Перед показом страницы в выдаче её основательно обрабатывают роботы поисковых систем. Вначале роботы сканируют страницу, затем вносят контент в индекс и предоставляют результаты в выдаче. Мы уже детально раскрыли процесс
Индексирование — объединение и систематизация всей собранной на этапе сканирования информации о страницах с помощью создания специальной базы, индекса.
Не все просканированные страницы попадают в индекс. При сканировании робот вносит в свою базу все страницы, которые может обнаружить, но в индекс войдут только те, которые робот сочтет полезными для пользователя.
Также не стоит путать индексирование с ранжированием. На данном этапе ранг документу не присваивается, так как база постоянно пополняется новыми страницами и определить релевантность документа однозначно нельзя — через секунду может появится более релевантная страница. Поэтому ранг странице присваивается непосредственно в момент поиска.
Как формируется индекс?
Индекс содержит данные о словах на странице, о их местоположении, данные из основных тегов и атрибутов, например, тегов title и атрибутов alt. Построив индекс, роботы поисковых систем легко проводят поиск нужных документов.
Большинство роботов используют «инвертированный индекс» — для каждого термина создается список документов, которые содержат этот запрос.
Например:
Термин | Документ |
Термин 1 | Документ 1, Документ 3, Документ 5, Документ 7 |
Термин 1 | Документ 3, Документ 5, Документ 4 |
Термин 1 | Документ 3, Документ 6 |
Если посмотреть на создание инвертированного индекса глазами робота, то выглядит это примерно так:
- Конверсия в чистый текст — робот удаляет нетекстовые элементы (разметка, графика).
- Токенизация — робот создает выборку слов для выделения лексем (семантических единиц для обработки).
- Лингвистическая обработка лексем. Собранные лексемы всех слов со всех текстов упорядочиваются по алфавиту и для каждой из них добавляется номер вхождения и информация о номере страницы, откуда лексема была взята.
- Собственно составление индекса.
Сама запись в индексе выглядит примерно так, но для экономии места роботы могут усложнять ее структуру:
Лексема / номер страницы + номер вхождения / номер страницы + номер вхождения / номер страницы + номер вхождения /
Как управлять индексированием?
Как стимулировать роботов внести страницы в индекс:
1. Открыть закрытые для индексирования страницы.
2. Проследить, чтобы страницы просканировались, добавляя ссылки для сканирования в очередь с помощью вебмастера. Также можно использовать
3. Размещать релевантный контент, метатеги, оптимизировать изображения, следить, чтобы рекламные блоки занимали максимум 30% первого экрана сайта.
Как ограничить доступ роботов к индексированию контента:
1. Добавить специальный метатег в верхней части HTML-страниц: <meta name="robots" content="noindex" />.
2. Добавить специальный HTTP-заголовок: X-Robots-Tag: noindex.
Как проверить, попала ли страница в индекс?
1. Вручную, через строку поиска.
1.2. С помощью оператора поиска site:domen.com проверить индексацию всего сайта:
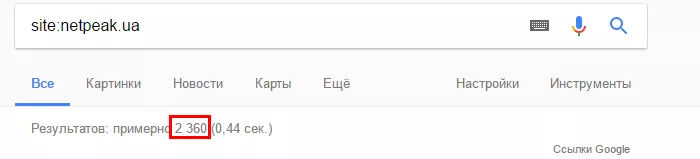
1.3. С помощью оператора site:domen.com/page1, где domen.com/page1 — url проверяемой страницы:
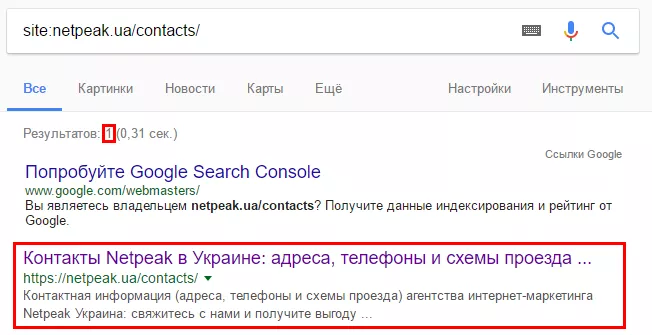
1.4. С помощью оператора поиска cache:domen.com/page1, где domen.com/page1 — url проверяемой страницы :
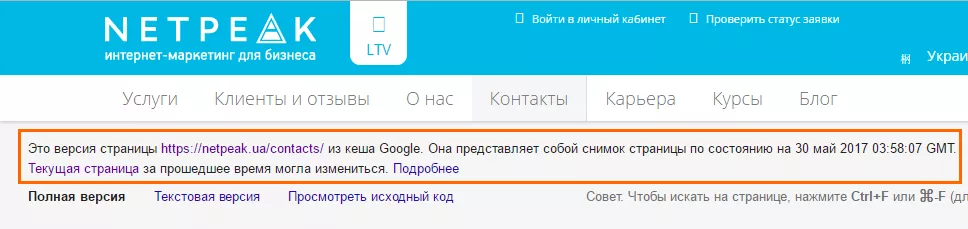
2. С помощью вебмастера Google:
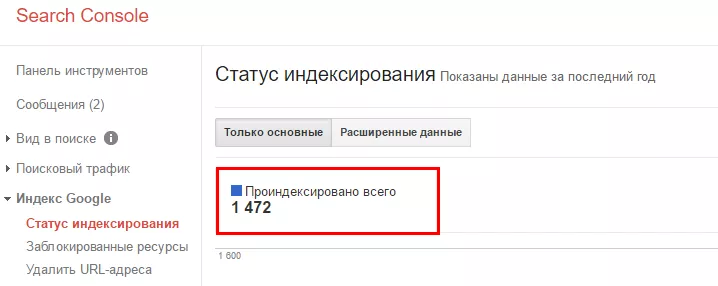
3. С помощью плагина RDS Bar:
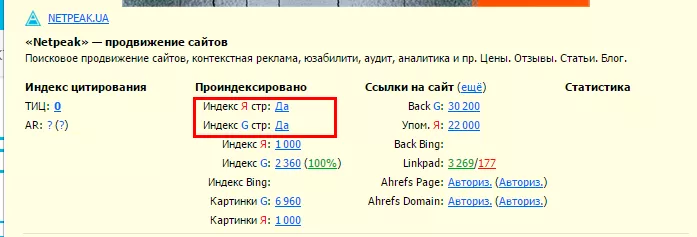
Больше
Почему страница выпадает из индекса?
1. Установлен запрет на сканирование в
2. На странице существует атрибут
3. Ответ сервера содержит HTTP-статус 4XX или 5XX, это препятствует обработке страницы роботом.
4. Сайт находится под фильтрами поисковых систем (из-за неуникального контента, манипулирования ссылочными факторами и так далее).
5. На странице присутствуют дубли контента.
6. Страница перенаправляет робота — отображается
Выводы
- Во время индексирования роботы поисковых систем систематизируют собранные в процессе сканирования данные о страницах сайта.
- SEO-специалист может влиять на индексирование контента сайта (но нет стопроцентной гарантии, что роботы поисковых систем к нему прислушаются).
- Сканирование страницы не гарантирует того, что контент будет проиндексирован, а индексация контента не означает, что он будет ранжироваться.
Остались вопросы? Пишите в комментариях, или ищите ответы в других выпусках рубрики «Азбука SEO».

 62
62
 3
3
 11
11
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок