What is Indexing, and How to Prevent a Website from Being Indexed
In the field of search engine optimization (SEO), indexing is one of the key stages that determines the visibility of a website and its individual pages in search engines such as Google, Bing, Yahoo, etc. In this article, I’ll explain what indexing is and how it works, how to check if your site is being indexed, and how to correctly block your site from it.
What is indexing in simple terms?
Indexing is the process by which search engine crawlers (also known as spiders or bots) crawl webpages to gather information about their content. These robots follow links between pages and analyze the content. After collecting the data, they add the information to the search engine index.
A database index is a large database that contains collected data about web pages. It helps search engines quickly find pages that match user search queries. Having high-quality and relevant content in the index will ensure an efficient search experience for users.
How does website indexing work?
To effectively prevent a website from being indexed, you should first understand the indexing process.
Search engine crawlers start indexing a website by visiting it. Let’s say the search engine crawler wants to index the https://netpeak.net/ website. Here is an overview of the process:
- The search engine crawler starts by crawling the homepage of a website. It examines the HTML code, images, links, and other elements on the page.
- The search engine crawler then follows the links on the home page and crawls other pages. For example, if there is a link to https://netpeak.net/blog/category/seo/ on the home page, the robot will follow it.
- The search robot analyzes the content of the visited pages and collects text, images, videos, and other content elements. The https://netpeak.net/blog/category/seo/ page contains a list of articles and other information. This is what the robot needs.
- After gathering the information, the search robot adds the page to its index. This helps the search engine find it when the user enters relevant queries.
- The next steps are updating and reindexing. Search robots return to each site from time to time to update information and find new content. They scan these changes and update the index.
- The site then appears in search results. When a user types a query into a search engine, it uses its index to find the most relevant pages. For example, if a user searches for “how to create an SEO-friendly website architecture,” the search engine uses the index to find the page https://netpeak.net/blog/how-to-create-seo-friendly-website-architecture-best-practices/ and displays it in the results:
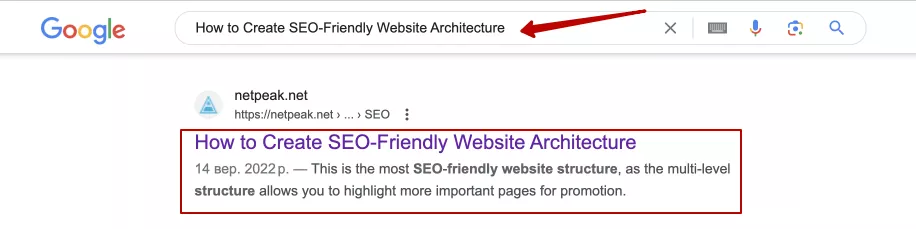
Website indexing is a complex process that allows search engines to efficiently find and display relevant pages in search results. Understanding this process helps both SEO experts and website owners improve visibility and ensure efficient interaction with search engine crawlers.
How to check if a website is indexed
Checking indexing is important because it allows you to make sure that search engines understand your website and deliver your content to users correctly. The following methods can help you find out if your website is indexed properly:
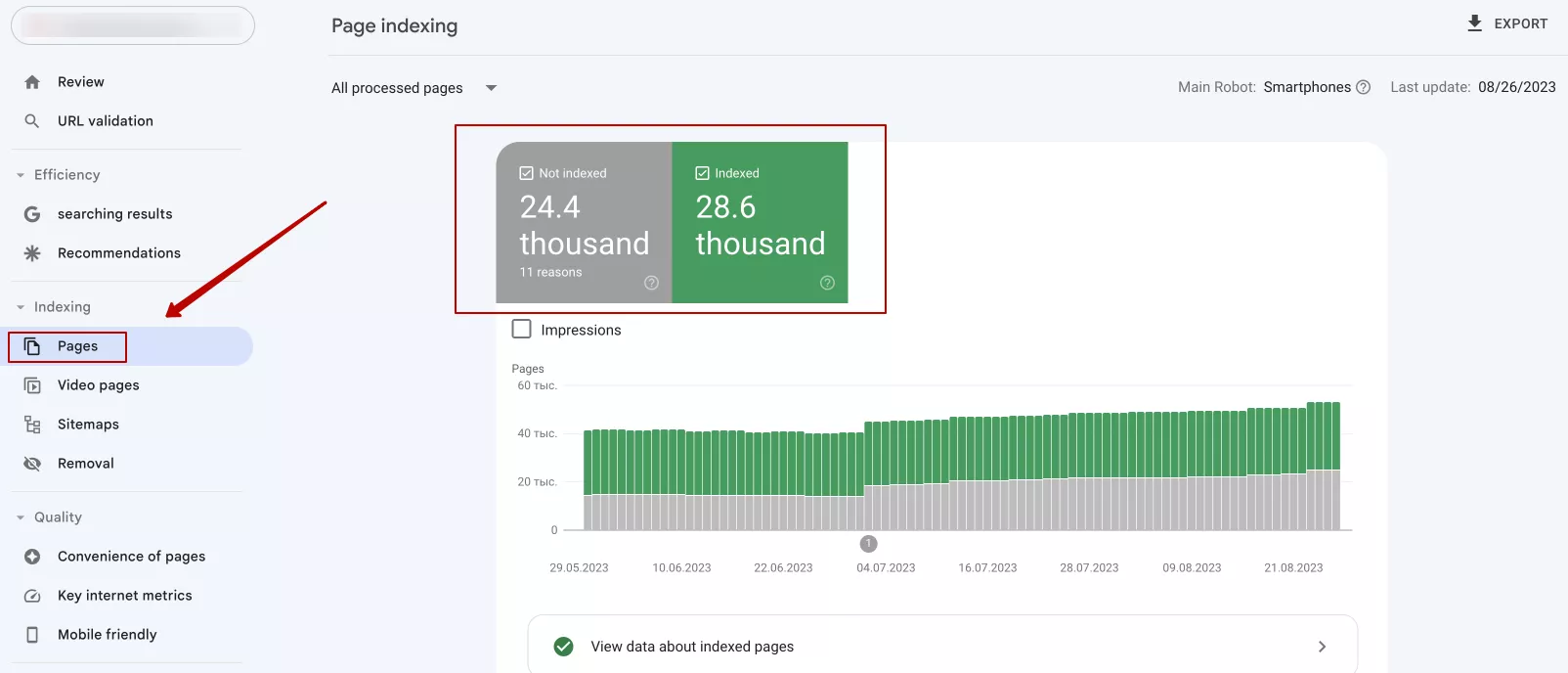
1. Use Google Search Console, which is a free tool provided by Google. It provides information about how Google sees your website, reports on page indexing, error detection, and more. To check indexing in Google Search Console, go to Pages. You can see how many pages are indexed and which pages have problems:
2. Use the site: command in search engines. It allows you to check how many pages of a particular website are indexed in a particular search engine. For example, entering site: netpeak.net in Google will show all the pages indexed from this website:
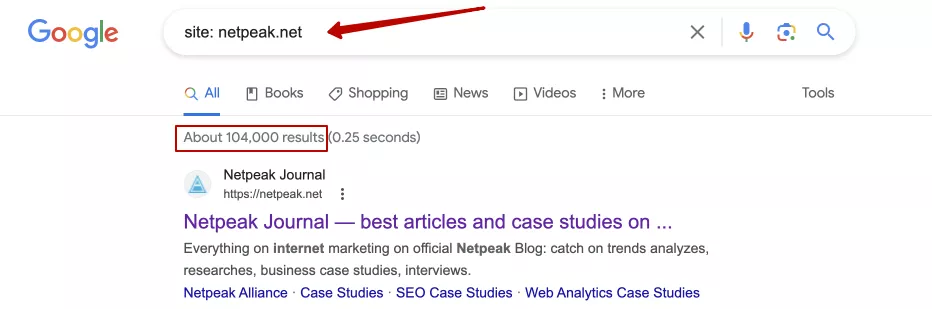
However, this is a rather imprecise way to obtain information about the indexing of a site and its individual pages. At the same time, it is useful because, in combination with other operators, it allows you to find certain pages with attachments or parameters that should be hidden from indexing on your site. This method also allows you to check the indexing of individual pages or competitor websites.
3. There are also various services that evaluate website indexing. For example, Netpeak Checker allows you to find out if a website or pages are in the search results. Other services that help track indexing and identify possible problems are Ahrefs and SEMrush.
What pages should not be indexed?
Proper control over how search engines index your website and its content is an important part of SEO. In certain cases, blocking pages from being indexed may be appropriate and useful. We are talking about the following pages:
- Test or development pages. Such pages are often incomplete, not suitable for public viewing, or may contain errors. By excluding these pages from indexing, you eliminate the possibility of accidentally publishing unfinished content.
- Pages containing confidential information. Privacy is always a priority; if your site contains pages with personal, financial, or other confidential information, you should prevent them from being indexed. This could be a page with user credentials, payment information, etc.
- Duplicate content. If your site has pages with repeated content on other pages, it can cause problems with search engine rankings. Remove duplicate content from the index to ensure better visibility and consistency for the main page.
- Internal administrative pages. These pages manage site content or settings and should not be accessible to the public. By preventing them from being indexed, you can avoid the potential risk of unauthorized access and maintain control over the administrative part of the site.
- Custom purchase or registration pages. If your site contains pages with a shopping cart, registration, checkout, search, comparison, sorting, price filters, and displays of the number of products on the pages, you should exclude them from indexing. They create duplicates.
Understanding the indexing process will help you optimize your website effectively, as it will allow you to exclude unimportant pages from indexing and vice versa.
Effective methods to prevent website indexing
There are four main methods that help manage indexing.
Robots meta tag
A robots meta tag is one of the most common ways to control the indexing of web pages. There are four main rules related to the robots meta tag:
- index — allow the bot to index;
- noindex — prevent indexing;
- follow — allow the bot to follow the links on the page;
- nofollow — ignore the links on the page.
Adding a noindex meta tag to the page code in the <head> block prevents search engines from indexing it. Use the following to add a nofollow tag:
<meta name="robots" content="noindex, follow" />Where noindex is an attribute that prevents the page from being indexed by search engines. It is worth adding the follow attribute, as it allows the robot to follow the links to another page and continue exploring the site.
For example:

Another way to implement this rule is to add
<meta name="robots" content="noindex, nofollow" />Where the nofollow tag instructs the robot not to follow the links to other web pages.
If you replace robots with bing, for example, the instruction will only apply to the Bing search engine. However, if a particular page is to be hidden from indexing, I recommend that you add instructions for all search robots.
The robots meta tag is especially useful to protect individual pages from public access.
Attention! Google Help states: “For the noindex rule to be effective, the page or resource must not be blocked by a robots.txt file, and it has to be otherwise accessible to the crawler. If the page is blocked by a robots.txt file or the crawler can’t access the page, the crawler will never see the noindex rule, and the page can still appear in search results, for example if other pages link to it."
X-Robots-Tag in the server response
The X-Robots-Tag header can be set at the server level or at the individual page level to control search engine indexing. It tells search engines how to process a particular page or resource. This header can contain the same directives as the robots meta tag:
X-Robots-Tag: noindex, nofollowEssentially, it instructs search engines not to index the page (noindex) and not to follow links on it (nofollow). The rule can be set in several variations.
You can set the X-Robots-Tag for a specific page or resource on the server in the server settings. Alternatively, use a configuration file that specifies the HTTP headers to be set for specific requests.
To configure X-Robots-Tag for Apache server, add the following code to the .htaccess file:
Header set X-Robots-Tag "noindex, nofollow"In this way, we set the X-Robots-Tag header for all webpages and prevent them from being indexed and the link from being clicked.
After making changes to Apache .htaccess, you need to restart the web server for the changes to take effect.
To configure X-Robots-Tag for Nginx server, use an additional nginx module called add_header. This module allows you to add HTTP headers to server responses.
- Open your website’s configuration file.
- Locate the server block that corresponds to your website and add or edit the add_header line in that block to add the X-Robots-Tag header.
For example:
add_header X-Robots-Tag "noindex, nofollow"Just like the previous examples, the X-Robots-Tag header is set to noindex, nofollow in this example. This prohibits indexing and following other links. After making changes to the configuration file, restart the Nginx web server for the changes to take effect.
After the X-Robots-Tag is installed, search engines will follow the specified directives for indexing and following links on the specified page or resource.
HTTP 403 (Forbidden)
The HTTP 403 (Forbidden) message indicates that the request to the server was correct, but the server refused to process it due to access restrictions. This code can be used to block a page from being indexed by search engines, and here’s how:
1. Create a page to display the access denied message. This is the page that users will be redirected to if they can’t access the initial page. For example, it can be named forbidden.html and have the content you want to display to users when they try to access the forbidden page. This redirect page should be designed appropriately. If you place a link to the main page, for example, the user will not leave the site entirely but will simply go to that webpage.
You can add information such as “We’re sorry, but you don’t have permission to access this page. Please contact your site administrator to request access.” It’s worth noting that 403 codes can be used to block not only specific pages but also the entire website from being indexed. This can be useful, for example, if you need to restrict access to users from certain regions or countries.

2. Use the HTTP 403 code and configure robots.txt. You need to configure your server to send a 403 HTTP code when you try to access a forbidden page, and at the same time, tell search engines in the robots.txt file not to crawl this page:
- Configure your web server (e.g., via the “.htaccess” file for Apache) to send an HTTP 403 for the forbidden page.
<Files “forbidden page.html">
Order Allow,Deny
Deny from all
</Files>where forbidden page.html is the path to the forbidden page.
- In the robots.txt file, add the following line for the page you want to block from crawling.
User-agent: *
Disallow: /forbidden page.htmlThis entry tells search engines that the page /forbidden page.html should be ignored and not crawled.
After completing these steps, when users try to access the forbidden page, the server will send them a 403 error code and redirect them to the created forbidden.html page. Search engines will also ignore this page because of the settings in the robots.txt file and will not index it in their database.
Attention! Google Help recommends that you do not overuse the 403 code to control indexing. This is because such a page may be removed from Google search in the future. When a robot visits a page with a 403 code, it sees an error on the user side, so it must return later. After repeated visits and receiving the same response code, these pages may be removed from Google search.
Protecting pages with a password
You can use password protection if you need to restrict access to pages for search engines and users. This means that the user must enter the correct username and password to access the site or specific page.
This method is particularly useful in the following cases:
- Administrative interface pages. If you have an administrative panel or other part of the site that only a limited number of users (e.g., administrators) should have access to, HTTP authentication helps ensure that only those users have access.
- Test or development sites and pages. If you are developing or testing a website, you can use HTTP authentication.
- Specialized services or resources. Some websites provide specialized services or resources that only certain groups of users should have access to. HTTP authentication will ensure limited access.
- Protection from public indexing. If you need to protect a page or directory from being indexed by search engines, HTTP authentication can be used as an additional layer of security after disallowing crawls in the robots.txt file.
This method ensures a high level of security and privacy for users, and it ensures that only those with appropriate credentials have access.
Read more on our blog:
- What Is the EEAT Algorithm, and How It Affects Search Results
- All About Using the 410 Gone Error
- Using AI for SEO: How to Save Time and Money
Conclusions
Indexing is an integral part of an SEO strategy. It helps ensure your website is properly visible and relevant to your target audience. Accordingly, it is important to check indexing to ensure search engines correctly interpret the content delivered to users.
However, you may want to block some pages from indexing, such as test pages or confidential content. The following methods can be used for this purpose:
- Robots meta tag
- X-Robots tag
- HTTP 403 (Forbidden)
- Password protection
They help to effectively control the process of website indexing and protect confidential information.

 4
4
 3
3
 0
0
Related Articles
How to Set Up Consent Mode in GA4 on Your Website with Google Tag Manager
Let's explore how to properly integrate consent mode in GA4, configure it for effective data collection, and at the same time comply with GDPR and other legal regulations
Display Advertising Effectiveness Analysis: A Comprehensive Approach to Measuring Its Impact
In this article, I will explain why you shouldn’t underestimate display advertising and how to analyze its impact using Google Analytics 4
Generative Engine Optimization: What Businesses Get From Ranking in SearchGPT
Companies that master SearchGPT SEO and generative engine optimization will capture high-intent traffic from users seeking direct, authoritative answers