Как создать фид динамического ремаркетинга для Facebook без программиста
Важно: из-за ограничений парсинга таблиц формулы годятся для формирования небольших фидов до 1000 продуктов.
Парсим данные в разных таблицах: из-за парсинга большого количества данных мы либо долго ждем результаты, либо получаем ошибки в формулах. А чаще всего и то и другое. Поэтому собираем данные в отдельных таблицах, а потом объединяем их.
Процесс занимает 1-3 часа, в зависимости от навыков работы в Google SpreadSheets и времени парсинга самого сайта.
У меня ушел час на подготовку и ввод формул, два часа на сканирование сайта, чтобы получить необходимые данные.
Все шаги показаны на примере проекта команды болгарского офиса Netpeak.
Этапы создания продуктового фида для фейсбук
Фид в фейсбуке — это таблица с товарами, которая должна отвечать определенным требованиям площадки.
Форматы файлов для Facebook: csv, tsv и xml (rss/atom).
Для продуктов необходимы следующие поля:
- id;
- title;
- description;
- availability;
- condition;
- price;
- link;
- image_link;
- brand, mpn or gtin (include at least one).
1. Сохранение исходных ссылок продуктов
Нам нужен список со ссылками на продукты. Их можно взять из sitemap xml.
- сохраняем xml карту;
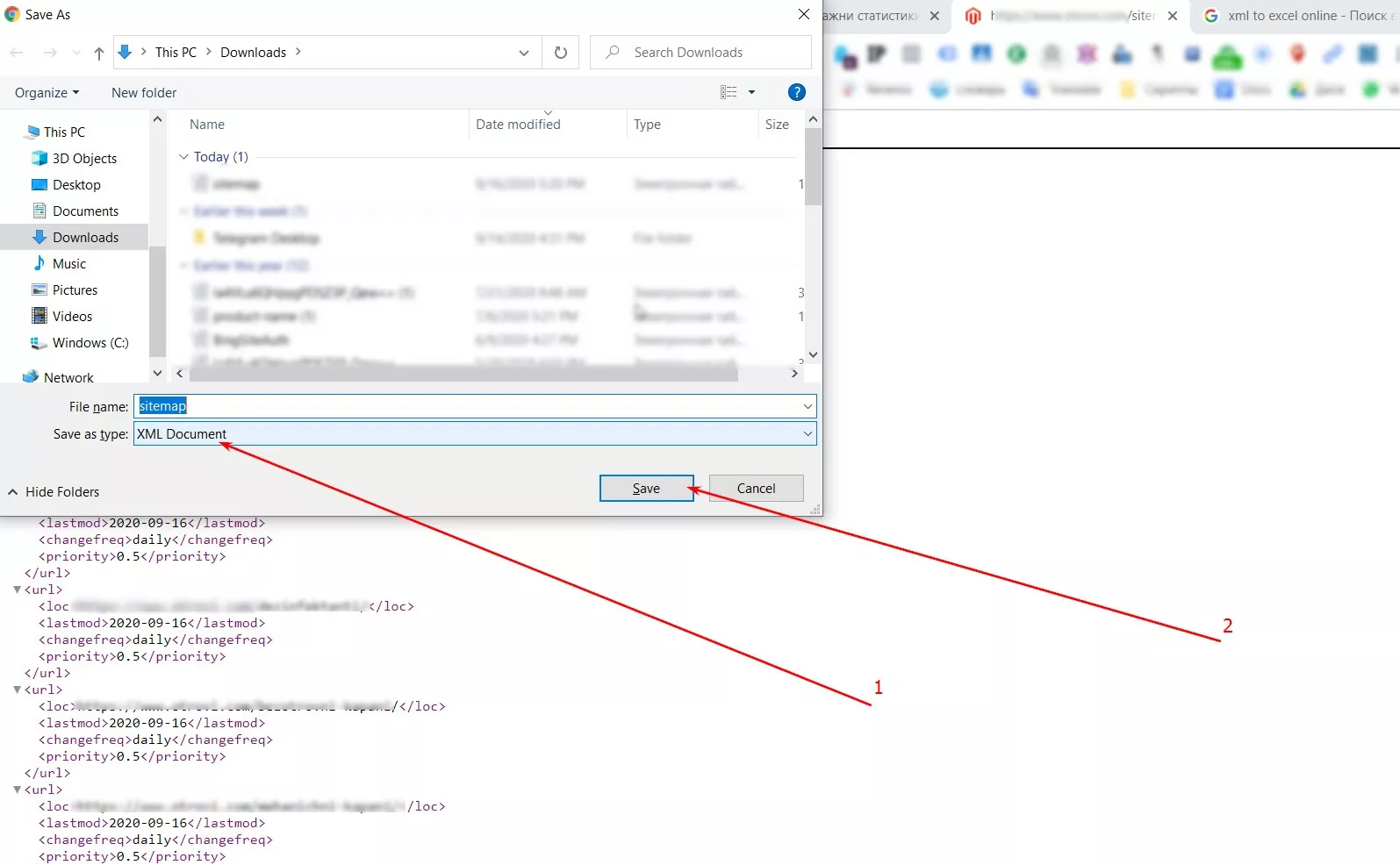
- конвертируем xml в xlsx формат;
Существует много инструментов для бесплатного конвертирования, например, freefileconvert.
- копируем ссылки в таблицу Google;
Для парсинга данных используем XPath.
XPath (XML Path Language) — язык запросов к элементам xml или xhtml документа. Он применяется для навигации по элементам и атрибутам XML-документа. Выражения языка запросов очень похожи на пути, которые можно видеть при работе с файловой системой компьютера.
XPath использует выражения пути для выбора узлов в документе XML.
Самые полезные выражения пути:
|
Выражение |
Описание |
|
имя_узла |
Выбирает все узлы с именем имя_узла |
|
/ |
Выбирает от корневого узла |
|
// |
Выбирает узлы в документе от текущего узла, который соответствует выбору, независимо от того, где они находятся |
|
. |
Выбирает текущий узел |
|
.. |
Выбирает родителя текущего узла |
|
@ |
Выбирает атрибуты |
Как ещё использовать XPath?
Xpath — декларативный язык запросов к элементам xml или (x)html документа и xslt преобразований.
XPath можно использовать для навигации по элементам и атрибутам в документе XML.
Это означает, что вы можете выбрать любой элемент или содержимое любого элемента, атрибута, таблицы или мета-объекта в источнике HTML документа или визуализированного документа.
2. Парсинг заголовка продукта
ImportXML(Url; XPath) — формула Google Spreadsheets, которая импортирует данные из источников в формате XML, HTML, CSV, TSV по URL и применении языка запросов XPath.
С помощью ImportXML можно парсить элементы метаданных (title, description, heading) любого сайта.
Рассмотрим на примере заголовка для страницы:
В коде страницы находим <h1>
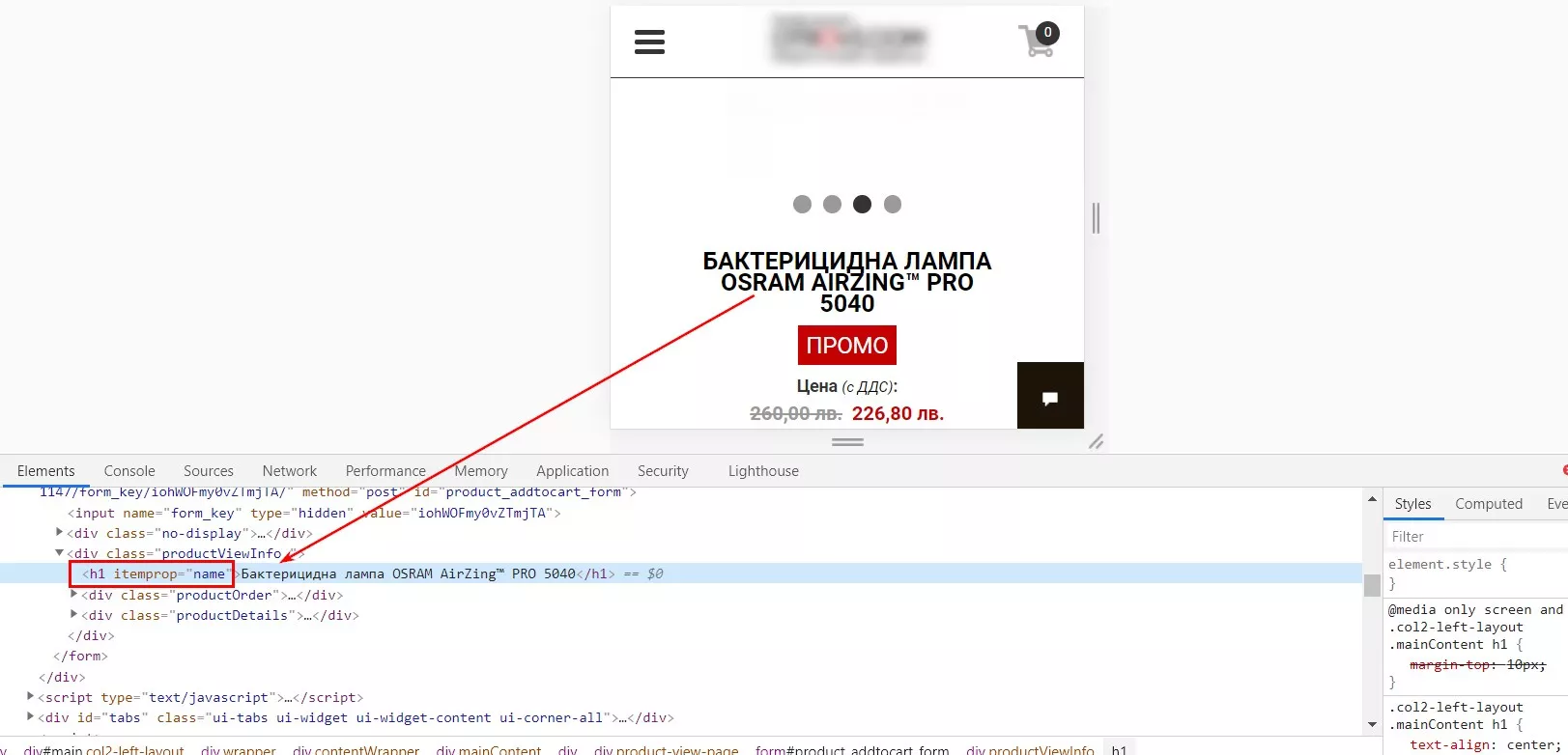
Таким образом XPath для страницы сайта будет выглядеть «//h1».
//h1 — указывает на относительный путь к тегу h1. То есть нас не интересует на какой глубине (уровне вложенности) от корня находится заголовок.
Полная функция для Google Spreadsheets будет выглядеть так:
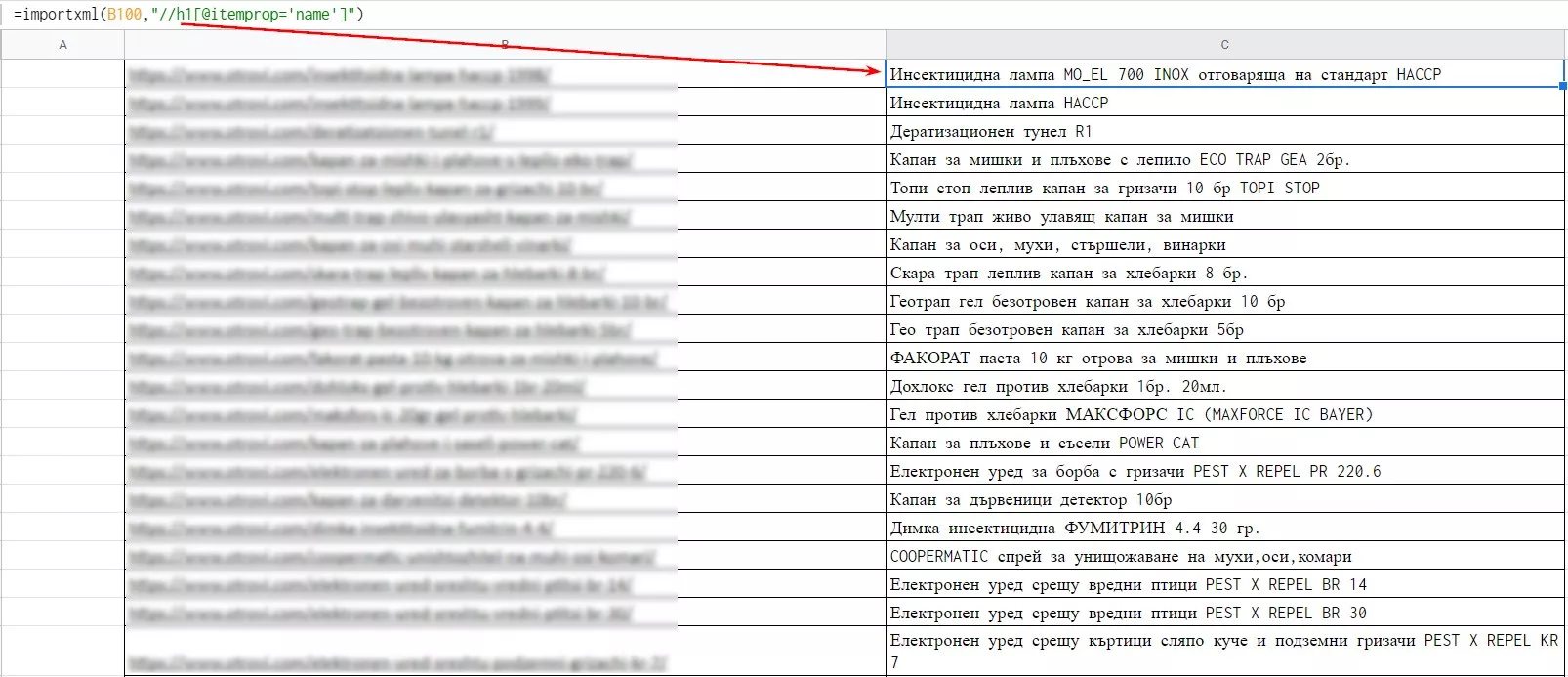
=importxml(URL,"//h1[@itemprop='name']")
Применение для списка страниц:
3. Парсинг цен/наличие продукта
В данном примере удобнее было парсить целый блок цен (старая/новая цена + наличность), но бывают случаи, когда приходится парсить отдельно.
Рассмотрим конкретный случай, когда блок цен описан следующим образом:
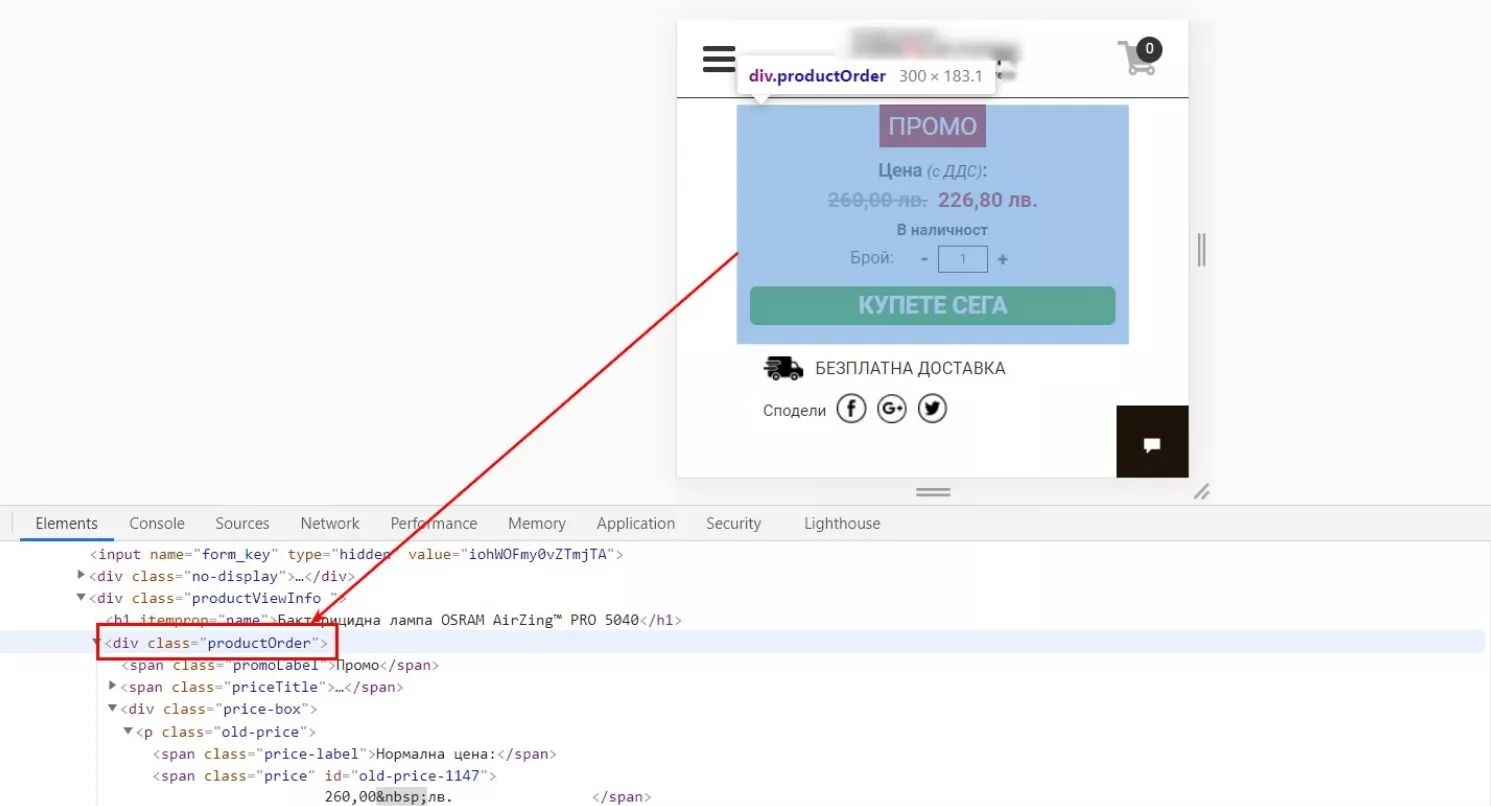
Формула: =importxml(URL,"//div[@class='productOrder']")
Есть минус — таблица принимает нечитабельный вид, но с этим справимся чуть позже.
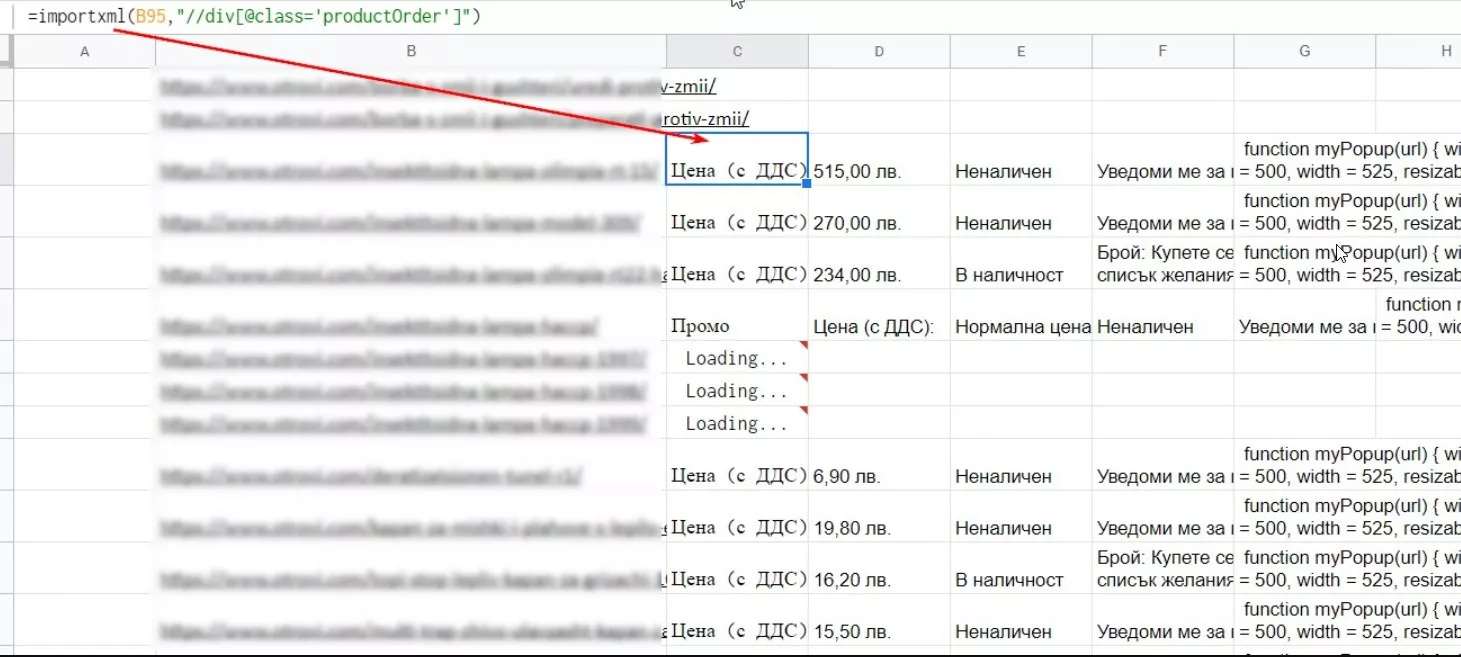
{kind=link}
Наличие продукта
Используем обычную функцию IF. Если в описании продукта присутствует «В наличии», выводим In stock, в противном случае — out of stock.
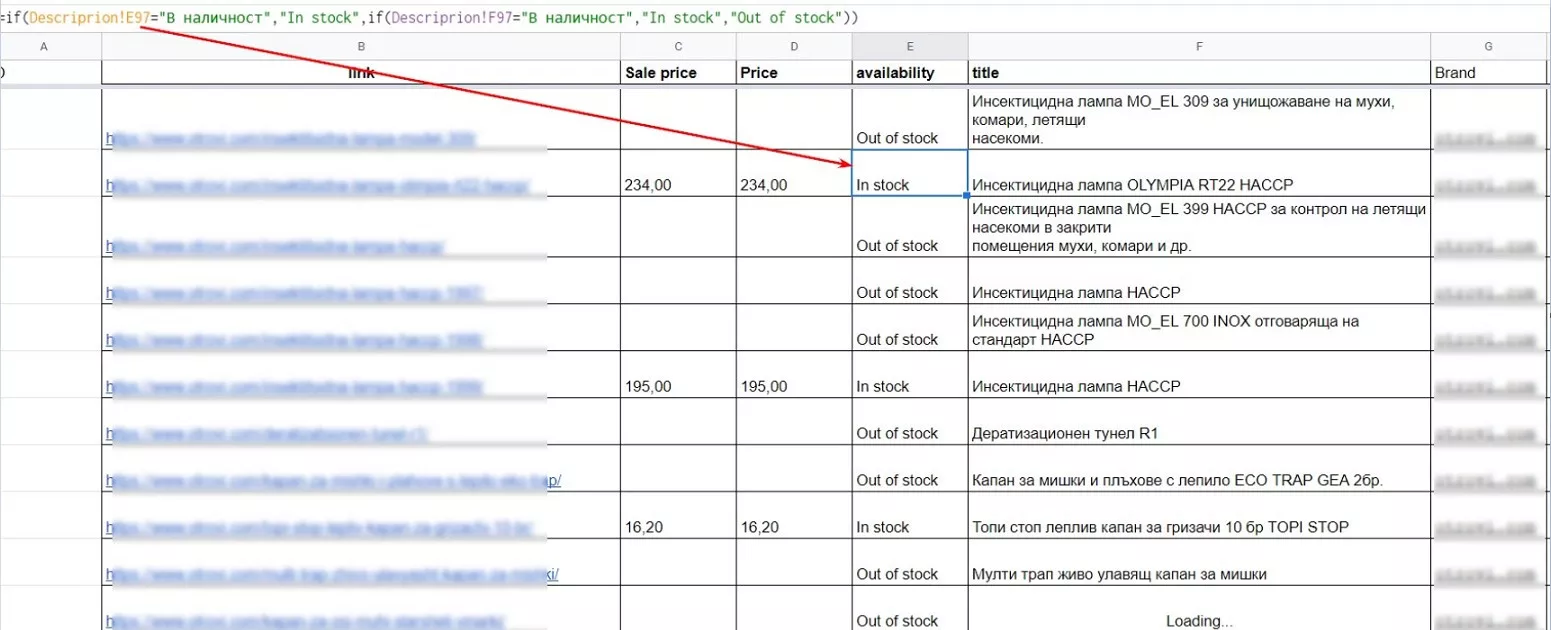
Цена
В отдельную ячейку выводим цену только, если продукт есть в наличии, для продуктов, которых нет, лучше не заморачиваться.
В нашем случае цена на сайте выводится без указания валюты, а в фиде необходимо ее указывать.
Для этого используем функцию «Concatenate» (объединение текста из разных ячеек).
Цена выводится по формуле =if(Isblank(Data2!C96),,CONCATENATE(Data2!C96,Data2!I96)) — если ячейка с ценой пустая. В таком случае выводим пустую ячейку. Если цена есть — выводим цену и добавляем идентификатор валюты (BGN).
Isblank — проверка, есть ли в ячейке число, текстовое значение, формула или нет.
{kind=link}
![]()
4. Парсинг ID продукта
В нашем случае можем идентифицировать продукт по sku.
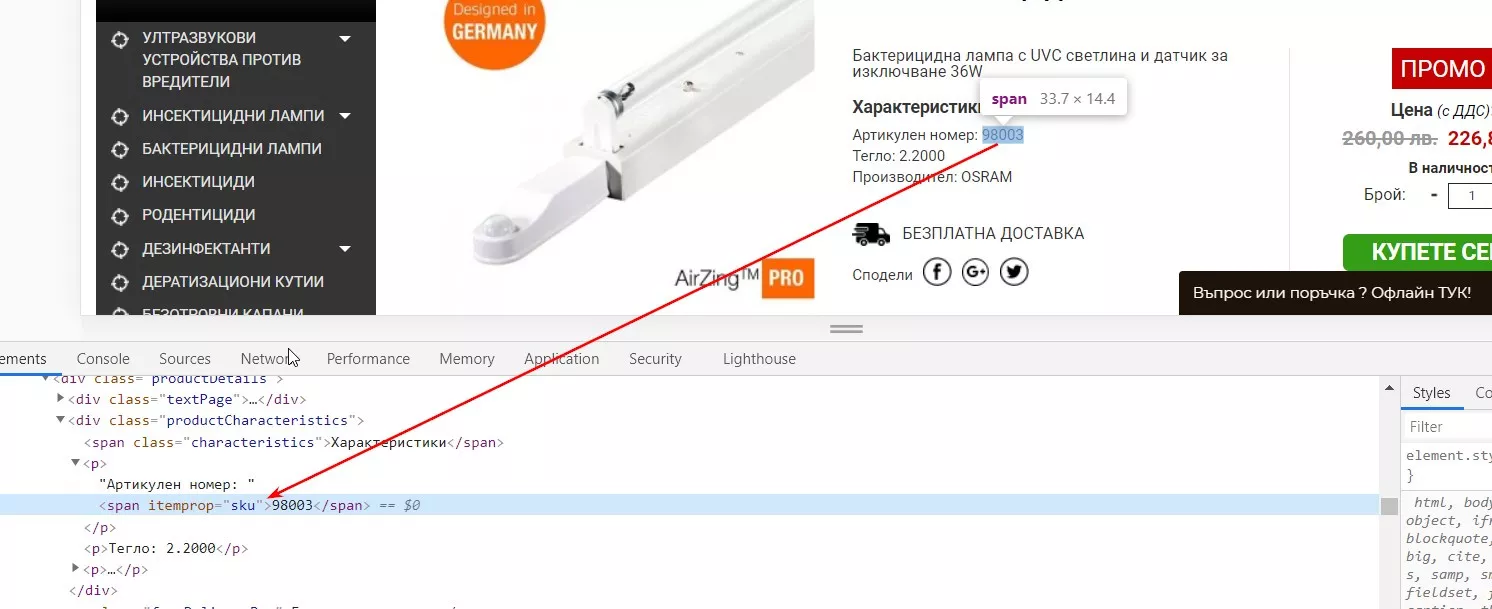
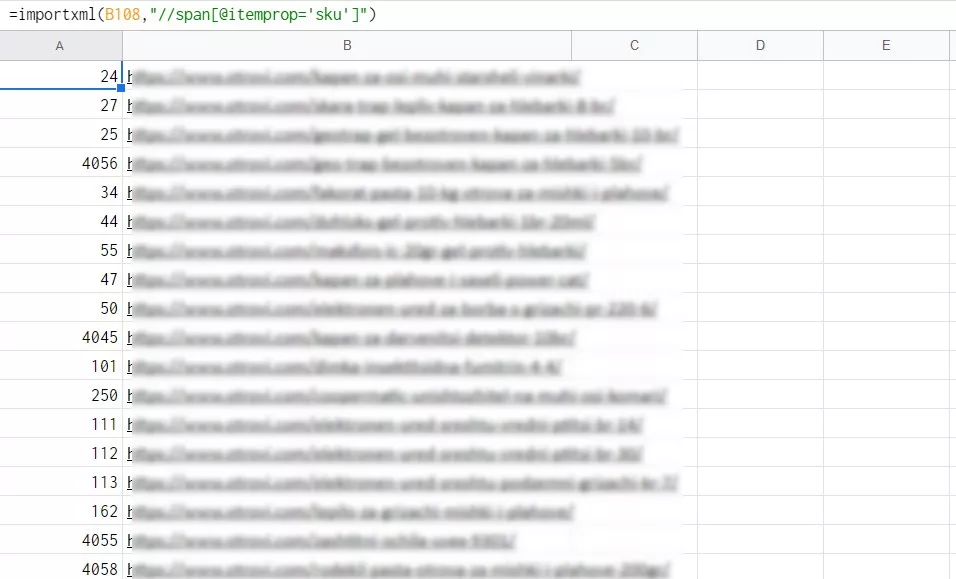
Формула для Google Таблиц: =importxml(URL,"//span[@itemprop='sku']")
Результат:
5. Парсинг URL изображений
Проще всего оказалось взять URL изображений из Open Graph разметки (для других сайтов может быть по-другому).
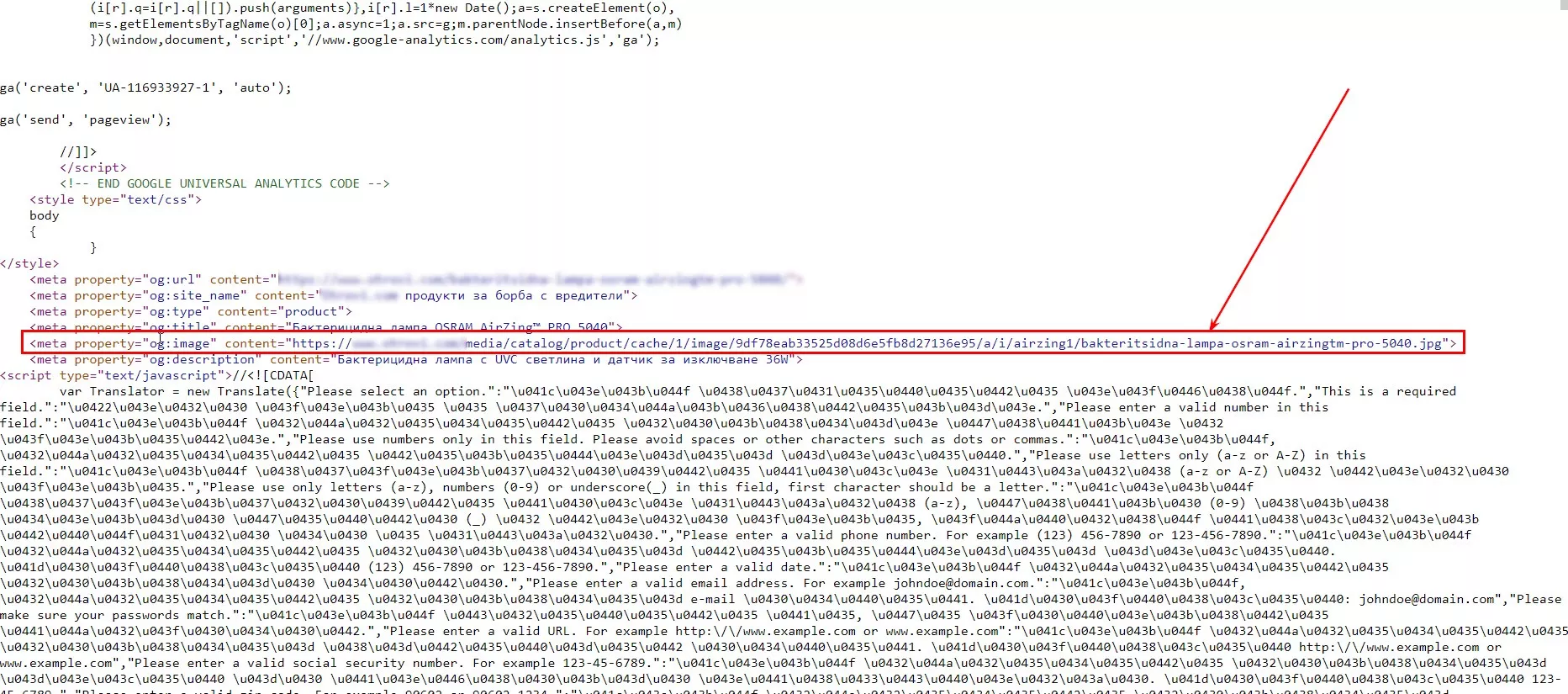
Формула
=importxml(URL,"//meta[@property='og:image']/@content")
6. Собираем данные в одной таблице
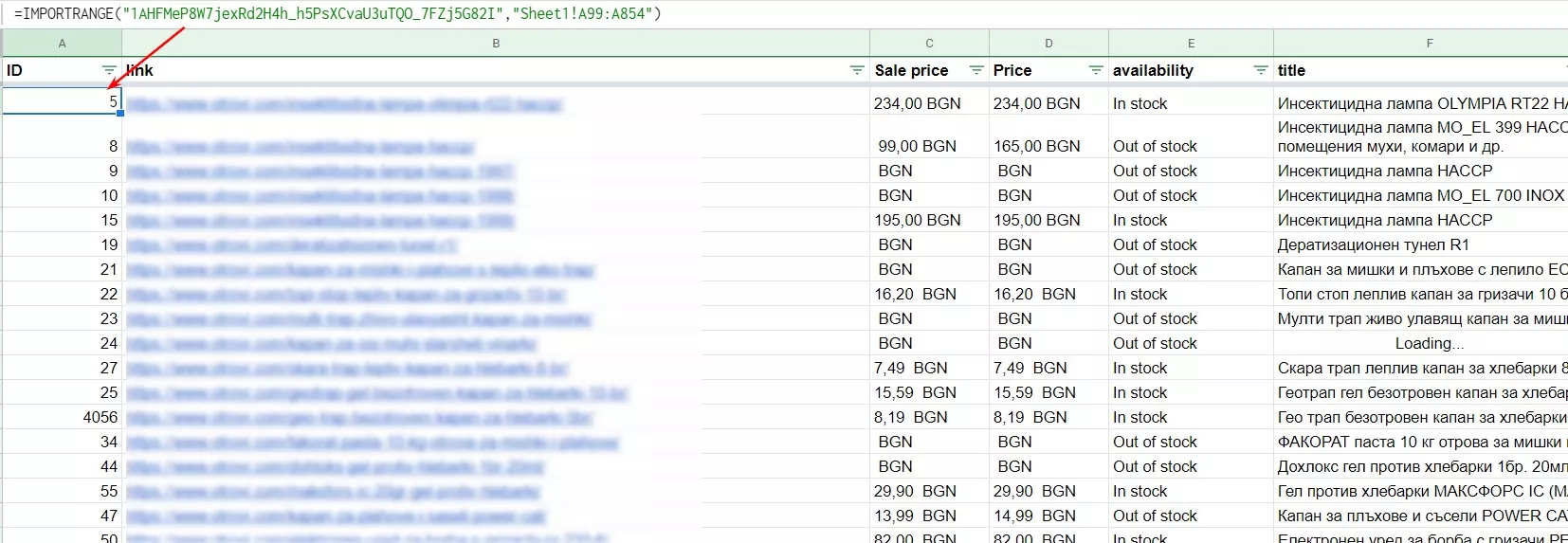
Для переноса данных из одного файла в другой в Google Таблицах используется функция «Importrange».
=IMPORTRANGE( "URL таблицы","Sheet1!C3:C853")
Sheet1!C3:C853 — расположение интересующих нас элементов.
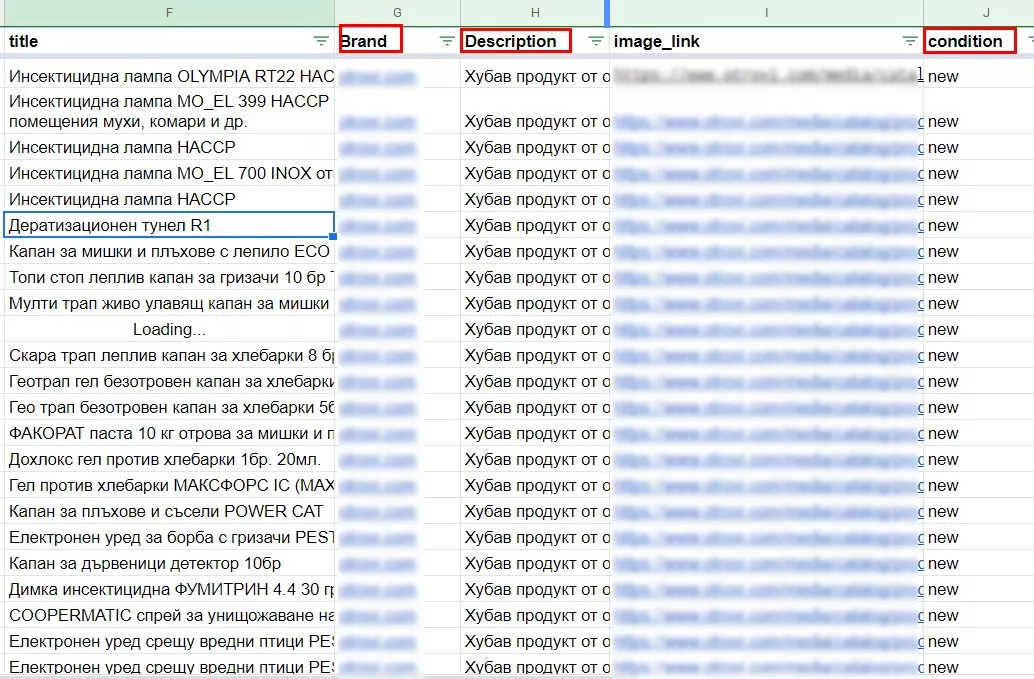
Недостающие колонки «Brand», «Description», «Condition» копируем одни и те же данные:
- brand — название сайта;
- description — общая фраза, в нашем случае «Хороший продукт от известных производителей»;
- condition — new.
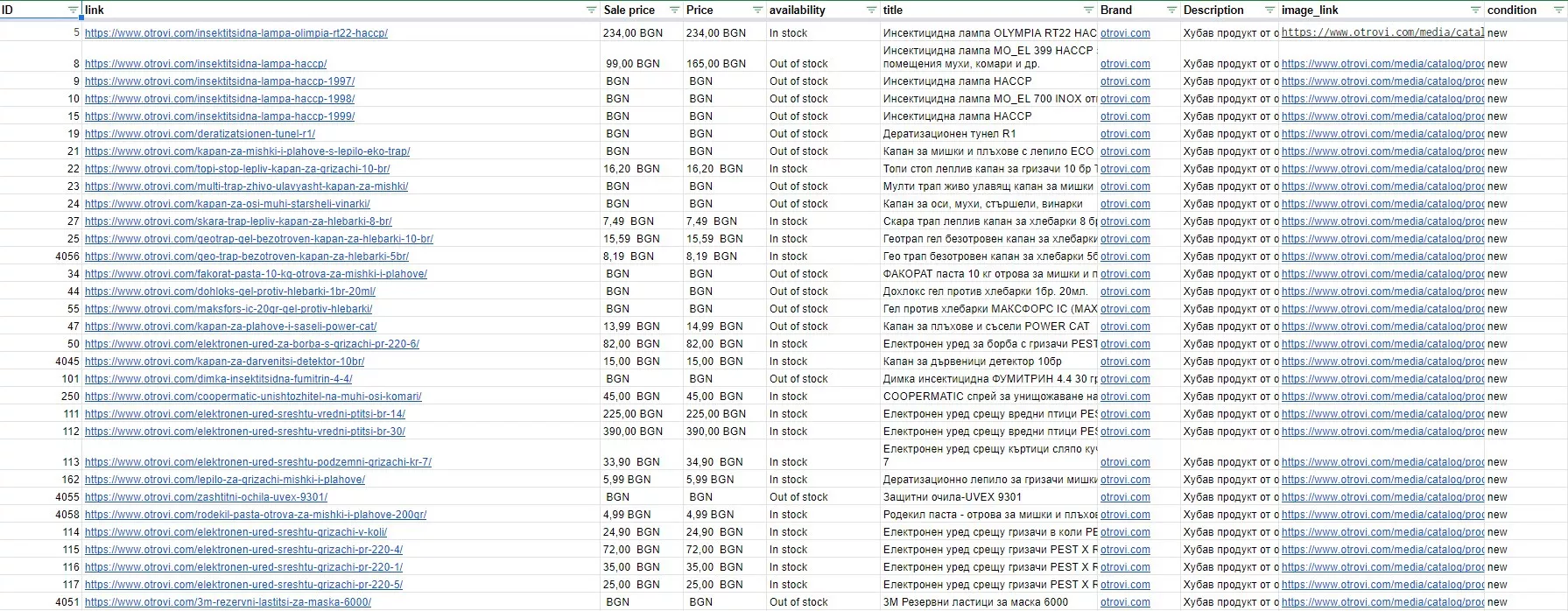
7. Фид
В результате получаем таблицу:
8. Загрузка файла в Facebook
Таблицу загружаем в фейсбук и получаем такой результат:
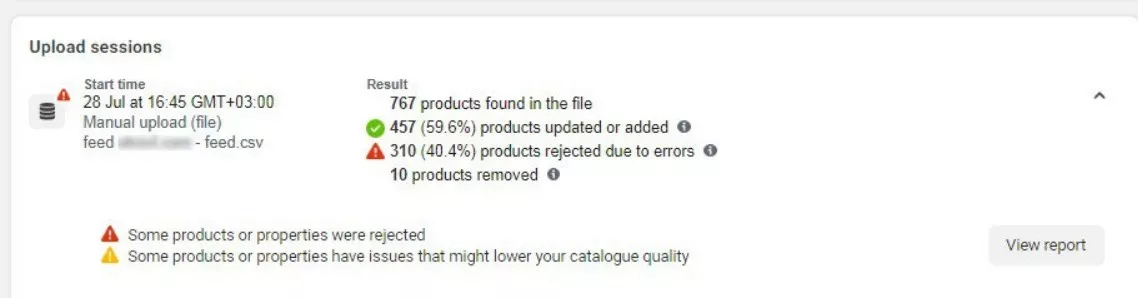
310 продуктов с пометкой отказных — это те, которых нет в наличии, так что делаем вывод, что фид работает.
Результаты работы кампании с таким фидом за четыре месяца:
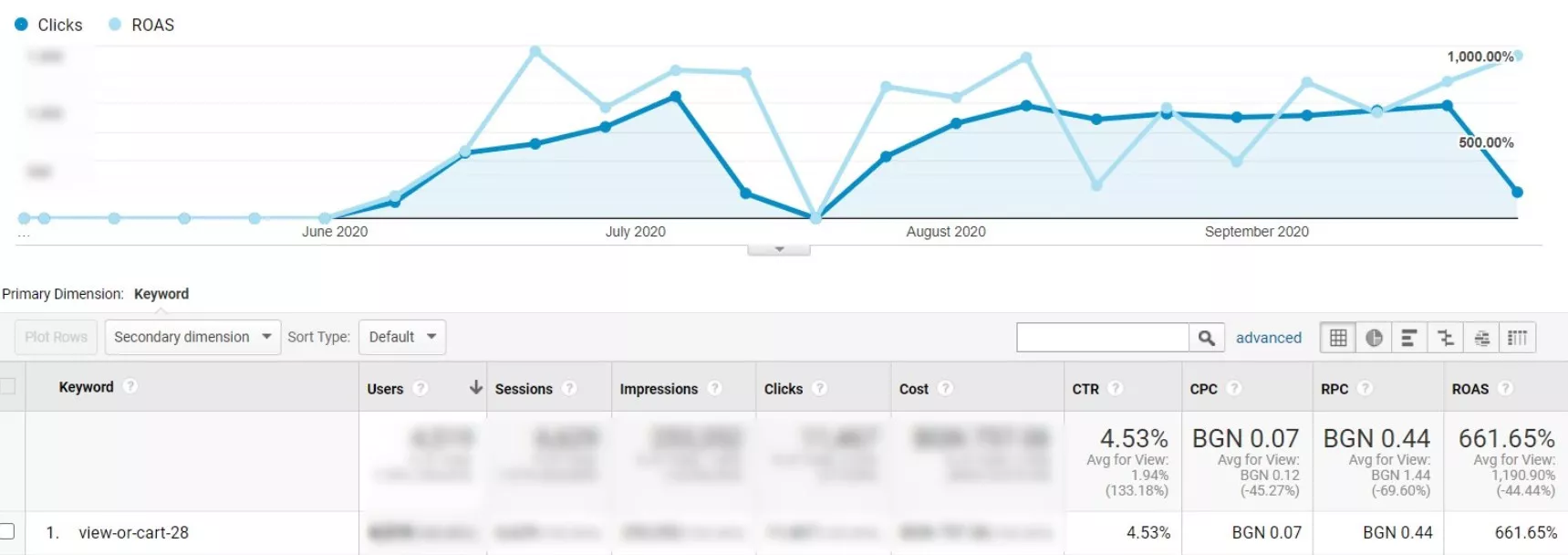
Выводы
Плюсы метода:
- экономия средств. Бесплатный аналог продуктового фида, если вы в самом начале развития интернет-магазина, инвестируете только свое время;
- безопасность. Нет необходимости давать доступы к сайту сторонним лицам;
- скорость. Возможность быстро запустить динамический ремаркетинг и возвращать пользователей на сайт;
- универсальность. Аналогично бесплатно можно парсить цены конкурентов и быть в курсе изменений ценовой политики на их сайтах.
Минусы:
- подходит только для небольших объемов данных;
- парсинг занимает много времени;
- если сайт блокирует множество запросов, могут возникать ошибки;
- при добавлении товаров или изменении URL адресов, изменения в фид придется вносить вручную.

 21
21
 4
4
 12
12
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок