Преди време публикувах няколко материала за работа с Google BigQuery. В тази статия ще разкажа за предимствата и спецификите на тази услуга, а също и за допълнителни инструменти за BigQuery.
Google BigQuery е облачна база данни с изключително висока скорост на обработка на огромни масиви от данни.
Как да започнем работа в Google BigQuery
Влезте в Google Cloud Platform. При първото стартиране системата предлага да активирате безплатен пробен период и да получите кредит от $300 за 12 месеца. Честно казано, за да изразходвате в BigQuery такава сума за една година, ще Ви се наложи много да се постараете. За да продължите работа, трябва да въведете данни за плащане.
Натиснете «My Project».

След това — «Create project».
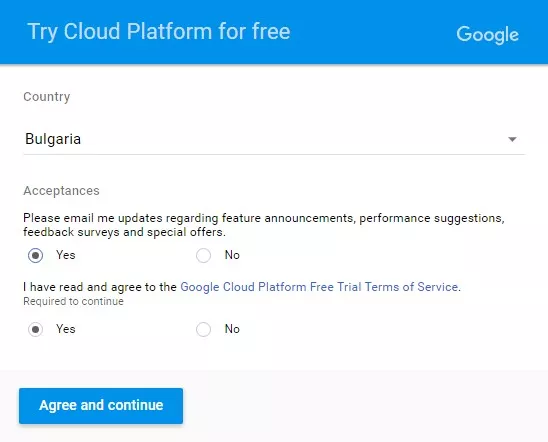
Приемете условията за използване на платформата.
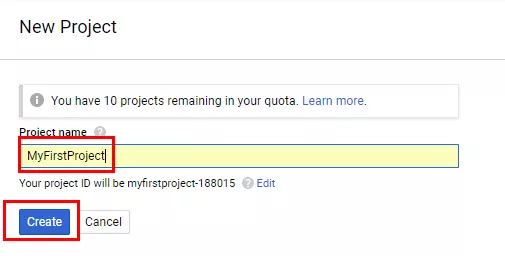
Накрая, дайте име на проекта, определете настройки за известия и още веднъж се съгласете с условията за използване на платформата.
След потвърждаването изчакайте няколко минути.
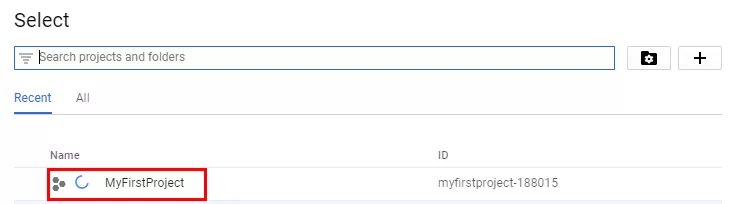
Скоро след това ще получите известие, че проектът е създаден. Преминете в раздела за плащане и свържете платежния акаунт.
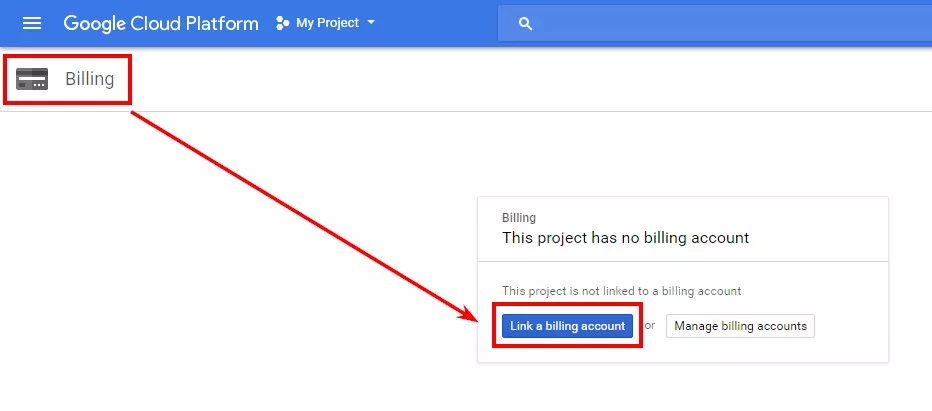
Сега проектът е свързан към току-що създадения платежен акаунт.
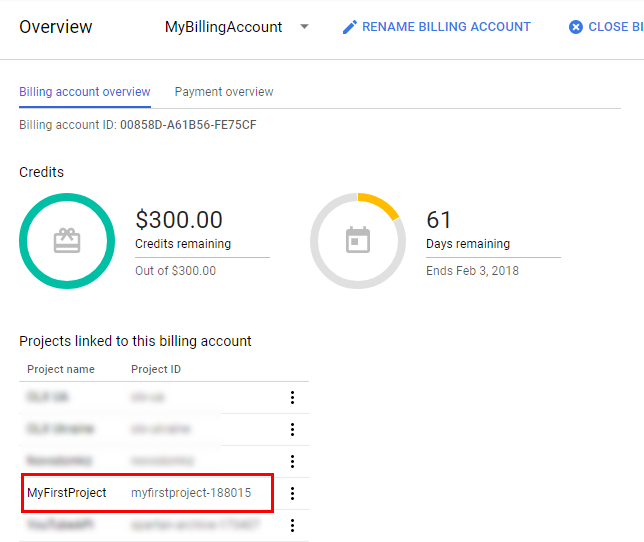
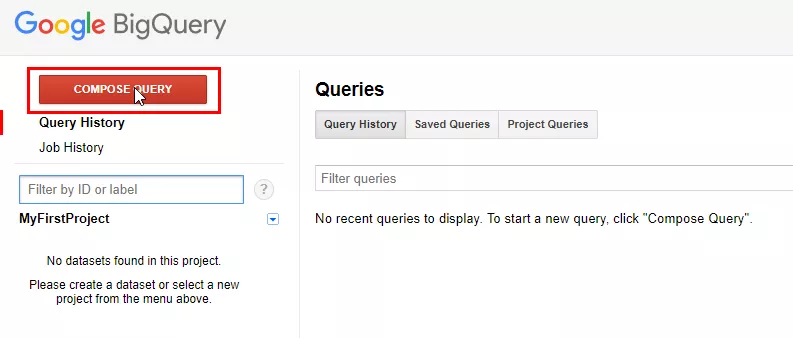
Преминете към интерфейса на Google BigQuery и напишете своята първа заявка.
За да отворите редактора на заявки, натиснете «Compose query» или «Ctrl + Space».
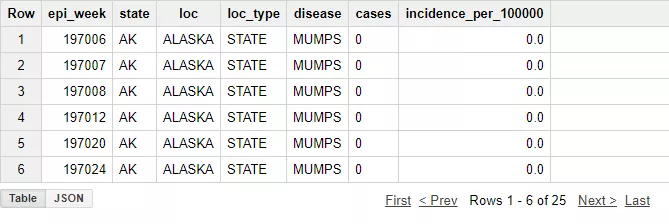
Да разгледаме как да напишем първата заявка, вземайки за пример публични данни в BigQuery. Вземете първите 15 реда от таблицата project_tycho_reports, която се намира в набора с публични данни lookerdata.
SELECT *FROM [lookerdata:cdc.project_tycho_reports]LIMIT 25Заявката ще върне резултат:
Защо е добре да изберете точно Google BigQuery
Скоростта — това е основното предимство на BigQuery, но не е единственото. BigQuery е облачна услуга. При нейното използване не е нужно да се наема сървър и да се плаща поддръжка.
Цената на BigQuery е значително под тази за наемане на най-елементарен сървър: дори ако много се постараете и ежедневно записвате в тази база данни милиони редове, едва ли ще можете да похарчите над $5.
Следващото предимство е простотата на използване. Във всяка друга система за управление на бази данни (СУБД), освен знания по SQL, се налага дълго да разучавате тънкостите при администриране и настройка на базата данни (БД).
И ако сам по себе си SQL-диалекта във всички БД е много подобен, то административната част обикновено навсякъде е различна.
В BigQuery цялата административна част е поета от Google. В тази платформа няма никакви настройки, индекси, ядра за обработка на таблици, тайм-аути или външни ключове. Реализирана е поддръжка само на една кодировка UTF-8.
За да работите с BigQuery, трябва да знаете само как да качите данни в BigQuery, и да имате базови знания по SQL.
Независимо от леката работа, в BigQuery се поддържат практически всички функции на СУБД:
прозоречни функции ;- съхранение на данни във вид на структури (нерелационни възможности);
- представяне и таблични изрази (common table expression).
Действително, в момента на публикуването на статията услугата не поддържа:
- рекурсивни заявки;
- създаване на съхраними процедури и функции;
- транзакции.
Специфики на SQL за Google BigQuery
BigQuery може да превключва между стандартен SQL и диалекти.
DML-операции INSERT, UPDATE и DELETE в момента се поддържат само при използване на стандартен SQL.
Още едно различие между тези диалекти е способът за вертикално обединяване на таблици. В стандартния SQL за целта служи операторът UNION и ключовата дума ALL или DISTINCT:
SELECT 12 AS A, 32 AS BUNION ALLSELECT 2 AS A, 29 AS BВ собствения SQL-диалект функционалността за вертикално обединяване на таблици е значително по-широка. Съществува специален набор от функции за подаване на таблици (Table Wildcard Functions).
За просто обединяване е достатъчно да се изброят имената на нужните таблици или подзаявките чрез запетая. Обединяването на заявки от примера по-горе на вътрешния SQL диалект в BigQuery ще изглежда така:
SELECT *FROM (SELECT 12 AS A, 32 AS B), (SELECT 2 AS A, 29 AS B)Превключвателят между SQL-диалектите в BigQuery се намира в интерфейса в блока с опции: натиснете бутона Show options под редактора на заявки.
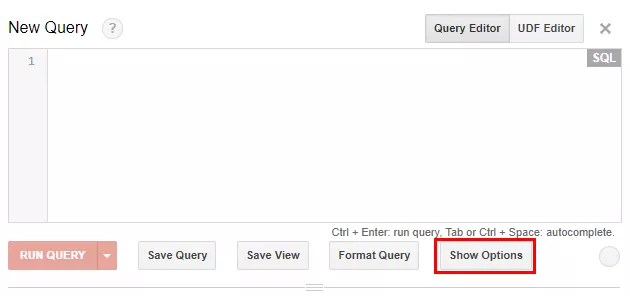
С помощта на чекчето «SQL Dialect» превключете нужния диалект.
Инструменти за работа с BigQuery
Ние вече изяснихме как се качват данни в базата и как да се обръщаме към данните с SQL заявки. Но едва ли бихте искали да взаимодействате с данни, като се ограничите само с тези възможности. По-скоро бихте зареждали данни за създаване на дашборд или нещо подобно.
Повечето популярни BI-системи и електронни таблици поддържат интеграция с Google BigQuery. Microsoft Power BI е интегрирана от юли 2017 година. Конекторът има доста бедни възможности: той не може да се обръща към съхранени изгледи или да изпраща в BigQuery заявки. Засега с помощта на вградения конектор може да се дърпат само плоски таблици.
Simba Drivers
Ако трябва да получите данни от Google BigQuery в електронна таблица или BI-система, която няма такива възможности за интеграция по подразбиране, използвайте безплатните Simba Drivers.
Този драйвер поддържа всички необходими възможности, включително превключване на SQL-диалекти.
Език R
Езикът R е един от най-мощните инструменти за работа с данни. Той може както да получава данни от Google BigQuery, така и да ги записва. За целта е най-удобен пакетът bigrquery.
За начало, инсталирайте език R. Също така, за удобство при работа с R, препоръчвам да се инсталира интегрираната среда за разработка RStudio.
Стартирайте RStudio и с помощта на съчетанието на клавиши «Ctrl+Alt+Shift+0» отворете всички достъпни в нея панели. Най-често трябват панелите Source и Console.
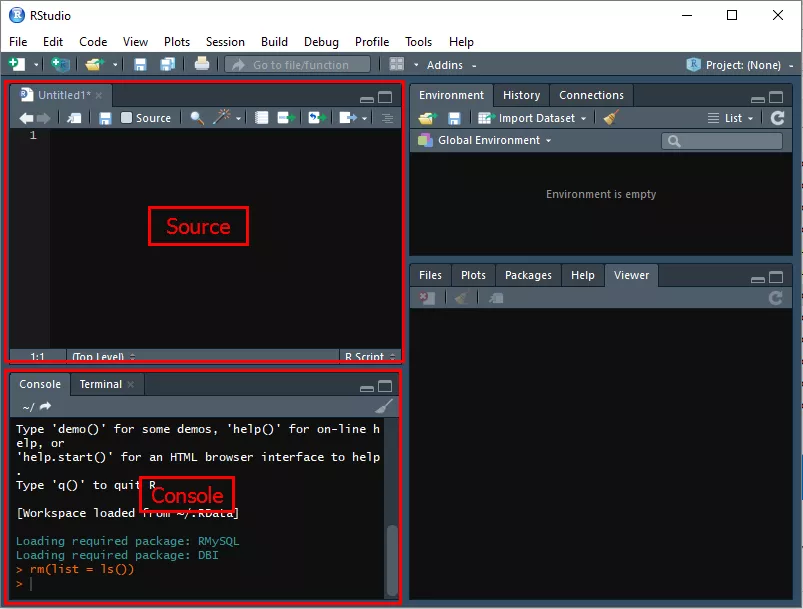
За да инсталирате develop-версията на пакета bigrquery, от репозитория на GitHub предварително инсталирайте пакета devtools. Въведете в прозореца Source кода, след това го отбележете (натиснете левия бутон на мишката) и натиснете «Ctrl+Enter», за да изпълните командата:
install.packages("devtools")Сега вече инсталирайте пакета bigrquery:
devtools::install_github("rstats-db/bigrquery")За да са достъпни функциите на пакета в R, след инсталирането ги включете с помощта на командата library или require. Например, да включим пакета bigrquery с помощта на кода:
library(bigrquery)Структурата на данни в Google BigQuery се състои от проект с набор от данни, съдържащи таблици. Проекта вече сте го създали, а сега, за да изпратите информация, създайте набор от данни. Изберете в интерфейса от падащото меню «Create new dataset».
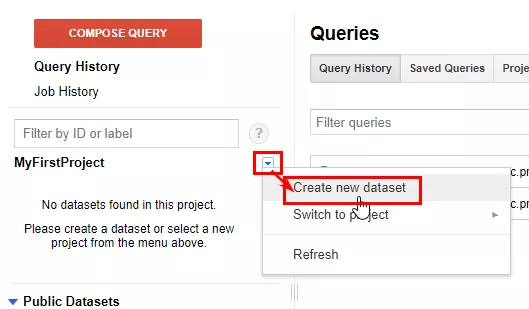
За да създадете набор от данни с помощта на езика R, използвайте команда insert_dataset. Командата иска само 2 аргумента:
project — ID на проекта (вземете го от URL-а в BigQuery).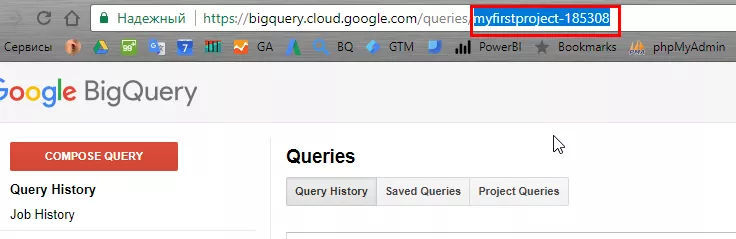
dataset — името на новия набор от данни.
Нека да създадем първия набор от данни с име myFirstDataSet. Въведете в областта Source показания по-долу код, отбележете командата с помощта на мишката и натиснете «Ctrl+Enter», за да го изпълните.
insert_dataset(project = "myfirstproject-185308", dataset = "myFirstDataSet")В прозореца Console в RStudio ще се появи запитване за създаване на акаунт, за да не трябва след това повторна верификация.
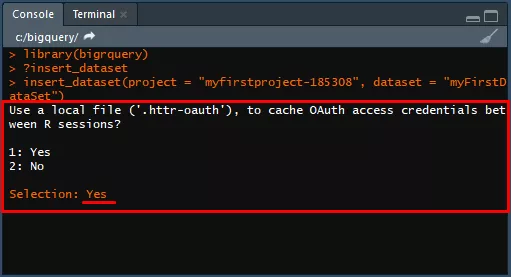
Въведете на Selection в Console отговор Yes и натиснете Enter. Ще се отвори браузър — разрешете достъпа до данни и получете кода за оторизация.
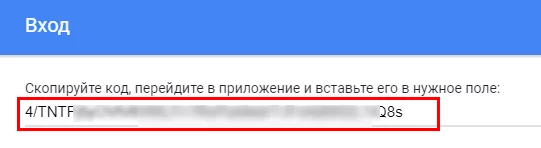
Копирайте генерирания код. След това го вмъкнете в Console RStudio в отговор на запитването за оторизационен код и натиснете Enter.
Отлично, Вие създадохте набор от данни.
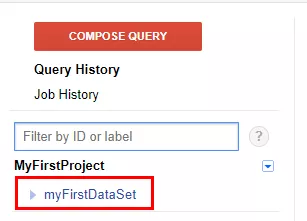
Сега запишете вградената в R таблица mtcars в набора с данни myFirstDataSet. За да предадете данни от R в BigQuery, в пакета bigrquery има функция insert_upload_job. Тя има такива аргументи:
project — ID на проекта (вижте или в URL-а на проекта, или в режим превключване на проекти).
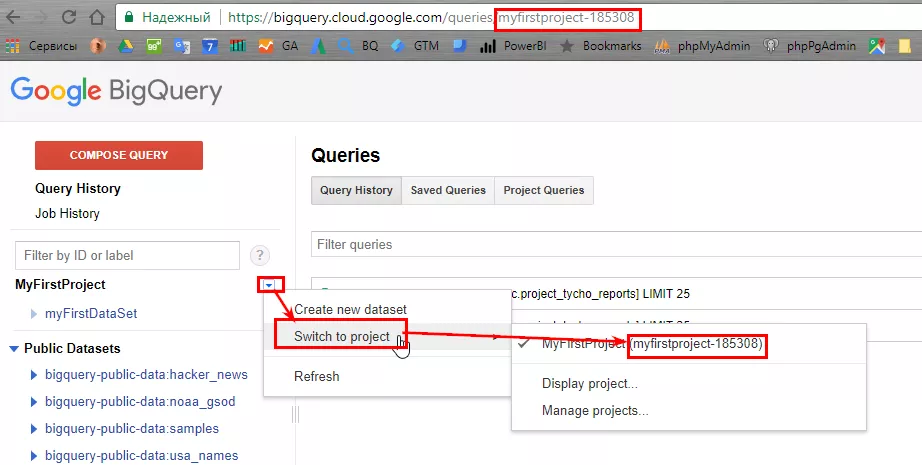
dataset — името на набора данни, където планирате да изпратите данните. В нашия случай myFirstDataSet.
table — име на таблицата със записани данни.
values — data frame (таблица с данни) в R с данни за предаване към BigQuery.
billing = project акаунтът за плащане на операции. По подразбиране — платежен акаунт, който е свързан с проекта.
create_disposition — опция за определяне на необходимите действия.
Ако в BigQuery няма таблица с определено в аргумента table име, въведете "CREATE_IF_NEEDED" — системата ще създаде нова таблица.
Ако поставите "CREATE_NEVER" и таблица с определеното име не се открива в набора от данни, ще бъде върната съответна грешка.
write_disposition — опция за избор на добавяне на данни в съществуваща таблица.
"WRITE_APPEND" — допиши данни в таблица.
"WRITE_TRUNCATE" — презапиши данни в таблица.
"WRITE_EMPTY" — запиши данни за празна таблица.
Кодът за предаване към BigQuery, вграден в R таблица mtcars:
insert_upload_job(project = "myfirstproject-185308",
dataset = "myFirstDataSet",
table = "mtcars_bigquery",
values = mtcars,
create_disposition = "CREATE_IF_NEEDED",
write_disposition = "WRITE_APPEND")
При успешно изпълняване на операцията, в R конзолата ще се появи допълнителна информация, а в интерфейса на BigQuery ще е създадена таблица mtcars_bigquery.
За извличане на данни от BigQuery в R в пакета bigrquery е предназначена функцията query_exec. Основни аргументи:
query — текст на SQL-заявка, резултатът от която искате да въведете в R.
project — ID на проекта за извличане на данни.
page_size — максимален размер на върнатия резултат в редове (по подразбиране 10 000).
max_pages — максимален брой страници, върнати от заявката (по подразбиране 10).
use_legacy_sql — избор на SQL-диалект за обработка на заявката.
По подразбиране е дадено значение TRUE с вътрешен диалект BigQuery.
За стандартен SQL диалект, въведете в този аргумент стойност FALSE.
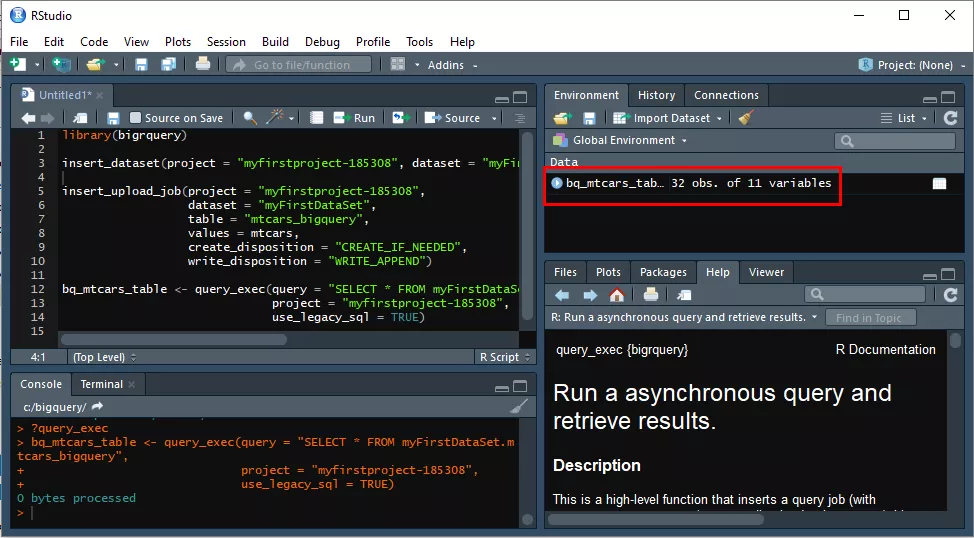
За обратно извличане на данни, които сте изпратили в BigQuery на предишната стъпка, въведете команда:
bq_mtcars_table <- query_exec(query =
"SELECT * FROM myFirstDataSet.mtcars_bigquery",
project = "myfirstproject-185308",
use_legacy_sql = TRUE)В работното обкръжение (чието описанието виждате в прозореца Environment) ще се появи нов обект - bq_mtcars_table.
Изводи
Google BigQuery е лесен и в същото време изключително мощен инструмент за съхраняване и обработка на данни. Това е облачна база данни с поддръжка на повечето функции в СУБД.
Услугата излиза значително по-евтино от купуване, поддръжка и администриране на сървър за безплатни бази данни (MySQL или PostgreSQL).
Надявам се, моят цикъл от инструкции за начало на работата с Google BigQuery, да облекчи Вашата работа.
Успех при работата с Big data!

 1
1
 1
1
 0
0