Що таке robots.txt і навіщо взагалі потрібний індексний файл
Файл robots.txt разом з XML-картою несе важливу інформацію про ресурс: він показує роботам пошукових систем, як саме «читати» сайт, які сторінки важливі, а які слід пропустити. Ще robots.txt — одна з перших сторінок, на яку варто дивитися, якщо на сайт раптово впав трафік.
Що за роботс ті екс ті?
Файл robots.txt або індексний файл — звичайний текстовий документ у кодуванні UTF-8, що діє для протоколів http, https, а також FTP. Файл дає пошуковим роботам поради: які сторінки/файли варто сканувати. Якщо файл містить символи не в UTF-8, а в іншому кодуванні, пошукові роботи можуть неправильно їх обробити. Правила, перелічені у файлі robots.txt, дійсні лише щодо того хоста, протоколу та номера порту, де розміщено файл.
Файл має міститись у кореневому каталозі у вигляді звичайного текстового документа та бути доступним за адресою: https://site.com.ua/robots.txt.
В інших файлах прийнято ставити позначку BOM (Byte Order Mark). Це Юнікод-символ, який використовується для визначення послідовності в байтах при зчитуванні інформації. Його кодовий символ — U+FEFF. На початку файлу robots.txt мітка послідовності байтів ігнорується.
Google встановив обмеження за розміром файлу robots.txt — він не має важити більше ніж 500 Кб.
Гаразд, якщо вам цікаві суто технічні подробиці, файл robots.txt є описом у формі Бекуса-Наура (BNF). Водночас використовуються правила RFC 822.
Під час обробки правил у файлі robots.txt пошукові роботи отримують одну з трьох інструкцій:
- частковий доступ — доступне сканування окремих елементів сайту;
- повний доступ — сканувати можна все;
- повна заборона — робот нічого не може сканувати.
У разі сканування файлу robots.txt роботи отримують такі відповіді:
- 2xx — сканування пройшло успішно;
- 3xx — пошуковий робот слідує за переадресацією, допоки не отримає іншої відповіді. Найчастіше є п’ять спроб, щоб робот отримав відповідь, відмінну від відповіді 3xx, потім реєструється помилка 404;
- 4xx — пошуковий робот вважає, що можна сканувати весь вміст сайту;
- 5xx — оцінюються як тимчасові помилки сервера, сканування повністю забороняється. Робот буде звертатися до файлу до тих пір, поки не отримає іншу відповідь. Пошуковий робот Google може визначити, коректно чи некоректно налаштована віддача відповідей відсутніх сторінок сайту, тобто якщо замість 404 помилки сторінка віддає відповідь 5xx, в цьому випадку сторінка буде оброблятися з кодом стану 404.
Поки що невідомо, як обробляється файл robots.txt, який недоступний через проблеми сервера з виходом до інтернету.
Навіщо потрібен файл robots.txt
Наприклад, іноді роботам не варто відвідувати:
- сторінки з особистою інформацією користувачів на сайті;
- сторінки з різноманітними формами надсилання інформації;
- сайти-дзеркала;
- сторінки з результатами пошуку.
Важливо: навіть якщо сторінка знаходиться у файлі robots.txt, існує ймовірність, що вона з’явиться у видачі, якщо на неї було знайдено посилання всередині сайту або на зовнішньому ресурсі.
Так роботи пошукових систем бачать сайт із файлом robots.txt і без нього:
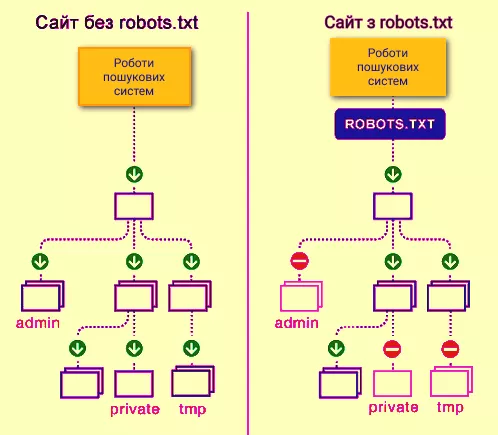
Без robots.txt та інформація, яка має бути прихована від сторонніх очей, може потрапити у видачу, а через це постраждаєте і ви, і сайт.
Так робот пошукових систем бачить файл robots.txt:
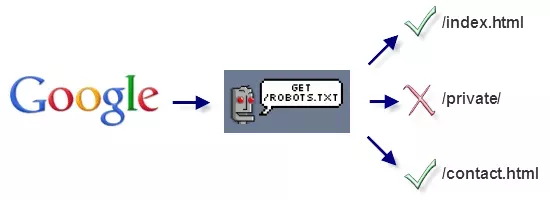
Google виявив файл robots.txt на сайті та знайшов правила, за якими слід сканувати сторінки сайту
Як створити файл robots.txt
За допомогою блокнота, Notepad, Sublime або будь-якого іншого текстового редактора.
У змісті файлу мають бути прописані інструкція User-agent і правило Disallow, до того ж є ще кілька другорядних правил.
User-agent — візитівка для роботів
User-agent — правило про те, яким роботам необхідно переглянути інструкції, описані у файлі robots.txt. На даний момент відомі 302 пошукові роботи. Щоб не прописувати всіх окремо, варто використати запис:

Він говорить про те, що ми вказуємо правила robots.txt для всіх пошукових роботів.
Для Google головним роботом є Googlebot. Якщо ми хочемо врахувати лише його, запис у файлі буде таким:

У цьому випадку всі інші роботи будуть сканувати контент на основі своїх директив щодо обробки порожнього файлу robots.txt.
Інші спеціальні роботи:
- Mediapartners-Google — для сервісу AdSense;
- AdsBot-Google — для перевірки якості цільової сторінки;
- Googlebot-Image — для картинок;
- Googlebot-Video — для відео;
- Googlebot-Mobile — для мобільної версії.
Disallow — розставляємо «цеглини»
Disallow дає рекомендацію, яку саме інформацію не варто сканувати.
Такий запис відкриває весь сайт для сканування:

А цей запис говорить про те, що абсолютно весь контент на сайті заборонено для сканування:

Його варто використовувати, якщо сайт знаходиться в процесі доробок, і ви не хочете, щоб він у такому стані засвітився у видачі.
Важливо видалити це правило, коли сайт буде готовий до того, щоб його побачили користувачі. На жаль, про це забувають багато вебмайстрів.
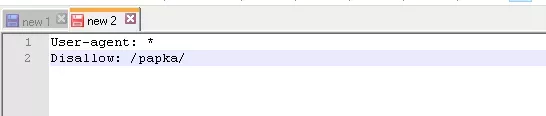
Приклад. Як прописати правило Disallow, щоб дати інструкції роботам не переглядати вміст папки /papka/:
Щоб роботи не сканували конкретну URL-адресу:
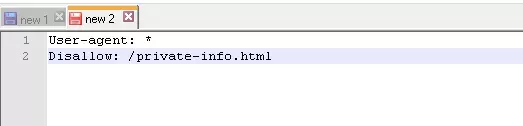
Щоб роботи не сканували конкретний файл:

Щоб роботи не сканували всі файли певного типу на сайті:

Цей рядок забороняє індексувати всі файли .gif
Allow — направляємо роботів
Allow дозволяє сканувати будь-який файл/директиву/сторінку. Скажімо, необхідно, щоб роботи могли подивитися тільки сторінки, які починалися б з /catalog, а весь інший контент закрити. У цьому випадку прописується така комбінація:

Правила Allow та Disallow сортуються за довжиною префікса URL (від меншого до більшого) та застосовуються послідовно. Якщо для сторінки підходить декілька правил, робот вибирає останнє правило у відсортованому списку.
Sitemap — медична карта сайту
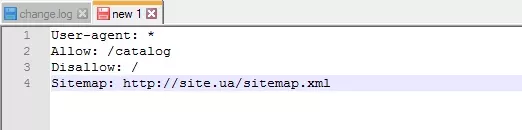
Sitemap повідомляє роботам, що всі URL сайту, обов’язкові для індексації, знаходяться за адресою https://site.ua/sitemap.xml. Під час кожного обходу робот дивитиметься, які зміни вносилися до цього файлу, та швидко освіжатиме інформацію про сайт у базах даних пошукової системи.
Інструкція має бути грамотно вписана у файл:
Crawl-delay — секундомір для слабких серверів
Crawl-delay — параметр, за допомогою якого можна задати період, через який завантажуватимуться сторінки сайту. Це правило актуальне, якщо у вас слабкий сервер. У такому разі можливі великі затримки при зверненні пошукових роботів до сторінок сайту. Цей параметр вимірюється в секундах:

Важливо. Google більше не підтримує цю директиву. Вона актуальна для інших пошукових систем, наприклад, Bing.
Clean-param — мисливець контентом, що дублюється
Clean-param допомагає боротися з get-параметрами для запобігання дублювання контенту, який може бути доступний за різними динамічними адресами (із знаками питання). Такі адреси з’являються, якщо на сайті є різні сортування, id сесії тощо.
Допустимо, сторінка доступна за адресами:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
У такому разі файл robots.txt виглядатиме так:

Тут ref вказує, звідки йде посилання, тому воно записується спочатку, а вже потім вказується решта адреси.
Але перш ніж перейти до еталонного файлу, необхідно дізнатися про деякі знаки, які застосовуються при написанні файлу robots.txt.
Символи в robots.txt
Основні символи файлу — «/, *, $, #».
За допомогою слеша «/» ви покажете, що саме хочете закрити від виявлення роботами. Наприклад, якщо стоїть один слеш у правилі Disallow, це заборона сканувати весь сайт. За допомогою двох знаків слеш можна заборонити сканування будь-якої окремої директорії, наприклад: /catalog/.
Такий запис каже, що ви забороняєте сканувати весь вміст каталогу catalog, але якщо напишете /catalog, забороните всі посилання на сайті, які будуть починатися на /catalog.
Зірочка «*» означає будь-яку послідовність символів у файлі. Вона ставиться після кожного правила:

Цей запис каже, що всі роботи мусять не індексувати будь-які файли з розширенням .gif у папці /catalog/
Знак долара «$» обмежує дії зірочки. Якщо потрібно заборонити весь вміст папки catalog, але водночас не можна заборонити урли, які містять /catalog, запис в індексному файлі буде таким:

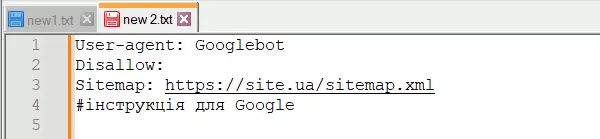
Ґрати «#» використовуються для коментарів, які вебмайстер залишає для себе або інших вебмайстрів. Робот не враховуватиме їх при скануванні сайту.
Наприклад:
Як перевірити файл robots.txt
Якщо хочете дізнатися, чи правильно заповнили файл robots.txt, перевірте його в інструменті вебмайстрів Google. Просто введіть вихідний код файлу robots.txt у форму за посиланням та вкажіть сайт, що перевіряється.
Як не потрібно заповнювати файл robots.txt
Часто при заповненні індексного файлу допускаються прикрі помилки, причому вони пов’язані зі звичайною неуважністю або поспіхом. Трохи нижче чарт помилок, які я зустрічала на практиці.
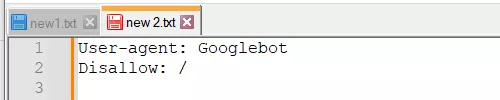
- Переплутані інструкції:

Правильний варіант:
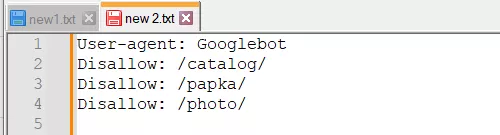
- Запис декількох папок/директорій в одній інструкції Disallow:

Такий запис може заплутати пошукових роботів, вони можуть не зрозуміти, що саме їм не слід індексувати: чи то першу папку, чи то останню. Тому потрібно писати кожне правило окремо:
- Сам файл має називатися лише robots.txt, а не Robots.txt, ROBOTS.TXT або якось інакше.
- Не можна залишати порожнім правило User-agent — потрібно сказати, який робот має враховувати прописані у файлі правила.
- Зайві знаки у файлі (слеші, зірочки).
- Додавання до файлу сторінок, яких не повинно бути в індексі.
Нестандартне застосування robots.txt
Крім прямих функцій індексний файл може стати майданчиком для творчості та способом знайти нових співробітників.
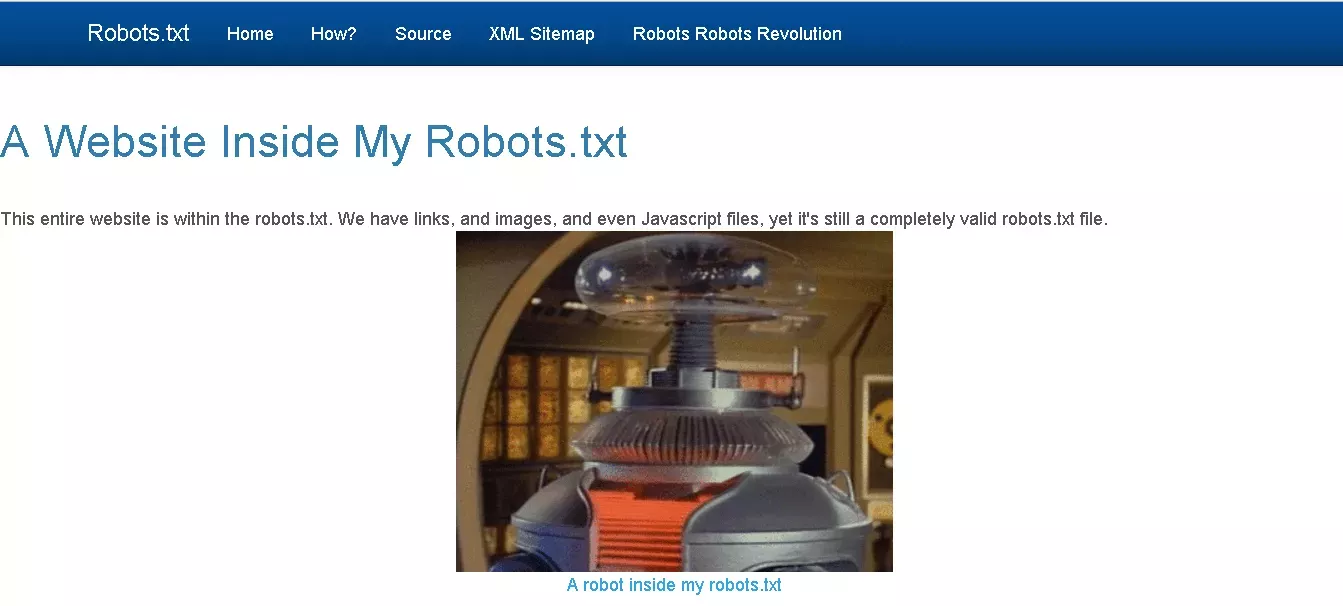
Ось сайт, у якому robots.txt сам є маленьким сайтом із робочими елементами і навіть рекламним блоком:
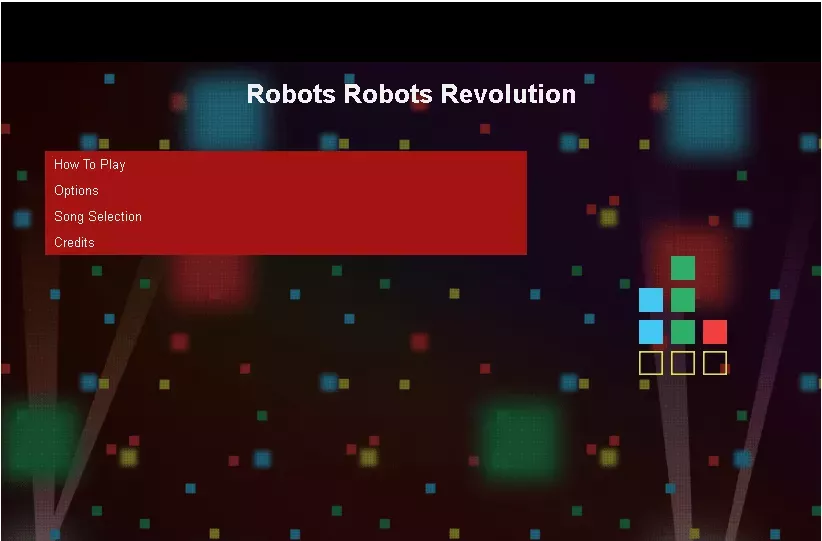
Хочете щось цікавіше? Ловіть посилання на robots.txt із вбудованою грою та музичним супроводом:
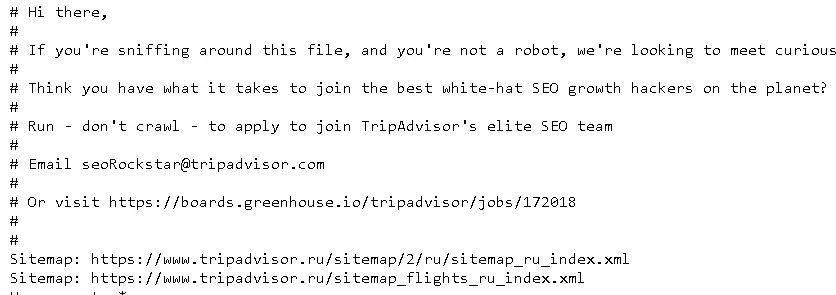
Багато брендів використовують robots.txt, щоб ще раз заявити про себе:


Як майданчик для пошуку фахівців файл використовують в основному SEO-агентства. А хто ще може дізнатися про його існування? :)
Ну і ще Google з цією метою створив спеціальний humans.txt:
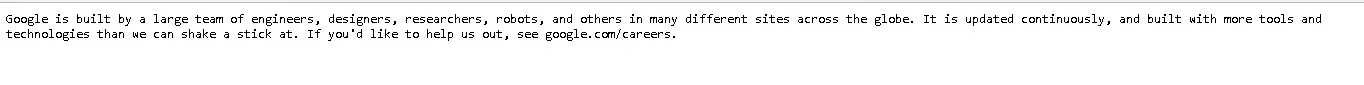
Коли у вебмайстра з'являється достатньо вільного часу, він часто тратить його на модернізацію robots.txt:

Висновки
За допомогою Robots.txt ви зможете задавати інструкції пошуковим роботам, рекламувати себе, свій бренд, шукати спеціалістів. Це велике поле для експериментів. Головне, пам’ятайте про грамотне заповнення файлу та типові помилки.
Правила, вони ж директиви, вони ж інструкції файлу robots.txt:
- User-agent — це правило про те, яким роботам необхідно переглянути інструкції, описані в robots.txt.
- Disallow пропонує рекомендацію, яку саме інформацію не варто сканувати.
- Sitemap повідомляє роботам, що всі URL-сайти, обов’язкові для індексації, знаходяться за адресою https://site.ua/sitemap.xml.
- Allow дозволяє сканувати будь-який файл/директиву/сторінку.
- Clean-param допомагає боротися з get-параметрами, щоб уникнути дублювання контенту.
Знаки при створенні robots.txt:
- Знак долара «$» обмежує дії знак зірочки.
- За допомогою слеша «/» ми показуємо, що хочемо закрити від виявлення роботами.
- Зірочка «*» означає будь-яку послідовність символів у файлі. Вона ставиться після кожного правила.
- Решітка «#» використовується для позначення коментарів, які пише вебмайстер для себе або інших вебмайстрів.
Використовуйте індексний файл правильно — і сайт завжди буде у видачі.

 4
4
 1
1
 0
0
Свіжі
Більше замовлень без зниження окупності: +59,5% доходу з Google Ads для сервісу доставки піци
Що змінюється, коли рекламна система бачить не просто кліки, а реальні покупки
Від «бізнесу по зальоту» до екосистеми з трьох десятків компаній: 20 років Netpeak
За 20 років Netpeak — впевнений гравець міжнародного ринку, зокрема, в Європі, на Близькому Сході, Центральній Азії та в Америці, із 600 співробітниками й офісами в Україні, Болгарії, Казахстані, США
7 помилок у Google Ads, які впливають на результати рекламної кампанії
У цій статті розберу типові помилки, з якими можна часто зіштовхнутися: 5 базових і 2 неочевидних. Для кожної покажу, як виявити проблему, виправити її та відслідкувати, який її вплив на рекламні кампанії