Задължителни инструменти на SEO специалиста за парсинг
Много от дейностите при SEO оптимизация на сайта могат и трябва да се автоматизират. Например, събиране на информация, съставяне на списък на продуктите, анализ на цени на конкуренти, скорост на внедряване на препоръки. Автоматизацията на тези процеси с помощта на парсинг дава възможност да не си навличаме главоболия и да спестим стотици часове еднообразен труд.
Трябва да предупредя: обучението и добрата настройка на инструментите за парсинг отнемат много време — по-дълго, отколкото бихте го направили ръчно. Между другото, така е с всички инструменти, с които работиш за първи път. Важното е да започнеш.
За две години в Netpeak се запознах с доста методи за парсинг на данни. Ще разкажа кои инструменти и за какви цели използвам при оптимизация на сайт. Ще вървя от простото към сложното.
1. Google Spreadsheet
С помощта на Google таблици от сайта могат да се теглят прости елементи за сравняване и събиране на малки обеми от данни. Това са title, description, h1, keywords, заглавия, артикули, цени, текстове, таблици с данни. Този безплатен инструмент е подходящ за дребни задачи. Например, да се създаде файл за проследяване на текста и заглавията на страница.
Съществуват две прости функции:
1. =importhtml — за импорт на данни от таблици или списъци.
2. =importxml — за импорт на данни от документи във формат XML, HTML, CSV, TSV, RSS, ATOM XML.
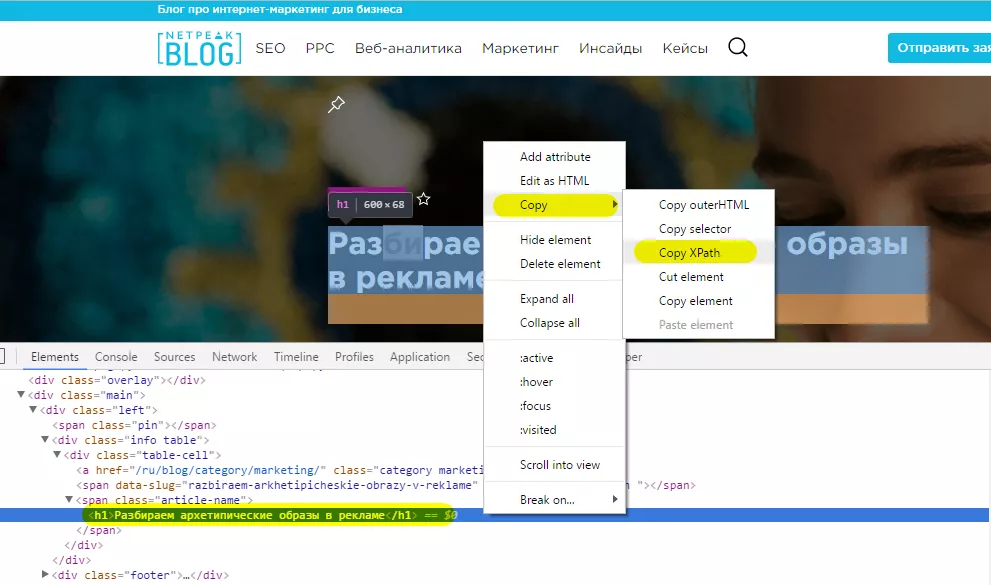
За да работите с функцията =importxml, ще ви трябват знания за XPath. Но, ако не искате да губите време за изучаване на документация, използвайте дебъгера на браузера.
За да стартирате дебъгера, кликнете върху нужния елемент на страницата с десния бутон на мишката и изберете «Инспектиране», или натиснете F12.
В дебъгера минете по пътя: Copy — Copy XPath. Копирания XPath вмъкнете във функция =importxml.
Минуси
С всеки изминал месец все по-зле и по-зле се обработва функция =importxml. Преди можеше без проблеми да се парсят данни едновременно за ~500 URL-адреса, сега трудно се обработват 50 URL.
Плюсове
- автоматично обновяване при вход;
- може да се настрой автоматично обновяване по време (минута, час, ден);
- при парсинга на данни директно в таблицата може да се прави преобразуване на данни и веднага да се правят готови отчети, примери, визуализации.
Какви задачи решава?
С помощта на функцията =importxml може в реално време да се събират данни за мета тагове и, например, за брой коментари към интересуващите ни статии.
В колонка A — клетки с линк към страница. Тагът title за клетка A2 се дърпа с помощта на =IMPORTXML(A2;"//title").
Мета тагът description: =IMPORTXML(A2;"//meta[@name='description']/attribute::content").
Таг H1 — с помощта на: =IMPORTXML(A2;"//h1").
Автор на поста: =IMPORTXML(A2;"//a[@class='author-name']").
Дата на публикация: =IMPORTXML(A2;"//div[@class='footer']/span").
Брой коментари към поста: =IMPORTXML(A2;"//span[@class='regular']").
С помощта на функция =importhtml също така може да се изтеглят много интересни данни, например, основна информация от Уикипедия за интересуващите ни обекти.
2. Netpeak Spider
Десктоп програма за сканиране на сайт, която служи за търсене на SEO-грешки и включва възможност за парсинг на данни от HTML-страници.

SEO специалистът при обикновено сканиране на сайт понякога изпитва недостиг на данни за анализ. С помощта на Netpeak Spider може, например, да се открият страниците на сайта с грешка 404, страници без таг Title и допълнително да се изпарсят цени от продуктови страници.
Така може да се намерят стоки без цена и след това да се вземе адекватно решение — да се оставят, да се премахнат, да се спрат за сканиране/индексация.
Също така може да се дръпнат всички текстове, които са публикувани на страниците, като се зададе определен CSS-селектор или клас, в чиито рамки са поставени.
Цената на програмата е $14 на месец или $117 на година (с 30% намаление).
Минуси
- няма свързаност с API;
- няма възможност за обновяване на данни по сценарий.
Плюсове
- съществува възможност да се добави готов списък с URL за парсинг на данни и така удобно да се сканира целият сайт;
- едновременно може да се пускат до 15 парсера с уникални настройки;
- може да се филтрират страници, на които не са били намерени търсените данни;
- показват се всички уникални включвания, техния брой и дължина;
- освен парсера за данни, получаваме също така инструмент за комплексен SEO анализ на сайта.
Какви задачи решава?
Парсинг на цени
Задача: трябва да проучим цените на лаптопи.
Списък с URL:
https://rozetka.com.ua/asus_x555lj_xx1465d/p11201236/
https://rozetka.com.ua/asus_x555sj_xo001d/p6596109/
https://rozetka.com.ua/asus_n551jb_xo127d/p10727833/
https://rozetka.com.ua/asus_e502sa_xo014d/p9155171/
https://rozetka.com.ua/asus_e502sa_xo001d/p10677881/
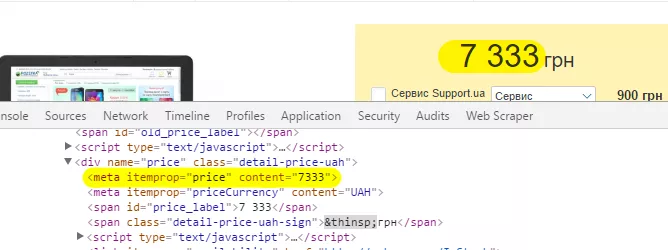
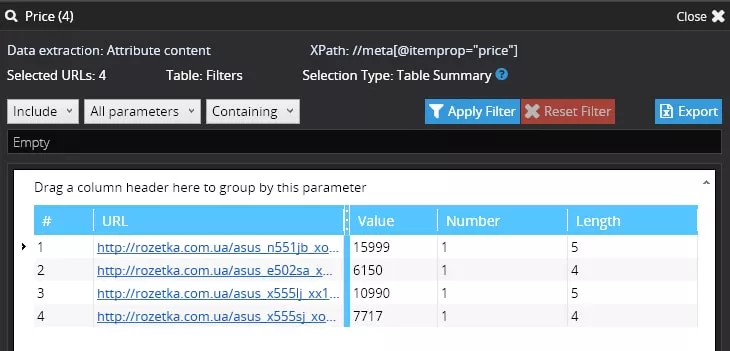
Решение Първо трябва да се определи какъв елемент ще се дърпа — в този случай ще изтегляме мета таг «itemprop» със стойност «price»:
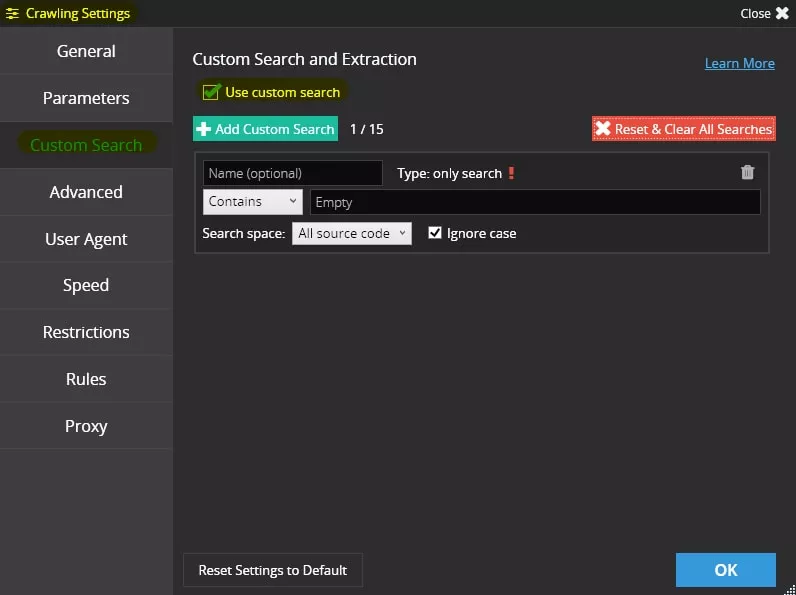
След това преминаваме към настройките за сканиране на Netpeak Spider на таб «Custom Search» и чекваме «Use custom search»:
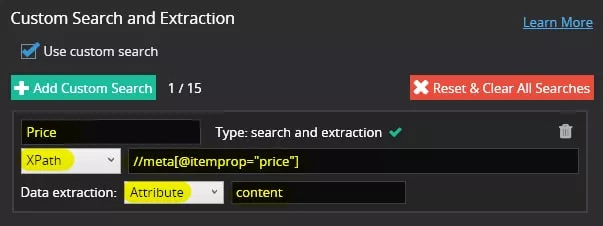
Сега трябва да се направят настройките за търсене — за пример ще използваме XPath: //meta[@itemprop="price"]
А в допълнителните настройки за търсене избираме «Data extraction» — «Attribute» — «content»:
Какво получаваме?
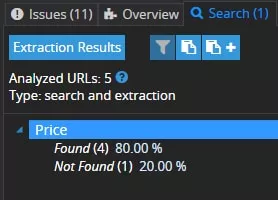
1. На четири страници Spider намира цени — отчетът се отваря при избиране на нужното търсене и натискане на бутона «Extraction Results»:
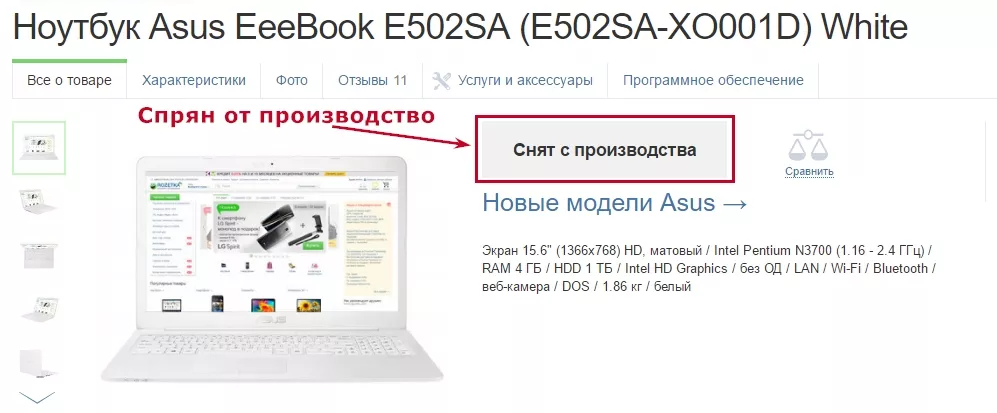
2. На една страница не е намерена цена — на тази страница (https://rozetka.com.ua/asus_e502sa_xo001d/p10677881/) виждаме съобщение, че стоката не се произвежда вече:
Проверка за внедряване на GTM
Задача: да се провери интеграция на GTM код на страниците и да се отговори на два въпроса.
- Включен ли е кодът по принцип?
- Кодът сложен ли е с правилен идентификатор?
Списък с URL:
https://netpeak.net/ru/blog/category/seo/
https://netpeak.net/ru/blog/category/ppc/
https://netpeak.net/ru/blog/category/web-analytics/
https://netpeak.net/ru/blog/category/marketing/
Решение. Аналогично, първо трябва да се определи, какъв елемент отговаря за GTM кода — в този случай ще дърпаме GTM ID с помощта на регулярен израз.

В Netpeak Spider отиваме в аналогични настройки за сканиране и въвеждаме търсене по регулярен израз: ['"](GTM-\w+)['"]
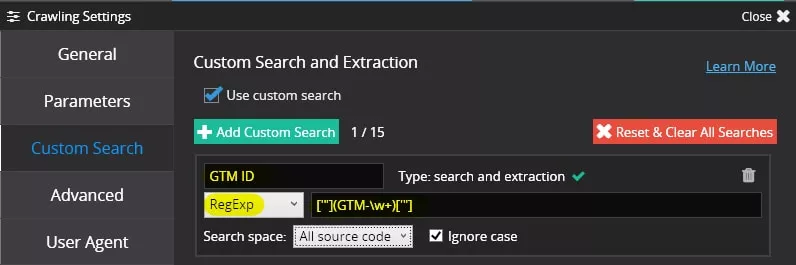
Какво получаваме?
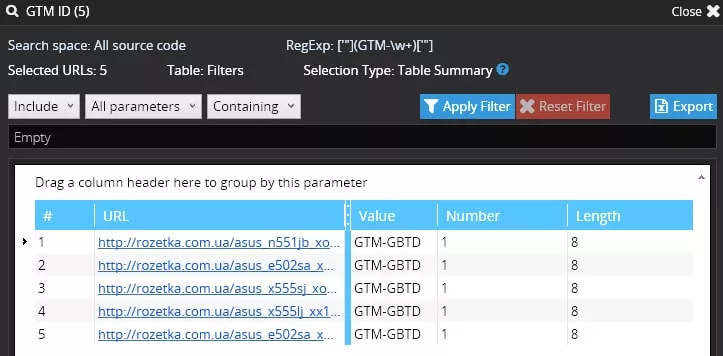
Виждаме, че кодът е включен и идентификаторът е верен.
За да видите повече примери на използване на Netpeak Spider, прочетете подробния обзор на тези функции в блога на Netpeak Software.
3. Web Scraper
Web Scraper е безплатно разширение за браузъра Chrome. Вие можете да настроите план за обхождане на сайтове, тоест да се определи логиката на движение на краулера и да се определят данните, които ще бъдат извличани. Web Scraper ще обхожда сайта в съответствие с настройката и ще извлича данните. Това позволява извлечените данни да се експортират в CSV.
Минуси
- Няма възможности за интеграция с API, тоест за обновяването на данни Web Scraper трябва да се стартира самостоятелно и да се чака, докато приключи сканирането.
- Добре е, че проектите се пазат в браузъра, съществува и възможност да се запази проекта във формат JSON.
- Също така, има ограничение за един поток. 2 000 страници се парсят повече от час.
- Работи само в Chrome.
Плюсове
- Удобен, опростен и интуитивно разбираем инструмент.
- Може да се извличат данни от динамични страници, които използват JavaScript и Ajax.
Какви задачи решава?
Парсене на информация от продуктовата страница
План за обхождане на сайта показва логиката на парсинга:
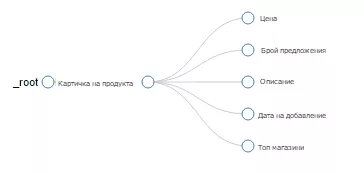
Елементи на парсинга:

След завършване на парсинга информацията ще бъде показана в такъв вид:
Материали за обучение:
4. Google Spreadsheet + Google Apps Script
Google Apps Script е език за програмиране, основан на JavaScript. Позволява създаване на нови функции и приложения за работа с Google Docs, Google Sheets и Google Forms. Настройването на свързването може да стане безплатно.
Минуси
Нужно е познаване на езика за програмиране JavaScript.
Плюсове
Изразходвайки определено време за настройка на отчетите, може оперативно да се реагира на промяна на данни.
Какви задачи решава?
С помощта на свързаността на Google Spreadsheet и Google Apps Script може да се получават и обновяват данни в режим реално време, а това е полезно за следене на конкуренти и настройване на сигнали при промени, например, на тагове title. Също така може да се настрои мониторинг на цени и да се получават известия при промяна на показатели.
Изводи
За гъвкаво и ефективно използване на безплатни инструменти за парсинг на сайтове, е необходимо поне да се знае какво е XPath, а най-добре да се владеят и основите на JavaScript. И платените решения, като Netpeak Spider, предлагат все повече интересни възможности, като едновременна настройка на 15 потока за парсинг.
Много от въпросите, свързани с автоматизацията, преди време решаваше Kimono, но от момента на затваряне на облачния инструмент той престана да е така привлекателен за SEO специалистите.
Пишете в коментарите какви инструменти използвате Вие за парсинг и какви задачи решавате с тяхна помощ.

 1
1
 0
0
 1
1