Как вывести информационный сайт из-под YMYL фильтра Google — кейс maanimo.com
У многих информационных ресурсов после июньского апдейта Гугла в 2019 году начались проблемы. Трафик начал уменьшаться, и это при том, что критически важных работ не велось. Характерная особенность алгоритмического фильтра YMYL (я стал его так называть) в том, что в Google Search Console не приходит никаких уведомлений, но при этом количество ключевых слов в топ-100 неумолимо уменьшается.
Я в SEOmind проследил динамику сайтов, к аналитике которых имел доступ, и обнаружил, что фактор YMYL в алгоритме Google стал существеннее еще с мартовских обновлений, а в «June 2019 Core Update» он получил еще больше веса. Если раньше большие новостные порталы могли выезжать за счет своего траста, то теперь их начало «прибивать». Не обошли неприятности и крупные сайты, такие как CNN и BBC. У них после обновления алгоритма упал трафик на 70%, и им пришлось расстаться с частью журналистов, так как попросту не хватало денег на зарплаты.
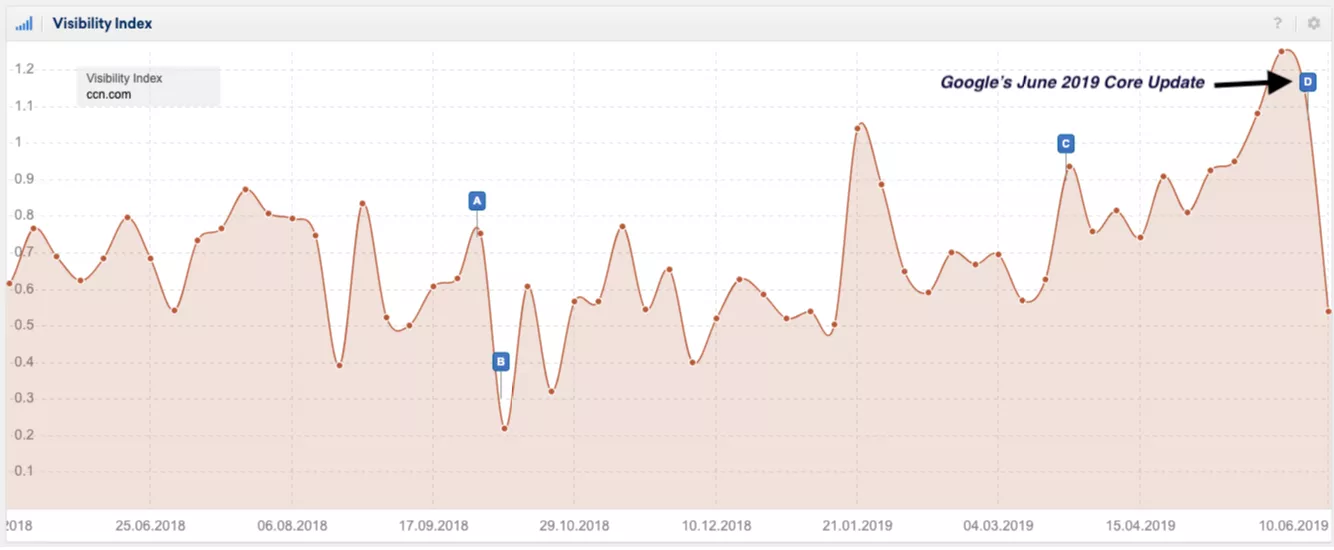
Диаграмма падения трафика на сайте BBC
В этом материале я хочу рассказать о финансово-информационном сайте maanimo.com, который также пострадал от алгоритма, и показать, какие работы я проводил, чтобы вывести его из-под YMYL фильтра.
Что такое YMYL?
Из каких именно компонентов состоит EAT, Гугл умалчивает, поэтому приходится действовать чисто логически. Нужно напомнить, что впервые алгоритмические YMYL фильтры появились после так называемого Google Medic Update в августе 2018 года. Тогда он затронул только сайты медицинской тематики. По заявлениям руководства Google, они пошли на расширение тематик, так как в интернете неправдивой информации, которая может причинять вред и становиться источником манипуляций.
Вводные данные
Maanimo — финансово-информационный портал c курсами валют, справочником финансовых и страховых компаний, витринами страховых и кредитных услуг, полезными материалами общей тематики, а также новостями на поддомене.
Сайт почувствовал недостачу EAT факторов еще при мартовском апдейте и до июньского понемногу терял трафик и видимость по профильным ключевым словам. Если честно, до последнего не верил, что проблемы именно из-за них, пока в июне трафик окончательно не подкосили новые обновления. После «June 2019 Core Update» сайт ежедневно терял в трафике по 500-1000 посетителей, пока в процентом соотношении не потерял около 70% своего трафика.
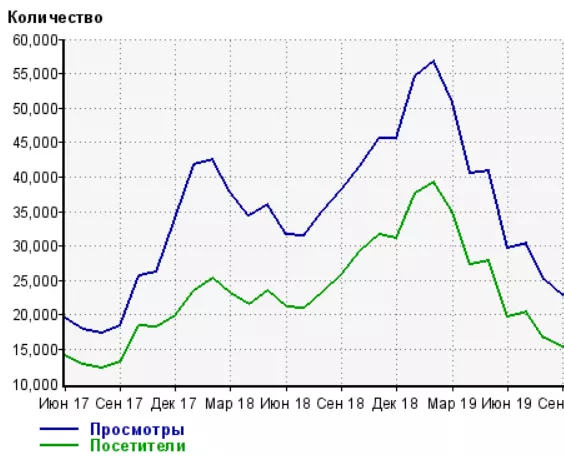
Плавный обвал трафика сайта maanimo.com
Задача
Клиент поставил задачу разобраться в особенностях нового алгоритма Гугл и исправить ситуацию. После того как я увидел что крупные новостные ресурсы начали падать по всему миру, я первым делом начал изучать материалы и кейсы по выведенным после Google Medic Update сайтам, так как понимал, что скорее всего используется такой же алгоритм оценки авторитетности. Также я изучил пострадавшие новостные ресурсы, но с первого раза не удалось определить общие факторы, из-за которых они пострадали. Со временем удалось это сделать.
Что я сделал для решения проблем с трафиком
После долгих часов и дней анализа я составил план, который пополнялся в ходе внедрения работ:
- Проверка ссылочной массы ресурса.
- Минимизация связи новостного поддомена с основным ресурсом.
- Создание авторов статей и их личной страницы на ресурсе.
- Увеличение авторитетности самих статей.
- Добавление ресурса в Google Maps.
- Указание на сайте адресов и телефонов редакции.
- Добавление в футере социальных сетей.
- Добавление страниц: о нас, политика конфиденциальности, пользовательское соглашения.
- Всплывающий попап о принятии условий пользования сайтом.
О каждом этапе проведенных работ я расскажу более подробно.
Проверка ссылочной массы сайта
В любой непонятной ситуации проверяй ссылочную массу — с этого я и начал работу. В ходе проверки выявил странные домены (при переходе они были недоступны). Располагались они в доменных зонах:
- cf;
- ga;
- gq;
- tk;
- ml и тому подобные.
Узнать, что на этих сайтах, нет возможности, так как не в веб-архиве, ни в кэше ничего от них не осталось. Первая мысль, что конкуренты проспамили сайт и он упал. Но по заявлениям руководителей Google, их алгоритм способен автоматически отклонять плохие ссылки и не учитывать их при ранжировании. Решил проверить это и все спамные сайты отклонил через Google Search Console. Подождал пару недель, никакого эффекта не получил. Значит, алгоритм действительно их не учитывал при ранжировании сайта.
После этого я второй раз начал анализировать ссылки, делая это на «максималках». Я проанализировал все ссылающиеся сайты, а их с 2008 года накопилось порядка 5000. Добавил в лист отклонения прогоны, а также домены, которые ломались под запрещенные тематики (гембл, порно, дейтинг).
Отделение новостного поддомена от сайта
Так как при новом обновлении пострадали новостные сайты, я начал задумываться о проблемах именно из-за новостей, тем более они выводились на главную страницу сайта. Думал, что Google считает ресурс новостным и поэтому его не полюбил.
На этом этапе я убрал ссылки с поддомена news.maanimo.com на главное зеркало сайта. И если ссылки с футера и сайдбара я убрал за считанные минуты, то вот со ссылками из новостей пришлось хорошо попотеть. Проблема в том, что из новостных материалов перелинковка делалась на основной домен, например, новость о каком-то банке и ссылка с названия финансового учреждения на каталог банков. Половину таких ссылок я физически удалил, а вторую половину закрыл тегом nofollow. После выполнения работ осталось только сквозное меню, которое убрать невозможно, да и смысла тоже в этом не было (Google хорошо понимает навигационные элементы).

Сквозные элементы меню
Создание сущностей авторов статей
Я создал страницы авторов для наших штатных журналистов. В каждой статье стал выводиться автор, по клику на фото можно попасть на персональную страницу и посмотреть все его материалы и информацию о нем.
Создание функционала «автор статьи»
Увеличение авторитетности материалов
Как можно придать авторитетности статье? Изначально я задумался, как я оцениваю и воспринимаю авторитетность материала. Пришел к выводу, что его улучшают исходящие ссылки на официальные сайты, официальные исследования ученых и инфографика.
К примеру, есть статья с тарифами на отопление. В ней я ссылался на официальный источник, который утверждает эти самые тарифы (в Украине это «Национальная комиссия, осуществляющая государственное регулирование в сферах энергетики и коммунальных услуг»). Также добавлял в тексты инфографику с динамикой тарифов по годам или их стоимости по регионам.
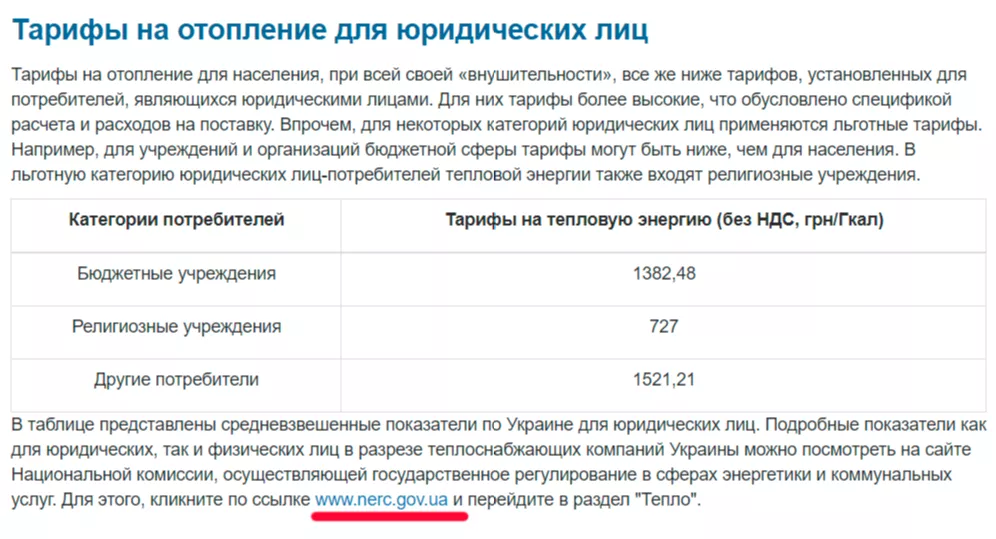
Повышаем авторитетность материала
Регистрация в Google Maps
Добавил реальный адрес редакции сайта и немного заполнил описание ресурса. По моему убеждению, это один из важных факторов в данный момент. В других проектах увидел взаимосвязь динамики получения реальных отзывов и позиций сайта.
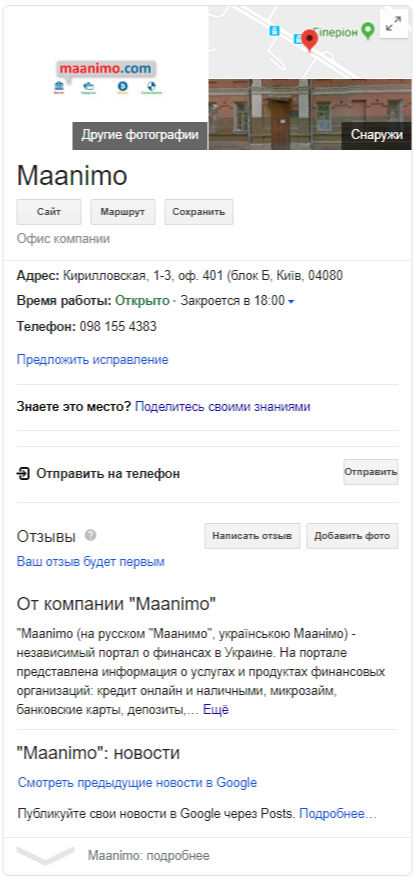
Карточка ресурса в Google Maps
Указание контактов редакции и социальных сетей
В футер добавил контактную информацию о сайте и торговой марке, также добавил ссылки на социальные сети.
Создание технических страниц
Сделал страницы и добавил их в футер:
- о нас;
- политика конфиденциальности;
- пользовательское соглашение.

Внешний вид футера после внесенных изменений
Принятие условий пользования сайтом и согласие на обработку файлов cookie
Добавил всплывающий попап о принятии условий пользования сайтом и обработке персональной информации.

Pop-up принятия условий пользования сайтом
Результаты
Спустя пару месяцев после проведения описанных работ, трафик понемногу стал возвращаться. Если посмотреть внимательно на скриншот внизу, видно, что трафик падал медленно, и так же медленно он начинает расти. Я подозреваю, что должно получиться симметричное отображение или около того.
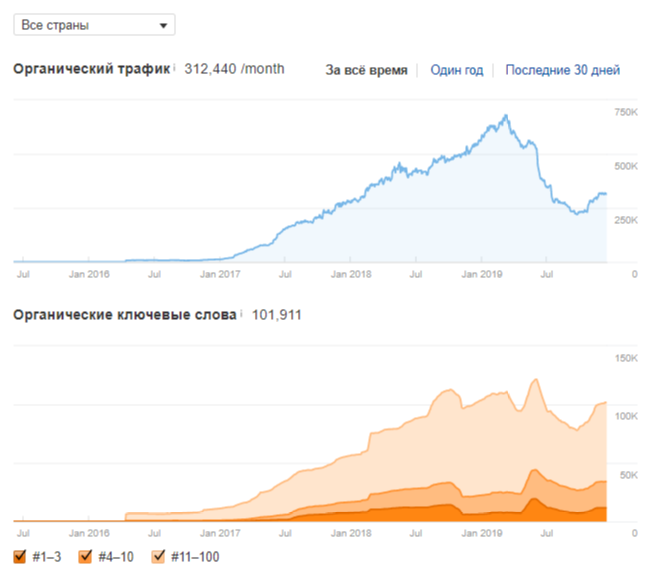
Видимость ключей ресурса до и после
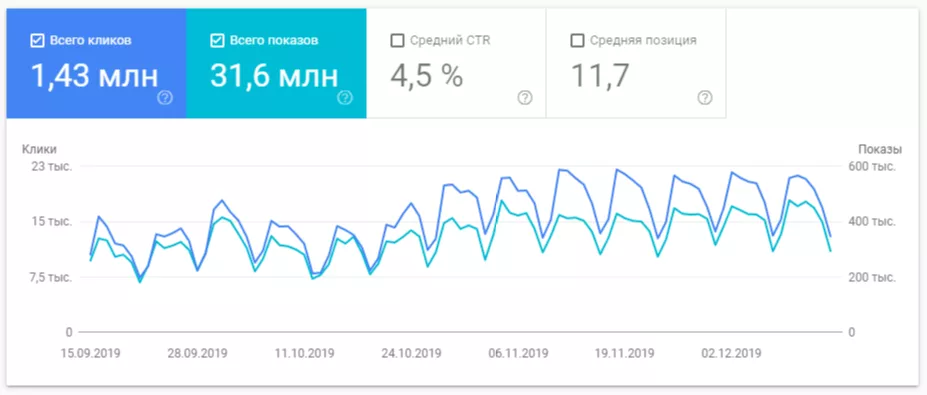
Постепенное возвращение трафика
Итоги
В этом кейсе я описал метод решения проблемы информационного сайта, который попал под июньский «June 2019 Core Update». План работ я построил на основе анализа материалов о «медицинском апдейте», анализа упавших новостных ресурсов по всему миру и логического мышления. Спустя пару месяцев после внедрения изменений трафик начал понемногу возвращаться.
Мнение авторов гостевых постов может не совпадать с позицией редакции и специалистов агентства Netpeak.

 19
19
 0
0
 13
13
Свежее
Local campaigns в Meta Ads: от создания локации до запуска кампании
Как работают локальные рекламные кампании в Meta Ads, когда их стоит использовать и как правильно настроить рекламу
Как увеличить трафик на 286% в категории ботинок: кейс магазина обуви Miraton
Вывели ключевую категорию бренда в топ-3 поиске из-за расширения структуры сайта и работы с индексацией
Что такое MCP и как AI-агент может анализировать маркетинговые отчеты вместо вас
В этой статье я покажу, как работает архитектура такого агента, и объясню, как он автоматизирует маркетинговую аналитику