Как быстро найти ошибки SEO-оптимизации с помощью Netpeak Spider
Анализ ошибок SEO-оптимизации — это стандартная задача любого SEO-специалиста на протяжении всего времени работы с проектами. Чтобы сэкономить время на проверках, используя при этом минимум сервисов и ресурсов, можно быстро найти основные ошибки SEO-оптимизации с помощью Netpeak Spider. Детальнее об отчетах и настройках инструмента рассказываю на примере из своей работы.
Сканирование
Настройки следует выбирать в зависимости от целей сканирования. Например, если хотите проанализировать весь сайт или один раздел, все поддомены, а также учесть внешние ссылки вы можете дополнительно выбрать настройки 1, 2 или 3 соответственно.
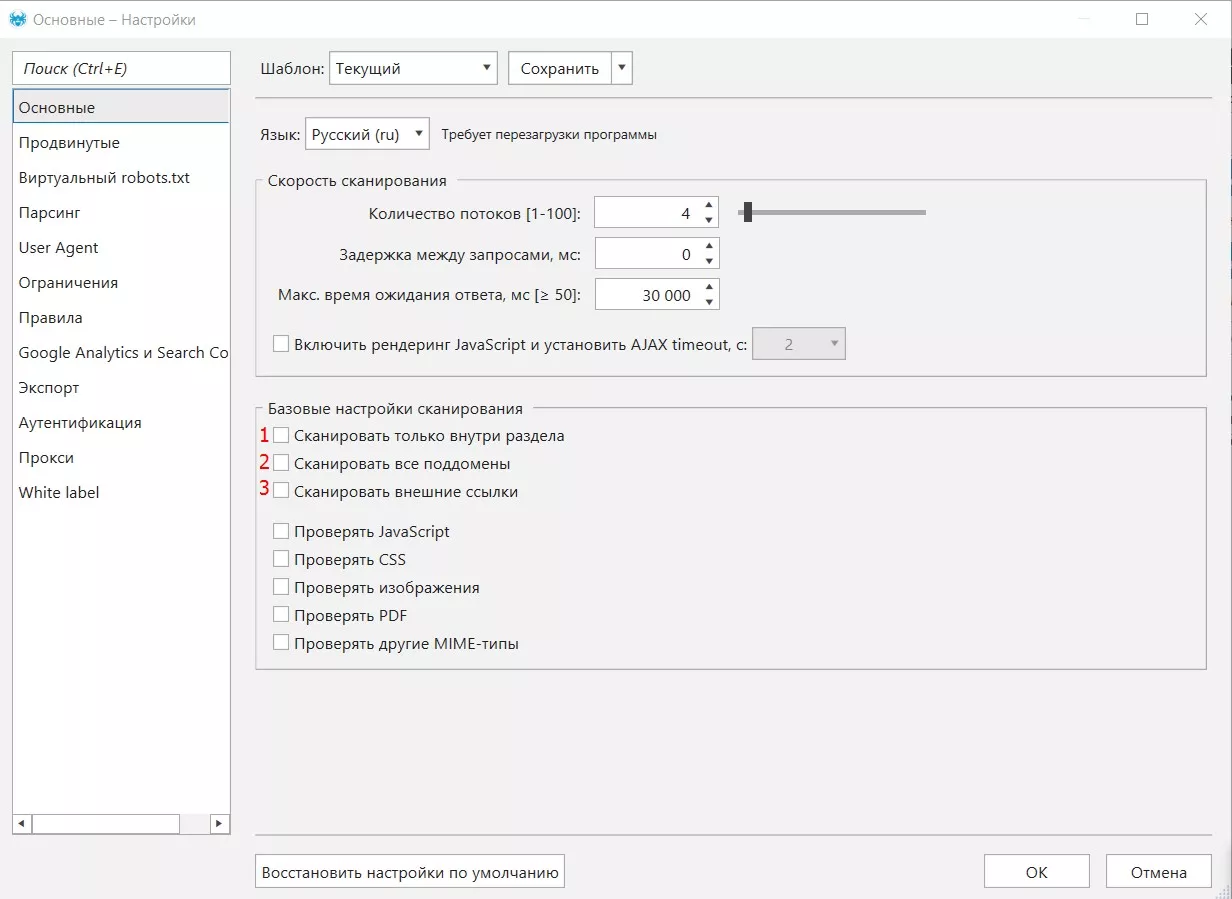
Также, по необходимости можно зайти в раздел «Продвинутые» и добавить настройки по учету инструкций индексации (если вы уверены в корректной работе таких инструкций).
Какую информацию мы можем получить для анализа ошибок на сайте с помощью Netpeak Spider:
- ошибки XML карты сайта;
- настройка canonical;
- страницы с кодом ответа 4**;
- динамические URL;
- настройка 301 редиректов;
- проверить, какие страницы закрыты или какие необходимо закрыть в robots.txt;
- скорость загрузки страниц сайта;
- дубли мета-данных title, description.
Все эти данные (и даже больше) предоставляет Netpeak Spider.
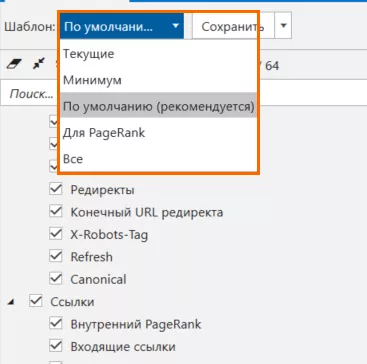
Теперь переходим к параметрам анализа — можем выбрать на рабочей панели Netpeak Spider шаблон параметров «по умолчанию» (рекомендуемый разработчиками) со всеми основными параметрами для анализа и немного его подкорректировать.
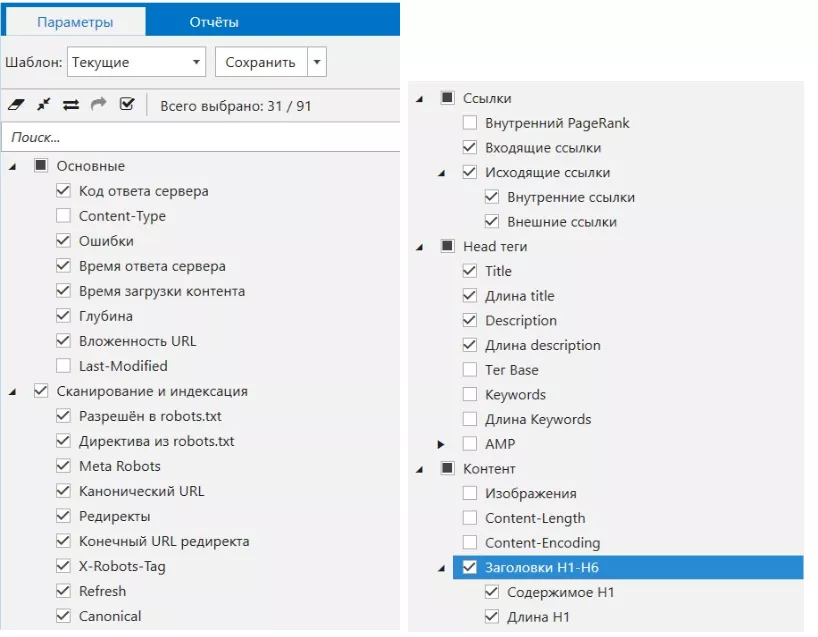
Правлю относительно необходимых данных, чтобы сканировать быстрее и получать в отчетах информацию в удобном виде. Например так:
Ошибки XML-карты сайта
Почему стоит проверять ошибки XML-карты? Этот файл — помощник в индексации важных страниц сайта. Если в нем ошибки, появятся дубли страниц и на их индексацию впустую пойдет краулинговый бюджет.
Для того, чтобы проверить ошибки карты сайта, выбираем меню «Инструменты» — «Валидатор XML Sitemap». Затем вставляем ссылку на соответствующую карту сайта и нажимаем кнопку «Старт».
Появится отчет такого вида:
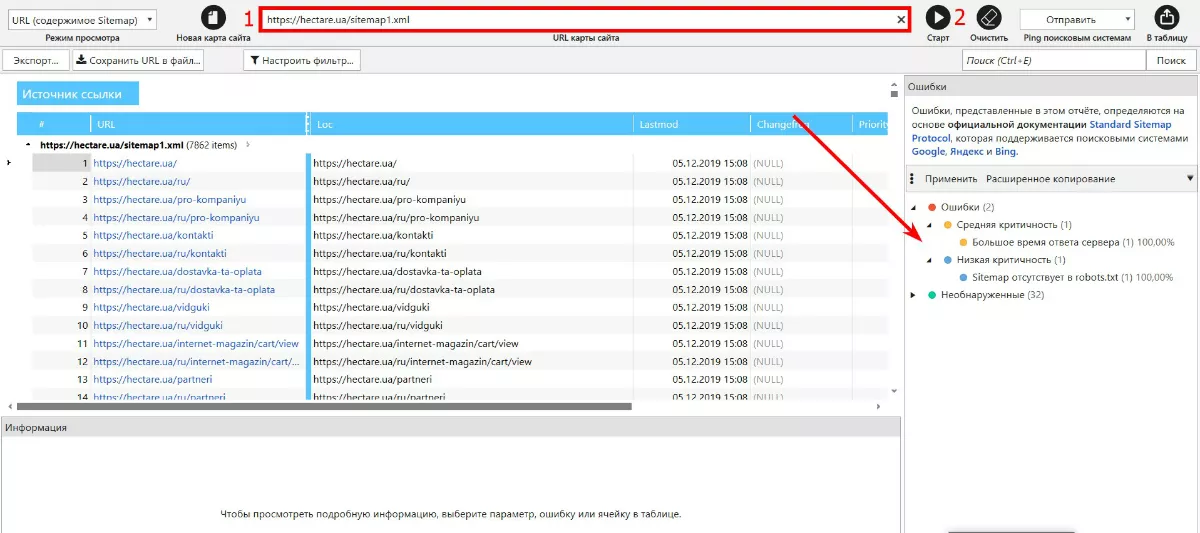
В моем примере критических ошибок нет, есть ошибка относительно скорости и указание на то, что ссылка на Sitemap отсутствует в robots.txt. Это легко исправить.
В случае, если ошибок нет вообще, можно сразу отправить пинг поисковым системам и уведомить, что надо прокраулить нашу карту.
Какие критические ошибки может показать нам валидатор (согласно официальной документации Standart Sitemap Protocol, всего их 34):
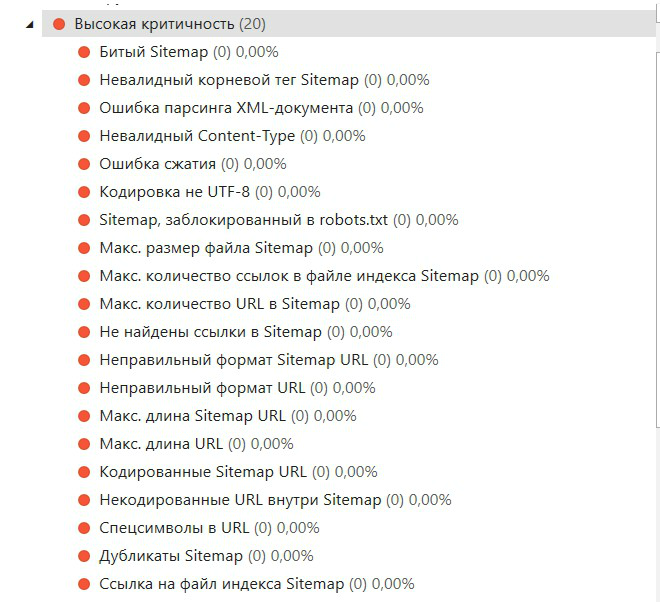
Из вышеперечисленных ошибок высокой критичности чаще встречаются ошибки, связанные с кодировкой не UTF-8, блокировкой сайта в robots.txt, неправильным форматом URL и размером файла. 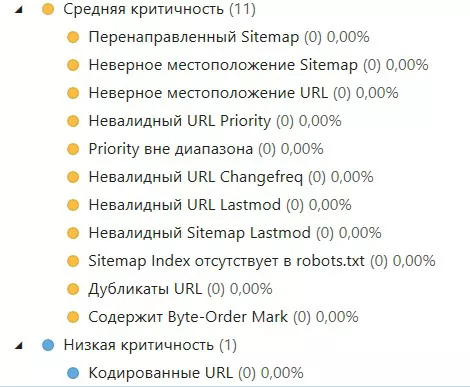
Средней критичности — ошибка с наличием дубликатов URL и скоростью загрузки (как в примере). Но это не означает что остальные ошибки могут не появится в вашем анализе.
Проверка canonical на страницах сайта
Основная и главная функция rel="canonical" — возможность избежать появления дублей контента на сайте и копирования его на сторонние ресурсы.
Напомним, мы настраиваем каноникал на страницах:
- фильтрации/сортировки — в таком случае атрибут rel="canonical" должен вести на эту же страницу без атрибутов фильтрации в URL;
-
пагинации — в данном случае на всех страницах пагинации каноническая ссылка может быть указана на страницу «page all», если этой страницы нет, то каноникал настраиваем на сами страницы пагинации или на первую страницу пагинации; - страницы печати — в данном случае основная версия страницы является канонической;
- с UTM-метками — каноникал на страницы без UTM меток.
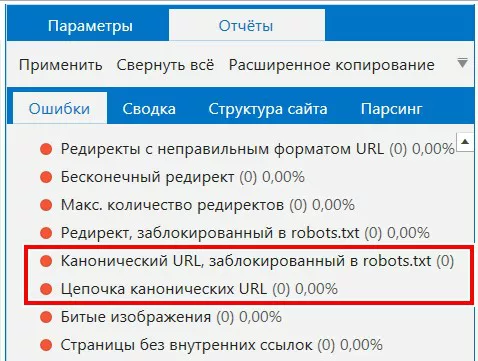
Какие ошибки могут возникать при добавлении атрибута rel="canonical"?
- На странице указано больше, чем одна каноническая ссылка.
- Каноническая страница закрыта от индексации через мета тег robots или noindex.
- Цепочка канонических URL, когда на странице URL 1 тег rel="canonical" ссылается на URL 2, который в свою очередь содержит такой же канонический тег на URL 3. Данный отчет можно увидеть через панель «Экспорт» — «Отчёты по ошибкам» — «Цепочки канонических URL».
Чтобы исправить, каноникал для страниц сайта необходимо настраивать на адреса страниц, которые в свою очередь не ссылаются в этом теге или заголовке на другие URL.
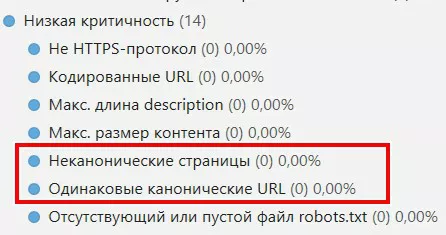
- Одинаковые канонические URL (необходимо убедится, что одинаковый каноникал настроен для похожих по содержанию и контенту страниц).
Чтобы проверить канонические ссылки, следует выбрать соответствующий пункт на боковой панели:
Для более полного отчета и глубинной работы с каноническими ссылками, также можно открыть отчет через меню «База данных» (пункт «canonical»).
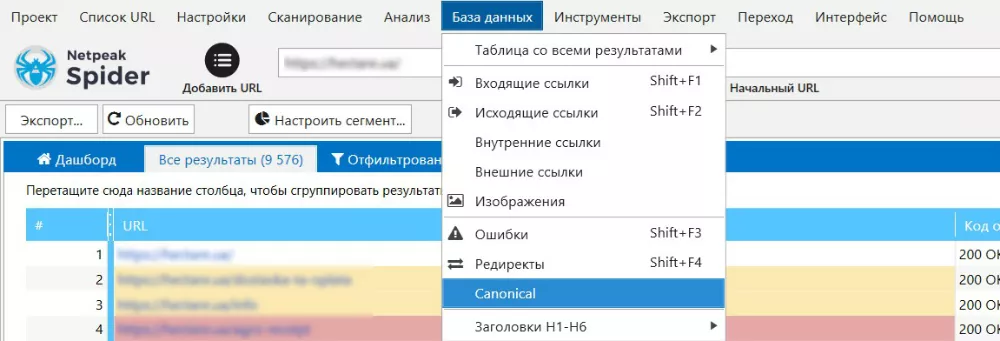
Далее откроется подробный отчет с данными кода ответа текущей и канонической ссылки, а также информацией о закрытии целевого URL от индексации:
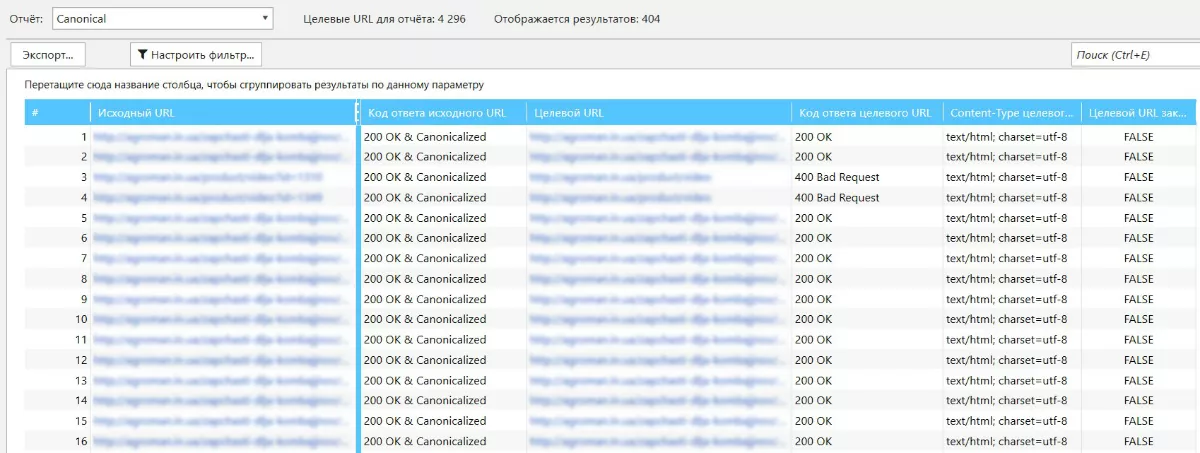
Так мы получаем максимально доступный, понятный отчет который можно использовать для постановки технического задания на программистов.
Страницы с кодом ответа 404
Пользователи не любят такие страницы и могут быстро уйти с сайта. В лучшем случае, вернуться на предыдущую страницу или главную. Когда человек покидает сайт, это негативно влияет на поведенческие факторы, которые учитываются при ранжировании сайта.
Что делать, если на сайте найдены страницы с 404 кодом ответа сервера?
- Проверяем, что это за страницы и есть ли на них входящие ссылки, через которые может зайти пользователь или поисковой робот.
- Если это удаленные страницы сайта, настроить код ответа 410, чтобы убрать страницы из индекса.
- Если был переезд или изменены URL страниц, исправить переадресацию с помощью создания карты редиректов (используйте 301 редирект со страниц с ошибками на правильные страницы).
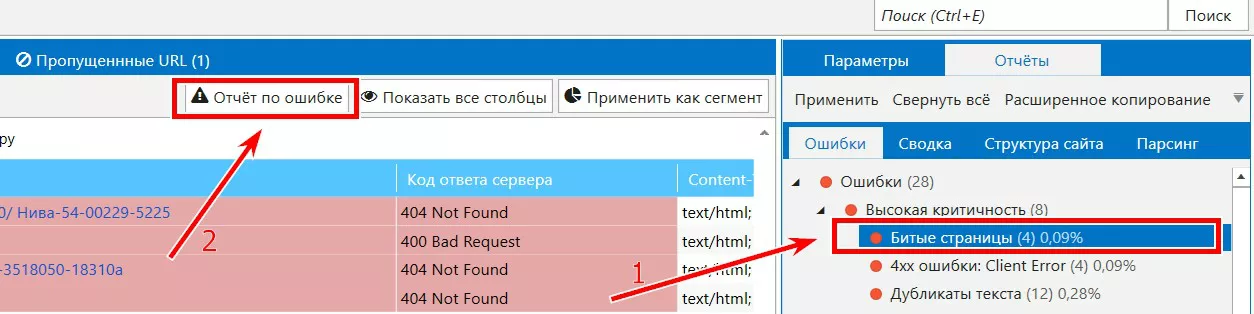
«Проблемные» страницы можем найти в отчетах раздела «Битые страницы», «4хх ошибки» и «5хх ошибки» соответственно.
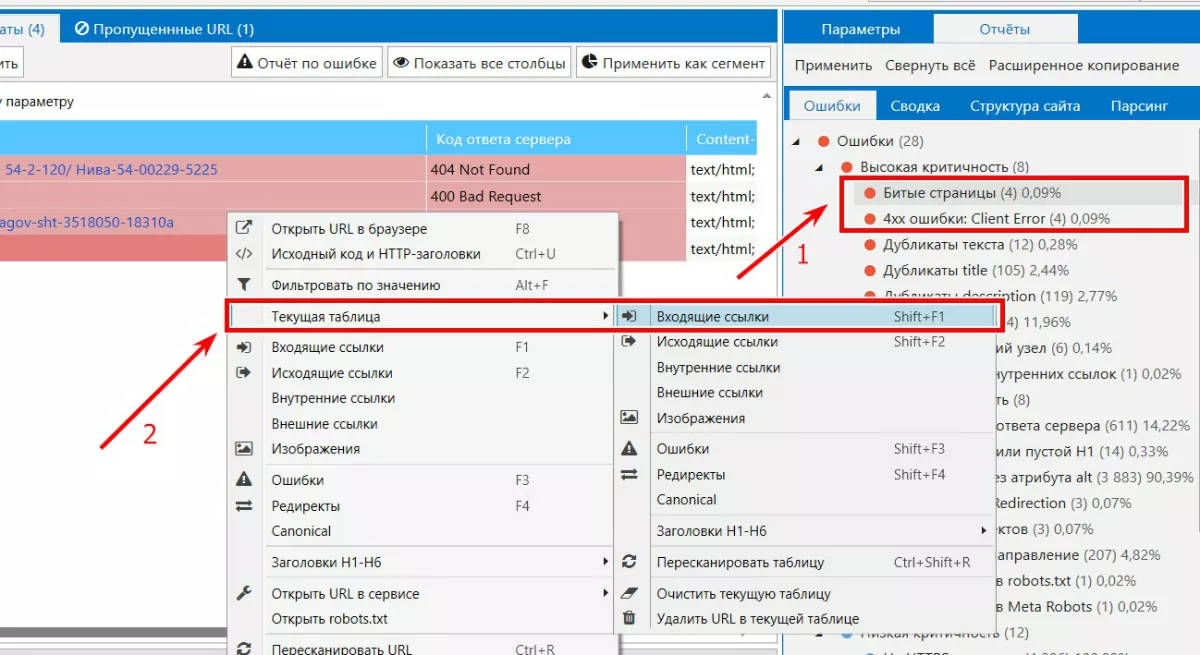
Следующий шаг после просмотра таких отчетов — узнать входящие ссылки на данные страницы, чтобы определить, нужно ли настраивать редирект, и возможно ли составить корректное и полное техническое задание для программиста.
Или так:
Страницы, закрытые от индексации
При ежемесячном анализе, не лишним будет периодически проверять, какие страницы сайта скрыты от индексации с помощью robots.txt, meta-robots и X-robots-tag. Вдруг важные категории и страницы сайта случайно скрыли или наоборот ненужные страницы стали доступны для индекса.
Если говорить про страницы, которые точно не должны попадать в индекс, то это:
- корзина (для интернет-магазинов, доставок и так далее);
- личный кабинет;
- сортировка;
- страницы пересечения фильтров (в зависимости от тематики сайта).
В результате сканирования, Spider предоставит список страниц, который можно отфильтровать по значениям и принять необходимые меры (то есть открыть или закрыть определенные страницы сайта).
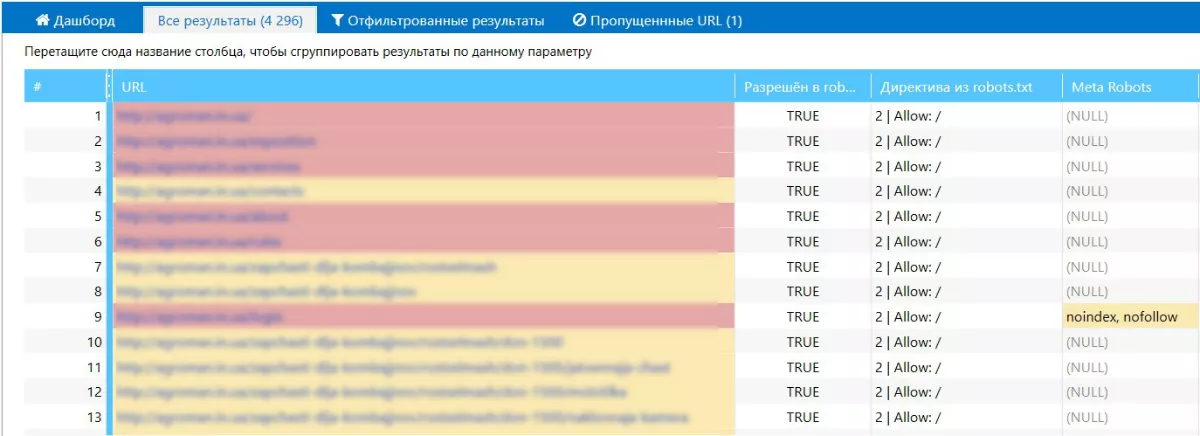
А также с помощью отчетов:
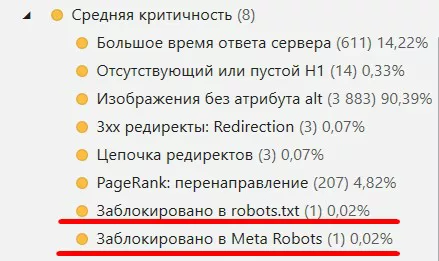
Теперь остается составить техническое задание для программиста и исправить все ошибки.
Проверка 301 редиректов
Существует много причин, по которым на сайте необходимо использовать 301 редирект. Например:
- склейка домена;
- избавление от дублей главной страницы и слеша в конце URL;
- переезд на новый домен;
- смена структуры URL на сайте;
- частные случаи при удалении и исправлении битых страниц на сайте.
При настройке 301 редиректов, возникают подобные ошибки как и с добавлением rel= “canonical” на сайт:
- страницы не должны вести на битые или закрытые от индексации страницы;
- нерелевантные страницы редиректа;
- многошаговость редиректа (когда редирект ведет на страницу с редиректом).
Далее открывается отчет с данными о коде ответа на страницах, уровень вложенности и закрытые от индексации страницы:
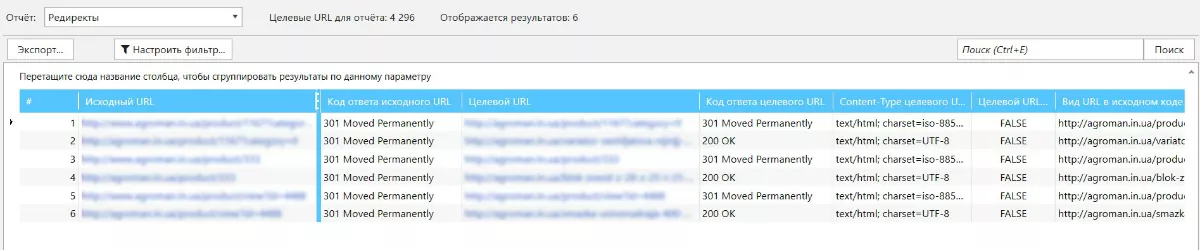
Также для дальнейшей работы можно сразу сделать выгрузку специального отчета в готовый документ. Он более полный и содержит ссылку на страницу с редиректом.
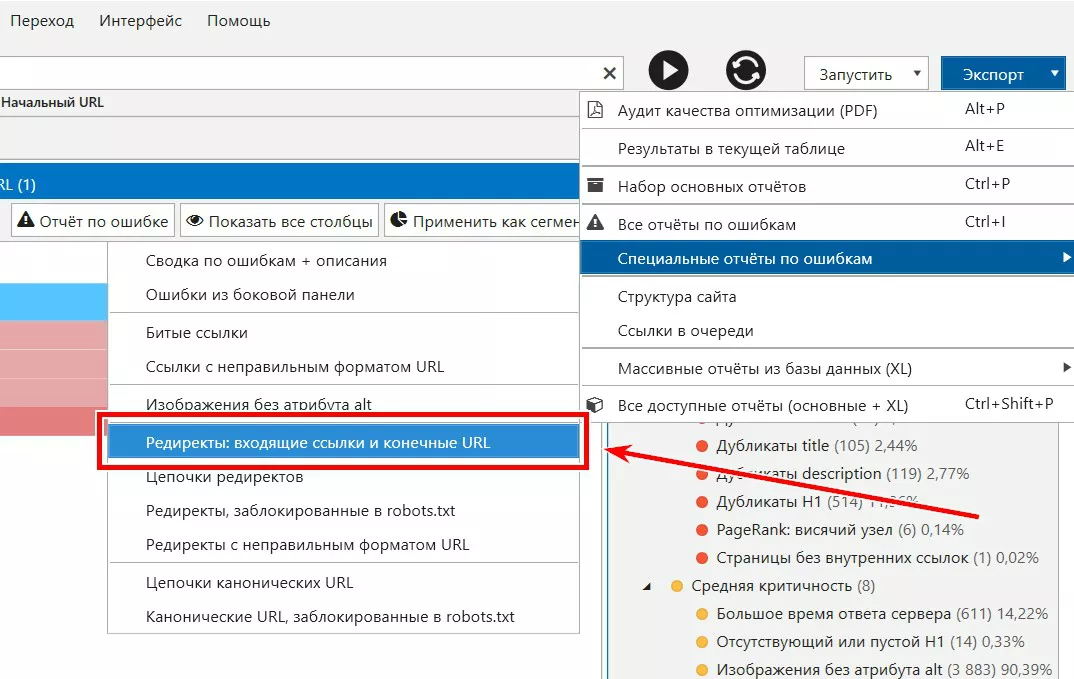
После представленных данных можно также составить корректную карту редиректов и сделать реализацию, которая бы уменьшила количество внутренних 301, 302 редиректов на сайте.
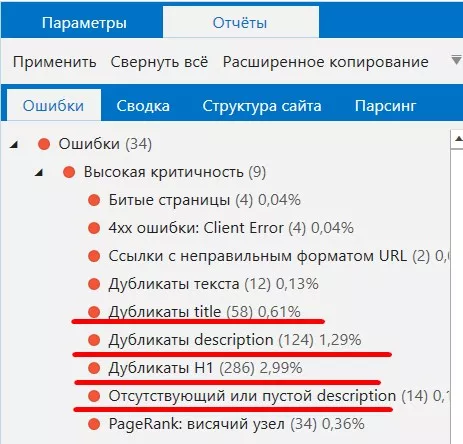
Дубли мета-данных title, description
Мета-данные title, description в целом относятся к контенту сайта, и появление таких дублей может негативно отражаться на SEO-оптимизации сайта.
Если на сайте дублируются title или description, поисковый робот может предположить, что такие страницы сайта — дубли. В дальнейшем из-за этого можно потерять позиции в выдаче. Дело в том, что робот не сможет определить, какая страница приоритетней для показа пользователям. Отсутствующие и незаполненные поля, блоки (везде, где нужна информация) также не дают полной картины пользователю, какая именно информация содержится на странице.
В Spider существуют специальные отчеты для этого.
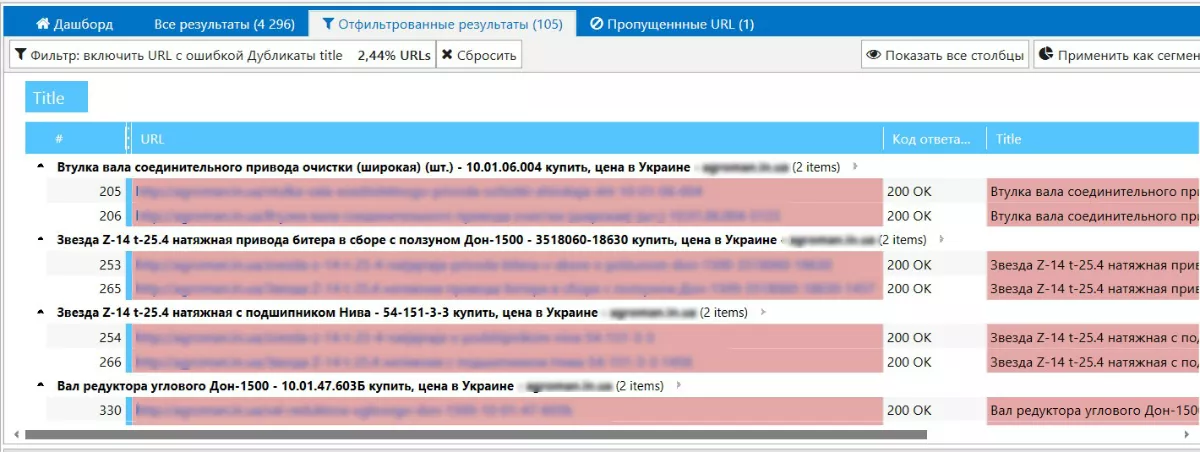
Для решения ошибки существует два варианта:
- Для похожих страниц категорий, фильтров, можно прописать шаблон генерации мета-тегов.
- Вероятнее всего будут и страницы, для которых шаблон может не сработать — здесь не обойтись без ручных мета-данных.
Данные в Spider подаются в виде таблицы с удобным представлением. Ее можно экспортировать и внести необходимые изменения, на основе этой таблицы удобно составить техническое задание для исправления ошибки.
С помощью инструмента также можно проверить, как внедрили шаблоны формирования мета-данных. Каким образом? Просканировав раздел или категорию, для которого применялись шаблоны.
Скорость загрузки страниц сайта
Один из важных показатель качества и оптимизации сайта — скорость загрузки. Сюда входит время ответа сервера, построения DOM и так далее.
Важно: чем сайт быстрее, тем лучше. Если данный показатель больше секунды, вы уже рискуете потерять позиции, а посетители скорее всего покинут сайт, не дождавшись загрузки.
Проверку скорости загрузки полезно осуществлять как в начале работы с проектом, так и ежемесячно — чтобы контролировать ситуацию и принимать своевременные меры, чтобы
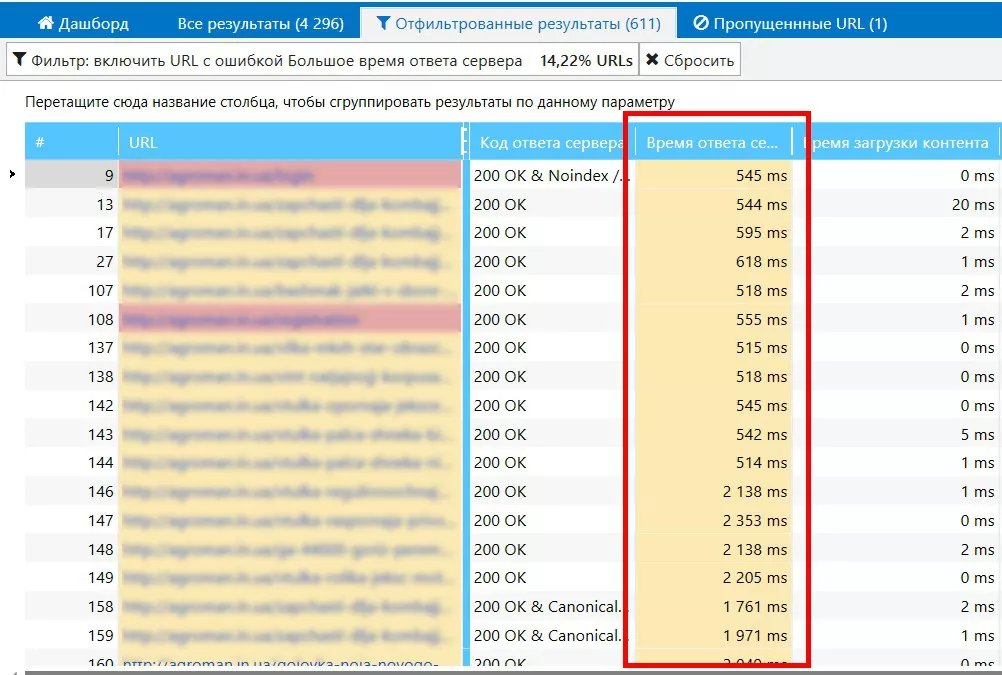
Напомним, рекомендуемое оптимальное значение времени ответа сервера — 200 мс.
Данные из Netpeak Spider представлены в отчете «Большое время ответа сервера» в виде списка. Для удобства в настройках сканирования на вкладке «Ограничения» можно задать своё значение для времени ответа сервера, которое будет считаться ошибкой. В Netpeak Spider данное значение по умолчанию равно 500 мс.
Динамические URL
Вопрос о негативном или благоприятном влиянии динамических страниц на сайте до сих пор открыт. Часть SEO-специалистов, чтобы не дублировать контент, и не терять CTR страниц, предпочитают псевдостатистические URL. Другие не видят проблем в таких страницах и ничего с этим не делает.
Основная загвоздка с динамическими URL — они генерируются автоматически и вероятность дублирования контента становится выше. Поэтому так актуально своевременно обнаружить и проанализировать такие страницы.
Основное отличие динамических URL — наличие в нем знаков «?», «&» или «=». Соответственно, мы можем отфильтровать и проанализировать данный тип страниц. Выбираем «Настроить сегмент», далее добавляем соответствующие условия.
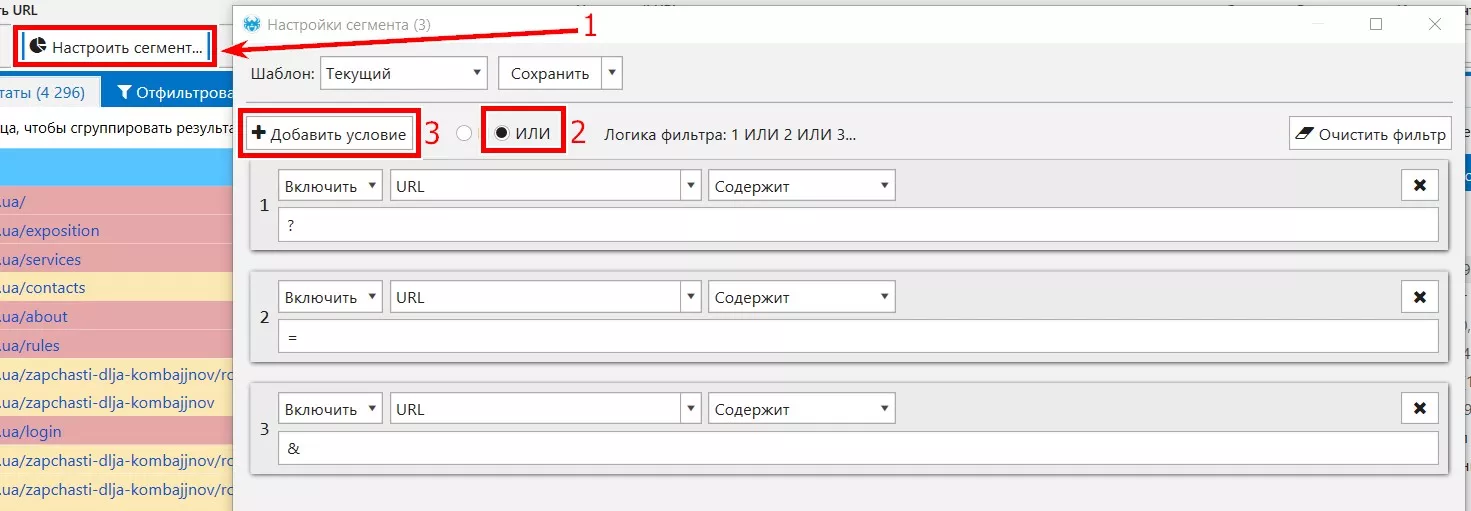
Или с помощью регулярного выражения:
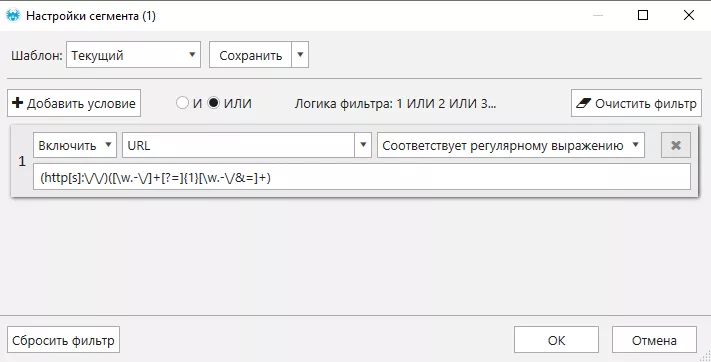
После этого получаем список динамических URL и можем их проанализировать, нам важно:
- если это страницы пагинации — проверить, чтобы они были канонические, с настроенным корректно каноникал;
- если это не страницы пагинации, необходимо проверить данные страницы на дубль контента. Если его нет, настроить каноникал на эти же страницы без get-параметра.
Выводы
Анализ сайта будь-то на первом этапе работы с проектом, или периодические проверки внедрения рекомендаций — важный пункт SEO-оптимизации. Без подходящего инструмента комплексного анализа на проведение проверки будет уходить большое количество времени.
Netpeak Spider — многофункциональный инструмент SEO-специалиста на всех этапах работы. Кроме полного анализа можно также сохранить время и ресурсы для проверки типичных задач реализованных клиентом на сайте. А сохраненное время SEO-специалист может использовать на дополнительные креативные задачи и решения.

 20
20
 6
6
 8
8
Свежее
Как учитывать сезонность при разработке SEO-стратегии
Учет сезонных тенденций позволяет заранее подготовиться и «поймать волну» в нужные месяцы. Как именно это сделать, рассказываем в материале
Как вывести приложение из «мертвой точки» и увеличить количество органических просмотров на 142 730% в App Store
Три рынка, локальные поисковые привычки и системная работа с метаданными и видимостью в App Store
Как опубликовать приложение в Apple App Store — полное руководство
Как выпустить приложение и не поддаться панике. Пошагово расскажу, как подготовиться к релизу