tracking text and h1 headers availability.
There are two simple functions:
- =importhtml — for data import from tables and lists.
- =importxml — for data import from any of various structured data types including XML, HTML, CSV, TSV, RSS, ATOM XML.
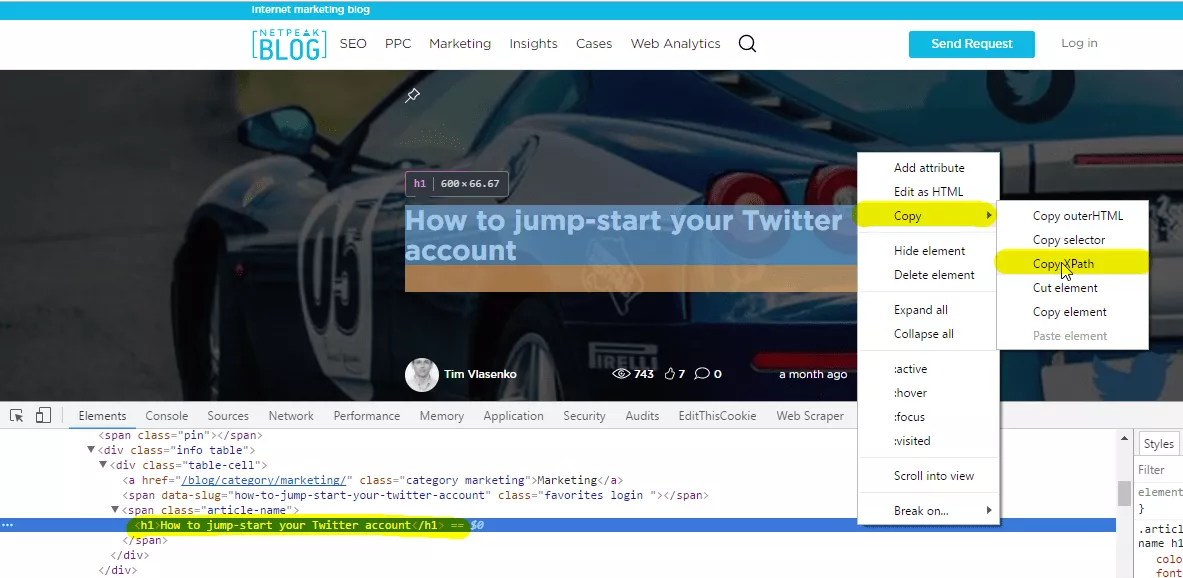
For using =importxml you need to know XPath. But if you don’t want to spent time on documentation, you can use browser debugger.
To run the debugger, do right-click on page element and choose “Inspect”, or press F12.
When debugger is opened, press Copy->Copy XPath. Copied XPath should be pasted in function =importxml.
Disadvantages
Every month processing of function =importxml is worsening.
Earlier data for ~500 URL could be parsed at the moment, now it is difficult to parse ~50 URL.
Advantages
- Automatic update with opening the file;
- Automatic updating by time can be set (a minute, an hour, a day);
- During parsing extracted date might be converted and reports, examples, visualization might be done at the same time.
Examples of use
For example, using function =importxml in real time meta information (title, keywords, description, h1) and number of comments under articles might be collected:
In column A — cells with links to chosen pages.
Title tag for column A2 is imported by query =IMPORTXML(A2;"//title").
Description meta tag:
=IMPORTXML(A2;"//meta[@name='description']/attribute::content").
H1 tag is imported by query =IMPORTXML(A2;"//h1").
Author: =IMPORTXML(A2;"//a[@class='author-name']").
Date of publication: =IMPORTXML(A2;"//div[@class='footer']/span").
Number of comments under chosen post: =IMPORTXML(A2,"//span[@class='icon-comment']")
Using function =importhtml also can be extracted a lot of interesting data, for example, general information from Wikipedia about required objects.
2. Netpeak Spider
Netpeak Spider is the desktop software for site crawling which is oriented on SEO-issues search. It includes an capability to parse data from html-pages.

Sometimes, when SEO specialist use regular crawling, it’s not enough data for analysis. Netpeak Spider helps to find error 404 pages, pages with missing Title tags and additionally prices on product cards might be parsed.
As a result products cards without prices might be founded. Based on this information you can make a decision what to do with these product cards — delete, close for scanning/indexation or do nothing.
Also texts on landing pages might be imported using CSS-selector or class, where they are situated.
Pricing: $14 per month or $117 per year (-30% discount).
Disadvantages
- No connection by API;
- No opportunity to update data by scenario.
Advantages
- There is a capability to add a list of URLs for parsing or just crawl the whole site.
- 15 parsers with unique settings might be run at the same time.
- Pages without requested data can be filtered.
- All unique contains, their number and length are shown.
- Besides data parser you’ll get a tool for complex SEO site analysis.
2.1. Examples of use
2.2.1. Pricing parsing
Task:
to know prices of products.
Decision
First of all you need to find an element which will be extracted. In our case it is an element with class “price nowPrice”:
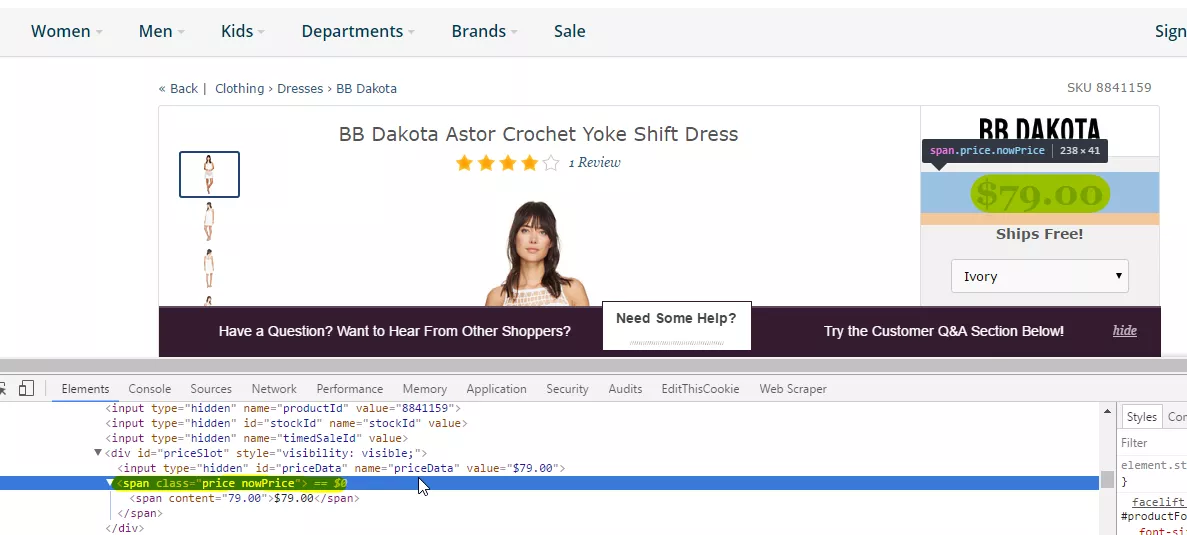
Then “Copy”->”Copy xPath”.
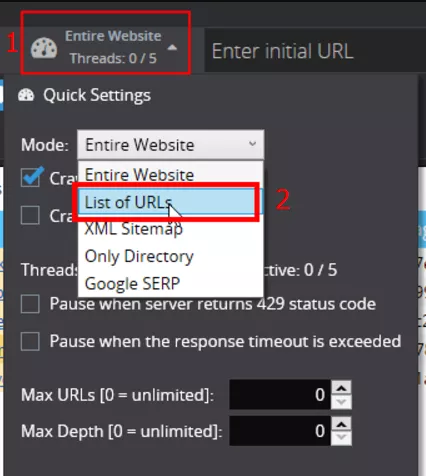
Next step is to run Netpeak Spider and choose “List of URLs” crawling mode:
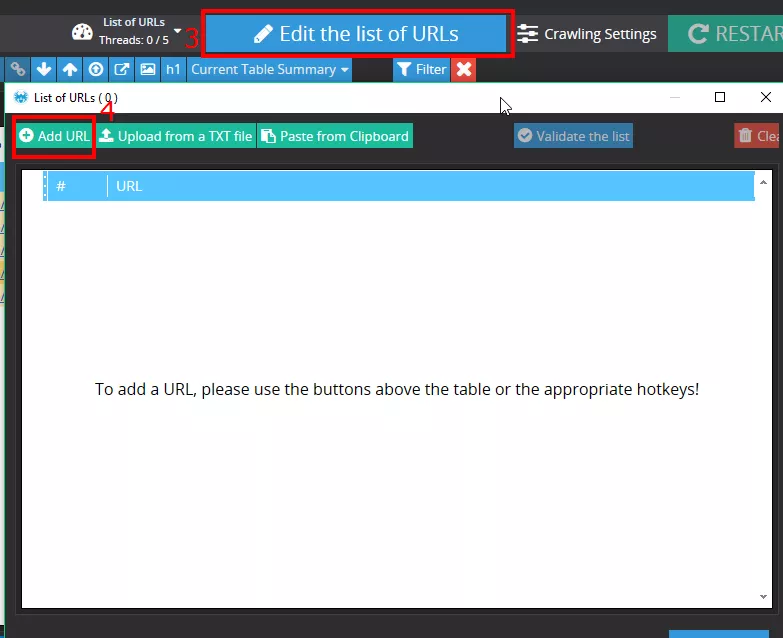
Then go to “Crawling Settings” on tab “Custom Search” and choose “Use custom search”:
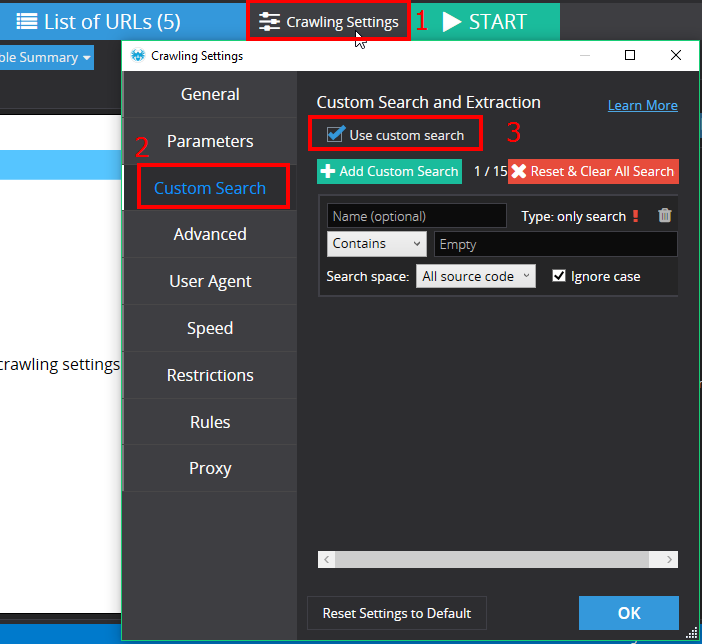
It’s time to set configuration for search — in our case we use XPath: //*[@id="priceSlot"]/span
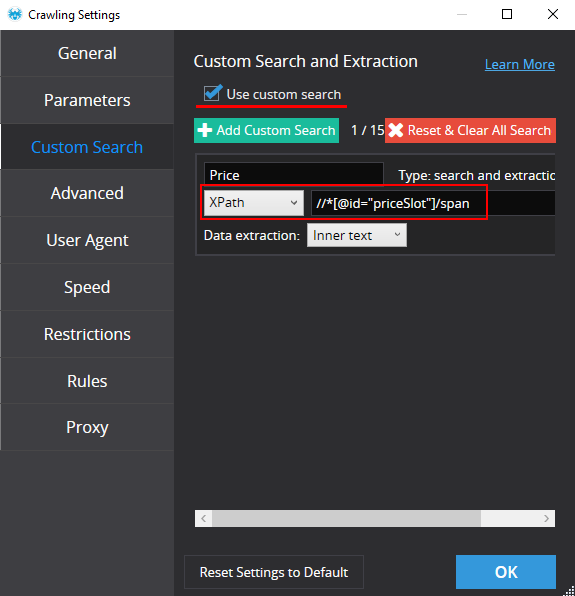
Push “Start”.
Results
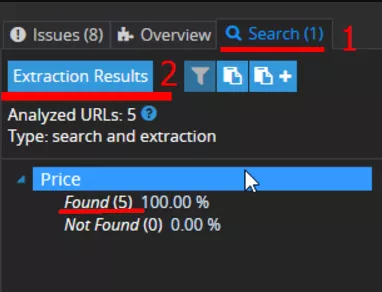
- Spider has founded a price on each page — you can see a report, if you click the “Extraction results” button.
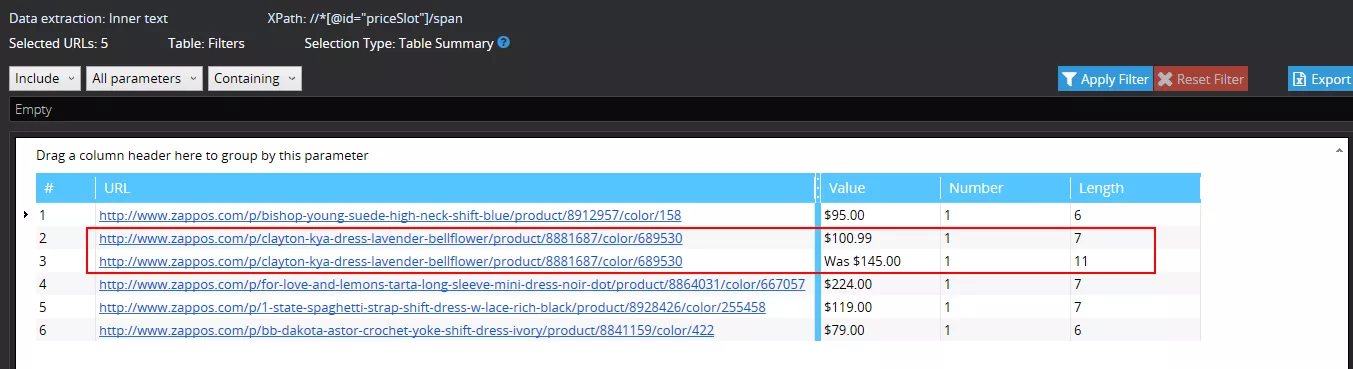
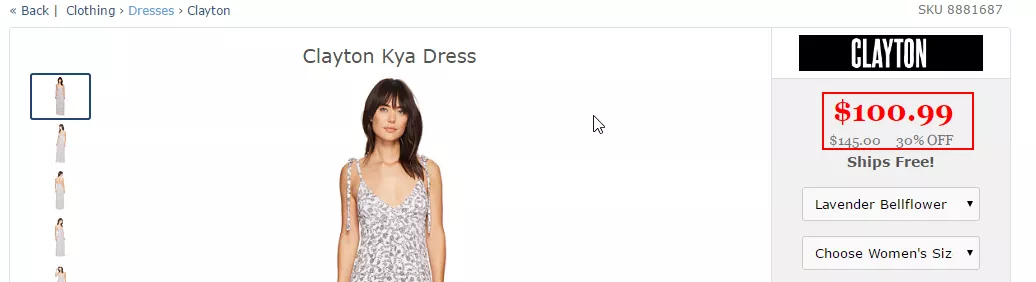
- On page http://www.zappos.com/p/clayton-kya-dress-lavender-bellflower/product/8881687/color/689530
two prices were found - an old one and current price:
2.2.2. Checking of GTM code implementation
Task
To check integration GTM code and answer to two questions:
- Is GTM code available on each page of the site?
- Is tracking ID the same on each page?
URL’s:
https://netpeak.net/blog/category/seo/
https://netpeak.net/blog/category/ppc/
https://netpeak.net/blog/category/analytics/
https://netpeak.net/blog/category/marketing/
Decision
Firstly we need to understand which element is responsible for GTM code. In our case we will extract tracking ID using regular expression.
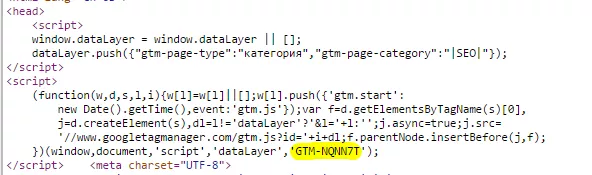
Run Netpeak Spider, add the list of URLs, go to “Crawling Settings” on tab “Custom Search” and choose “Use custom search”: ['"](GTM-\w+)['"]
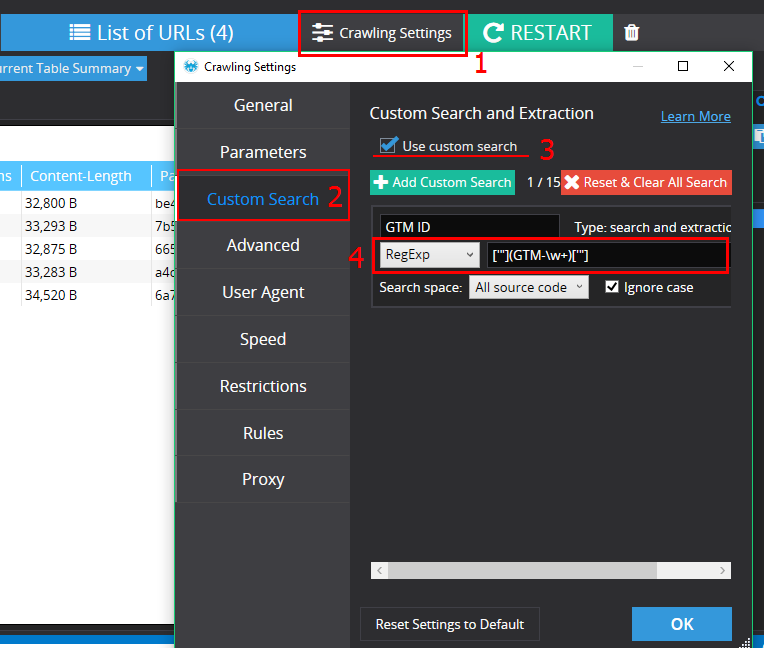
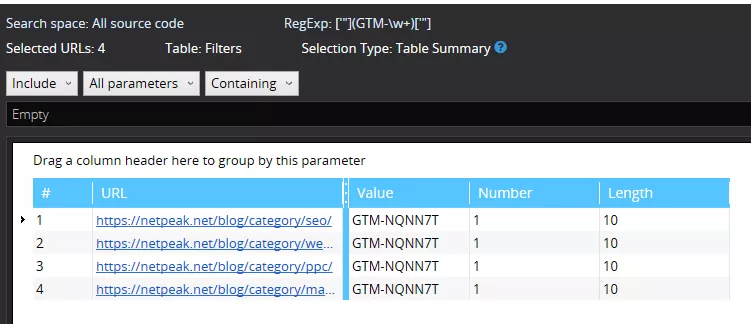
GTM code is implemented and the tracking ID is right and the same on each page.
To find out more about using Netpeak Spider read full review of functions in post Netpeak Spider 2.1.1.4: Custom Search and Extraction
3. Web Scraper
Web Scraper is a free browser extension for Chrome. Using this extension you can create a plan (sitemap) how a web site should be traversed and what should be extracted. Using these sitemaps the Web Scraper will navigate the site accordingly and extract all data. Scraped data later can be exported as CSV.
Disadvantages
- No integration by API, that mean for data updating Web Scraper have to be run again. Projects are saved in browser, so there is an opportunity to save project in JSON.
- Limitation: one thread. For example, 2000 URLs are parsed during more than 1 hour.
- Web Scraper can be used in Chrome only.
Advantages
- Convenient, simple and user-friendly interface.
- It can extract data from dynamic pages which use Javascript and Ajax.
Example of use
Task
To parse information about product card.
A plan of traverse show a logic of parsing:
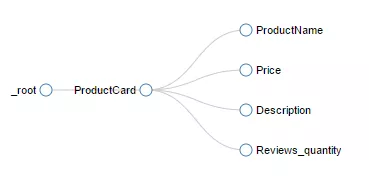
Decision
Parsing Elements:
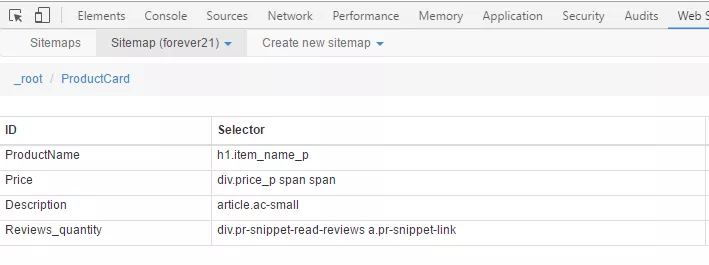
After ending of parsing you will be able to get data in the next format:
Information to learn:
4. Google Spreadsheet + Google Apps Script
Google Apps Script - is a scripting language based on JavaScript that lets you create new functions and apps for work with Google Docs, Google Sheets, and Google Forms. It is free to set up a bunch.
Disadvantages
You have to know JavaScript programming language.
Advantages
After spending time on reports setting you will be able to reaсt quickly on data changes.
What tasks might be solved?
Google Spreadsheet together with Google Apps Script might give you receiving and updating data in real-time. It’s useful to follow your competitors and set alerts when something is changed, for example titles. Also price monitoring might be set.
Example of script for price tracking.
Conclusions
For flexible and effective using of free parsing tools you have to know at least XPath, and for advanced - to know bases of JavaScript. In addition, paid tools, as Netpeak Spider, offer more interesting capabilities (for example using of 15 threats at the same time).
Many questions connected with parsing were solvable using “Kimono”, but after closing cloud service it became not so attractive for SEO specialists.
Let me know in comments below what tools you are using for parsing and what tasks they help to solve.

 0
0
 0
0
 0
0
Related Articles
Display Advertising Effectiveness Analysis: A Comprehensive Approach to Measuring Its Impact
In this article, I will explain why you shouldn’t underestimate display advertising and how to analyze its impact using Google Analytics 4
Generative Engine Optimization: What Businesses Get From Ranking in SearchGPT
Companies that master SearchGPT SEO and generative engine optimization will capture high-intent traffic from users seeking direct, authoritative answers
From Generic to Iconic: 100 Statistics on Amazon Marketing for Fashion Brands
While traditional fashion retailers were still figuring out e-commerce, one company quietly revolutionized how U.S. consumers shop for everything from workout gear to wedding dresses