Как новостная лента Facebook предсказывает то, что вы хотите увидеть?
Алгоритм новостной ленты Facebook окружает множество мифов и догадок. До недавнего времени об особенностях ее работы знали немногие. И вот теперь компания решила показать, как устроена персонализация контента. Подробности — читайте дальше в посте.
Учитываются не только «лайки» и «шейры»
Алгоритм Facebook — чрезвычайно сложная и разветвленная система ранжирования на основе машинного обучения (machine learning, ML). Этой системе нужно показывать релевантный и полезный контент всякий раз, когда пользователь заходит на сайт или в приложение Facebook. А значит, анализировать огромный объем контента.
Речь идет о триллионах публикаций и по тысячам сигналов ранжирования нужно понять, что именно отдельно взятый пользователь хотел бы увидеть. Когда кто-то заходит в Facebook, весь этот процесс происходит в фоновом режиме, а новостная лента загружается за нескольких секунд.
К тому же, кроме «лайков», шеров, добавленных в сохраненное и другого, нужно учитывать все новые и новые факторы, такие как кликбейт и фейк-ньюз, для чего Facebook приходится находить другие решения.
Новостная лента — это не один алгоритм, а многоуровневая система. В ее основе несколько моделей машинного обучения для определения наиболее релевантного контента. Определяя, что заинтересует пользователя с большей вероятностью, система отсеивает тысячи постов, и в итоге пул возможных публикаций сужается до нескольких сотен. Они и появляются в новостной ленте.
Что интересно Хуану?
Чтобы понять, как это все происходит на практике, рассмотрим конкретный пример.
Допустим, день назад некий пользователь, назовем его Хуаном, заходил в Facebook. За это время:
- его друг Вей выложил фото своего кокер-спаниеля;
- подруга Саанви разместила видео, снятое во время утренней пробежки;
- одна из страниц, на которые Хуан подписан, опубликовала статью о том, как лучше всего рассмотреть Млечный путь ночью;
- а в группе, посвященной кулинарии, появилось четыре рецепта дрожжевого теста.
Весь этот контент, скорее всего, заинтересует Хуана, потому что он подписан на соответствующие страницы и пользователей.
Чтобы определить, какой контент в новостной ленте Хуана должен быть выше, нужно выяснить, что для него важнее. В математических терминах, необходимо определить критерий выбора для Хуана и провести однокритериальную оптимизацию.
Чтобы понять, понравится ли конкретный пост Хуану, система анализирует данные о публикациях: дата или отмеченные на фото пользователи, «лайки» и прочее.
Но «лайки» не единственный способ выразить свои предпочтения. Люди ежедневно делятся статьями, просматривают видео на страницах селебрити или оставляют комментарии к постам друзей. С точки зрения математики задача усложняется тем, что нужна оптимизация по нескольким критериям, каждый из которых помогает сформировать список релевантного контента для ленты.
Множество ML-моделей выдают уйму прогнозов для Хуана: вероятность взаимодействия с фото Вея, видео Саанви, статьей о Млечном пути или рецептах теста. Каждая из моделей предлагает свой список контента для пользователя. Иногда бывают расхождения.
Например, может быть выше вероятность того, что Хуану понравится видеоролик о пробежке Саанви, а не статья о Млечном пути. Но при этом он с большей вероятностью прокомментирует статью, а не видео. Поэтому нужно объединить все предположения в общий рейтинг, оптимизированный для конечной цели: показать пользователю содержательный и релевантный контент.
При формировании ленты учитывается мнение аудитории — Facebook регулярно проводит опросы. Пользователей спрашивают, насколько ценным они считают взаимодействие с контентом друзей, стоят ли публикации потраченного времени.
Алгоритм ранжирования
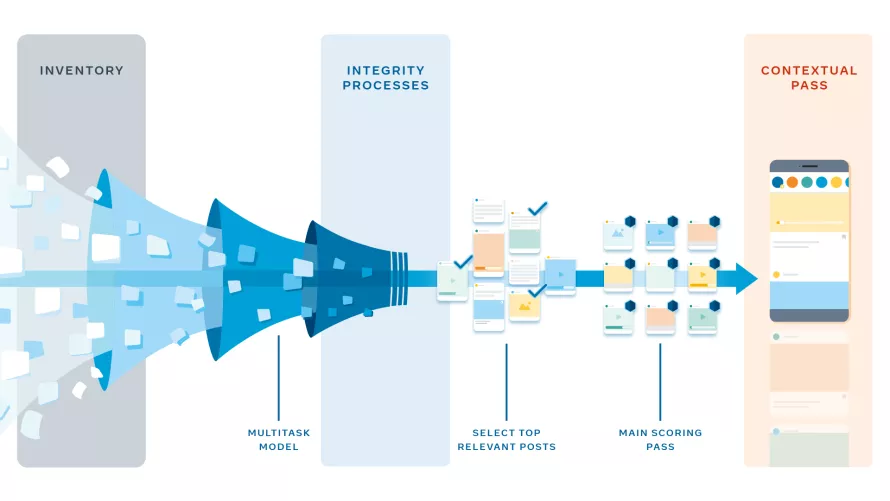
Нужен эффективный механизм, чтобы ежедневно в реальном времени сортировать больше тысячи постов для каждого из 2 миллиардов пользователей. Такая задача выполняется в несколько этапов, стратегически разработанных так, чтобы делать все быстро и уменьшить объем требуемых вычислительных ресурсов.
Вначале система собирает все возможные публикации для ленты Хуана: фото кокер-спаниеля, видео пробежки и прочее. Список потенциального контента включает в себя любые посты, которыми с Хуаном поделились друзья, группы и страницы, начиная с того момента, как он в последний раз открывал приложение или сайт Facebook.
Но как быть с публикациями, которые размещены до предыдущего посещения соцсети и которые Хуан не видел? Такие посты, если они соответствуют интересам Хуана, могут появиться в текущей ленте. Логика формирования ленты также учитывает действия друзей. То есть посты, которые Хуан уже видел, но спровоцировавшие в дальнейшем активное обсуждение, тоже могут оказаться в ленте.
Затем система оценивает каждый пост по ряду критериев:
- тип контента;
- сходство с другими постами;
- соответствие тому, с чем Хуан обычно взаимодействует.
Чтобы все это рассчитать для двух миллиардов человек в реальном времени, ML-модели параллельно запускаются на нескольких машинах — предикторах.
Но прежде чем объединить все прогнозы в единый рейтинг, применяются дополнительные правила. Система ожидает первых прогнозов, а затем сужает список возможных постов. Делается это в несколько подходов, чтобы сэкономить вычислительные ресурсы.
- Вначале соцсеть применяет к каждому посту определенные интегральные процессы, чтобы определить, нужны ли методы поиска последовательности и какие именно.
- На следующем этапе упрощенная модель сужает список примерно до 500 наиболее релевантных постов для Хуана. Ранжирование меньшего количества постов позволяет использовать более мощные модели нейросетей в дальнейшем.
- Затем идет основной этап подсчета рейтинга, на котором происходит большая часть персонализации. Для каждого поста рассчитывается индивидуальный рейтинг. И каждый из 500 постов получает свое место в этом списке.
- Довершает все подсчеты контекстный этап, на котором система учитывает такие характеристики, как разнообразие типов контента. Поэтому в ленте условного Хуана видеоролики не идут один за другим.
Все эти сложные вычисления происходят за время, пока вы открываете приложение Facebook. То есть за несколько секунд люди получают готовую ленту, которую можно с интересом просматривать.
Выводы
Алгоритм новостной ленты Facebook — многоуровневая и разветвленная система ранжирования на основе машинного обучения.
Система работает в несколько этапов:
- Собирает все возможные публикации для ленты пользователя (с учетом действий его друзей и подписок).
- На основе собственных прогнозов сужает список примерно до 500 наиболее релевантных постов.
- Затем максимально персонализирует этот список. То есть размещает 500 постов в ленте согласно рейтингу, присваивая «очки интересности» каждой из публикаций на основе предыдущего опыта пользователя (что он «лайкал», какими публикациями делился и так далее)
- Добавляет элемент разнообразия, чтобы однотипные посты не шли друг за другом.
Все это происходит за считанные секунды, пока загружается лента новостей в Facebook. Соцсетью пользуются 2 миллиарда человек по всему миру, то есть речь идет о ранжировании триллионов постов каждый день.
Спасибо за помощь в подготовке перевода статьи партнерам Netpeak Сluster — Центру международных экзаменов по английскому языку Grade.ua и Cambridge.ua.

 10
10
 4
4
 0
0
Свежее
От «бизнеса по залету» до экосистемы из трех десятков компаний: 20 лет Netpeak
За 20 лет Netpeak стала уверенным игроком на международном рынке, в частности в Европе, на Ближнем Востоке, в Центральной Азии и в Америке, с 600 сотрудниками и офисами в Украине, Болгарии, Казахстане и США
7 ошибок в Google Ads, которые влияют на результаты рекламной кампании
В этой статье разберу типичные ошибки, с которыми часто приходится сталкиваться: пять базовых и две неочевидные. Для каждой покажу, как выявить проблему, исправить её и отследить, какое влияние она оказывает на рекламные кампании
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами