Вътрешни дублирани страници - как да се справим с тях?
Представете си следната ситуация: в сайта си имате страници с два различни URL адреса, които обаче имат напълно еднакво съдържание. Смятате ли, че всичко е наред? Ако сте отговорили с “не”, то сте напълно прави - Google никак, ама никак не обича дублажите.
В настоящата статия ще се запознаем с начините на откриване, дефиниране и отстраняване на дублирани вътрешни страници, за да избегнем проблеми с “всемогъщата” търсачка.
Настанете се удобно!
Дублирани страници - дефиниция и видове

Дублирани страници - това са отделни страници от сайта, чието съдържание напълно или частично съвпада. Обикновено те представляват копие на цяла страница или на конкретна част от нея, и са достъпни от различни URL-адреси.
Какво води до появата на дубликати в сайта:
1. Автоматичното генериране на дублирани страници от системата за управление на съдържанието в сайта (CMS). Например:
https://site.bg/press-centre/user/view/identifier/novini/
https://site.bg/press-centre/novini/
2. Грешки, направени от уебмастърите. Например, когато един и същ продукт е представен в няколко категории и е достъпен от различни URL-адреси:
https://site.bg/category-1/product-1/
https://site.bg/category-2/product-1/
3. Промяна в структурата на сайта, когато на вече съществуващите страници са присвоени нови адреси, но в същото време са съхранени и дублиращите се стари адреси. Например:
https://site.bg/category/product
https://site.bg/category/subcategory/product
Съществуват два вида дубликати: пълни и частични.
Пълни дубликати
Пълни дубликати са страници с напълно идентично съдържание, които обаче са достъпни от различни адреси.
Примери за пълни дубликати:
- URL-адреси на страници с и без наклонени черти ('/', '//', '///'):
https://site.bg/catalog///product и https://site.bg/catalog//////product.
2. HTTP и HTTPS страници:
https://site.bg и http://site.bg
3. Адреси с www и без www:
https://www.site.bg и https://site.bg.
4. URL страница с index.php, index.html, index.htm, default.asp, default.aspx, home:
https://site.bg/index.html
https://site.bg/index.php
https://site.bg/home
5. URL-адреса на страница в горния и долния регистър:
https://site.bg/example/
https://site.bg/EXAMPLE/
https://site.bg/Example/
6. Промени в йерархичната структура на URL-а. Например, ако даден продукт е наличен на няколко различни URL:
https://site.bg/categotry/subcategory/product
https://site.bg/category/product
https://site.bg/product
https://site.bg/subcategory/product
7. Наличие на допълнителни параметри и етикети в URL-адреса.
- URL с GET параметри: https://site.bg/index.php?example=10&product=25. Страницата напълно съответства със следната: https://site.bg/index.php?example=25&cat=10
- Наличие на utm-тагове и gclid параметри: UТМ-таговете помагат за предоставяне на информация в аналитичната система и проследяване на различните параметри на трафика. URL на целевата страница, към която са добавени UTM маркерите, изглежда така:
https://www.site.bg/?utm_source=adsite&utm_campaign=adcampaign&utm_term=adkeyword
- Параметър gclid (Google Click Identifier): маркиране на целевия URL, който се добавя автоматично за проследяване на данните за компаниите, канала и ключовите думи в Google Analytics. Например, ако някой кликне върху вашата реклама и бъде пренасочен към сайта https://site.bg, тогава пренасочващият адрес за посетителя ще изглежда така: https://site.bg/?gclid=123xyz.
- Openstat етикет: Той е универсален и се използва за анализ ефективността на рекламните кампании, за анализ на посещенията на сайта и поведението на потребителите на сайта. Връзката с етикета 'openstat':
https://site.bg/?_openstat=231645789
- Реферална връзка: рефералният линк е специална връзка с вашия идентификатор, чрез който сайтовете разпознават откъде е дошъл новия посетител. Например:
https://site.bg/register/?refid=398992 и
https://site.bg/index.php?cf=reg-newr&ref=Uncertainty
8. При странициране: обикновено дублажите се получават при първа страница от продуктовия каталог на онлайн магазина. Тя често съответства на страница тип категория или обща страница в раздела: https://site.bg/category и https://site.bg/category/page-1.
9. При страница 404: Неправилните настройки за грешка 404 също могат да доведат до дублирания. Например: https://site.bg/rococro-23489-rocoroc* и https://site.bg/8888*
*Удебеленият текст може да съдържа всякакви знаци и/или числа.
Страници от този вид трябва да върнат код с отговор на сървъра 404 (не 200) или да пренасочват към актуална страница.
Частични дубликати
Частични дубликати са страници, в които има едно и също съдържание, но с малки разлики в елементите.
Видове частични дубликати:
- Дублирания на продуктови страници и категории. Тук дубликатите може да възникнат поради наличие на продуктови описания в общата продуктова страница за дадена категория. Същите описания съществуват и в отделните продуктови страници - по този начин част от съдържанието на общата категория се припокрива с тяхното.
Пример
Виждаме даден текст в общата продуктова категория:
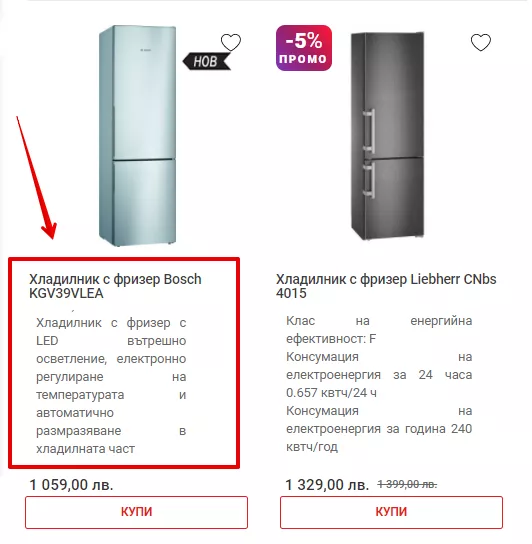
Същият текст е на страницата на продукта:
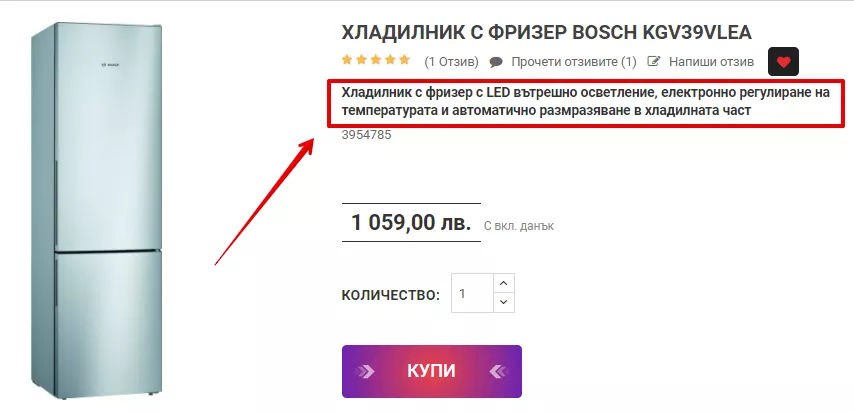
За да се избегне дублиране, не бива описанието на даден продукт да бъде част от общата категория. Друга опция е да се използва уникално описание, което да не дублира това в продуктовата страница.
- Дублиране на страници с филтри, страници от търсения и страници от страницирането, където има почти еднакво съдържание и се променя само неговото разположение.
- Дублирания на страниците за печат или за изтегляне, данните които напълно съответстват на основните страници. Например:
https://site.bg/novini/document-1
https://site.bg/novini/document-1/print
Частичните дубликати са по-трудни за откриване, но последиците от тях също се отразяват негативно върху класирането на сайта.
До какво водят дублираните страници в сайта?
Наличието на дублирани страници не пречи на посетителите да получат необходимата информация. Когато става дума за търсещите роботи обаче, нещата стоят по друг начин.
Тъй като URL адресите са различни, търсачките възприемат тези страници като различни. Следователно, голямото количество дублирано съдържание води до:
- Проблеми с индексирането. Генерирането на дублирани страници увеличава общия размер на сайта. Като индексират брой 'излишни' страници, ботовете неефективно изразходват crawling бюджета. Той е ограничен и представлява количеството страници, които ботът може да обходи при едно посещение на сайта. По този начин „важните“ страници може изобщо да не се индексират.
- Промени в релевантността на страниците в резултатите от търсенето. Възможно е алгоритъмът на търсачката да изчисли, че страницата-дубликат е по-подходяща за извеждане в страницата с резултати. Следователно, в резултатите от търсенето потребителите може да попаднат на страница, която не е целенасочено създадена за тяхната заявка. Има и още един, по-лош сценарий - поради конкуренцията между дублиращите се страници, никоя от тях да не достигне до страницата с резултати.
- Загуба на линк маса. При наличие на дублирани вътрешни страници, посетителите ще бъдат непрекъснато насочвани към дубликатите, а не към оригиналните страници. Това ще доведе до загуба на органична линк маса.
Начини на откриване на дублирани страници
И така, вече разбрахме какво представляват дубликатите, какви са техните видове и до какво водят. Преминаваме към следващата стъпка, а именно - как да ги намерим. Ето някои ефективни начини:
С помощта на специални инструменти
Има различни SEO инструменти, които могат да открият наличието на дубликати.
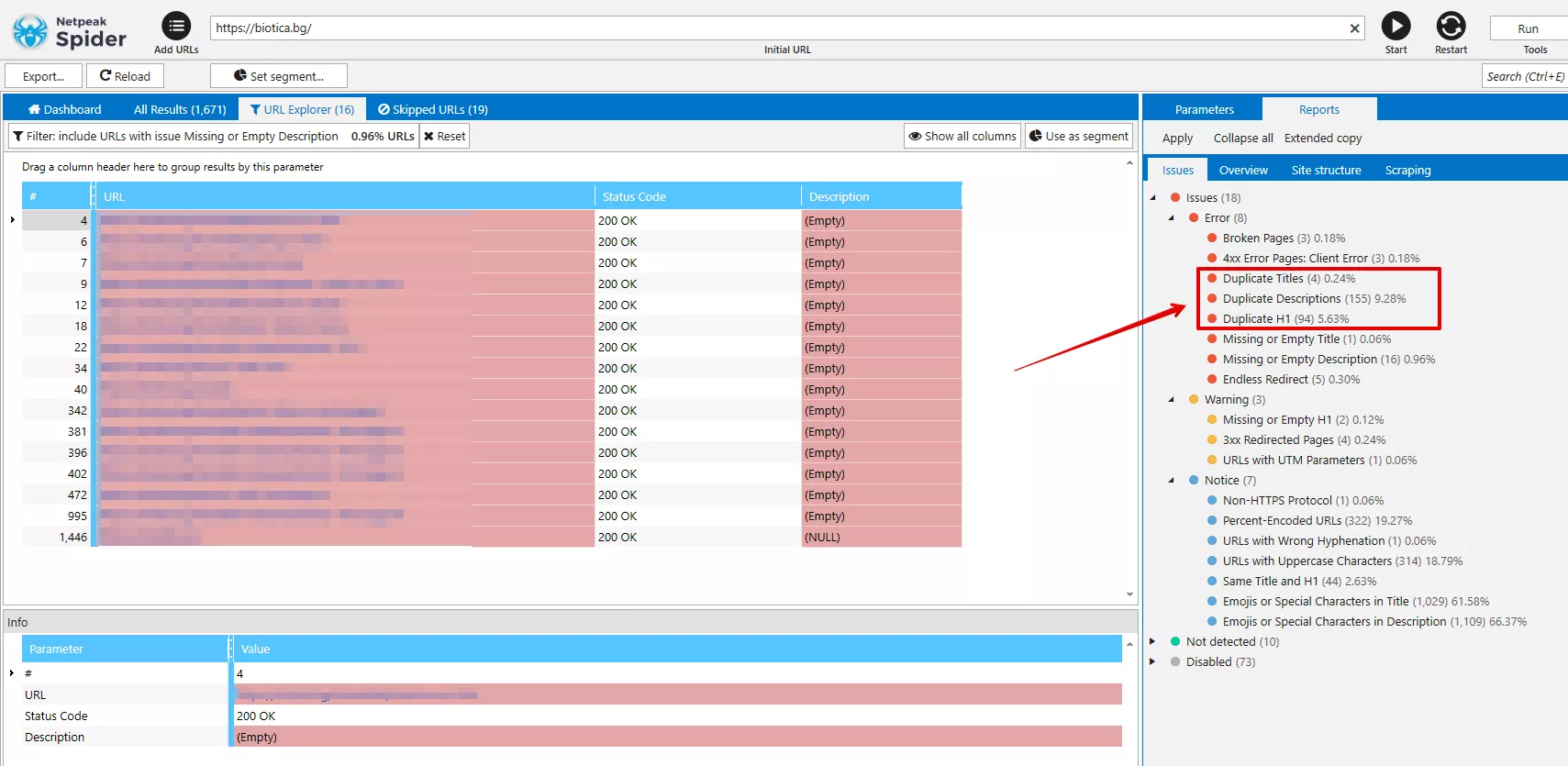
Инструментът Netpeak Spider например, открива както пълно дублиране на страници, така и дублажи по съдържанието на блока <body> и повтарящи се метаданни “Title”, “H1”, “Description”.
С помощта на оператори за търсене
Друг начин за откриване на дубликати е търсенето на вече индексирани дублирани страници с помощта на търсещи оператори.
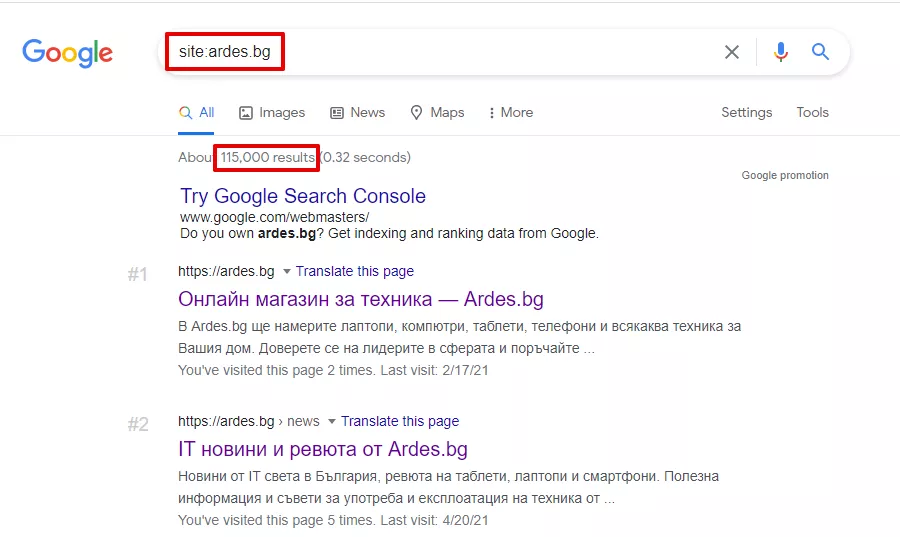
- “site”
За целта в полето за търсене в Google въведете заявката „site: examplesite.bg“. Резултатът ще покаже броя страници на сайта в общия индекс на Google. Ако този брой страници значително надхвърля страниците в XML-картата на сайта, може да се направи извод, че е много вероятно да има дубликати.
Дублираните страници могат да бъдат намерени лесно в резултатите от търсенето.
- “текст” + “site”
Този метод може да се използва и за анализ на резултатите от търсенето по определен фрагмент от текста на страниците, които е възможно да имат дубликати.
За да направите това, поставете в полето за търсене част от текста в кавички, след него оставете интервал, поставете операторът 'site:' и въведете името на сайта. Трябва да посочите вашия сайт, за да намерите страниците, на които присъства този конкретен текст.
Пример
„Фрагмент от текст в страница на сайта, който може да има дубликати“ site:example.bg
Ако в резултатите от търсенето се появи една страница, то тя няма дубликати. Ако в SERP излязат няколко страници, трябва да ги анализирате и да определите причините за дублирания текст.
- “site” + “intitle”
Със същия метод, само че този път използвайки оператор 'intitle:', можете да анализирате съдържанието в 'Title' на страниците в резултатите от търсенето. Дублирането на „Title“ е знак за дублирани страници. За да проверите това, използвайте търсещия оператор „site:“ и след него оператора “intitle”.
Пример
site:examplesite.bg intitle: пълен или частичен текст на тага Title.
Ето как изглежда:
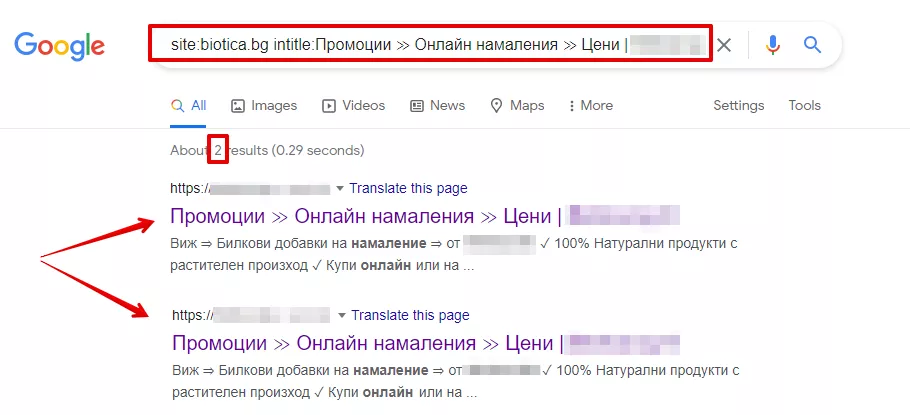
- “site” + “inurl”
Чрез комбинацията на операторите „site“ и „inurl“, може да се определят дублиращите се страници, възникнали в страниците за сортиране (sort) или на страниците от филтриране и търсене (filter, search).
Например, за откриване на страници с филтри в полето за търсене се въвежда следното: site:examplesite.bg inurl:filter
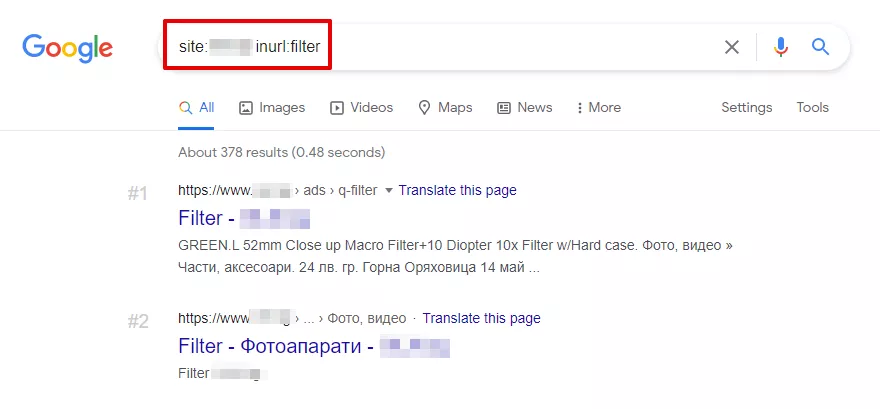
И все пак, не забравяйте, че търсещите оператори показват само онези дубликати, които вече са индексирани от Google. Следователно, не може да се разчита само на този метод.
Как да се отървем от дубликатите
Вече разбрахме какво представляват дублиращите се страници, разгледахме техните видове и се запознахме с последиците от тях. Нека преминем към най-интересната част, а именно - как да ги премахнем.

Има няколко метода за премахване на дублиращи се страници:
301 редирект
Това е основният метод за премахване на пълните дубликати. Перманентният редирект 301 автоматично пренасочва от една страница на сайта към друга. При правилна настройка на редиректа, ботовете виждат, че дадена страница вече не е достъпна и е преместена на друг адрес.
Освен това, чрез пренасочването с редирект 301 ние предаваме линк тежестта на дублирана страница към правилната такава.
Този метод е подходящ за елиминиране на дубликати, които се появяват поради:
- URL адреси в различни регистри (малки/големи букви);
- йерархични дубликати на URL адреси;
- определяне на основната версия на сайта (www или без);
- проблеми с използването на наклонени черти в URL адреса.
Например, с 301 редирект пренасочваме следните дублирани страници:
https://site.bg/category///product
https://site.bg/category//////product
https://site.bg/product
към правилната:
https://site.bg/category/product
Robots.txt
Чрез файла robots.txt препоръчваме на търсещите роботи кои страници или файлове да не бъдат обхождани и индексирани.
За целта е необходимо да използвате директивата 'Disallow', която забранява на търсещите роботи да обхождат ненужните страници.
User-agent: *
Disallow: /page
Нека отбележим, че ако страницата е посочена в robots.txt с директивата Disallow, тази страница все още може да се показва в резултатите от търсенето. Защо? Тя е била индексирана по-рано или има вътрешни или външни връзки към нея. След като съдържанието е веднъж индексирано, инструкциите в robots.txt имат препоръчителен характер. Те не могат да гарантират изтриването на дубликатите.
Мета тагове <noindex, nofollow> и <noindex, follow>
Можем да забраним индексирането на дадена страница и чрез мета тагове.
Мета тагът <meta name="robots" content="noindex, nofollow”> казва на роботите да не индексират дадено съдържание, както и да не следват връзките. Този мета таг има по-силна тежест от robots.txt и няма да бъде игнориран от търсещите роботи.
От своя страна, мета тагът <meta name="robots" content="noindex, follow”> също казва на робота да не индексира дадено съдържание, но този път да следва връзките, поставени към него.
За да се отървете от дублиращите се страници чрез този метод, сложете в <head> частта на техния HTML код някой от посочените мета тагове.
Ако роботът обходи за първи път дадена страница и види директивата "noindex, follow", тогава той не индексира страницата, но вероятността за проследяване на вътрешни връзки все още остава. Но ако ботът се върне след известно време и отново види „noindex, follow“, тогава страницата е напълно премахната от индекса, ботът спира да я посещава и да взима предвид връзките, поставени в нея. Тоест - в дългосрочен план няма особена разлика между мета таговете "noindex, follow" и "noindex, nofollow".
Атрибут rel =“canonical”
Този метод е подходящ в случаите, когато дадена дублирана страница не може да бъде изтрита, и трябва да остане отворена за преглед. Обикновено се използва за елиминиране на дубликатите на страниците с филтри и сортиране, страници с get-параметри и utm-маркери. Използва се също за премахване на дублирания от страниците за печат, както и когато има едно и също съдържание в различните езикови версии и в различните домейни.
Използвайки канонична връзка, ние посочваме предпочитания, изначалния адрес, който искаме Google да индексира.
Пример
Даден сайт за техника има категория “Лаптопи”. Категорията съдържа филтри, които показват различните параметри на лаптопите - марка, цвят, разделителна способност на екрана, материал на корпуса и т.н. В този случай е подходящо да зададем канонична връзка към основната категория “Лаптопи” на всички “допълнителни” страници, генерирани от филтрите.
Това става като поставим в HTML-кода на дадената страница атрибута rel =“canonical” между таговете <head> ... </ head>.
За страниците:
https://site.bg/index.php?example=10&product=25
https://site.bg/example?filtr1=%5b%25D0%,filtr2=%5b%25D0%259F%
https://site.bg/example/print
Канонична ще бъде страницата https://site.bg/example
В HTML кода на страниците трябва да изглежда така: <link rel="canonical" href="https://site.bg/example" />.
Заключение
И така, нека обобщим:
- Вътрешни дубликати - това са отделни страници от сайта, чието съдържание напълно или частично съвпада;
- Причини за възникване на дубликати в сайта - автоматично генериране, грешки, допуснати от уебмастъри, промени в структурата на сайта;
- Проблеми, до които водят дублиранията в сайта: влошаване на индексирането, изменения в релевантността на страниците в резултатите от търсенето, загуба на естествена линка маса.
- Начини за откриване на дубликатите: използване на специализирани инструменти (Netpeak Spider), използване на търсещи оператори.
- Методи за отстраняване на дубликатите: редирект 301, команди във файла robots.txt, мета тагове ”noindex, nofollow” и “noindex, follow”, задаване на канонична връзка rel=”canonical”.
Препоръчително е регулярно да провеждате анализ за дублирани страници в сайта си. По този начин навреме ще идентифицирате и отстраните възникналите грешки.
И не забравяйте - THERE CAN BE ONLY ONE!

 62
62
 9
9
 13
13