Url разные, а контент страниц одинаковый. Думаете, ничего страшного? Всего лишь пара одинаковых страниц на сайте. Но одинаковый контент может попасть под фильтры поисковых систем. Чтобы этого не произошло, надо знать, как избавляться от внутренних дублей страниц.
Понятие дублей страниц и их виды

Дубли — это отдельные страницы сайта, контент которых полностью или частично совпадает. По сути, это копии всей страницы или ее определенной части, доступные по уникальным URL-адресам.
Что приводит к появлению дублей на сайте:
- Автоматическая генерация дублирующих страниц движком системой управления содержимым сайта (CMS) веб-ресурса. Например:
https://site.net/press-centre/cat/view/identifier/novosti/
https://site.net/press-centre/novosti/
- Ошибки, допущенные вебмастерами. Например, когда один и тот же товар представлен в нескольких категориях и доступен по разным URL:
https://site.net/category-1/product-1/
https://site.net/category-2/product-1/
- Изменение структуры сайта, когда уже существующим страницам присваиваются новые адреса, но при этом сохраняются их дубли со старыми адресами. Например:
https://site.net/catalog/product
https://site.net/catalog/category/product
Есть два типа дублей: полные и частичные.
Что такое полные дубли
Это страницы с идентичным содержимым, доступны по уникальным, неодинаковым адресам. Примеры полных дублей:
1. URL-адреса страниц со слешами («/», «//», «///») и без них в конце:
https://site.net/catalog///product; https://site.net/catalog//////product.
2. HTTP и HTTPS страницы: https//site.net; http//site.net.
3. Адреса с «www» и без «www»: http//www.site.net; http//site.net.
4. URL страниц с index.php, index.html, index.htm, default.asp, default.aspx, home:
https://site.net/index.html;
https://site.net/index.php;
https://site.net/home.
5. URL-адреса страниц в верхнем и нижнем регистрах:
https://site.net/example/;
https://site.net/EXAMPLE/;
https://site.net/Example/.
6. Изменения в иерархической структуре URL. Например, если товар доступен по нескольким разным URL:
https://site.net/catalog/dir/tovar;
https://site.net/catalog/tovar;
https://site.net/tovar;
https://site.net/dir/tovar.
7. Дополнительные параметры и метки в URL.
- URL с GET параметрами: https://site.net/index.php?example=10&product=25. Страница полностью соответствует следующей: https://site.net/index.php?example=25&cat=10.
- Наличие utm-меток и параметров gclid.
Utm-метки помогают предоставить в систему аналитики информацию для анализа и отслеживания различных параметров трафика. URL целевой страницы, к которой добавляются utm-метки, выглядят так:
https://www.site.net/?utm_source=adsite&utm_campaign=adcampaign&utm_term=adkeyword - Параметры gclid (Google Click Identifier). Пометка целевых URL, которая добавляется автоматически для отслеживания данных о компании, канале и ключевых словах в Google Analytics. Например, если переходят по вашему объявлению для сайта https://site.net, то адрес перехода посетителя будет выглядеть так: https://site.net/?gclid=123xyz.
- Метка yclid. Помогает отслеживать эффективность рекламных кампаний в Яндекс Метрике. Метка позволяет отследить действия посетителя, который перешел на сайт по рекламному объявлению. Вот как выглядит адрес перехода:
https://site.net/?yclid=321. - Метка openstat. Универсальная и также используется для анализа эффективности рекламных кампаний, анализа посещаемости сайта и поведения пользователей на сайте. Ссылка с меткой «openstat»:
https://site.net/?_openstat=231645789. - Дубли, которые создаются реферальной ссылкой. Реферальная ссылка это специальная ссылка с вашим идентификатором, по которому сайты распознают, от кого пришел новый посетитель. Например:
https://site.net/register/?refid=398992;
https://site.net/index.php?cf=reg-newr&ref=Uncertainty.
8. Первая страница пагинации каталога товаров интернет-магазина или доски объявлений, блога. Она зачастую соответствует странице категории или общей странице раздела pageall: https://site.net/catalog; https://site.net/catalog/page1.
9. Неправильные настройки 404 ошибки приводят к появлению многочисленных дублей. Например: https://site.net/rococro-23489-rocoroc; https://site.net/8888-???.
Выделенный жирным текст может вмещать какие-либо символы и/или цифры. Страницы такого вида должны отдавать код ответа сервера 404 (не 200) или же перенаправлять на актуальную страницу.
Что такое частичные дубли
В частично дублирующихся страницах контент одинаковый, но есть небольшие отличия в элементах.
Виды частичных дублей:
1. Дубли на карточках товаров и страницах категорий (каталогов). Здесь дубли возникают из-за описаний товаров, которые представлены на общей странице товаров в каталоге. И те же описания представлены на страницах карточек товаров. Например, в каталоге на странице категории под каждым товаром есть описание этого товара:

И тот же текст на странице с товаром:

Чтобы избежать дубля, не показывайте полную информацию о товарах на странице категории (каталога). Или используйте неповторяющееся описание.
2. Дубли на страницах фильтров, сортировок, поиска и страницах пагинации, где есть похожее содержимое и меняется только порядок размещения. При этом текст описания и заголовки не меняются.
3. Дубли на страницах для печати или для скачивания, данные которых полностью соответствуют основным страницам. Например:
https://site.net/novosti/novost1
https://site.net/novosti/novost1/print
Частичные дубли тяжелее обнаружить. Но последствия от них проявляются систематически и негативно отражаются на ранжировании сайта
К чему приводят дубли страниц на сайте
Дубли могут появиться независимо от возраста и количества страниц на сайте. Посетителю они не помешают получить нужную информацию. Совсем иная ситуация с роботами поисковых систем. Поскольку URL разные, поисковые системы воспринимают такие страницы как разные. Следствием большого количества дублирующегося контента становится:
- Проблемы с индексацией. При генерировании дублирующих страниц увеличивается общий размер сайта. Боты, индексируя «лишние» страницы, неэффективно тратят краулинговый бюджет собственника веб-ресурса. «Нужные» страницы могут вовсе не попасть в индекс. Напомню, что краулинговый бюджет это количество страниц, которое бот может просканировать за один визит на сайт.
- Изменения релевантной страницы в выдаче. Алгоритм поисковика может решить, что дубль больше подходит запросу. Поэтому в результатах выдачи он покажет не ту страницу, продвижение которой планировалось. Другой итог: из-за конкуренции между дубль-страницами, ни одна из них не попадет в выдачу.
- Потеря ссылочного веса страниц, которые продвигаются. Посетители будут ссылаться на дубли, а не на оригиналы страниц. Результат потеря естественной ссылочной массы.
Каталог средств для поиска дублированных страниц
Итак, мы уже выяснили, что такое дубли, какими они бывают и к чему приводят. А теперь перейдём к тому, как их обнаружить. Вот несколько эффективных способов:
Поиск дублей с помощью специальных программ
Netpeak Spider. С помощью сканирования можно обнаружить страницы с дублирующимся содержанием: полные дубли страниц, дубли страниц по содержимому блока <body>, повторяющиеся теги «Title» и метатеги «Description».
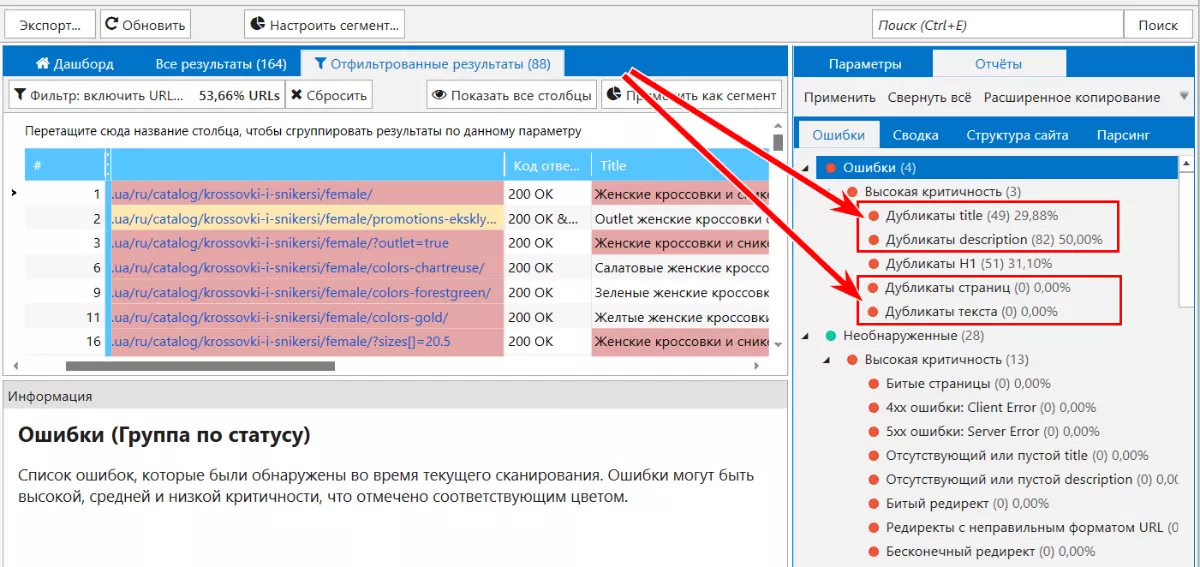
Использование поисковых операторов
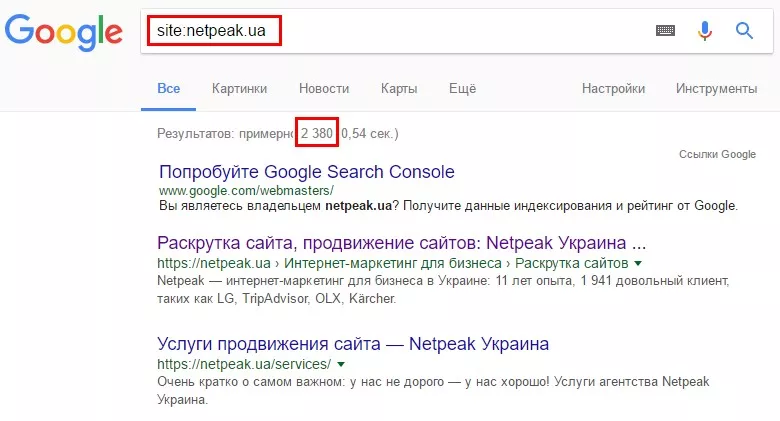
Для поиска дублей можно проанализировать страницы, которые уже проиндексированы, используя поисковый оператор «site:». Для этого в поисковую строку, например Google, вводим запрос «site:examplesite.net». Он покажет страницы сайта в общем индексе. Так мы увидим количество страниц в выдаче, если оно сильно отличается от количества найденных спайдером страниц или страниц в XML-карте.
Просмотрев выдачу, вы обнаружите повторяющиеся страницы, а также «мусорные» страницы, которые нужно удалить из индекса.
Также можно воспользоваться поиском для анализа выдачи по определенному фрагменту текста со страниц, которые, по вашему мнению, могут иметь дубли. Для этого берём в кавычки часть текста, после него ставим пробел, оператор «site:» и вводим в строку поиска. Необходимо указать ваш сайт, чтобы найти страницы, на которых присутствует именно этот текст. Например:
«Фрагмент текста со страницы сайта, которая может иметь дубли» site:examplesite.net
Если в результатах поиска одна страница, значит у страницы нет дублей. Если же в выдаче несколько страниц, необходимо проанализировать их и определить причины дублирования текста. Возможно, это и есть дубли, от которых необходимо избавиться.
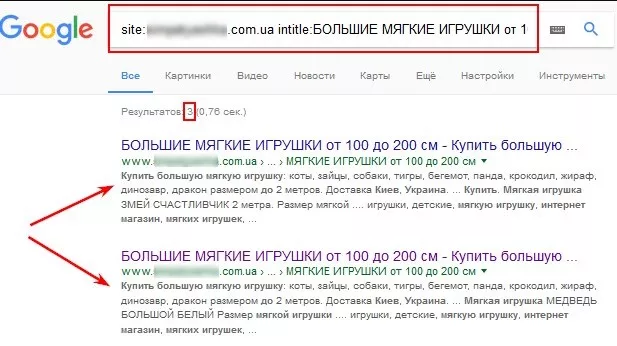
Аналогичным образом, используя оператор «intitle:», анализируем содержимое «Title» на страницах в выдаче. Дублирование «Title» бывает признаком дублирующих страниц. Чтобы проверить, используем поисковый оператор «site:». При этом вводим запрос вида:
Вот как это выглядит:
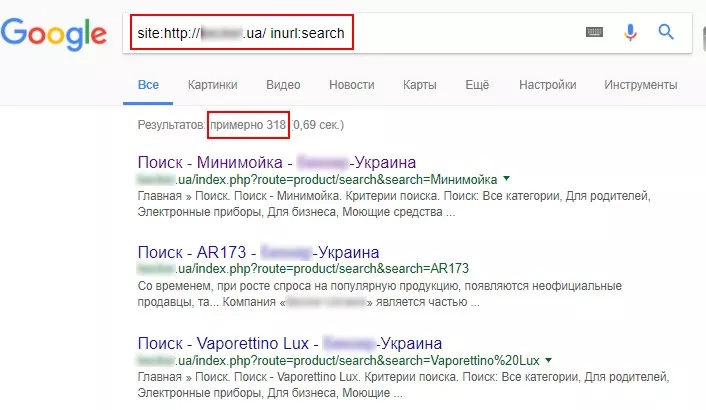
Используя операторы «site» и «inurl», можно определить дубли страниц, которые возникли на страницах сортировок (sort) или на страницах фильтров и поиска (filter, search).
Например, для поиска страниц сортировок в поисковой строке нужно прописать: site:examplesite.net inurl:sort.
Для поиска страниц фильтров и поиска: site:examplesite.net inurl:filter, search.
Запомните, поисковые операторы показывают только те дубли, которые уже были проиндексированы. Поэтому нельзя полностью полагаться на этот метод.
Как избавиться от дублей
Мы уже рассмотрели, что такое дубли, виды, последствия дублей и как их найти. Теперь переходим к самому интересному как же сделать так, чтобы они перестали вредить оптимизации. Используем методы устранения дублей страниц:
301 редирект
Считается основным методом устранения полных дублей. 301 редирект выполняет автоматическое переадресование с одной страницы сайта на другую. По настроенному редиректу боты видя, что по данному URL страница больше не доступна и перенесена на другой адрес.
301 редирект позволяет передать основной странице ссылочный вес с дублирующей страницы.
Этот метод актуален для устранения дублей, которые появляются из-за:
- URL в разных регистрах;
- иерархии URL;
- определения основного зеркала сайта;
- проблем с использованием слешей в URL.
Например, 301 редирект используют для перенаправления со страниц https://site.net/catalog///product;
https://site.net/catalog//////product;
https://site.net/product на страницу https://site.net/catalog/product.
Файл robots.txt
С помощью метода мы рекомендуем поисковым ботам, какие страницы или файлы не стоит сканировать.
Для этого необходимо использовать директиву «Disallow», которая запрещает поисковым ботам заходить на ненужные страницы.
User-agent: *
Disallow: /stranica
Отметим, если страница указана в robots.txt с директивой Disallow, эта страница все равно может оказаться в выдаче. Почему? Она была проиндексирована ранее, или же на нее есть внутренние или внешние ссылки. Инструкции robots.txt носят рекомендательный характер для поисковых ботов. Они не могут гарантировать удаление дублей.
Рекомендуем детальнее ознакомиться с
Метатег <meta name="robots" content="noindex, nofollow> и <meta name="robots" content="noindex, follow>
Метатег <meta name="robots" content="noindex, nofollow"> указывает роботу не индексировать документ и не переходить по ссылкам. В отличие от robots.txt, этот метатег — прямая команда, и она не будет игнорироваться поисковыми роботами.
Метатег <meta name="robots" content="noindex, follow"> указывает роботу не индексировать документ, но при этом переходить по ссылкам размещенным в нем.
Но, как сообщает представитель Google Джон Мюллер, рано или поздно метатег "noindex, follow" воспринимается поисковой системой как "noindex, nofollow".
То есть, если бот заходит впервые и видит директиву "noindex, follow", то он не индексирует страницу, но вероятность перехода по внутренним ссылкам еще остается. Но если бот возвращается через некоторое время и опять видит "noindex, follow", то страница полностью удаляется из индекса, бот перестает на нее заходить и учитывать размещенные ссылкам на этой странице. Это значит, что в долгосрочном периоде нет разницы между мета тегами "noindex, follow" и "noindex, nofollow".
Для использования метода необходимо разместить на дублирующих страницах в блоке <head> один из метатегов:
<meta name="robots" content="noindex, nofollow" /> или же аналогичный: <meta name="robots" content="none" />; <meta name="robots" content="noindex, follow" />.
Атрибут rel="canonical"
Используйте метод, когда удалять страницу нельзя и её нужно оставить открытой для просмотра.
Тег для устранения дублей на страницах фильтров и сортировок, страницах с get-параметрами и utm-метками. Применяется для печати, при использовании одинакового информационного содержания на разных языковых версиях и на разных доменах. Атрибут rel="canonical" для разных доменов поддерживается не всеми поисковыми системами. Для Google он будет понятен, Яндекс его проигнорирует.
Указывая каноническую ссылку, мы указываем адрес страницы, предпочтительной для индексации. Например, на сайте есть категория «Ноутбуки». В ней фильтры, которые показывают разные параметры выбора. А именно: бренд, цвет, разрешение экрана, материал корпуса и т.д. Если эти страницы фильтров не будут продвигаться, то для них канонической указываем общую страницу категории.
Как задать каноническую страницу? В HTML-код текущей страницы помещаем атрибут rel="canonical" между тегами <head>...</head>. Например, для страниц:
https://site.net/index.php?example=10&product=25;
https://site.net/example?filtr1=%5b%25D0%,filtr2=%5b%25D0%259F%;
https://site.net/example/print.
Канонической будет страница https://site.net/example.
В HTML коде это будет выглядеть так: <link rel="canonical" href="https://site.net/example" />.

Выводы
1. Дубли — отдельные страницы сайта, контент которых полностью или частично совпадает.
2. Причины возникновения дублей на сайте: автоматическая генерация, ошибки, допущенные вебмастерами, изменение структуры сайта.
3. К чему приводят дубли на сайте: индексация становится хуже; изменения релевантной страницы в поисковой выдаче; потеря естественной ссылочной массы продвигаемыми страницами.
4. Методы поиска дублей: использование программ-парсеров (Netpeak Spider); поискового оператора site.
5. Инструменты устранения дублей: соответствующие команды в файле robots.txt; тег meta name="robots" content="noindex, nofollow"; тег rel="canonical"; 301 редирект.
Устранили дублирующий контент? Теперь необходимо проверить сайт ещё раз. Так вы увидите эффективность проведенных действий, оцените результативность выбранного метода. Анализ сайта на дубли рекомендуем проводить регулярно. Только так можно вовремя определить и устранить ошибки.

 79
79
 8
8
 26
26
Свежее
7 ошибок в Google Ads, которые влияют на результаты рекламной кампании
В этой статье разберу типичные ошибки, с которыми часто приходится сталкиваться: пять базовых и две неочевидные. Для каждой покажу, как выявить проблему, исправить её и отследить, какое влияние она оказывает на рекламные кампании
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?