Localización de metadatos en la App Store: diferencias culturales y nacionales
Según el informe de previsión del mercado de los móviles 2021-2025 de Sensor Tower, los mercados de aplicaciones móviles más grandes del mundo son Asia, Europa, Norteamérica, Latinoamérica, Oriente Medio y Australia:
Gasto de los consumidores de la App Store por región
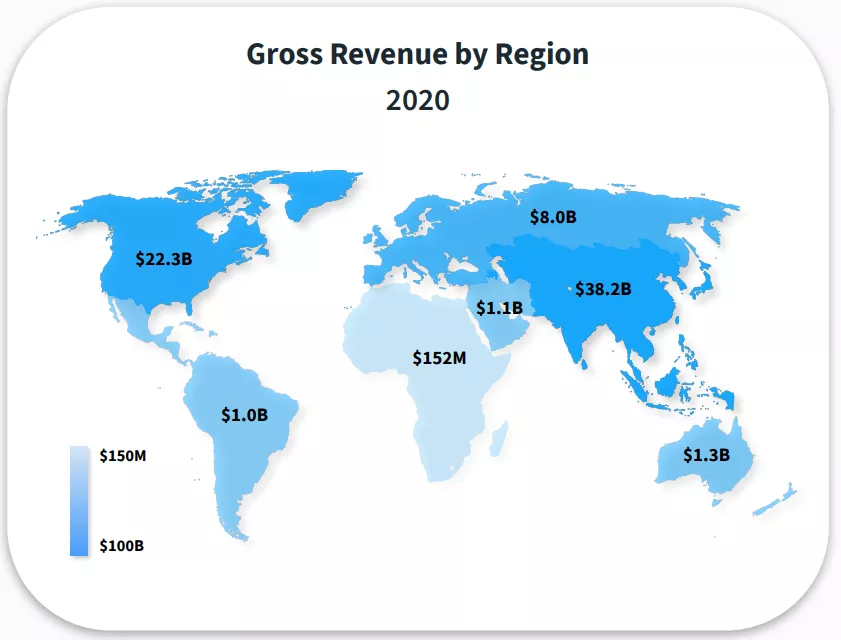
Title: Ingresos brutos por región
Descargas de la App Store por región
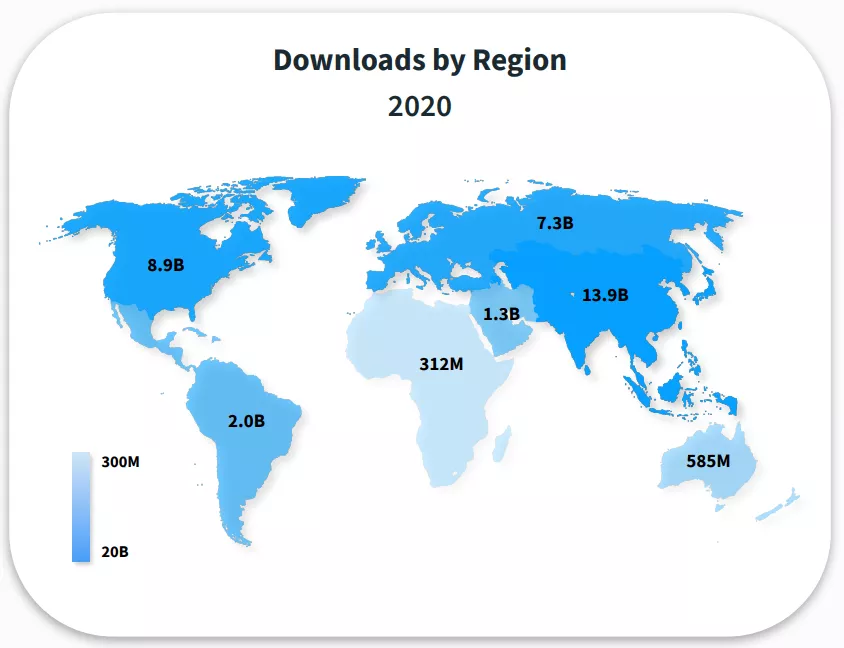
Title: Descargas por región
Cada región se distingue considerablemente de las demás en cuanto a tradiciones, mentalidad y visión de la vida de la población local e incluso en cuanto al sistema jurídico que afecta a las particularidades de hacer negocios en esas zonas. Como parte del marketing, la optimización de la App Store (ASO) debe ejecutarse teniendo en cuenta las diferencias de cada región. Su función es adaptar los metadatos textuales y gráficos para que se adapten a cada país de destino.
En este artículo, un especialista en RadASO explica cómo las peculiaridades culturales y nacionales de las distintas regiones afectan al proceso de creación de metadatos de texto para la App Store (título, subtítulo y descripción, que no se indexan pero afectan a los índices de conversión) y cómo superar las dificultades que se pueden encontrar durante el proceso de localización de la página del listado de aplicaciones.
Localización de metadatos para la zona de Asia
Los países clave de la región en términos de descargas y rentabilidad son China, Japón y Corea, por lo que esta sección se centrará principalmente en las características de estos países.
1. Características de la competencia en el mercado regional
Uno de los fenómenos que hemos observado al hacer ASO para los mercados regionales es que los desarrolladores locales ocupan una posición fuerte en el mercado de las aplicaciones móviles, por lo que es necesario centrarse en ellos a la hora de localizar las páginas del listado de aplicaciones. Un ejemplo de ello es la lista de las principales aplicaciones por número de instalaciones en el nicho de los sistemas de vigilancia de bebés en el Reino Unido, Estados Unidos y Japón:
Reino Unido
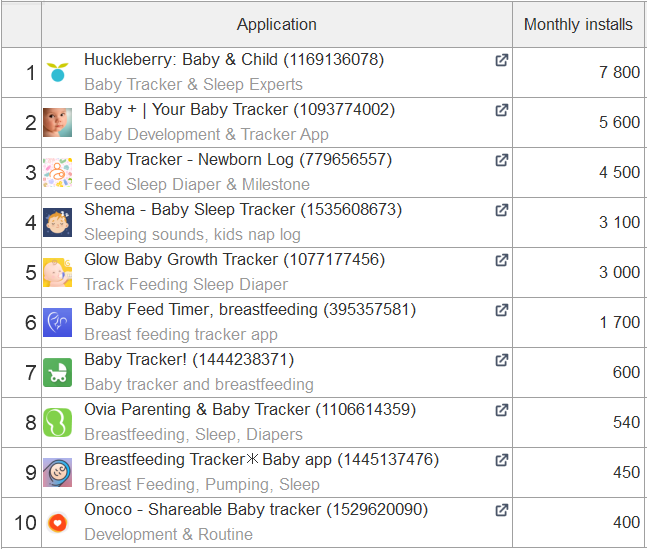
![]()
EE.UU.
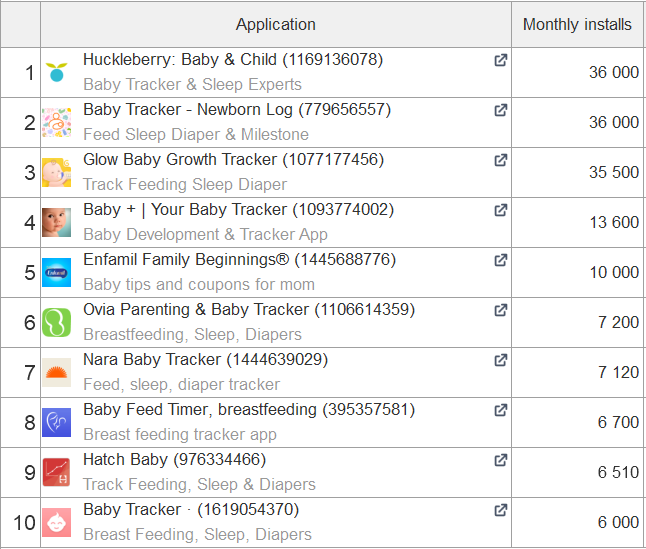
Japón
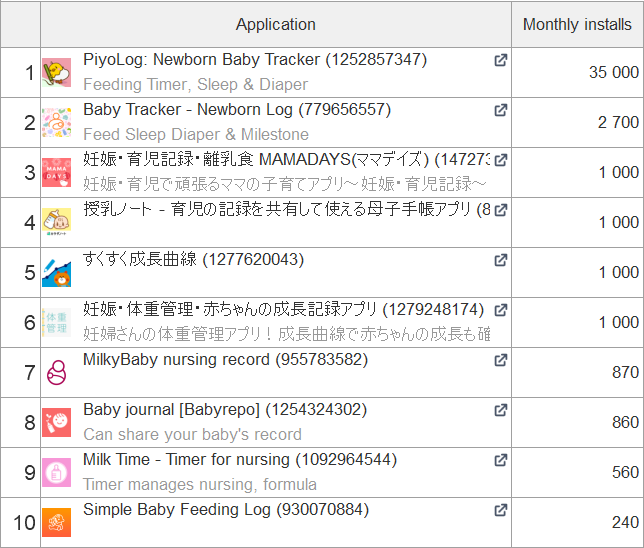
Como se puede ver, hay diferencias significativas en los rankings de búsqueda: en los países occidentales predominan los competidores globales, mientras que en Japón solo lo hacen los locales.
2. Localización de marcas en los países de la región
Los usuarios de la zona de Asia prefieren utilizar variantes locales de marcas conocidas. Y en China, por ejemplo, el gobierno apuesta por la pureza de la lengua materna, sobre todo a través de la legislación. Del mismo modo, los nombres de las aplicaciones también se suelen localizar. Para ello se pueden adoptar dos estrategias: transmitir el sonido del nombre y el contenido.
Al transmitir el sonido, el traductor trata de preservar la identidad fonética, es decir, la forma en que el consumidor percibe el nombre de la marca. Al hacerlo, el contenido del nombre adaptado suele cambiar. A continuación se muestra un ejemplo de adaptación del nombre de la aplicación Le Baby – breastfeeding, sleep para China:
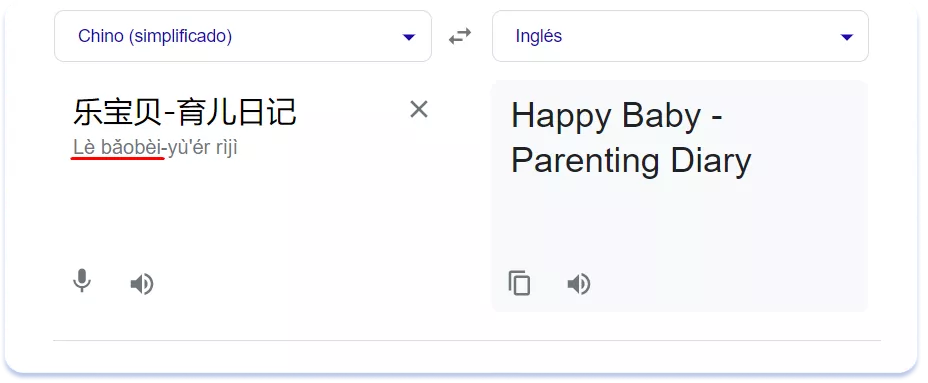
El sonido del nombre sigue siendo el mismo, pero el significado, aunque haya cambiado, sigue sonando bien.
Y aquí tenemos un ejemplo de adaptación semántica del nombre TinyLog en chino:
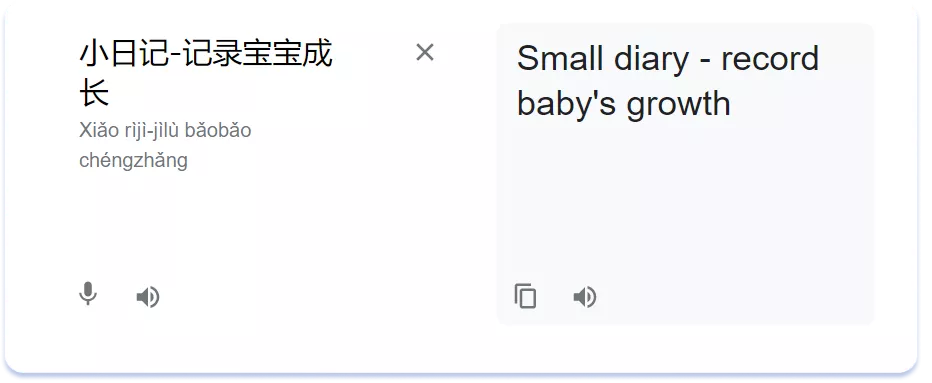
En Japón, el proceso de adaptación de los nombres resulta complicado debido a la existencia de tres sistemas de escritura del japonés: el kanji, que son caracteres tradicionales de origen chino, y los dos alfabetos que lo componen, el hiragana y el katakana. Este último se utiliza a menudo para transliterar palabras extranjeras al japonés, incluidos los nombres de marcas. Además, los tres sistemas de escritura pueden estar presentes en la misma frase japonesa.
He aquí un ejemplo de adaptación al japonés del nombre de la aplicación PiyoLog: Newborn Baby Tracker:
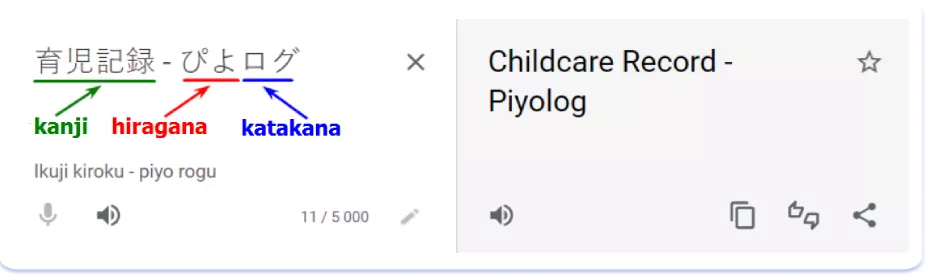
Como se puede ver, se han utilizado dos componentes del alfabeto a la vez para transmitir el sonido del nombre "PiyoLog".
Hay que tener en cuenta que la región asiática es muy diversa culturalmente. Por eso, la localización de los nombres de las aplicaciones puede variar mucho de un país a otro. Un estudio detallado del mercado local y la ayuda de un hablante nativo que conozca bien el contexto cultural de su país te ayudarán a adaptar correctamente el nombre de la marca o de la aplicación.
3. Diversidad léxica de las lenguas orientales
Las lenguas regionales de Asia tienen un vocabulario bastante rico, lo cual influye también de manera significativa en el núcleo semántico: hay muchas grafías de palabras y conceptos diferentes. Por ejemplo, la palabra "bebé" se escribe de forma diferente en chino y en coreano:
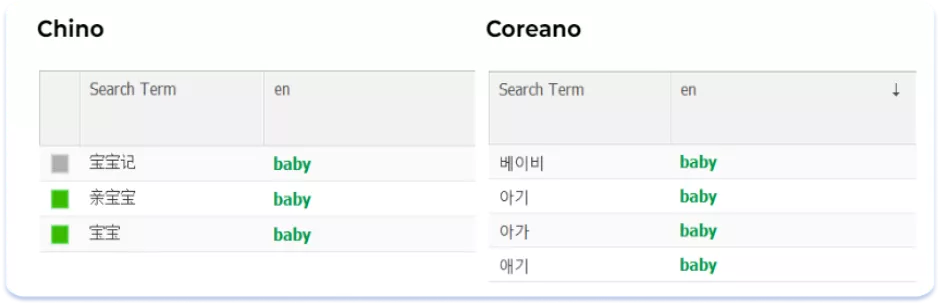
Entender cuál de las posibles variantes aparece más orgánica en el texto resulta difícil y solo alguien que esté profundamente inmerso en esa cultura lingüística estará a la altura de esa tarea. Es recomendable trabajar con hablantes nativos a la hora de preparar metadatos textuales para las lenguas asiáticas. Incluso los conocimientos y habilidades de un traductor profesional pueden no ser suficientes para localizar correctamente los metadatos para esta región (para preservar pequeños matices en el significado y el tono de la escritura).
4. Peculiaridades de la puntuación en las lenguas orientales
Una característica importante de las lenguas de la zona de Asia es el sistema de puntuación, algo que los europeos tienden a considerar poco común.
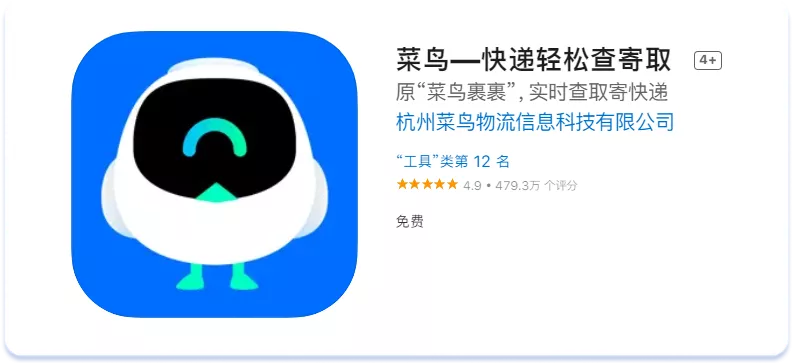
Una de las características más significativas que afectan a la apariencia de los metadatos textuales y a la clasificación de las aplicaciones para las consultas de búsqueda incluidas en los metadatos son las reglas especiales de uso de los espacios en las lenguas orientales. En la escritura tradicional china y japonesa no se utilizan espacios y las palabras de una frase se escriben seguidas, pero separadas por signos de puntuación únicamente cuando es necesario. Así se ve, por ejemplo, el nombre de una de las aplicaciones de rastreo de paquetes en la página de la App Store:
Y así es como quedaría el título desglosado en palabras sueltas:
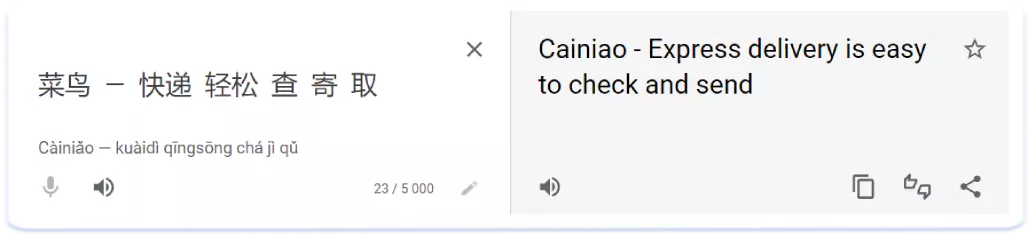
Curiosamente, al incluir cada una de estas "palabras" sueltas en los metadatos del texto del listado de la App Store, la aplicación también se clasifica para la frase escrita en conjunto. Por ejemplo, para que se indexe el término de búsqueda anterior "菜鸟-快递轻松查寄取" hay que añadir palabras clave individuales para este término de búsqueda en el campo de palabras clave: 菜鸟,快递,轻松,查,寄,取. Esta característica hace que los metadatos de texto y los textos en chino y japonés tengan por lo general una gran capacidad y sean ricos en palabras clave. Recomendamos no añadir demasiadas en los campos Título y Subtítulo de las localizaciones asiáticas para evitar que la App Store los marque como relleno de palabras clave.
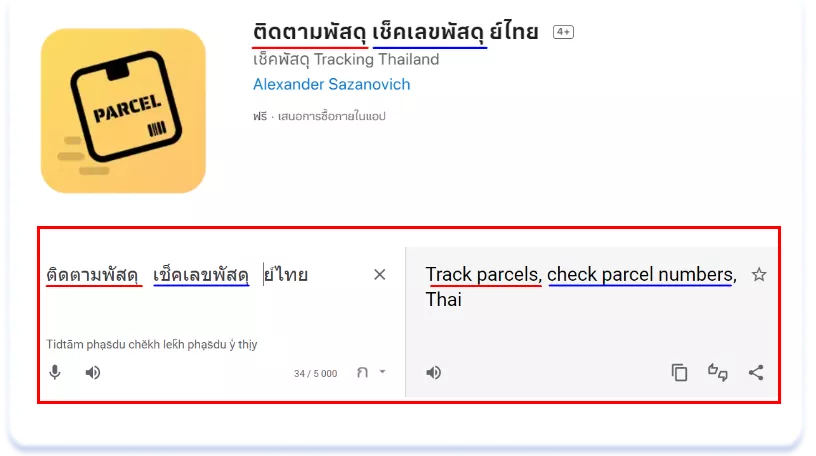
El caso del tailandés es ligeramente diferente. En este idioma, los espacios solo se utilizan para separar frases y no hay espacios entre palabras dentro de una frase. Por ejemplo, la página de una de las aplicaciones de rastreo de paquetes en tailandés tiene este aspecto:

Desglosemos el subtítulo anterior en palabras por separado:
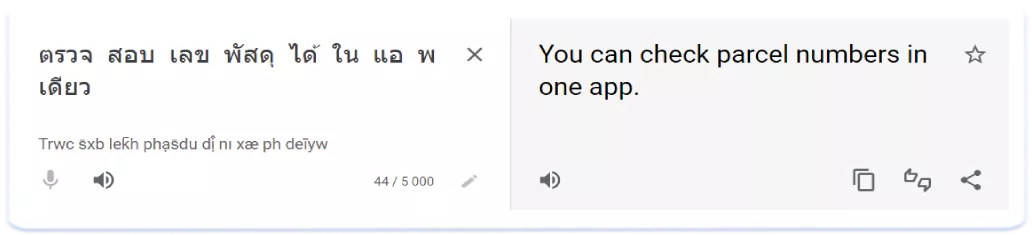
Pero a diferencia de los idiomas jeroglíficos, el hecho de añadir todas las palabras individuales de un término de búsqueda a los metadatos probablemente no servirá para clasificar una frase que se escribe junta. Es decir, para clasificar un término de búsqueda como "เช็คพัสดุ" ("comprobar el paquete"), habría que añadirlo a los metadatos en su totalidad. Por suerte, la mayoría de las consultas de búsqueda son frases sueltas que pueden escribirse con un espacio en el título y el subtítulo o con una coma en las palabras clave. La siguiente aplicación se clasificará para dos consultas relevantes: "ติดตามพัสดุ" ("seguimiento del paquete") y "เช็คเลขพัสด" (comprobar el número de paquete) como frases independientes:
ติดตามพัสดุ เช็คเลขพัสดุ ย์ไทย
Las diferencias de puntuación entre las lenguas europeas y asiáticas no se limitan al uso de los espacios. Las lenguas locales de la región emplean su propio sistema de signos de puntuación y reglas para su uso. Como ejemplo, he aquí un fragmento de la descripción de la aplicación de seguimiento de la lactancia materna:

Vemos el uso de caracteres chinos y japoneses específicos en el texto: la coma "," y el punto chino "。". Al mismo tiempo, el texto también parece contener las conocidas comas y guiones "europeos", pero esto no es del todo así. En la escritura china y japonesa, la anchura de los signos de puntuación debe coincidir con la anchura del carácter, por lo que los signos de puntuación ya contienen un espacio "incorporado", creando la sangría necesaria entre dos caracteres colocados uno al lado del otro. En este caso, tanto el signo de puntuación como el espacio "incorporado" se cuentan como un solo carácter. EnRadASO, llamamos a estos caracteres "supersímbolos". Veamos una pequeña lista de ellos:
- Punto chino "."
- coma china ",";
- coma en forma de gota ",";
- dos puntos ":"
- guion "-";
- punto y coma ";"
- signo de exclamación "!"
- signo de interrogación "?"
- interjección "・".
Puedes utilizarlos para ahorrar espacio en las localizaciones chinas y japonesas. Estos caracteres también pueden utilizarse en otras localizaciones, pero hemos observado que algunos de ellos "pegan" las palabras compartidas. Por ejemplo, cuando se utiliza una coma china en esta estructura de frase, "bebé, rastreador de etapas", el listado de aplicaciones probablemente se clasificará para el término de búsqueda "rastreadordeetapas del bebé". En cuanto a las consultas con "bebé" y "etapas", la aplicación no se clasificará. Lee más sobre el uso de "supersímbolos" en el canal de Telegram de RadASO:
Las lenguas de la zona de Asia también tienen otros signos de puntuación, algunos de los cuales no se mencionan en este artículo: variedades específicas de comillas, paréntesis (en japonés, por ejemplo, hay 14 variedades), caracteres que repiten jeroglíficos, etc. Solo un hablante nativo o una persona que esté totalmente inmersa en el contexto lingüístico y cultural del país en cuestión puede entender realmente los entresijos de las lenguas asiáticas.
5. Rasgos distintivos de la región sobre la visión del mundo
Al trabajar con metadatos textuales, hay que tener en cuenta las diferencias entre las distintas culturas y los habitantes de la región asiática no son una excepción en este sentido. Mientras que los países de Europa, Norteamérica y Australia se caracterizan por el uso de un lenguaje claro y conciso, y por el individualismo, el lenguaje escrito de los asiáticos tiene una forma de comunicación más respetuosa y un énfasis en la interacción humana. Además, los textos suelen ser más abundantes y ricos, no tan sucintos como en el mundo occidental. La diferencia entre los enfoques occidental y oriental de la escritura textual (y de los metadatos textuales en particular) se evidencia con mayor claridad al comparar las versiones estadounidense y japonesa de las páginas de listados de aplicaciones:
![]()
Traducción del título y subtítulo de la versión japonesa de la página:
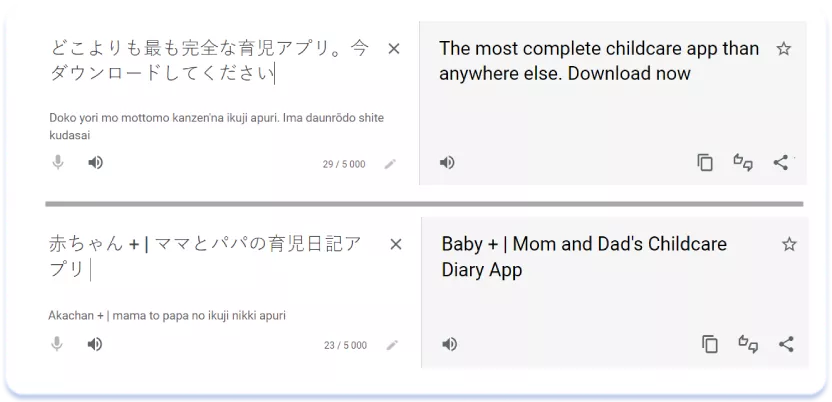
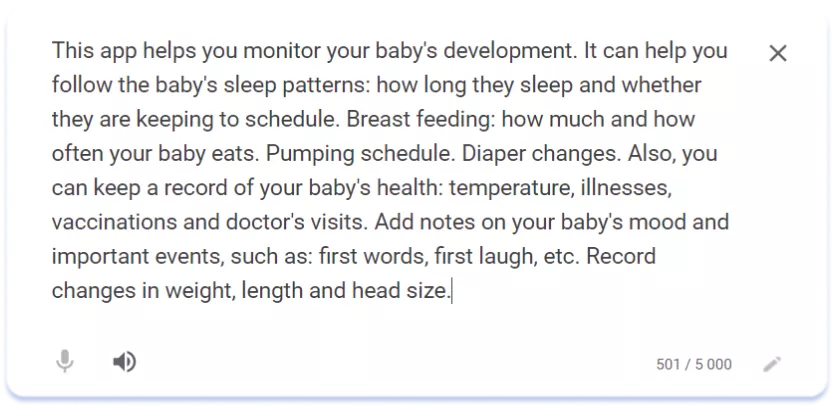
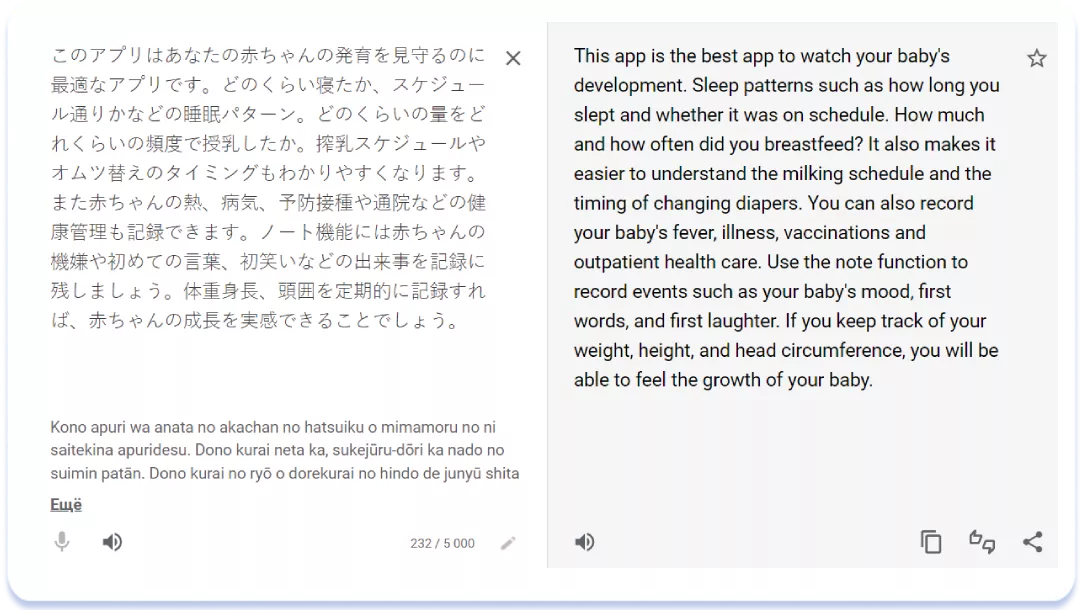
El estilo más rico de los textos de los títulos y subtítulos en japonés se debe en parte a la capacidad de la escritura japonesa y a la posibilidad de incluir más información en el límite de 30 caracteres. Sin embargo, el diferente tono de escritura al dirigirse al público también es bastante evidente. Una comparación de las descripciones de otra aplicación, My Baby – Newborn Tracker, en las versiones americana y japonesa de la página del listado de aplicaciones, demuestra las mismas tendencias:
Localización de descripción en inglés (EE.UU)
Descripción en la localización de Japón
6. Diferencias regionales en chino
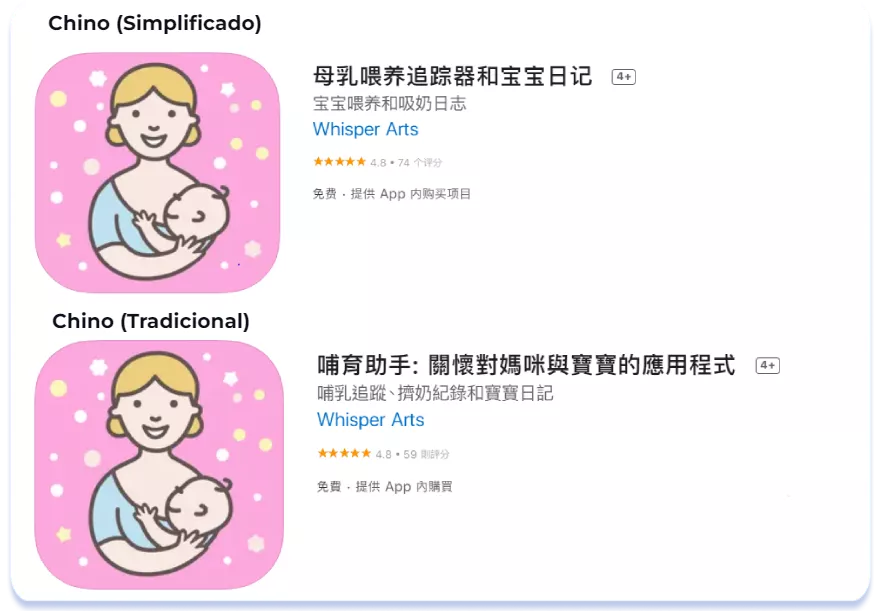
Para concluir nuestro análisis de la región asiática, vamos a abordar brevemente la cuestión de las diferencias regionales del chino. Como ya se sabe, existen dos localizaciones del chino en la App Store: el chino (simplificado), válido en China, Singapur y Estados Unidos, y el chino (tradicional) para Hong Kong, Taiwán y Macao. Todas estas regiones tienen importantes diferencias políticas, económicas e históricas. Al localizar la página del listado de aplicaciones al chino, hay que centrarse en el núcleo semántico, los competidores y las peculiaridades culturales de tu país más prioritario. A continuación se muestra un ejemplo de cómo la optimización de los metadatos de la aplicación Breastfeeding Newborn tracker varía entre China (chino [simplificado]) y Taiwán (chino [tradicional]):
Chino (simplificado) & Chino (tradicional)
Características de los locales occidentales: regiones europea, americana y australiana
Estas regiones tienen muchos lazos históricos y, por tanto, son muy similares culturalmente. Veamos sus principales particularidades.
1. El impacto de las diferencias léxicas entre lenguas en la formación de metadatos
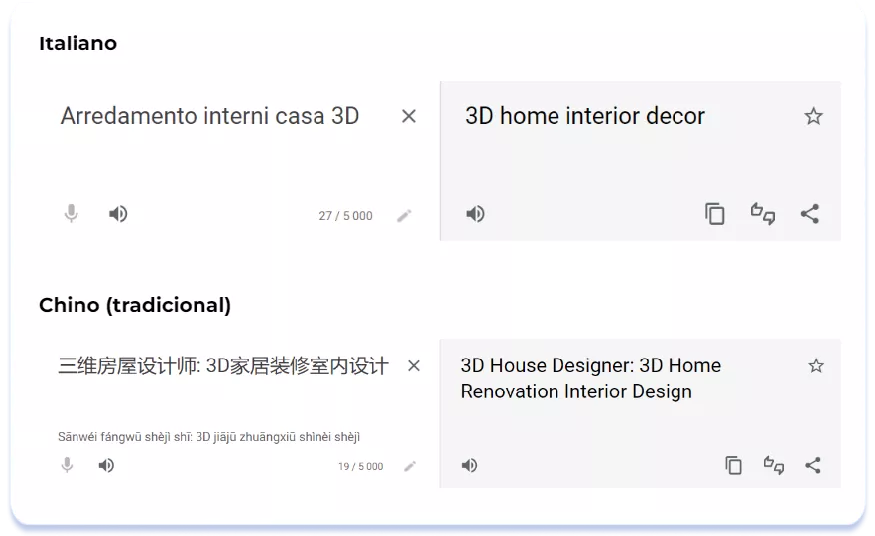
Al describir las características de los países asiáticos, mencionamos que los países de esta región suelen tener estilos de escritura más ricos. Sin embargo, las diferencias culturales y lingüísticas entre los países orientales y occidentales no son la razón principal por la que los metadatos textuales de las páginas de listados de aplicaciones localizadas en Occidente tienen un aspecto más seco y lacónico que sus homólogas orientales. La razón principal es la longitud típica de las palabras en los idiomas europeos. Si optimizas tu página de aplicaciones para las localidades europeas, no podrás incluir un gran número de términos de búsqueda en los metadatos (recuerda que los campos Título y Subtítulo están limitados a 30 caracteres cada uno). Veamos, por ejemplo, la aplicación Room Planner – Home Design 3D, optimizada para los idiomas italiano y chino (tradicional):
Italiano & Chino (tradicional):

Aunque el Título y el Subtítulo en la versión italiana son más largos (27 y 28 caracteres, respectivamente) que en la versión china (19 y 24 caracteres), esta última tiene una ventaja en cuanto a la información que puede incluir y la densidad de palabras clave. A continuación se muestran las traducciones de los títulos de las versiones italiana y china (tradicional):
Los mayores problemas con las palabras clave de los metadatos radican en la optimización de la página del listado de aplicaciones para las localizaciones de las lenguas romances como el francés, el español, el italiano y el portugués, así como algunas lenguas germánicas como el alemán y el holandés. El inglés, por su parte, es uno de los más cortos y adecuados para la optimización de palabras clave entre todos los idiomas occidentales. La empresa Alconost ha elaborado una tabla estadística que muestra cómo puede variar la longitud del texto cuando se transmite la misma información en diferentes idiomas. He aquí un extracto de la tabla:
|
Lengua de origen |
Lengua de destino |
Cómo de largo (+) o corto (-) es el texto en la lengua de destino |
|---|---|---|
|
Inglés |
Francés |
21,18% |
|
Inglés |
Español |
19,52% |
|
Inglés |
Italiano |
17,91% |
|
Inglés |
Alemán |
16,67% |
|
Inglés |
Holandés |
13,80% |
|
Inglés |
Portugués (Portugal) |
14,29% |
|
Inglés |
Portugués (Brasil) |
12,96% |
|
Inglés |
Polaco |
9,33% |
|
Inglés |
Ruso |
9,11% |
|
Inglés |
Checo |
3,70% |
|
Inglés |
Árabe |
–6,25% |
|
Inglés |
Japonés |
–39,68% |
|
Inglés |
Coreano |
–44,04% |
|
Inglés |
Chino (simplificado) |
–61,97% |
|
Inglés |
Chino (tradicional) |
–63,80% |
2. Uso de la semántica local e inglesa con un núcleo semántico estrecho
Europa está integrada por muchos países, entre los que se encuentran naciones pequeñas desde el punto de vista del tamaño de la población: los países escandinavos, bálticos y del Benelux, así como un gran número de países del centro de Europa. Al recopilar el núcleo semántico de estos países, nos encontramos con el problema de no disponer de suficiente semántica en las lenguas locales para poblar los metadatos. Una posible solución es utilizar más semántica en inglés, pero antes de optar por esta vía, debemos tener muy en cuenta los diferentes niveles de penetración del inglés en la cultura de cada país. Wikipedia proporciona un mapa del dominio del inglés en Europa:
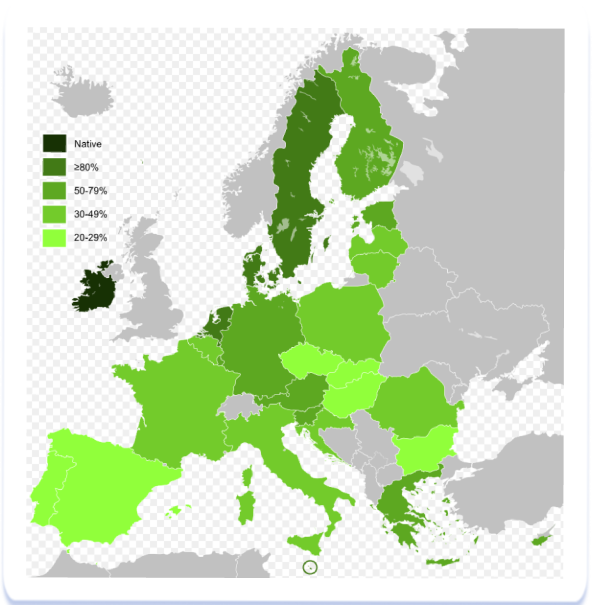
Como podemos ver, el mayor número de personas que hablan inglés se registra en Escandinavia, así como en los países cuyas lenguas están relacionadas con el inglés, es decir, Alemania, Austria y los Países Bajos. En el este y el sur de Europa, la penetración del inglés es más débil.
Veamos cómo influye la permeabilidad del inglés en los metadatos textuales en el ejemplo de Clockmaker: Mystery Match 3. Presentamos extractos de la página del listado de aplicaciones para la configuración regional del inglés (Reino Unido) en todos los países europeos, así como para las configuraciones regionales de los idiomas de varios países poco poblados en los que el núcleo semántico también es pequeño.
The Title field of the Danish and Dutch locales, where English is strong, is saturated with frequently used elements of English semantics: logic, puzzle, and jewel. Remember, keywords specified in this field have the highest value. Moreover, in the Dutch locale, the Subtitle field consists exclusively of English keywords:
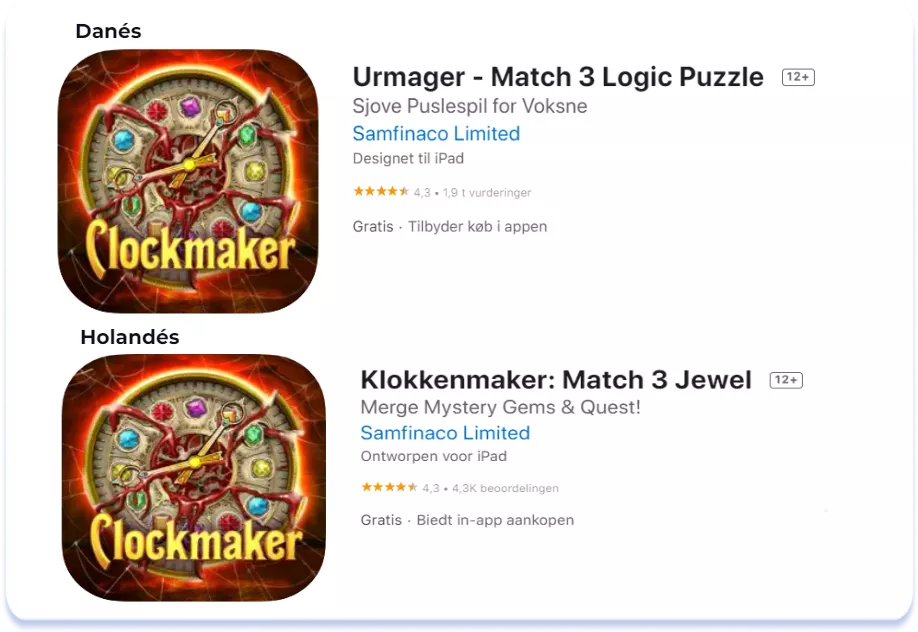
Al mismo tiempo, el Título de las localizaciones húngaras y eslovacas consiste en una semántica local de baja frecuencia. La excepción es la palabra clave "match 3" en la localización eslovaca, pero ésta ya está incluida en la localización inglesa (Reino Unido). Por su parte, el Subtítulo de la localización húngara está totalmente en húngaro y la localización eslovaca solamente contiene palabras en inglés.
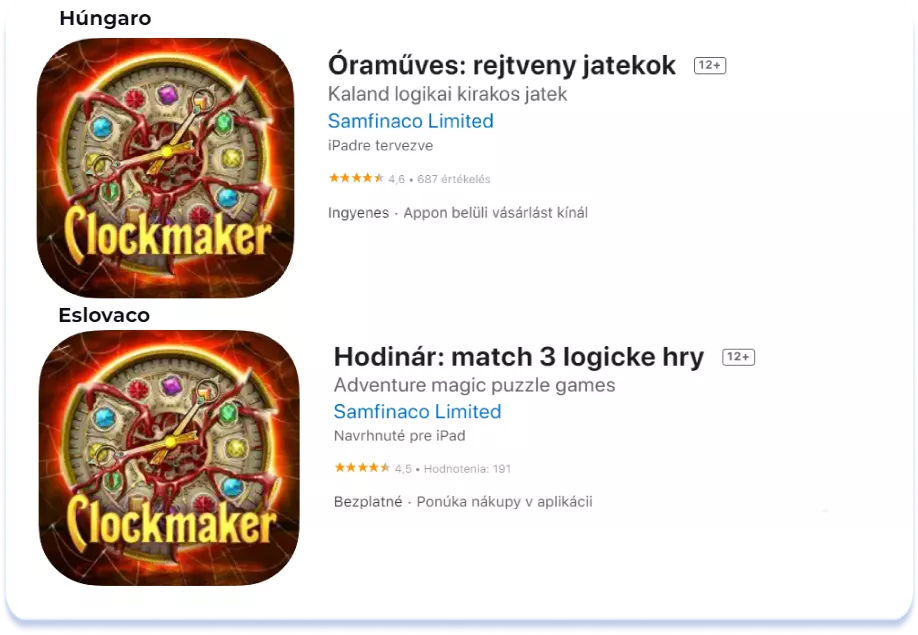
En varias aplicaciones, si hay una falta de semántica, los campos Título y Subtítulo se rellenan con palabras clave en inglés en el lugar en el que normalmente se utilizaría el idioma local. El texto de la casilla Descripción se localiza al idioma local (como ya hemos mencionado, en la App Store, el campo Descripción no está indexado):
Kitten Match (localización checa)

A la hora de valorar esta opción, hay que tener en cuenta que, si bien ganamos en el apartado de optimización de palabras clave (semántica en inglés más frecuente en los campos de Título y Subtítulo), al mismo tiempo corremos el riesgo de reducir sin querer las tasas de conversión en el proceso (por ejemplo, menor número de instalaciones de la aplicación), ya que la mayoría de los usuarios prefieren consumir los contenidos en su lengua materna.
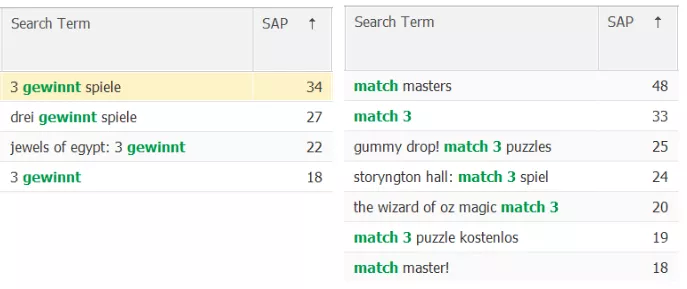
Cada país tiene una variedad de especificidades nacionales y de nicho en cuanto al uso del vocabulario en inglés. Solo un análisis detallado del núcleo semántico y de los competidores ayudará a determinarlas. Por ejemplo, en Alemania, la variante nacional del juego Match-3 "3 gewinnt" se utiliza mucho al mismo tiempo que el término de búsqueda "match 3":

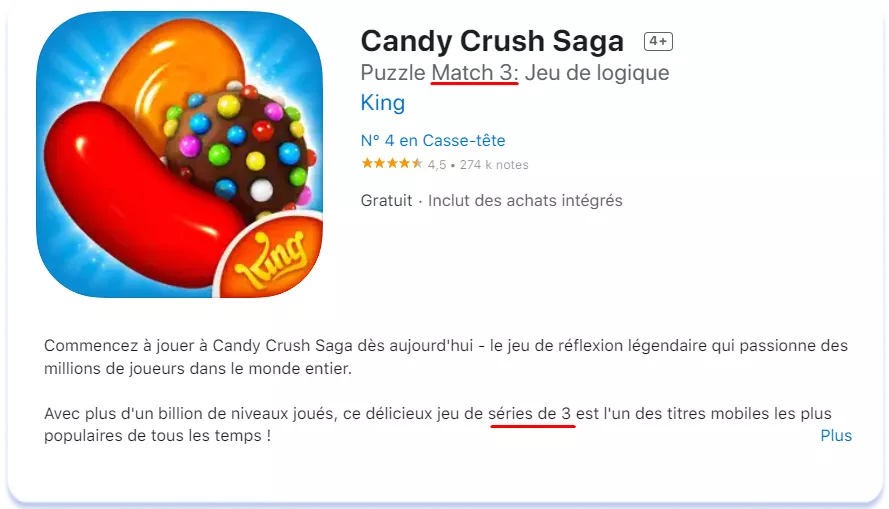
Mientras tanto, en Francia, donde el dominio del inglés es menor que en Alemania y donde la población suele ser reacia a hablar en inglés (influenciada por la antigua rivalidad entre ambos países), se utiliza el término en inglés "match 3" como término principal. En el ejemplo siguiente, la variante nacional del nombre del juego "séries de 3" se utiliza en el campo Descripción, que no se indexa en la App Store, mientras que la variante inglesa se utiliza en el Título:
3. Diferencias regionales entre el inglés, el francés, el portugués y el español
Otra característica de las regiones europea, americana y australiana es la amplia distribución geográfica de las principales lenguas: inglés, francés, portugués y español. La App Store ha creado incluso localizaciones separadas para diferentes variantes de estos populares idiomas como el inglés (Reino Unido), el inglés (Estados Unidos), el inglés (Canadá) y el inglés (Australia). Mira nuestra tabla para más detalles sobre la cobertura de los países. Como resultado, las versiones regionales de estas lenguas pueden diferir significativamente en términos de vocabulario, patrones de habla e incluso reglas gramaticales. Por ejemplo, a pesar del pasado histórico común de Estados Unidos y el Reino Unido, las versiones nacionales del inglés en estos países difieren significativamente desde el punto de vista gramatical:
- Las palabras en inglés americano que terminan en "-or" se convierten en "-our" en inglés británico: "colour," "favour," "flavour" or "behaviour";
- Algunas palabras en inglés americano terminadas en "-er" se convierten en "-re" en inglés británico: "centre", "theatre";
- En inglés americano, observamos la duplicación de la letra "l" en muchas palabras: "skillful", "fulfill", "enroll" ("skilful", "fulfil", "enrol" en inglés británico).
Además, el vocabulario de las dos variantes lingüísticas también es diferente. A continuación comparamos la popularidad de los términos de búsqueda (SAP) "truck games"/"lorry games" (juegos de camiones) y "jail games"/"prison games" (juegos de prisión) en Estados Unidos y en el Reino Unido:
|
Término de búsqueda |
Traducción |
SAP* Inglés (EE.UU.) |
SAP* Inglés (Reino Unido) |
|---|---|---|---|
|
truck games |
games with trucks |
62 |
39 |
|
lorry games |
games with trucks |
– |
32 |
|
jail games |
prison games |
29 |
8 |
|
prison games |
prison games |
32 |
24 |
*Popularidad de los anuncios de búsqueda (SAP): muestra la popularidad del término de búsqueda de 5 a 99.
Como se puede ver, el término "lorry games" se utiliza exclusivamente en inglés británico, mientras que "jail games" es típico del inglés americano.
A veces la misma expresión puede significar cosas diferentes en distintas variantes regionales del idioma. Veamos los resultados de la búsqueda del término "coin price" en EE.UU. y en el Reino Unido. Se observa que el valor de popularidad del término de búsqueda (SAP) en los dos países no es muy diferente: 8 en EE.UU. y 5 en el Reino Unido.

Como podemos ver, en EE.UU., el término de búsqueda se utiliza principalmente para describir la numismática y solo una aplicación en el top 10 está relacionada con el nicho de las criptomonedas: CoinMarketCap: Crypto Tracker. En el Reino Unido ocurre lo contrario: los resultados de los términos de búsqueda consisten casi exclusivamente en aplicaciones de criptomonedas. La única excepción es PCGS CoinFacts Coin Collecting, que ocupa el primer lugar en el ranking.
Las diferencias regionales significativas también son características de otras lenguas que se hablan en muchas partes del mundo. Aquí se muestra una comparación de la popularidad de los términos de búsqueda (SAP) "soldes" y "aubainerie" en Francia y Canadá, que ilustra la disimilitud léxica de las versiones canadiense y francesa de la lengua francesa:
|
Término de búsqueda |
Traducción |
SAP* Francés |
SAP* Francés (Canadá) |
|---|---|---|---|
|
soldes |
sale |
25 |
5 |
|
aubainerie |
sale |
– |
14 |
*Popularidad de los anuncios de búsqueda (SAP): muestra la popularidad del término de búsqueda de 5 a 99.
Puedes leer más sobre las características regionales del francés y el inglés en Canadá y las peculiaridades de la localización de aplicaciones para el mercado canadiense en este artículo de Alconost.
Veamos ahora el impacto de las diferencias léxicas en las páginas de listados de aplicaciones en la tienda. Comparemos, por ejemplo, los metadatos de texto en inglés americano y australiano de las tres principales aplicaciones del mercado australiano en el nicho de los casinos sociales (juegos simulados que se pueden encontrar en las salas de los casinos, pero en los que no se puede ganar dinero real):
Inglés (Australia)
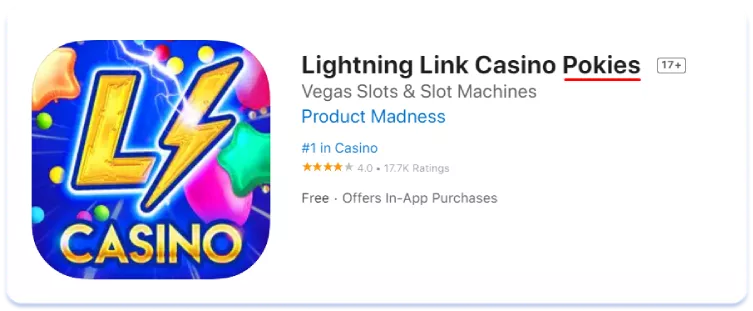
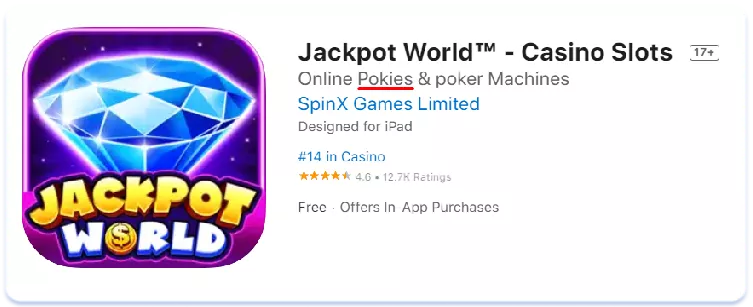

Inglés (EE.UU.)
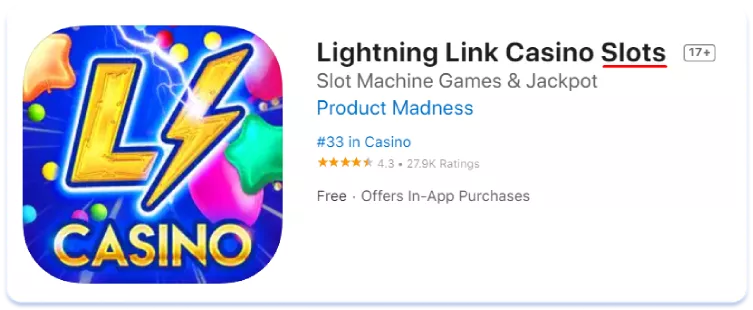
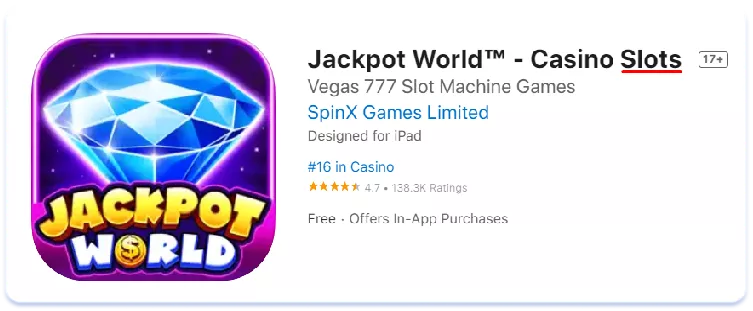
Cashman Casino Las Vegas Slots
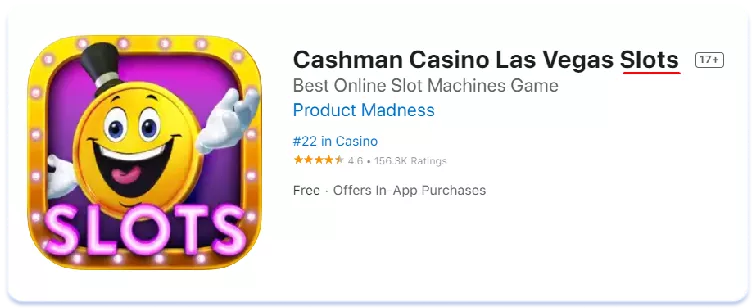
Como se ve, en Australia el término "pokies" se utiliza más para referirse a las máquinas tragamonedas que su homólogo estadounidense "slots". La conclusión en este caso es sencilla: un núcleo semántico recogido para una versión regional de una lengua puede ser completamente irrelevante para otra. Hay que recopilar y analizar siempre con cuidado la semántica de cada uno de los países para los que se localiza, por muy similares que parezcan el idioma y la cultura a primera vista.
Patrones de localización en Oriente Medio
Oriente Medio es una región interesante desde el punto de vista empresarial, con una de las tasas de ingresos medios por usuario (ARPU) más altas del mundo. Además, según el ya mencionado informe Mobile Market Forecast 2021–2025de Sensor Tower, la región está creciendo rápidamente; en 2025, habrá alcanzado una tasa de crecimiento del 208% en términos de ingresos en comparación con 2020:
Gasto de los consumidores de la App Store por región

Oriente Medio se encuentra entre las regiones europea y asiática y es culturalmente parecida a ellas. Centrémonos en las características culturales de esta región que afectan a los metadatos del App Store.
1. Diferencias regionales en la lengua árabe
Al igual que el mundo occidental, la región de Oriente Medio tiene una lengua dominante: el árabe. También se habla mucho fuera de Oriente Medio, en el norte de África, y tiene muchas diferencias regionales:
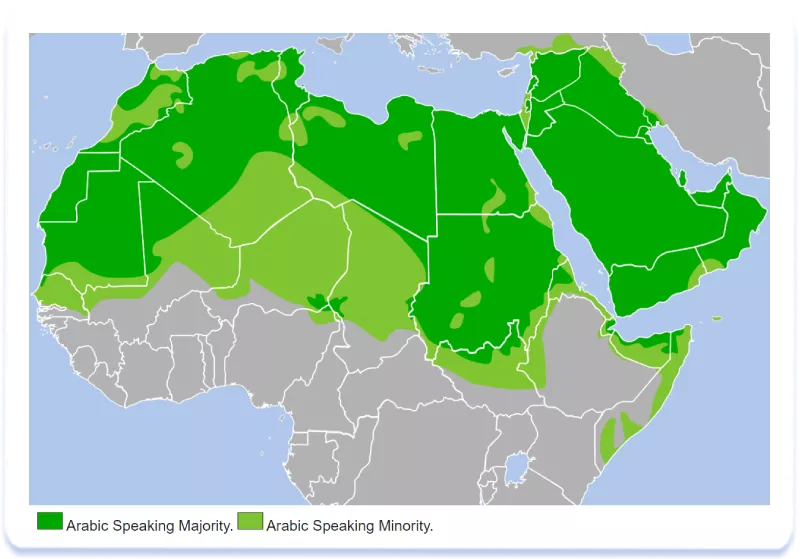
La configuración regional árabe de la App Store también se aplica aproximadamente a los mismos países (consulta nuestra tabla para conocer más detalles sobre la cobertura de la localización). La buena noticia es que, al trabajar con información textual, incluidos los metadatos, para cualquiera de los países con una localización árabe válida, utilizamos el Modern Standard Arabic (MSA) en lugar de los dialectos árabes locales. En consecuencia, la App Store solo admite una única configuración regional para el árabe. Al mismo tiempo, el proceso de recopilación de la semántica en árabe es similar al del inglés, el español, el francés y otros idiomas con una amplia difusión geográfica; el núcleo semántico se recopila para el país más importante en el que se quiere promocionar la aplicación. Por ejemplo, un núcleo semántico recogido para Egipto no sería efectivo si se quiere optimizar una página de listado de aplicaciones en un país como Arabia Saudí para hacer negocios.
2. Localización de nombres de aplicaciones y marcas en árabe
La necesidad de localizar los nombres de las aplicaciones y las marcas en árabe depende del nicho. Por ejemplo, el consenso es que los títulos de los juegos se suelen dejar escritos en inglés. Lo hemos comprobado con el nicho de juegos Match-3 en Arabia Saudí. De las 10 primeras aplicaciones por número de instalaciones, solo cuatro tienen una página de listado de aplicaciones localizada en árabe. A continuación se muestran extractos de las páginas de estas aplicaciones con el correspondiente Título y Subtítulo:



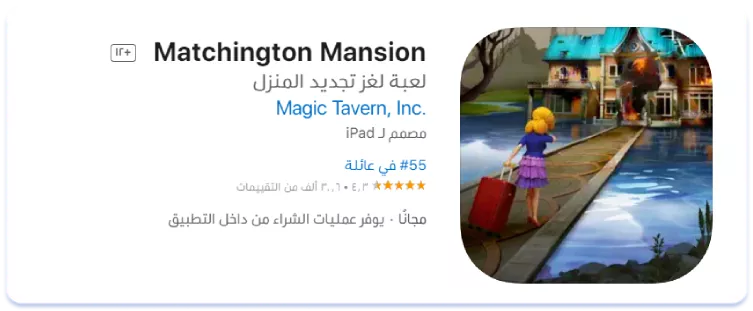
De hecho, en todos los ejemplos anteriores, los nombres de las aplicaciones se han dejado escritos en inglés. Pero la situación fue distinta cuando analizamos el nicho de monitoreo de la actividad infantil. De las tres primeras aplicaciones por número de descargas, dos tenían un nombre completamente localizado en árabe y una tenía un nombre parcialmente localizado:
![]()
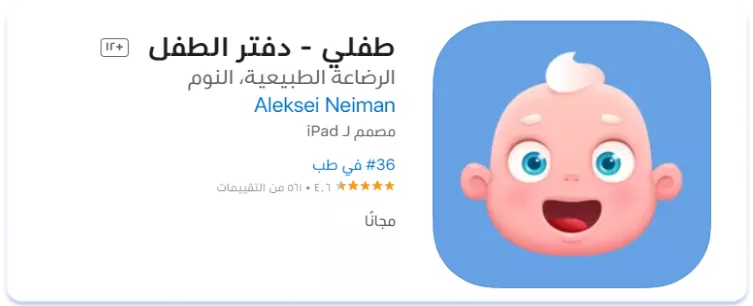

En resumen, antes de localizar la lista de aplicaciones al árabe, hay que realizar una amplia investigación sobre el nicho y los competidores. No existe una regla única para localizar los nombres de las aplicaciones en árabe.
Esta sección concluye con otro dato importante: en árabe y hebreo, la dirección de la escritura es de derecha a izquierda. En cambio, los números y las partes con alfabeto latino se leen de izquierda a derecha. En uno de los ejemplos anteriores, el texto del Título se lee así:
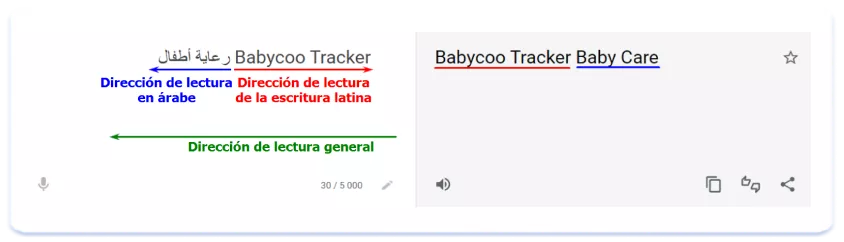
Sin embargo, puede que los títulos de este tipo mixto no se muestren correctamente en la búsqueda de la App Store: la parte de alfabeto latino se mostrará en su totalidad independientemente de su ubicación en el Título, mientras que puede que no ocurra lo mismo con la parte en árabe. El texto se mostrará íntegramente en alfabeto latino o en árabe.
3. Comprender la riqueza del vocabulario árabe
El árabe es una lengua de gran riqueza léxica. Hay diferentes grafías de los mismos términos y nombres:
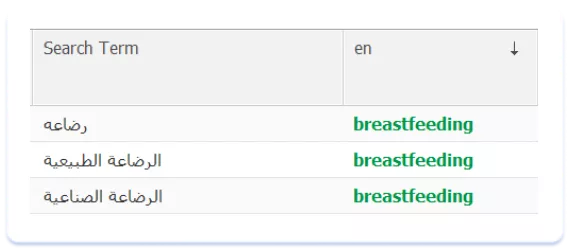
Nos encontramos con una situación similar al analizar las lenguas de la región asiática.
En árabe, el problema se resuelve de la misma manera: trabajando con un hablante nativo a la hora de localizar el texto. Solo un hablante nativo puede ayudarte a elegir las palabras que más se ajustan a los metadatos textuales.
4. Palabras que deben evitarse en los metadatos de texto en árabe
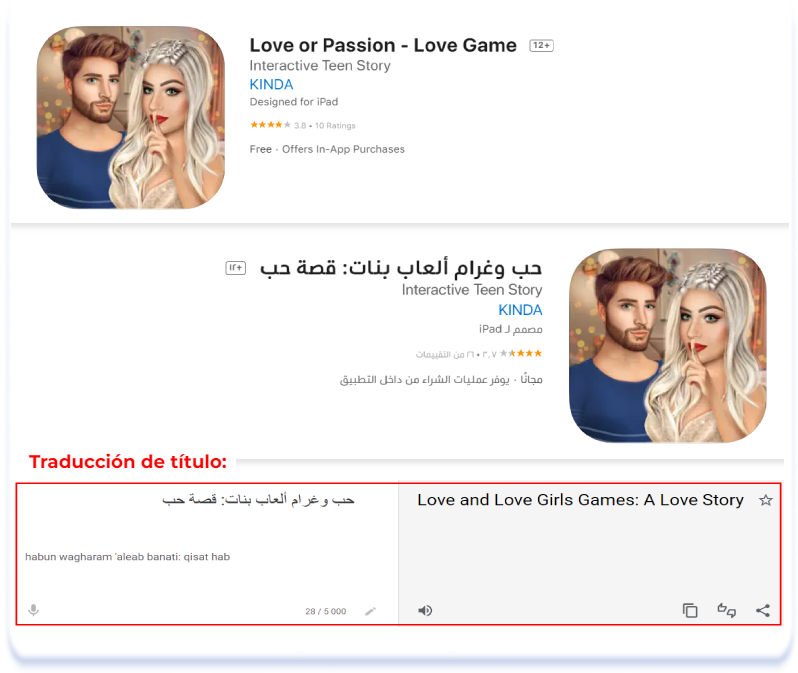
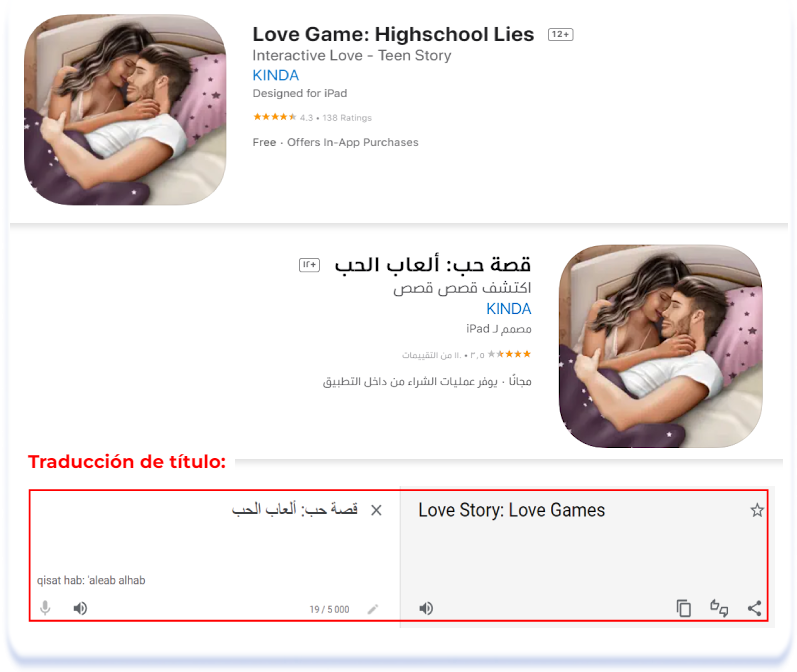
Hay muchos temas que deben evitarse en la cultura árabe: representaciones demasiado explícitas de las relaciones humanas y temas relacionados con el alcohol, las drogas, la violencia, el misticismo y el juego. A la hora de localizar las páginas de listados de aplicaciones para el mercado árabe, un hablante nativo ayudará a determinar la conveniencia de utilizar ciertas palabras en los metadatos. Anteriormente, mencionamos que al localizar juegos, los nombres suelen dejarse en inglés. A continuación se muestran algunos ejemplos de juegos cuyos títulos se han localizado en árabe para evitar una redacción ambigua en el título.
Love or Passion — Love Game (English [U.S.]) & حب وغرام ألعاب بنات: قصة حب
Love Game: Highschool Lies (English [U.S.]) & قصة حب: ألعاب الحب
Y en el siguiente ejemplo, para dar a la aplicación un toque aún más local, el juego se convirtió en una historia de amor "árabe":
Choose Your Story — Decisions (English [U.S.]) & قرارات اختر قصتك — العاب قصص
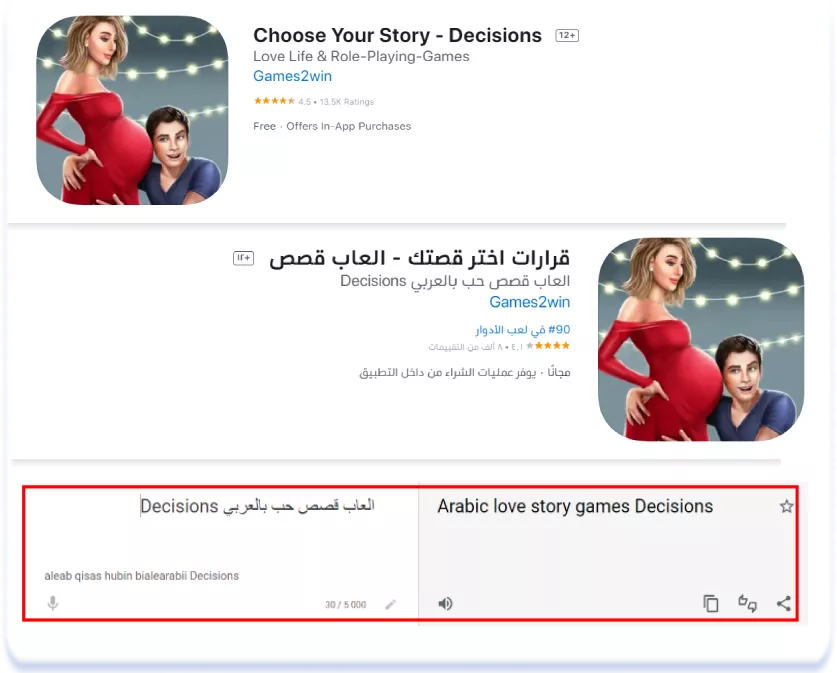
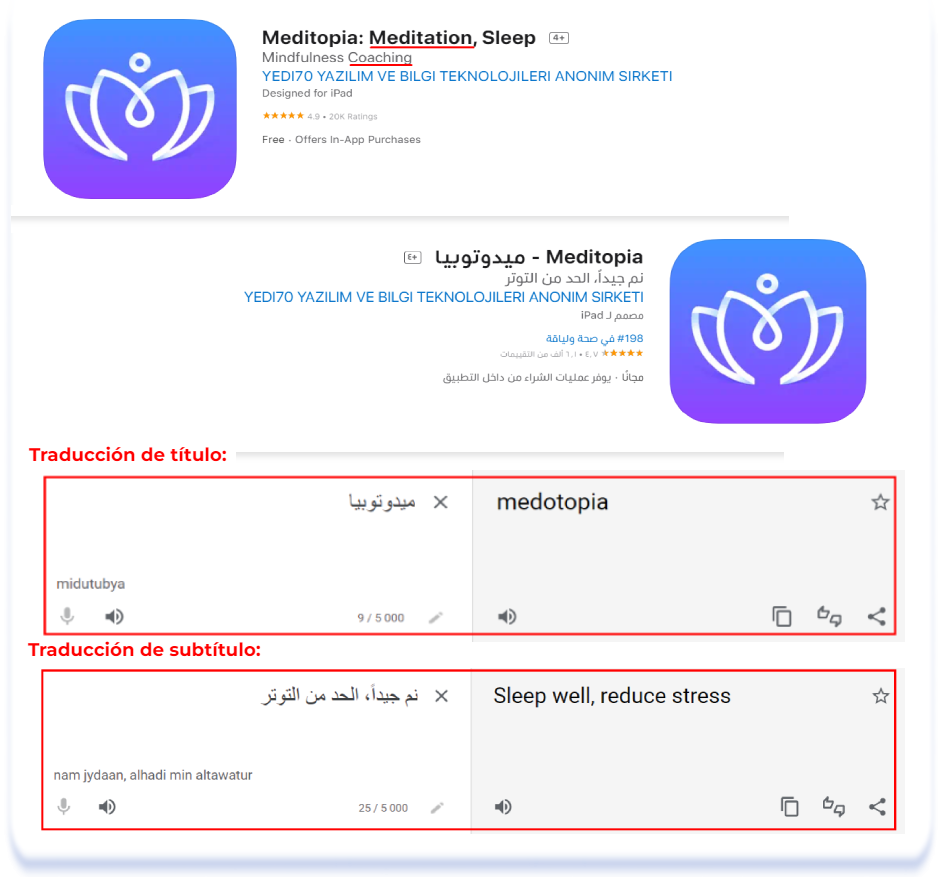
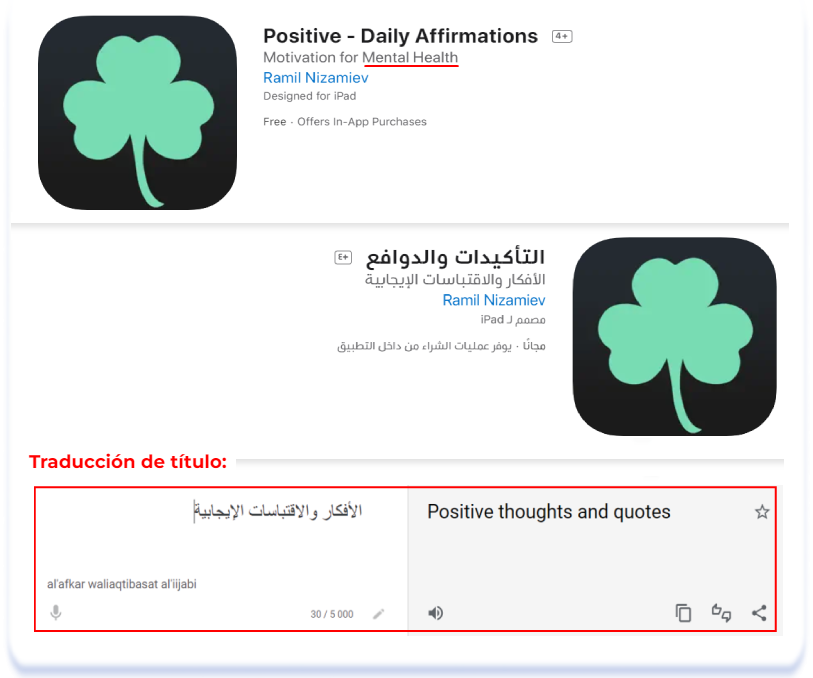
A veces los temas que hay que evitar no son obvios para las personas con una mentalidad occidental. Por ejemplo, temas completamente inofensivos como la psicología, la psicoterapia y las prácticas de salud mental siguen siendo tabú en la cultura árabe. No se habla de salud mental y el papel del psicólogo se asigna a una figura religiosa o a un médico. A continuación se muestran ejemplos de cómo la localización en árabe ha sustituido los tabúes en la cultura árabe por "salud mental", "coaching", "terapia cognitiva conductual (TCC)" e incluso "meditación":
Meditopia: Meditation, Sleep (English [U.S.]) & Meditopia — ميدوتوبيا
Positive — Daily Affirmations (English [U.S.]) & التأكيدات والدوافع
Moodnotes — Mood Tracker (English [U.S.]) & Moodnotes — مذكرات المزاج
![]()
El mundo está cada vez más globalizado y el número de temas tabúes en el mundo árabe ha ido disminuyendo con el tiempo. Pero adaptar los metadatos textuales y gráficos a las sensibilidades culturales de los países árabes sigue siendo la clave para conseguir promocionar las apps en sus mercados.
Las conclusiones
Algunos puntos importantes a tener en cuenta cuando se trabaja con metadatos textuales (las recomendaciones son igualmente válidas para la App Store y Google Play):
- Cuando empieces, fíjate en cómo han estructurado sus metadatos las aplicaciones de la competencia. Incluso algo rápido como un miniestudio de este tipo te ayudará a descubrir importantes matices culturales de la localización en las regiones a las que te diriges.
- Las diferencias en la cultura, la mentalidad e incluso el sistema legal de los distintos países son abismales. Solo un hablante nativo que esté inmerso en el entorno cultural de su propio país puede tener en cuenta todas estas peculiaridades.
- Ten cuidado al utilizar la semántica inglesa en los metadatos de texto visibles en países no anglófonos. La investigación de la competencia te dirá si tu enfoque es adecuado y apropiado.
- Las diferencias regionales entre los idiomas más hablados del mundo (inglés, francés, español, portugués, chino y árabe) son bastante importantes. Al compilar los metadatos, utiliza el núcleo semántico recogido para el país de la lengua a la que te diriges. Ten en cuenta que la App Store tiene varias localizaciones para muchos de estos idiomas (mira nuestra tabla, donde hemos recopilado datos sobre la cobertura de las localidades de los países).
- Al recopilar metadatos para diferentes países, utiliza los términos de búsqueda locales más populares en los idiomas locales: la menor competencia en las clasificaciones aumenta las posibilidades de obtener buenas posiciones para estos términos de búsqueda.
Y, por supuesto, recuerda que una página de listado de aplicaciones bien localizada no consiste solo en metadatos de texto bien compilados. Solo un esfuerzo exhaustivo en los metadatos textuales y gráficos ayudará a que tu listado de aplicaciones se asegure una buena posición en los resultados de búsqueda, tenga una alta tasa de conversión y tenga un excelente resultado financiero.
Leer también 10 diferencias entre los gráficos de App Store y Google Play.
Localización de texto: Kateryna Kalnova, RadASO.

 4
4
 2
2
 2
2
Artículos Relacionados
75 errores en la optimización ASO y el análisis de sus resultados
Nuestro equipo de expertos ha analizado cientos de campañas ASO y ha identificado los errores más comunes cometidos en el proceso de optimización.
Atraer a los usuarios a una aplicación móvil: La adquisición de usuarios como un proceso estratégico
La adquisición de usuarios es un proceso de marketing destinado a aumentar la audiencia a través de diferentes canales de tráfico
La historia de éxito de BNESIM: cómo aumentar el número de impresiones e instalaciones en dos iteraciones de metadatos
Tras el primer lanzamiento, el tráfico orgánico de la aplicación creció un 134%.