Многие задачи поисковой оптимизации сайта можно и нужно автоматизировать. Например, сбор информации, составление списка товаров, анализ цен конкурентов, скорость внедрения рекомендаций. Автоматизировать эти процессы позволяет парсер сайтов.
Парсинг сайтов (или скрапинг) — процесс автоматического сбора и извлечения информации из онлайн-ресурсов.
Должен предупредить: обучение и грамотная настройка инструментов для парсинга займут много времени — дольше, чем если бы вы все делали вручную. Впрочем, так обстоят дела со всеми инструментами, с которыми работаешь впервые. Главное — начать.
За два года в агентстве Netpeak я познакомился со множеством методов парсинга данных. Расскажу, какие парсеры и для каких целей я использую при оптимизации сайта. Буду идти от простых решений к сложным.
1. Google Spreadsheet
С помощью таблиц Google можно вытянуть из сайта простые элементы для сравнения и компонирования малых объемов. Это title, description, h1, keywords, заголовки, артикулы, цены, тексты, таблицы данных. Этот бесплатный инструмент подходит для точечных, малообъемных задач. Например, создать файл с отслеживанием текста и заголовков страницы.
Существуют две простые функции:
1. =importhtml — для импорта данных из таблиц или списков.
2. =importxml — для импорта данных из документов в форматах XML, HTML, CSV, TSV, RSS, ATOM XML.
Для работы с функцией =importxml потребуется знание XPath. Но если не хотите тратить время на изучение документации, используйте отладчик браузера.
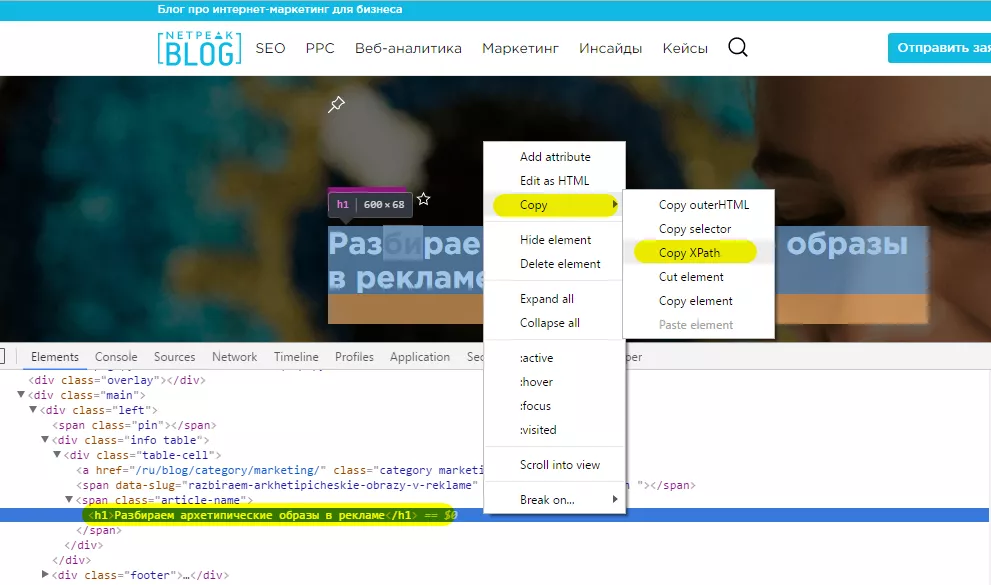
Чтобы запустить отладчик, кликните на нужном элементе страницы правой кнопкой мышки и выберите «Посмотреть код», или нажмите F12.
В отладчике пройдите по пути: Copy — Copy XPath. Скопированный XPath вставляйте в функцию =importxml.
Минусы
С каждым месяцем все хуже и хуже обрабатывается функция =importxml. Раньше можно было без проблем парсить данные сразу же для ~500 URL-адресов, сейчас с трудом обрабатываются 50 URL.
Плюсы
- автоматическое обновление при входе;
- можно настроить автоматическое обновление по времени (минута, час, день);
- при парсинге данных прямо в таблицу можно осуществлять преобразование данных и сразу же делать готовые отчеты, примеры, визуализации.
Какие задачи решает?
С помощью функции =importxml можно собирать в режиме реального времени данные о мета тегах и, например, о количестве комментариев к интересующим статьям.
В колонке A — ячейки с ссылкой на страницу. Тег title для ячейки A2 подтягивается с помощью запроса =IMPORTXML(A2;"//title").
Метатег description: =IMPORTXML(A2;"//meta[@name='description']/attribute::content").
Тег H1 — с помощью запроса: =IMPORTXML(A2;"//h1").
Автор поста: =IMPORTXML(A2;"//a[@class='author-name']").
Дата публикации: =IMPORTXML(A2;"//div[@class='footer']/span").
Количество комментариев к посту: =IMPORTXML(A2;"//span[@class='regular']").
С помощью функции =importhtml также можно подтянуть много интересных данных, например, основную информацию из Википедии об интересующих объектах.
2. Netpeak Spider
Десктопная программа для сканирования сайта, которая направлена на поиск SEO-ошибок, и включает возможности парсинга данных из HTML-страниц.

SEO-специалисту при обычном сканировании сайта иногда не хватает данных для анализа. С помощью Netpeak Spider можно, например, найти на сайте страницы с 404 ошибкой, страницы без тега Title и дополнительно спарсить цены на страницах товаров.
Таким образом можно обнаружить товары без цены и далее уже принять адекватное решение — оставить, убрать, закрыть их для сканирования/индексации.
Также можно вытянуть все тексты, которые размещены на страницах, задав определенный CSS-селектор или класс, в рамках которого они размещаются.
Стоимость программы — $14 в месяц или $117 в год (со скидкой 30%).
Минусы
- нет привязки по API;
- нет возможности обновлять данные по сценарию.
Плюсы
- существует возможность как добавить готовый список URL для парсинга данных, так и удобно просканировать весь сайт;
- одновременно можно запускать до 15 парсеров с уникальными настройками;
- можно отфильтровать страницы, на которых не были найдены искомые данные;
- показываются все уникальные вхождения, их количество и длина;
- кроме парсера данных, получаем также инструмент для комплексного SEO-анализа сайта.
Какие задачи решает?
Парсинг цен
Задача: необходимо узнать стоимость ноутбуков.
Список URL:
https://rozetka.com.ua/asus_x555lj_xx1465d/p11201236/
https://rozetka.com.ua/asus_x555sj_xo001d/p6596109/
https://rozetka.com.ua/asus_n551jb_xo127d/p10727833/
https://rozetka.com.ua/asus_e502sa_xo014d/p9155171/
https://rozetka.com.ua/asus_e502sa_xo001d/p10677881/
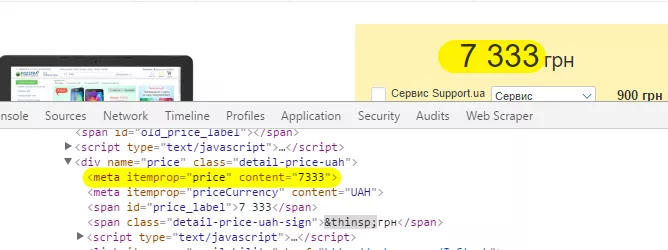
Решение. Для начала необходимо определить, какой элемент нужно вытянуть — в данном случае будем вытаскивать метатег «itemprop» со значением «price»:
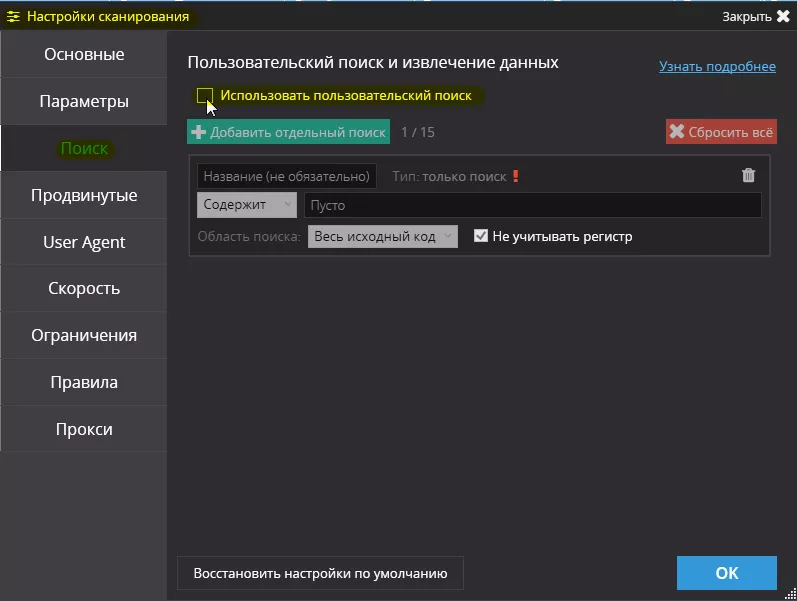
Далее переходим в настройки сканирования Netpeak Spider на вкладку «Поиск» и включаем галочку «Использовать пользовательский поиск»:
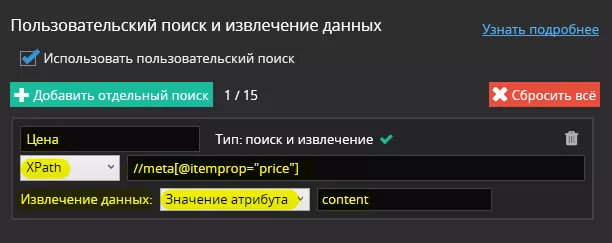
Теперь необходимо задать настройки поиска — в качестве примера будем использовать XPath: //meta[@itemprop="price"]
А в дополнительных настройках поиска выберем «Извлечение данных» — «Значение атрибута» — «content»:
Что в результате?
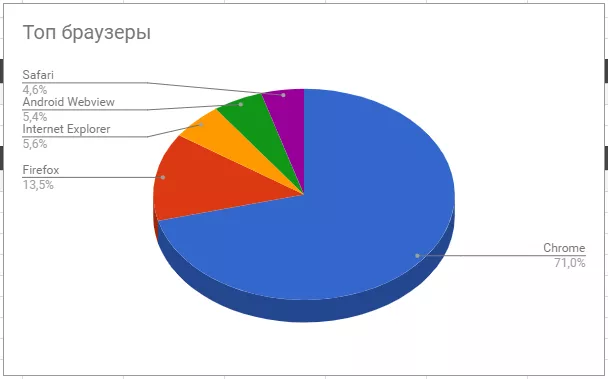
1. На четырёх страницах Spider нашел цены — отчёт открывается при выборе нужного поиска и нажатии на кнопку «Результаты извлечения»:
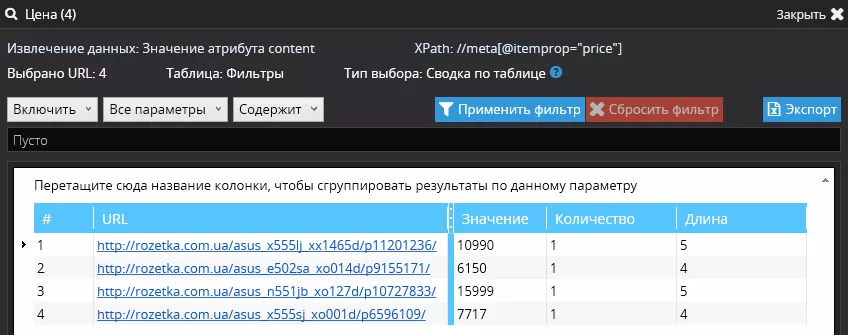
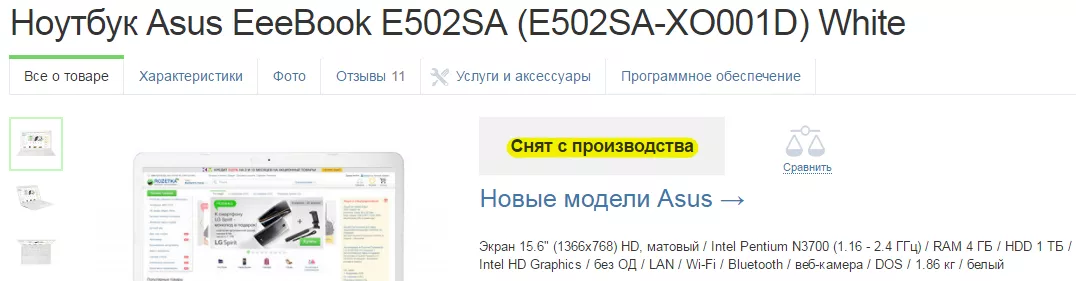
2. На одной странице не была найдена цена — на этой странице (https://rozetka.com.ua/asus_e502sa_xo001d/p10677881/) мы видим сообщение, что товар снят с производства:
Проверка внедрения GTM
Задача: проверить интеграцию кода GTM на страницах и ответить на два вопроса.
- Установлен ли код в принципе?
- Код установлен с правильным идентификатором?
Список URL:
https://netpeak.net/ru/blog/category/seo/
https://netpeak.net/ru/blog/category/ppc/
https://netpeak.net/ru/blog/category/web-analytics/
https://netpeak.net/ru/blog/category/marketing/
Решение. Аналогично, сначала нужно определить, какой элемент отвечает за код GTM, — в данном случае будем вытягивать GTM ID с помощью

В Netpeak Spider переходим в «Аналогичные настройки сканирования» и задаём поиск по регулярному выражению: ['"](GTM-\w+)['"]
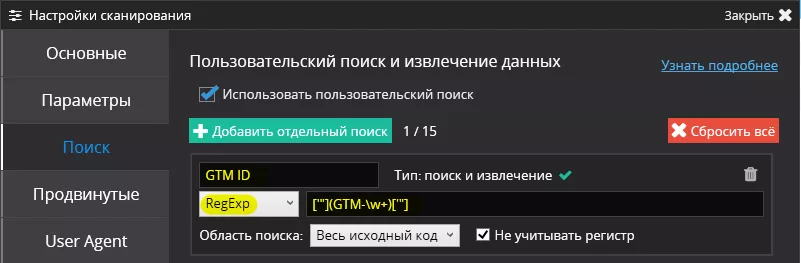
Что в результате?
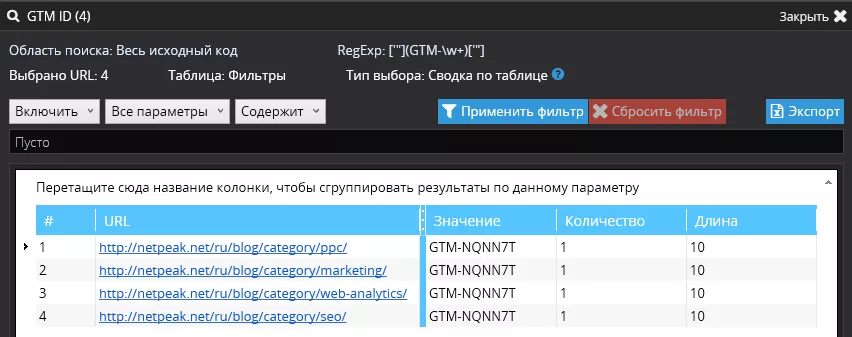
Видим, что код установлен и идентификатор правильный.
Чтобы узнать больше примеров использования Netpeak Spider, читайте подробный обзор этой функции в блоге Netpeak Software.
3. Web Scraper
Web Scraper — бесплатное браузерное расширение для Chrome. Вы можете настроить план обхода сайтов, то есть задать логику для перемещения краулера и указать данные, которые будут извлечены. Web Scraper будет проходить через сайт в соответствии с настройкой и извлекать соответствующие данные. Это позволяет экспортировать извлеченные данные в CSV.
Минусы
- нет возможности интеграции по API, то есть для обновления данных Web Scraper нужно запускать самостоятельно и ждать, пока завершится сканирование. Благо, проекты сохраняются в браузере, существует возможность сохранить проект в формате Json.
- также есть ограничение в один поток. 2 000 страниц парсятся больше часа.
- работает только в Chrome.
Плюсы
- удобный, простой и интуитивно понятный инструмент.
- может извлекать данные из динамических страниц, которые используют Javascript и Ajax.
Какие задачи решает?
Спарсить информацию о карточке товара
План обхода сайта показывает логику парсинга:
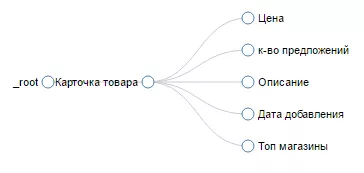
Элементы для парсинга:
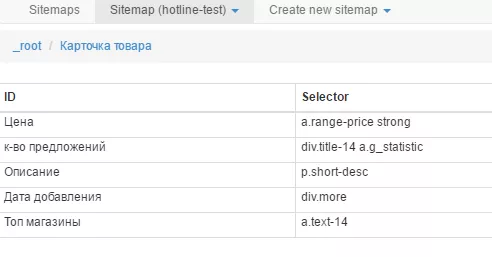
После завершения парсинга информация будет отображена в таком виде:
Обучающие материалы:
4. Google Spreadsheet + Google Apps Script
Google Apps Script — язык программирования, основанный на JavaScript. Позволяет создавать новые функции и приложения для работы с Google Docs, Google Sheets и Google Forms. Настроить связку можно бесплатно.
Минусы
Нужно знание языка программирования JavaScript.
Плюсы
Потратив определенное время на настройку отчетов, можно оперативно реагировать на изменения данных.
Какие задачи решает?
С помощью связки Google Spreadsheet и Google Apps Script можно получать и обновлять данные в режиме реального времени, а это полезно, чтобы следить за конкурентами и настраивать оповещение при изменениях, например, тегов title. Также можно настроить мониторинг цен и получать уведомления при изменении показателей.
Пример скрипта для отслеживания цен.
Выводы
Для гибкого и эффективного использования бесплатных инструментов парсинга сайтов необходимо как минимум знать, что такое XPath, а оптимально — еще и владеть основами JavaScript. Да и платные решения, вроде Netpeak Spider, предлагают все более интересные возможности, вроде одновременной настройки 15 потоков парсинга.
Многие вопросы, связанные с автоматизацией, раньше решал Kimono, но с момента закрытия облачного сервиса он перестал быть таким уж привлекательным для SEO-специалиста.
Пишите в комментариях, какие инструменты вы используете для парсинга, и какие задачи решаете с их помощью.

 4
4
 4
4
 0
0
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок