Събирането на информация и различни данни от уебсайтове е от голямо значение за всякакви дейности, свързани с SEO. Това обаче в доста от случаите може да се окаже не толкова лесна задача.
Въпреки че може да разчитаме на инструменти като Netpeak Spider и Screaming Frog, използването на XPath ни позволява да търсим и идентифицираме конкретно съдържание, вместо да експортираме абсолютно всичко.
С негова помощ можем да изберем всяко едно съдържание или елемент от HTML изходния код на даден документ, включително атрибути, таблици или мета тагове. Точно поради тази причина в това ръководство ще разгледаме какво е XPath, как да го използваме и защо улеснява живота на SEO специалистите, макар на пръв поглед да изглежда доста сложно за много хора.
Какво е XPath
XPath (XML Path Language) е език разработен от W3C, който ни позволява да съставяме изрази, чрез които да адресираме отделни части от XML (Extensible Markup Language) документи, да задаваме критерии, на които могат да отговарят определени възли от данни, и да извличаме информация от тях.
XPath изразите могат да се използват в HTML, JavaScript, Java, PHP, Python, C, C++ и други езици.
Това ги прави универсален инструмент за извличане на данни.
Как всъщност работи XPath
XPath изразите работят чрез навигиране през йерархичната структура на XML документ, като указват местоположението на елементите, и изглеждат подобно на файловите пътища на компютъра. Състоят се от поредица от стъпки, всяка разделена с наклонена черта «/», които показват връзката между елементите в документа. Стъпките могат да бъдат определени с помощта на различни типове изрази, включително имена на елементи, атрибути и текстови стойности. Нека да разгледаме следния XML документ за пример:
<countries>
<country id="1">
<name>България</name>
<capital>София</capital>
</country>
<country id="2">
<name>Португалия</name>
<capital>Лисабон</capital>
</country>
<country id="3">
<name>Великобритания</name>
<capital>Лондон</capital>
</country>
</countries>
За да изберем името на първата държава от този пример (т.е. България), XPath изразът ще бъде:
/countries/country[1]/nameТози израз се състои от три елемента:
- /countries - основния елемент на този документ;
- /country[1] - първия «country» елемент под «countries»;
- /name - елемента «name» под вече избрания «/country[1]».
Основен синтаксис на XPath
Израз | Действие |
/ | Избира основния възел и също се използва като разделител на пътя. |
// | Избира възли в документа, които отговарят на израза, независимо къде се намират. |
. | Избира текущия възел. |
.. | Избира «родителя» на текущия възел. |
@ | Избира атрибути. |
При XPath изразите могат да бъдат използвани различни «оператори», подобни на филтри, които ни помагат да изберем възли въз основа на някакви условия. Пример за няколко такива оператори:
XPath (Относителен) | Действие |
//a[1] | Избира първия елемент <a>. |
//a[last()] | Избира последния елемент <a>. |
//a[@netpeak] | Избира всички елементи <a>, които имат атрибут «netpeak». |
//a[@netpeak='seo'] | Избира всички елементи <a>, които имат атрибут «netpeak» със стойност «seo». |
//a[leva>10.00] | Избира всички елементи <a> с елемент «leva» и стойност по-голяма от 10. |
Различните типове XPath
Както вече разбрахме, XPath изразите са съставени от описания на пътища до конкретни възли и критерии, на които същите тези възли трябва да отговарят. Пътищата от своя страна могат да бъдат описани по абсолютен или относителен начин, като това определя в какъв контекст се изпълнява XPath заявката.
1. Absolute (Абсолютен) XPath
Съдържа пълния път от началния до избрания елемент. Ключова характеристика на абсолютният XPath е, че започва с една наклонена черта «/», която обозначава основния възел.
Нека да използваме за пример статия от блога на Netpeak и връзка, която се намира в текста.


Абсолютният XPath на тази връзка изглежда по следния начин:
/html/body/div[2]/div[2]/div[1]/div[2]/p[1]/a💡 Недостатък на абсолютният XPath е, че ако бъдат направени промени в пътя до избрания елемент, той няма да работи коректно.
2. Relative (Относителен) XPath
Започва с двойна наклонена черта «//». Чрез него може да търсим различни елементи, които се съдържат на дадена страница, без да се налага да пишем дълъг и сложен XPath. Относителният XPath е по-скоро препратка към избрания елемент.
Ако вземем предвид отново същата връзка от примера по-горе, то нейният относителен XPath ще бъде:
//div[@id="post_content"]/p[1]/a
Използване на XPath за SEO
Благодарение на XPath можем да извличаме най-различни данни от уебсайтовете за целите на SEO, като например мета тагове (Title, Description, Keywords и H1), хлебни трохички и други. Възможно е също да анализираме съдържанието на страниците, динамично да обновяваме информация за уебсайтa, автоматично да извършваме проверка на конкретни типове информация и още много.
XPath Cheat Sheet за SEO специалисти
Преди да съставим или използваме собствени XPath изрази за различни страници и елементи, ето един полезен списък с универсални такива, които могат да се използват за почти всеки уебсайт.
Елемент | XPath (Относителен) |
Заглавие на страница (Meta Title) | //title |
Мета описание (Meta Description) | //meta[@name='description']/@content |
AMP URL | //link[@rel='amphtml']/@href |
Каноничен адрес (Canonical URL) | //link[@rel='canonical']/@href |
Robots (Index/Noindex) | //meta[@name='robots']/@content |
H1 | //h1 |
H2 | //h2 |
H3 | //h3 |
Всички връзки от страница | //@href |
Пълен hreflang (връзка + стойност) | //*[@hreflang] |
Стойностите на атрибута hreflang | //link[@rel='alternate']/@hreflang |
Видове структурирани данни (Structured Data) | //*[@itemtype]/@itemtype |
Лесни начини за откриване на XPath
Един от най-лесните и бързи начини да намерим определен XPath е да използваме «Inspect Element» опцията на Google Chrome или друг браузър.
Посочваме или маркираме елемент от уебсайта, за който искаме да намерим XPath, след това щракваме с десния бутон върху него и избираме «Inpect/Инспектиране».
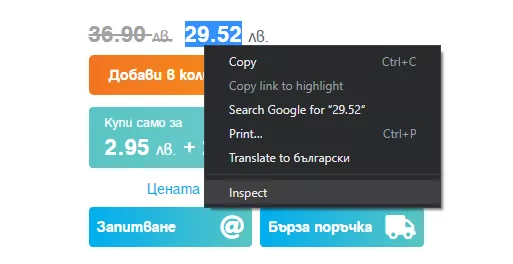
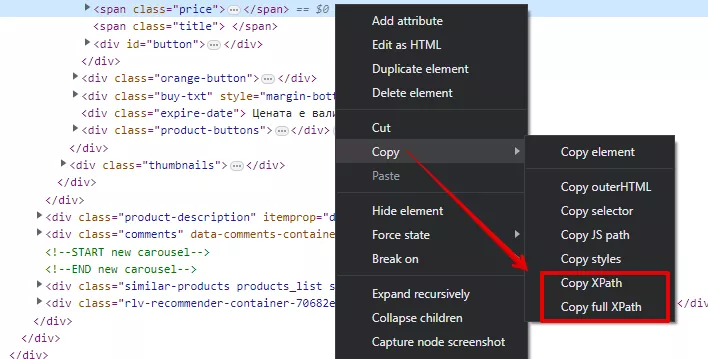
В HTML изходния код отново кликваме с десния бутон върху желания елемент и избираме «Copy/Копиране», а след това «Copy XPath/Копиране на XPath» или «Copy full XPath/Копиране на пълния XPath».
«Copy Xpath» ще копира относителния XPath на елемента, а «Copy full XPath» - абсолютния.
Друг също много лесен метод да намерим XPath e като използваме различни разширения за браузъра. Пример за подобно разширение е «XPath Helper», което може да изтеглим от Chrome Web Store.
След инсталирането на това разширение много лесно - чрез клавишна комбинация Ctrl-Shift-X (Command-Shift-X в macOS) или щракване върху бутона XPath Helper в лентата с инструменти на браузъра, ще отворим конзола. Вече само при посочване на елемент от страницата и натискане на клавиша Shift конзолата веднага ще ни покаже неговия XPath.

Как да извличаме данни с помощта на XPath
Извличането на данни от уебсайтовете за одити, анализи, актуализации на съдържанието и разрешаване на проблеми може да бъде подобрено чрез комбиниране на XPath с инструменти като Netpeak Spider, Screaming Frog и дори Google Sheets. Ето как да конфигурираме техните настройки за тази цел:
XPath & Screaming Frog
Oт менюто на Screaming Frog избираме Configuration > Custom > Extraction.
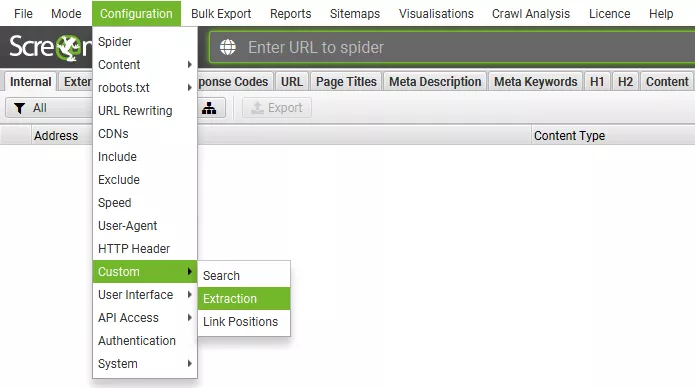
След това ще изскочи прозорец за конфигуриране на персонализирано извличане, където щракваме върху бутона «Add» в долния десен ъгъл, за да добавим ново условие.
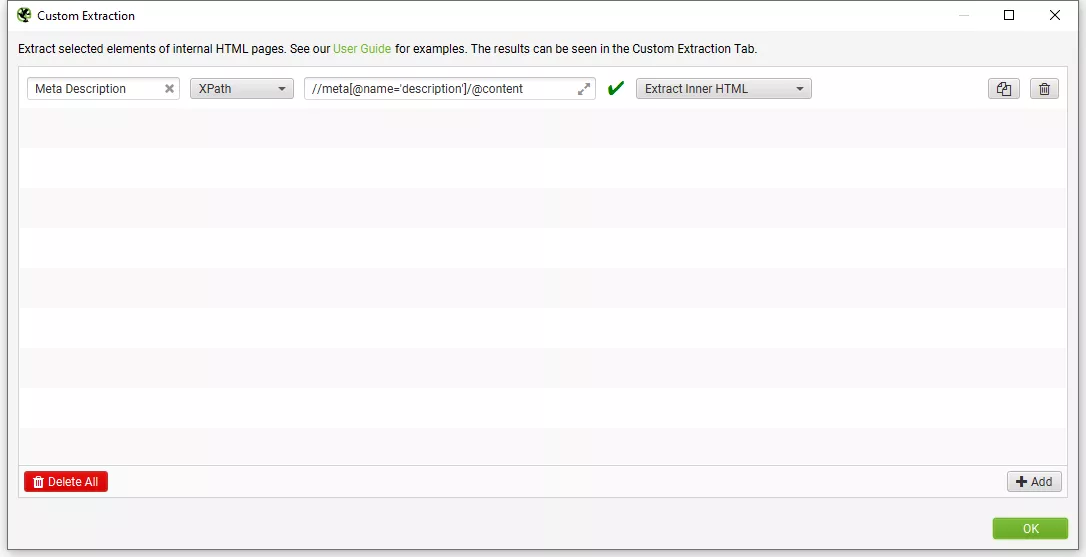
Наименуваме добавеното условие, избираме «XPath» от падащото меню, въвеждаме желания XPath израз, и от следващото падащо меню избираме типа данните, които ще извличаме.
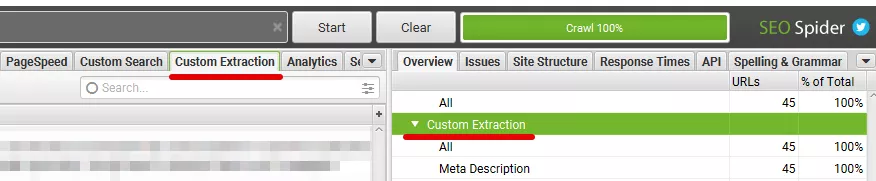
Възможно е да добавяме няколко различни условия и XPath изрази, за да извършим множество персонализирани извличания наведнъж. Това се осъществява отново чрез бутона «Add».
→ Сканираме уебсайта или страниците, които желаем, и може да видим резултатите в «Custom Extraction».
XPath & Netpeak Spider
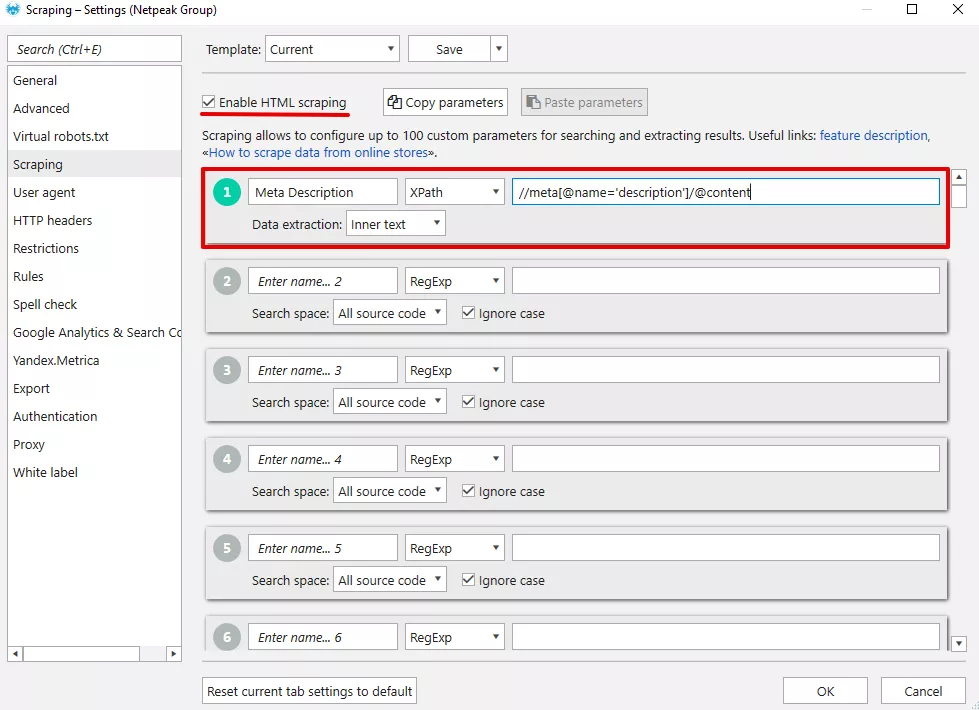
От горното меню на Netpeak Spider избираме «Settings», а след това «Scraping»
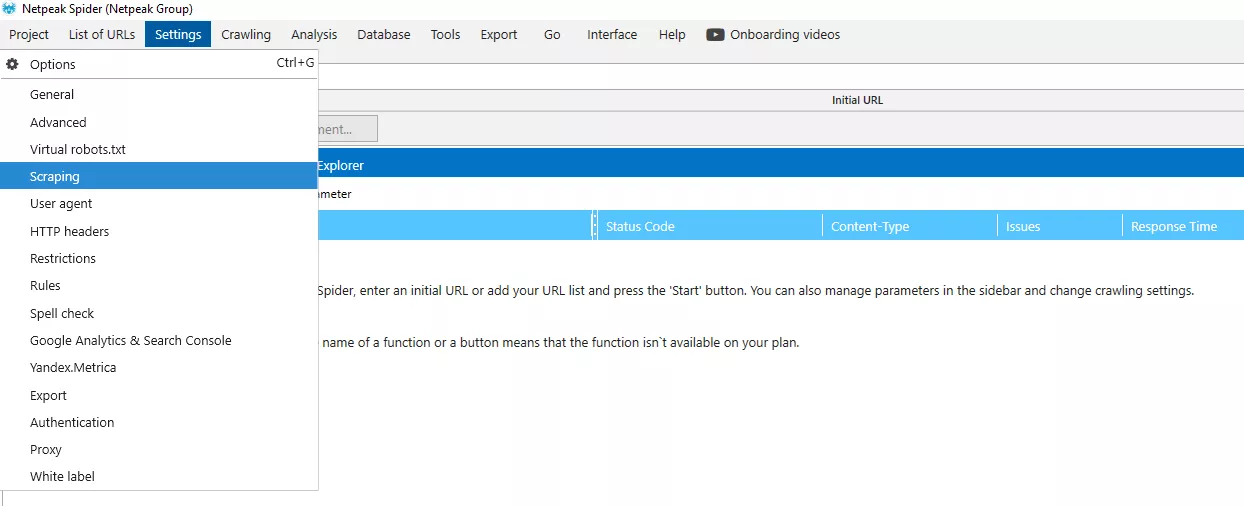
Тук отново именуваме добавеното условие, избираме «XPath» от падащото меню, въвеждаме желания XPath израз и от падащото меню при «Data extraction» избираме типа данни, които ще извличаме.
Важно е преди да конфигурираме условието, да поставим отметка на «Enable HTML scraping».
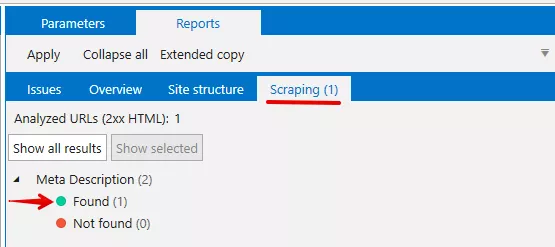
Сканираме уебсайта или страниците, които желаем, а след това може да видим резултатите в отчетите:
XPath & Google Sheets
XPath може да бъде използван и много лесно в Google Sheets чрез формулата IMPORTXML по следния начин:
=IMPORTXML("URL","XPath")При формулата:
- URL - заменяме с конкретен URL адрес или взима стойност от клетка в таблицата;
- XPath - заменяме с желан XPath израз.
Отваряме Google Sheets и създаваме нова таблица. За целта на този пример ще въведем избран адрес в клетка А2, а формулата IMPORTXML с XPath израза ще съставим в клетка B2.
Например, за да извлечем Meta Title от блога на Netpeak, е необходимо да използваме XPath израз «//title». Така формулата, която трябва да съставим, изглежда по следния начин:
=IMPORTXML(A2,"//title")
Ако желаем да използваме друг XPath израз, е необходимо просто да го добавим към формулата IMPORTXML, както направихме с «//title» по-горе.
Ето още няколко примера за използването на формулата с други XPath изрази:
1. =IMPORTXML("https://netpeak.net/bg/blog/", "//meta[@name='description']/@content")
2. =IMPORTXML("https://netpeak.net/bg/blog/", "//h1")
3. =IMPORTXML("https://netpeak.net/bg/blog/", "//link[@rel='canonical']/@href")При съставяне на формулата е добре да обърнем внимание, че URL адресът и XPath изразът трябва да бъдат оградени в кавички. Ще разберем, че са форматирани правилно, когато са оцветени в зелено.
Заключение
Надявамe се, че това ръководство не ви е накарало да се изплашите от XPath, а ви е помогнало да научите неговите основи и колко полезен може да бъде всъщност в работата на SEO специалистите. Имайте предвид, че ако за първи път се сблъсквате с XPath, e напълно нормално да изпитвате някои затруднения при използването му в началото, но ви гарантираме, че след като го овладеете, той ще бъде като магически трик в ръкава ви.

 37
37
 2
2
 14
14