Кейс: учим поисковый движок распознавать грамматические ошибки
Когда нетпиковец сталкивается с задачей, требующей временных затрат (например, создать проект Звезды смерти или построить компактный аппарат холодного ядерного синтеза), он в первую очередь думает, как автоматизировать эту работу. Результаты таких размышлений мы собираем на cпециальной странице нашего сайта. Сегодня мы расскажем о том, как в недрах агентства Netpeak рождается новый полезный сервис.
Давным-давно, в далекой-далекой галактике мы решили изменить поисковый движок сайта клиента для повышения видимости страниц в обычном поиске.
Задача
Поисковый движок клиентского проекта, с которым нам пришлось работать, создавал отдельную страницу под каждый запрос. Так как запросы бывают с опечатками, то таких страниц накопилась целая гора — как правильных, так и с
Нашей задачей было сделать так, чтобы все варианты запросов — как правильные, так и с ошибками — вели на одну страницу. Например, для каждого из запросов baseball, basaball, baaeball, baselball были свои страницы, а нужно было сделать так, чтобы все варианты сходились на одну страницу с правильным запросом — baseball. В таком случае страница будет соответствовать правильной форме запроса и мы сможем избавиться от мусора в выдаче.
Примеры групп:

Стоит отметить, что агентствам далеко не всегда доверяют внедрения изменений в движке сайта. Так что мы благодарны нашему клиенту за возможность реализации этого проекта.
Цель
Создать чёткий работающий механизм простановки редиректов со страниц для фраз с ошибками на страницу клиентского сайта с правильной фразой.
Это нужно как для улучшения сканирования и индексации целевых страниц поисковиком, так и для построения
Как рождался новый метод
Самое простое решение, которое тут же приходит в голову — загнать запросы в Google, а он нам честно исправляет. Но организовать такую пробивку — довольно затратное мероприятие. Поэтому мы с товарищами пошли другим путем. Наш математик-аналитик решил использовать лингвистический подход (внезапно!) и построить языковую модель.
Что это значит? Мы определяем вероятность встретить слово в языке и для каждого слова находим вероятности допустить в нем разные ошибки. Все бы ничего, и теория тут красивая, но для сбора такой статистики нужно иметь огромный размеченный текстовый корпус для каждого языка (опять же, ближе всего к этому подошли поисковики). Естественно, возникли вопросы, как это делать и кто все это будет воплощать в код. До нас подобным делом никто не занимался (если знаете кейс — киньте ссылку в комментарии), поэтому методику разрабатывали с нуля. Было несколько идей и заранее не было очевидно, какая из них лучше. Поэтому мы ожидали, что разработка будет вестись циклически — подготовка идеи, реализация, тестирования, оценка качества, а затем решение — продолжать дорабатывать идею или нет.
Реализацию технологии можно условно разбить на три этапа. О каждом из них — подробнее.
Этап №1. Формирование проблемы. Первые грабли
Внимание! После этой строки будет много терминов, которые мы постарались объяснить максимально простым языком.
Так как дополнительная информация (словари, частоты, логи) недоступна, то были попытки решить задачу с теми ресурсами, которые у нас были. Мы испробовали разные методы кластеризации. Основная идея — в том, что слова из одной группы должны не слишком сильно различаться.
Кластеризация — процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы.
Для того, чтобы посчитать степень различия между двумя запросами на разных этапах, мы использовали расстояние Левенштейна и коэффициент Жаккарда на би- и триграммах.
Расстояние Левенштейна показывает, какое минимальное количество изменений (удаление, вставка и замена) в строке А надо сделать, чтобы получить строку В.
Пример:
- Замена символа: sh[e]res — sh[i]res, sh[o]res;
- Вставка символа: sheres — s[p]heres;
- Удаление: gol[d][f] — gol[]f, gold[].
В каждом из примеров расстояние между словом с ошибкой и правильной формой — 1 исправление.
Коэффициент Жаккарда на би- и триграммах помогает выяснить, сколько общих комбинаций из двух- или трехсимвольных слогов есть у строк А и В.
Пример: пусть мы рассматриваем строки A = snowboard и B = border. Общая формула коэффициента для биграмм имеет вид:
J = (число одинаковых биграмм для А и В) / (общее число биграмм в А и В)
Разобьем строки на биграммы:
биграммы для A = { sn, no, ow, wb, bo+, oa, ar, rd+ } - 8 штук; биграммы для B = { bo+, or, rd+, de, er } - 5 штук; Плюсиками отмечены одинаковые биграммы их 2 штуки - bo и rd.
Для триграмм будет аналогично, только вместо двух букв будут использоваться три. Коэффициент Жаккарда для них будет такой:
J = 2 / (8 + 5 - 2) = 0.18
Пример более похожих слов:
А = baseball и В = baaeball { ba+, as, se, eb+, ba+, al+, ll+ } { ba+, aa, ae, eb+, ba+, al+, ll+ } J = 5 / (7 + 7 - 5) = 0.56
Хотя коэффициент Жаккарда и работает быстрее, но не учитывает порядок слогов в слове. Поэтому использовался в основном для сравнения с расстоянием Левенштейна. Теоретически, тут все было просто. Методики кластеризации для малых данных решаются достаточно легко, но на практике оказалось, что для завершения разбивки нужны либо огромные вычислительные мощности, либо — годы времени (а в идеале — и то, и другое). За две недели работы был написан скрипт на Python. При запуске он читал фразы из файла и выдавал списки групп в другой файл. При этом, как и любая программа этот скрипт грузил процессор и использовал оперативную память.
Большинство испытанных методов требовали терабайтов памяти и недели процессорного времени. Мы же адаптировали методы так, чтобы программе хватало 2 гигабайта памяти и одного ядра. Впрочем, миллион запросов обрабатывался примерно 4-5 дней. Так что время выполнения задачи все равно оставляло желать лучшего. Результат работы алгоритма на небольшом примере можно представить в виде графика:
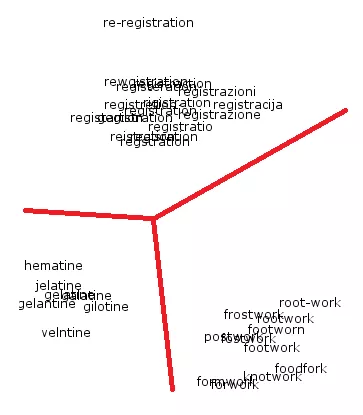
В применении к клиентскому проекту это означает, что страницы, соответствующие запросам в одном кластере, будут склеены друг с другом 301 редиректом. Напомним, что нашей целью было создать чёткий работающий механизм простановки редиректов со страниц для фраз с ошибками на страницу клиентского сайта с правильной фразой. Но даже на таком примере очевидны недочеты:
- Непонятно, как из групп находить правильные формы и есть ли они там вообще.
- Неизвестно, какие пороги для ошибок использовать. Если будет большой порог (больше 3-х ошибок), то группы будут очень большими и замусоренными, если слишком маленький — то каждое слово образует свою группу, что нас также не устраивало. Найти какое-то универсальное, приемлемое для всех групп значение — невозможно.
- Неясно, что делать со словами, которые могут быть отнесены одновременно к нескольким группам.
Этап №2. Упрощение. Новая надежда
Мы переделали алгоритм, приблизив его к традиционным механическим корректорам грамматики. Благо, таких достаточно. В качестве базы была выбрана библиотека для Python — Enchant. В этой библиотеке есть словари практически для любого языка мира, в использовании она довольно проста, и есть возможность получить подсказки — что на что нужно исправлять. В ходе предыдущего этапа мы многое узнали о видах запросов и о том, на каких языках могут быть эти запросы.
- английский (Великобритания);
- английский (США);
- немецкий;
- французский;
- итальянский;
- испанский;
- русский;
- украинский.
Дальше мы брали фразы и разбивали их на слова. Для каждого слова:
- Если оно правильное (находится в одном из словарей) — оставляем его как есть;
- Если оно неправильное — получаем список подсказок и берем первую попавшуюся;
- Все слова вновь склеиваем в фразу. Если такой фразы мы раньше не встречали, то создаем для неё группу. Исправленная форма фразы становится её «центром». Если же встречали, то значит для этой фразы уже есть своя группа, и мы добавляем туда новую ошибочную форму.

В итоге мы получили центр группы и список слов из этой группы. Тут, конечно, все лучше, чем в первый раз, но появилась скрытая угроза. Из-за специфики проекта в запросах очень много имен собственных. Есть и имена-фамилии людей, и города, организации, и географические местности, и даже латинские названия динозавров. В дополнение ко всему, мы обнаружили слова с неправильной транслитерацией. Так что мы продолжили искать пути решения проблемы.
Этап №3. Дополнения и пробуждение Силы
Проблема транслитерации решилась довольно просто и традиционно. Во-первых, сделали словарик соответствия букв кириллицы и латиницы. 
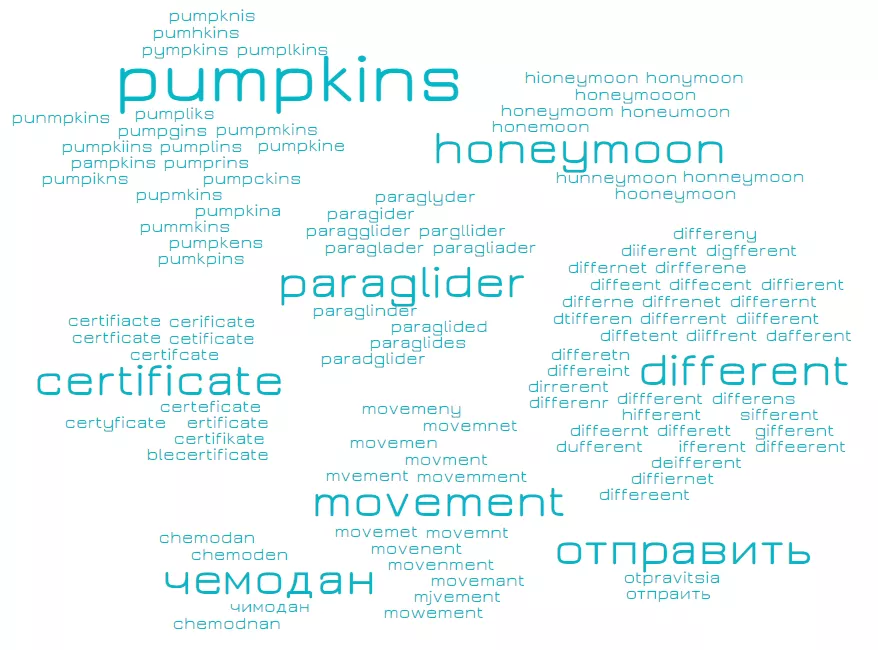
В соответствии с ним преобразовали каждую букву в проверяемых словах и отметили, есть ли для полученного слова исправление по словарю. Если вариант с транслитерацией имел наименьшее количество ошибок, то мы выбирали его как правильный. А вот имена собственные — тот еще орешек. Самым простым вариантом пополнить словари оказался сбор слов из дампов Википедии. Однако и в Вики есть свои слабые места. Слов с ошибками там довольно много, а методика их фильтрации еще не идеальна. Мы собрали базу слов, которые начинались бы с большой буквы, и без знаков препинания перед ними. Эти слова и стали нашими кандидатами в имена собственные. Например, после обработки такого текста подчеркнутые слова добавлялись в словарь:

При внедрении алгоритма оказалось, что для поиска подсказок в дополненном словаре Enchant иногда требуется больше 3 секунд на слово. Чтоб ускорить этот процесс, была использована одна из реализаций автомата Левенштейна.
Если коротко, идея автомата состоит в том, что по имеющемуся словарю мы строим схему переходов. При этом нам заранее известно, сколько исправлений в словах будут для нас приемлемы. Каждый переход означает, что мы делаем какое-то преобразование над буквами в слове — оставляем букву или применяем один из видов исправления — удаление, замена или вставка. А каждая вершина — это один из вариантов изменения слова.
Теперь, допустим, у нас есть слово, которое мы хотим проверить. Если в нем есть ошибка, нам нужно найти все подходящие нам формы исправления. Последовательно мы начинаем двигаться по схеме, перебирая буквы проверяемого слова. Когда буквы закончатся, мы окажемся в одной или нескольких вершинах, они и укажут нам варианты правильных слов.
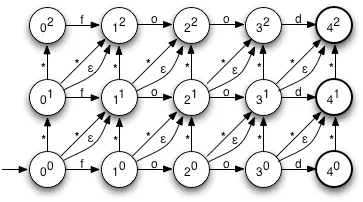
На изображении представлен автомат для слова food со всевозможными двумя ошибками. Стрелка вверх означает вставку символа в текущую позицию. Стрелка по диагонали со звездочкой — замена, с эпсилон — удаление, а по горизонтали — буква остается без изменений. Пусть у нас есть слово fxood. Ему будет соответствовать путь в автомате 00-10-11-21-31-41 — что равносильно вставке в слово food буквы x после f.
Кроме того, мы провели дополнительную работу по расширению собранных основных словарей, отсеиванию заранее не словарных фраз (названия моделей товаров и разные идентификаторы) в автоматическом режиме, внедрили транслитерацию и поиск по дополнительному словарю.
Что в итоге?
Мы еще работаем над модернизацией алгоритма, но уже на данном этапе разработки мы получили инструмент, которым можно чистить мусор, вроде облаков тегов, и склеивать 301 редиректами ненужные страницы. Такой инструмент будет особенно эффективен для небольшого количества слов с ошибками, но и на больших массивах показывает вполне удовлетворительные результаты. Промежуточный вариант скрипта отправлен клиенту для формирования блока перелинковки. По этому блоку можно будет собирать дополнительную информацию об исправлениях запросов. Полностью результаты работы скрипта на внедрение мы не отправляли, потому что все еще работаем над улучшением качества работы скрипта.
На создание кода и его испытания в общем ушло 40 часов работы математика-аналитика. Вывод: если вам однажды понадобится обработать около двух миллионов запросов — не отчаивайтесь. Такие задачи можно автоматизировать. Понятно, что добиться 100% точности будет очень сложно, но обработать корректно хотя бы 95% процентов информации — реально.

 25
25
 0
0
 1
1
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок