The robots.txt file and sitemap.xml contains some of the most important information about a resource; it shows search engine bots exactly how to "read" the site, which pages are important, and which should be skipped. The robots.txt is also the first page you should look at if your site traffic is suddenly dropping.
What is a robots.txt file?
A robots.txt file is a text UTF-8 encoded document that is valid for http, https, as well as FTP protocols. The file makes recommendations to search engine bots on which pages or files to crawl. If a file contains characters encoded differently from UTF-8, search crawlers may process them incorrectly. The instructions in the robots.txt file only work with the host, protocol, and port number where the file is located.
The file is located in the root directory as a plain text document and can be found at https://mysite.com/robots.txt.
In other files, it is common to place a Byte Order Mark (BOM). This is a Unicode character that is used to define a sequence in bytes while reading information. The code character is U+FEFF. The byte order mark is ignored at the beginning of the robots.txt file.
Google has set a size limit for robots.txt – it must not be more than 500Kb.
So, if you are interested in more technical details, the robots.txt file is a description in the form of a Backus-Naurus (BNF). RFC 822 directives are used in this case.
When processing directives in the robots.txt file, search engine bots receive one of the following three instructions:
- Partial access: individual elements of the site can be crawled.
- Full access: everything can be crawled.
- Full denial: robots can't crawl anything.
When scanning the robots.txt file, the search engine bots get these responses:
- 2xx – the scan was successful.
- 3xx – the search crawler follows the redirect until it gets a different answer. Usually, there are five attempts for the search engine bot to get an answer different from 3xx before a 404 error is registered.
- 4xx – the search robot thinks it can crawl all website content.
- 5xx – evaluated as a temporary server error, crawling is completely forbidden. The bot will continue to access the file until it receives another response. Google search bot can detect whether the response is correctly or incorrectly configured for missing pages of the site. This means that if a page gives the answer 5xx instead of a 404 error, the page will be considered with the response code 404.
It is still unclear how the robots.txt file is processed when it is inaccessible due to server problems with internet access.
{tilda_form_wildcard_25148512}
Why Is robots.txt Important?
Sometimes, there are pages that search engine bots should not visit. For example,
- website pages with users' personal information;
- pages with a lot of forms for sending information;
- mirror sites;
- pages with search results;
- duplicate pages.
Important: Even if a page is in the robots.txt file, there is a chance that it will appear in the SERP if a link has been found to it within the site or somewhere in an external resource.
But, is the robots.txt file truly necessary?
If you are sure that you want the crawlers to the entire content of your website, you don’t have to create even an empty robots.txt file.
But, without a robots.txt, information that should be hidden from prying eyes could appear in the search results. As a result, both you and the website could be affected.
How the search engine bot sees the robots.txt file:
Google found a robots.txt file on the website and identified directives to crawl the pages of the site.
Robots.txt Syntax
The syntax of the robots.txt is based on the regular expressions.
The main characters used in robots.txt are /, *, $, and #.
The slash ”/” is used to indicate what we want to hide from crawlers. For example, a single slash in the Disallow directive will block the entire site from being crawled.
Two slashes can be used to disallow crawling one directory, for example: /catalog/.
Such a record means that we deny crawling all content of the directory «catalog». However, if we write “/catalog”, we will disallow any website links that begin with /catalog.
An asterisk “*” means any sequence of characters in the file. It is used after each directive.

This record tells all search engine bots to not crawl any files with .gif extension in the /catalog/ directory.
The dollar sign “$” restricts the action of the “*”. If you want to disallow all content in the «catalog» directory, but at the same time you don’t want to disallow URLs that contain “/catalog”, the record in your robots.txt file will be as follows:

The “#” grid is used for comments left by the webmaster for himself or other webmasters. The search engine bot will not take them into account while crawling the website.
For example:
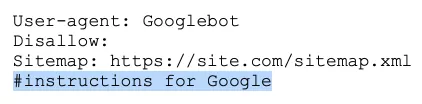
How to create your robots.txt file
To create a robots.txt file, you can use Notepad, Sublime, or any other text editor app. But if you would like to make this process more automated, you can use a free robots.txt generator. Such services help to create correct robots.txt based on the information of your website.
The main directives of robots.txt are «User-agent» and «Disallow». There are also some secondary directives.
User-agent – business card for search engine bots
User-agent is a directive about crawlers which would see the instructions described in the robots.txt file. Currently, there are 302 known search engine bots. To avoid prescribing all of them individually, it's worth using a record:
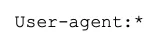
This means that we set the directives in robots.txt file for all crawlers.
For Google, the main crawler is Googlebot. If we only want to consider Googlebot, the record in the file should be as follows:

In this case, all other bots will crawl the content according to their directives for handling an empty robots.txt file.
Other special search engine bots:
- Mediapartners-Google – for AdSense services.
- AdsBot-Google – to check landing page quality.
- Googlebot-Image – for pictures.
- Googlebot-Video – for video.
- Googlebot-Mobile – for mobile version.
What does “Disallow” mean in robots.txt?
Disallow recommends information that should not be crawled.
This record opens up the entire website for crawling:

Whereas, this record says that absolutely all content of the website is denied to be crawled:

It could be useful if the site is under development and you do not want it to show it up in the SERP in its current configuration.
However, it is important to delete this directive as soon as the site is ready to be visited by users. Unfortunately, this is sometimes forgotten by many webmasters.
For example, here is how to write a Disallow directive to instruct robots not to crawl the contents of the /folder/ directory:

To prevent search engine bots from crawling a certain URL:

To prevent search engine bots from crawling a certain file:
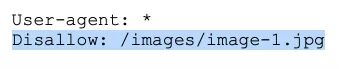
To prevent search engine bots from crawling all files of a certain type:

This directive deny to crawl all .gif files
Allow – a guide for search engine bots
“Allow” enables any file/directory/page to be crawled. For example, you want to let search engine bots visit pages that begin with «/catalog» and disable all other content. In this case, the following combination is used:

Allow and Disallow directives are sorted by URL prefix length (from shortest to longest) and applied one by one. If more than one directive is relevant for a page, the search engine bot will select the last rule in the sorted list.
Sitemap.xml – for website navigation
The Sitemap informs crawlers that all URLs required for indexing are located at https://site.com/sitemap.xml. During each crawl, search engine bots will see the changes that have been made to this file and quickly refresh the site's information in search engine databases.
The instructions need to be correctly written in the file:
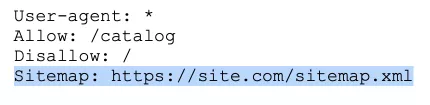
Crawl-delay – a timer for slow servers
Crawl-delay is a directive used to set the period of time after which the website pages will be crawled. This rule is useful if you have a slow server. In this case, there may be long delays in accessing website pages by crawlers. This parameter is measured in seconds.
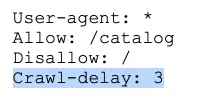
How to create an ideal robots.txt file?
Such a robots.txt file can be placed on almost any website:

The file opens the website content for crawling, a sitemap is included which will allow search engines to always see the URLs that need to be indexed.
But do not hurry to copy the file content for yourself – you need to write unique instructions for each website, which depend on the website type and CMS. At this point, it is a good idea to remember all the rules for filling up the robots.txt file.
How to check your robots.txt file
If you want to know whether your robots.txt file is filled in correctly, check it in Google Search Console. Enter the source code of the robots.txt file in the link form and select the website you want to check.
Common mistakes to avoid in robots.txt
Often, certain mistakes are made while filling up a robots.txt file, and these are usually caused by inattention or rushing. Here is a chart listing out these common robots.txt mistakes.
1. Wrong instructions:

Correct:

2. Writing more than one folder/directory in a single Disallow directive:

This can confuse search engine bots on whether they should crawl the first folder or the last. So, be sure to write each instruction separately:

3. The file should only be called robots.txt, not Robots.txt, ROBOTS.TXT, or something else.
4. The User-agent directive should not be left empty – you need to specify the search engine bots that should follow the instructions in the file.
5. Unnecessary characters in the file (e.g., slashes, asterisks).
6. Adding pages that should not be indexed to the file.
Not crawling isn’t not indexing
The directives in the robots.txt only restrict the crawling of the website's content. They do not apply to indexing.
To ensure that a URL is not indexed, it is recommended to use the robots meta tag or X-Robots-Tag HTTP header instead.
- Robots meta tags could be used to control how a certain HTML page appears (or does not appear) in SERP.
- HTTP header X-Robots-Tag could be used to control how non-HTML content appears (or does not appear) in search results.
The most useful robots meta tags are:
- Index: the page can be indexed.
- Follow: the crawler can go over the links on this page.
- Noindex: this page cannot be indexed.
- Nofollow: deny search engine bots to follow the links on this page.
- None: Noindex + Nofollow.
- Noimageindex: disable the indexation of images.
- Noarchive: do not show the cache version of this webpage.
- Nosnippet: do not show the metadata in the SERP.
Unusual use of robots.txt
In addition to its direct functions, robots.txt file can be a platform for creativity and a way to find new employees.
Many brands use robots.txt to express their individuality and emphasize their branding:


As a platform for finding specialists, the robots.txt is mostly used by SEO agencies. Who else would know of its existence? :)
When webmasters have some free time, they often spend it upgrading robots.txt:

Summary
By using Robots.txt, you can give instructions to search engine bots on which pages to crawl, promote yourself and your brand, as well as search for specialists. It's a great area for experimentation. The key takeaway is to remember to fill in the file correctly and avoid making typical mistakes.
The main directives of the robots.txt file are as follows.
- User-agent is a directive about which robots should see the instructions described in the robots.txt.
- Disallow advises which information should not be crawled.
- Sitemap tells robots that all URLs required for indexing are located at https://site.com/sitemap.xml.
- Crawl-delay is a parameter that can be used to specify the period of time after which the pages of the site will be loaded.
- Allow enables any file/directive/page to be crawled.
The characters used in robots.txt:
- The "$" restricts the action of the “*”.
- With "/" we show what we want to close from being crawled by search engine bots.
- The "*" means any sequence of characters in the file. It is placed after each rule.
- "#" is used to indicate comments written by the webmaster for himself or other webmasters.
Use your robots.txt file responsibly, and your website will always be in search results.

 7
7
 2
2
 3
3
Related Articles
How to Set Up Consent Mode in GA4 on Your Website with Google Tag Manager
Let's explore how to properly integrate consent mode in GA4, configure it for effective data collection, and at the same time comply with GDPR and other legal regulations
Display Advertising Effectiveness Analysis: A Comprehensive Approach to Measuring Its Impact
In this article, I will explain why you shouldn’t underestimate display advertising and how to analyze its impact using Google Analytics 4
Generative Engine Optimization: What Businesses Get From Ranking in SearchGPT
Companies that master SearchGPT SEO and generative engine optimization will capture high-intent traffic from users seeking direct, authoritative answers