Обзор Netpeak Spider 2.1: классификация ошибок, выбор параметров, новая логика работы с результатами
Чуть более месяца назад мы объявили о запуске новых продуктов Netpeak Software → Netpeak Spider 2.0 и Netpeak Checker 2.0. Если вы упустили этот пост, то всегда сможете к нему вернуться, чтобы узнать всю последовательность событий. Теперь же мы готовы представить вам новую версию продукта – Netpeak Spider 2.1. Последние несколько недель я работал в новой версии 2.1 (в режиме бета-тестирования) и, скажу откровенно, – вернуться даже на 2.0 я уже не могу: к хорошему слишком быстро привыкаешь :)
Netpeak Spider становится настоящей «машиной для SEO-оптимизации», поэтому мы дали ему кодовое название → «SEO-терминатор».
Встречайте Netpeak Spider 2.1 – программу, предназначенную для обнаружения и уничтожения ошибок внутренней оптимизации сайта. Мы хотим, чтобы 4 августа 2016 года запомнилось вам как «День краулинга».
1. Классификация ошибок
В новой версии мы реализовали определение более 50 видов ошибок, разделённых по степени важности:
- Error → критические ошибки;
- Warning → важные, но не критические;
- Notice → ошибки формата «обратите внимание».
Теперь в правой части программы расположена новая панель «Issues» – в ней отображаются все ошибки, которые были найдены во время сканирования:
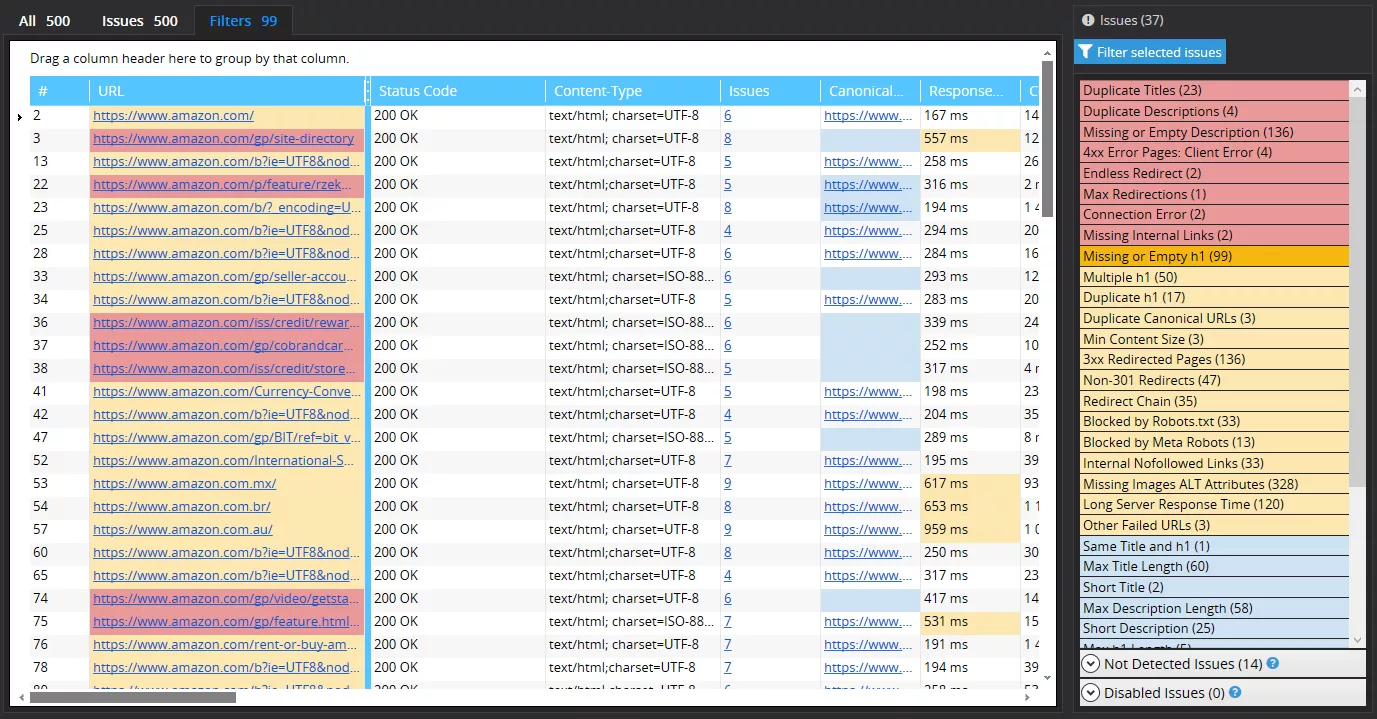
Список самих ошибок будет постоянно увеличиваться и видоизменяться, но пока что он такой:
| Ошибка | Описание |
|---|---|
| Errors | |
| Duplicate Pages* | Показывает полные дубли страниц по всему HTML-коду: в этом отчёте все URL сгруппированы по параметру Page Hash |
| Duplicate Body Content* | Показывает дубли страниц по содержимому блока <body>: в этом отчёте все URL сгруппированы по параметру Page Body Hash |
| Duplicate Titles* | Показывает страницы с дублирующимися тегами <title>: в этом отчёте все URL сгруппированы по параметру Title |
| Missing or Empty Title | Показывает страницы с отсутствующими или пустыми тегами <title> |
| Duplicate Descriptions* | Показывает страницы с дублирующимися тегами <meta name="description" />: в этом отчёте все URL сгруппированы по параметру Description |
| Missing or Empty Description | Показывает страницы с отсутствующими или пустыми тегами <meta name="description" /> |
| 4xx Error Pages: Client Error | Показывает все страницы, которые возвращают 4xx код ответа сервера |
| Redirect to 4xx Error Page | Показывает страницы, которые перенаправляют на URL с 4xx кодом ответа сервера |
| Endless Redirect | Показывает страницы, которые перенаправляют сами на себя, образуя тем самым бесконечный редирект |
| Max Redirections | Показывает страницы с более чем 4 редиректами (по умолчанию): обратите внимание, что максимальное количество редиректов можно менять в настройках сканирования на вкладке «Restrictions» |
| Connection Error | Показывает страницы, которые невозможно проанализировать из-за ошибки подключения |
| Max URL Length | Показывает страницы, у которых длина URL более 2000 символов |
| Missing Internal Links | Указывает на «висячие узлы» – страницы, на которых нет ни одной внутренней ссылки: такие страницы нарушают естественное распределение весов между страницами сайта |
| Broken Images | Показывает все изображения, которые возвращают 4xx-5xx код ответа сервера: обратите внимание, что для определения этой ошибки должен быть включён анализ изображений в настройках сканирования на вкладке «General» |
| Warnings | |
| Multiple Titles | Показывает страницы, которые содержат более одного тега <title> |
| Multiple Descriptions | Показывает страницы, которые содержат более одного тега <meta name="description" /> |
| Missing or Empty h1 | Показывает страницы с отсутствующими или пустыми заголовками h1 |
| Multiple h1 | Показывает страницы, которые содержат более одного заголовка h1 |
| Duplicate h1* | Показывает страницы с дублирующимися заголовками h1: в этом отчёте все URL сгруппированы по параметру h1 Value |
| Duplicate Canonical URLs* | Показывает страницы с дублирующимися тегами <link rel="canonical" />: в этом отчёте все URL сгруппированы по параметру Canonical URL |
| Min Content Size | Показывает страницы с менее чем 500 символов в блоке <body> (без HTML-тегов) |
| 3xx Redirected Pages | Показывает все страницы, которые возвращают перенаправление с 3xx кодом ответа сервера |
| Non-301 Redirects | Показывает страницы, которые возвращают 3xx код ответа сервера, но не 301 (permanent) редирект |
| Redirect Chain | Показывает страницы с «цепочками редиректов» (более 1 редиректа) |
| Meta Refresh Redirected | Показывает страницы, которые содержат <meta http-equiv="refresh" /> с указанием любого URL (включая адрес текущей страницы) |
| Blocked by Robots.txt | Показывает страницы, запрещённые к индексации с помощью инструкции disallow в файле robots.txt |
| Blocked by Meta Robots | Показывает страницы, запрещённые к индексации с помощью инструкции <meta name="robots" content="noindex"> в блоке <head> |
| Blocked by X-Robots-Tag | Показывает страницы, запрещённые к индексации с помощью директивы "noindex" поля X-Robots-Tag в HTTP-заголовках ответа сервера |
| Internal Nofollowed Links | Показывает страницы, содержащие внутренние ссылки с атрибутом rel="nofollow" |
| Missing Images ALT Attributes | Показывает страницы, содержащие изображения с отсутствующим или пустым атрибутом ALT: чтобы увидеть полный отчёт по данной ошибке, нажмите на кнопку «Current Table Summary», выберите 'Images' и настройте соответствующий фильтр (Include → URLs with issue → Missing Images ALT Attributes) |
| Max Image Size | Показывает все изображения, размер которых превышает 100 Кбайт: обратите внимание, что для определения этой ошибки должен быть включён анализ изображений в настройках сканирования на вкладке «General» |
| 5xx Error Pages: Server Error | Показывает все страницы, которые возвращают 5xx код ответа сервера |
| Long Server Response Time | Показывает страницы, у которых время получения первого байта от сервера превышает 500 мс |
| Other Failed URLs | Показывает страницы, которые невозможно проанализировать из-за других неизвестных ошибок, связанных с кодом ответа сервера |
| Notices | |
| Same Title and h1 | Показывает страницы, у которых заголовок h1 совпадает с содержимым тега <title> |
| Max Title Length | Показывает страницы, у которых длина тега <title> более 70 символов |
| Short Title | Показывает страницы, у которых длина тега <title> менее 10 символов |
| Max Description Length | Показывает страницы, у которых длина тега <meta name="description" /> более 160 символов |
| Short Description | Показывает страницы, у которых длина тега <meta name="description" /> менее 50 символов |
| Max h1 Length | Показывает страницы, у которых длина заголовка h1 более 65 символов |
| Max HTML Size | Показывает страницы с более чем 200 тыс. символов в блоке <body> (включая HTML-теги) |
| Max Content Size | Показывает страницы с более чем 50 тыс. символов в блоке <body> (без HTML-тегов) |
| Min Text/HTML Ratio | Показывает страницы, у которых отношение чистого текста (Content Size) ко всему контенту на странице (HTML Size) менее 10% |
| Nofollowed by Meta Robots | Показывает страницы, содержащие инструкции <meta name="robots" content="nofollow"> в блоке <head> |
| Nofollowed by X-Robots-Tag | Показывает страницы, у которых в поле X-Robots-Tag в HTTP-заголовках ответа сервера содержится директива "nofollow" |
| Missing or Empty Canonical Tag | Показывает страницы с отсутствующими или пустыми тегами <link rel="canonical" /> |
| Different Page URL and Canonical URL | Показывает страницы, у которых не совпадают URL в теге <link rel="canonical" /> с URL самой страницы |
| Max Internal Links | Показывает страницы с более чем 100 внутренних ссылок |
| Max External Links | Показывает страницы с более чем 10 внешними ссылками |
| External Nofollowed Links | Показывает страницы, содержащие внешние ссылки с атрибутом rel="nofollow" |
| Missing or Empty Robots.txt File | Показывает список URL, относящихся к отсутствующим или пустым файлам robots.txt: обратите внимание, что на разных поддоменах и протоколах (http, https) могут быть разные файлы robots.txt |
*Хорошая новость: поиск всех дубликатов в новой версии осуществляется в режиме реального времени, то есть теперь больше не надо вызывать отдельный инструмент поиска дубликатов → выбирайте необходимые параметры, запускайте сканирование и наслаждайтесь! :)
Чтобы быстро сориентироваться среди ошибок, наведите на них и через несколько секунд увидите подсказку. Будьте внимательны – все ненайденные в данный момент ошибки складируются в нижней части нового блока, в панели «Not Detected Issues»; а ошибки, определение которых вообще отключено, хранятся чуть ниже, в панели «Disabled Issues».
2. Новые параметры и возможность их выбора
В новой версии появилась возможность выбирать, какие параметры следует сканировать, а какие – нет. Это напрямую влияет на скорость сканирования и потребление оперативной памяти. А такие параметры, как Links, Redirects, Headers и Images вообще являются «тяжёлыми», что отмечено в их настройках – попробуйте их отключить, если они не нужны вам сию секунду.

Всего в Netpeak Spider 2.1 были добавлены 24 новых параметра:
| Параметр | Описание |
|---|---|
| Общие параметры | |
| Issues | Суммарное количество проблем (errors, warnings, notices), которые были найдены в рамках данного URL |
| X-Robots-Tag Instructions | Содержимое поля «X-Robots-Tag» в HTTP-заголовках ответа сервера: отвечает за инструкции для роботов поисковых систем и является аналогом тега Meta Robots в блоке <head> |
| Response Time | Время (в милисекундах) до получения первого байта от сервера |
| Content Download Time | Время (в милисекундах), за которое сервер возвращает HTML-код необходимой страницы |
| Redirect Target URL | Страница — конечная точка редиректа или цепочки редиректов, если они присутствуют |
| Content-Length | Содержимое поля «Content-Length» в HTTP-заголовках ответа сервера: отвечает за указание размера документа в байтах |
| Content-Encoding | Содержимое поля «Content-Encoding» в HTTP-заголовках ответа сервера: отвечает за указание типа сжатия документа |
| Параметры в теге <head> | |
| Meta Refresh | Содержимое тега <meta http-equiv="refresh" />: позволяет указывать, через сколько секунд перезагрузить страницу, а также, если это необходимо, на какой адрес перейти |
| Rel Next/Prev URL | Содержимое тегов <link rel="next" /> и <link rel="prev" />: позволяют указать, что эта страница — часть пагинации |
| Параметры контента | |
| h1 Value | Содержимое первого непустого заголовка h1 на странице |
| h1 Length | Длина в символах первого непустого заголовка h1 на странице |
| h2-h6 Headers | Количество, содержимое и длина заголовков h2-h6 на странице: по умолчанию эти параметры выключены, но при необходимости можно настроить их полный анализ |
| HTML Size | Количество символов в блоке <html>, включая HTML-теги |
| Content Size | Количество символов (с пробелами) в блоке <body> без HTML-тегов: проще говоря, размер текста на странице с пробелами |
| Text/HTML Ratio | Отношение чистого текста (Content Size) ко всему контенту на странице (HTML Size) в процентах |
| Characters | Количество символов (без пробелов) в блоке <body> без HTML-тегов: проще говоря, размер текста на странице без пробелов |
| Words | Количество слов в блоке <body> |
| Characters in <p> | Количество символов (без пробелов) в тегах <p> блока <body> |
| Words in <p> | Количество слов в тегах <p> блока <body> |
| Page Body Hash | Уникальный ключ содержимого блока <body>, рассчитанный по алгоритму SHA1: позволяет определять дубликаты страниц по данному параметру |
| Images | Количество изображений в тегах <img> на странице: вместе с количеством собирается информация об атрибутах ALT и исходном виде URL-ов, ведущих на изображения |
Все ошибки напрямую связаны с параметрами, в которых их можно обнаружить. Так, к примеру, чтобы включить набор ошибок тега <title>, необходимо включить параметр Title в настройках сканирования на вкладке «Parameters».
3. Новая логика работы с результатами
Здесь собралось так много пунктов, что мы вынуждены делать списки внутри списков :) Итак, поехали.
3.1. Абсолютно новая таблица с результатами
В Netpeak Spider 2.1 мы интегрировали полностью новую таблицу, которая порадует вас своими фишками:
Скорость работы
Новой таблице зачастую неважно, сколько у вас результатов – одна сотня или один миллион. Время отклика иногда поражает, а иногда заставляет задуматься: точно ли я так быстро доскроллил до нужного места? :) Короче говоря, мы очень постарались привнести в работу с программой новый «экспириенс», потому просим рассказать, как ваши ощущения.
Возможности
✔ Группировка
Теперь во всех таблицах вы сможете настроить группировку по любой колонке. Это позволит абсолютно по-новому взглянуть на результаты краулинга → к примеру, можно сгруппировать результаты по коду ответа сервера (Status Code) и посмотреть, какой код ответа на каких типах страниц у вас чаще всего встречается:

Будьте в курсе, что группировать можно не только по одной колонке, а даже по нескольким сразу. Представляете, какие инсайты вы сможете получить, если настроите правильные комбинации?!
✔ Включение/выключение колонок
Если вы нажмёте правой кнопкой мыши на название любой колонки, перед вами откроется чудо-панель: в ней вы сможете настроить отображение любой колонки, которая включена в настройках Crawling Settings на вкладке «Parameters»:

Обратите внимание, что данные настройки влияют на экспорт, таким образом в экспортный файл попадут все результаты, показ которых вы в данный момент включили.
✔ Настройка прикреплённой колонки
Теперь вы можете прикрепить любое количество колонок, а по умолчанию прикрепляется номер результата и URL. В будущем обещаем реализовать сохранение ширины колонок, их порядка и прикреплённой колонки, чтобы вам было ещё удобнее пользоваться таблицей. А пока что, увы, эти параметры сохраняются в пределах текущей сессии (то есть до первого выхода из программы).
3.2. Новые внутренние таблицы
Типы таблиц
✔ Issues info = Проблемы
Наша гордость – новая дополнительная таблица с перечнем всех проблем, которые присутствуют на странице/страницах. В ней можно фильтровать проблемы по типу, их важности и по параметру, в котором они были обнаружены:

✔ Redirects = Редиректы
Обновлённая таблица, в которой показываются все редиректы / цепочки редиректов, которые были обнаружены на странице/страницах, учитывая коды ответа сервера источника редиректа и целевой страницы:

✔ Links = Ссылки
Кардинально обновлённая таблица, которая содержит крайне полезные данные о типе ссылок, анкорах, атрибуте ALT (если изображение размещено в теге <a href="">), атрибуте REL и даже оригинальном виде URL в исходном коде:

✔ h1-h6 headers = заголовки h1-h6
Каждый тип заголовка расположен в своей «личной» таблице:

Если вам необходимо проанализировать заголовки h2-h6 – включите их анализ в настройках сканирования на вкладке «Parameters». Обратите внимание, что по умолчанию эти параметры выключены.
✔ Images = Изображения
Новая дополнительная таблица, содержащая данные о всех изображениях, найденных в тегах <img> на странице/страницах:

Новые возможности
✔ Суммарная таблица «Current Table Summary»
Ещё одна наша гордость – уникальная разработка, позволяющая открыть необходимые данные (ошибки, ссылки, редиректы, заголовки h1 или изображения) для тех страниц, которые находятся в текущей таблице.
Попробуйте отфильтровать таблицу, нажав на любой тип ошибки в панели «Issues» справа (например, 4xx Error Pages: Client Error, если они у вас есть) и после этого вызвать таблицу Current Table Summary → Incoming Links. В этом случае вы получите исчерпывающий список битых ссылок:

✔ Экспорт
Теперь в каждой внутренней таблице есть свой отдельный экспорт, который работает точно так же, как и «Export Current Table» в основных таблицах.
✔ Фильтрация
Добавлено большое количество новых параметров, а также универсальные фильтры типа «All parameters» (в этом случае фильтрация будет происходить по всем ячейкам в таблице) и «URLs with issue» (доступно для тех таблиц, где будет уместным фильтровать по виду ошибки). Также был добавлен новый тип фильтрации по параметру «Length» → теперь можно фильтровать по длине любую ячейку в таблице!
Попробуйте скомбинировать последние две фишки: пофильтровать, а потом нажать «Export» → в таком случае экспортироваться будут только отфильтрованные результаты.
✔ Типы выбора данных
Специально для вашего удобства мы внедрили 3 типа выбора данных:
- 1 URL → просто нажмите на любую ячейку и вызовите любую внутреннюю таблицу: в этом случае данные будут показываться исключительно по этому URL;
- по группе URL → попробуйте выбрать несколько URL, зажав левую кнопку мыши или используя клавиши SHIFT/CTRL, после чего вызовите любую внутреннюю таблицу: теперь вы получите данные по всем выбранным URL (в открывшейся таблице вы увидите надпись «Selection Type: Group»);
- по всем URL в текущей таблице → попробуйте нажать «Current Table Summary» и выбрать любую внутреннюю таблицу: в этом случае, вы получите данные по всем URL, которые есть в данной таблице (теперь вы увидите надпись «Selection Type: Table Summary»).
Совмещая разные способы работы с данными, вы сможете достичь небывалого комфорта и удобства от работы с таблицами. Очень ждём вашего фидбека, потому что мы очень старались!
3.3. Подсветка проблем
Если по определённому URL есть ошибка, теперь вся строка не подсвечивается красным цветом. Вместо этого подсвечивается отдельно URL (его подсветка всегда зависит от максимальной важности проблемы в данной строке) и отдельно ячейка с параметром (аналогично, подсвечивается в цвет, соответствующий максимальной важности проблемы в данной ячейке).

Мы убрали возможность кастомизировать цвета в таблице, чтобы каждый пользователь почувствовал, каким образом мы хотели донести самую важную информацию за счёт разделения всех проблем на разные типы по степени критичности.
3.4. Лучшее понимание ссылок
Теперь все ссылки делятся на чёткие типы:
- AHREF → самый распространённый тип ссылок, которые берутся из тега <a href="">
- IMG AHREF → так называемые ссылки-картинки – это изображения в теге <img>, которые находятся внутри тега <a href="">
- IMG → ссылки на картинки из тега <img>
- CSS → ссылки на файлы стилей
- JavaScript → ссылки на JS-файлы
- Canonical → ссылки, которые содержатся в теге <link rel="canonical" /> блока <head>
- Redirect → если Netpeak Spider обнаружил перенаправление на какую-либо страницу, то он отметит, что на эту страницу стоит ссылка с типом «Redirect»
- LINK → для того, чтобы активировать определение этого типа ссылок, необходимо включить анализ ссылок из тега <link> в настройках сканирования на вкладке «General»
- Meta Refresh → аналогично, для определения данного типа ссылок необходимо включить следование инструкциям Meta Refresh в настройках сканирования на вкладке «Advanced»
Кроме того, мы добавили ещё несколько параметров в каждую внутреннюю таблицу со ссылками:
- Alt → необходим для тех случаев, когда мы имеем дело со ссылками-картинками: в этом случае, анкор подобной ссылки будет являться атрибутом ALT (если он присутствует) у изображения внутри тега <a href="">
- Rel → необходим для обнаружения ссылок с rel="nofollow", однако может показывать и другие интересные значения этого атрибута (узнать подробнее)
- URL Source View → уникальная на данный момент разработка: позволяет понять, в каком виде краулер обнаружил ссылку при сканировании; удобно использовать в тех случаях, когда необходимо быстро найти нужную ссылку в исходном коде сайта

3.5. Типы отображения информации и взаимодействие с ней
Мы полностью переделали все таблицы, добавив в них новую логику: если вы видите подчёркнутые URL-ы или числа – это значит, что с ними можно взаимодействовать. К примеру, если вы нажмёте на подчёркнутый URL клавишей «пробел» или двойным нажатием левой кнопки мыши, то он откроется в вашем браузере по умолчанию.
Если вы попробуете то же самое проделать с количеством входящих ссылок (Incoming Links), то вызовете внутреннюю таблицу, которая отвечает за все входящие ссылки на данную страницу/страницы.

3.6. Другие улучшения в таблицах
Работа в режиме реального времени
Теперь не нужно останавливать краулинг, чтобы отфильтровать или экспортировать данные – работа со всеми таблицами возможна в режиме реального времени даже в момент сканирования. Например, вы можете настроить фильтрацию данных в таблице «Filters» и запустить сканирование – после этого данные, которые будут соответствовать настроенному фильтру, будут автоматически попадать в эту таблицу: это очень удобно, если вы ищите определённую информацию на сайте.
Сортировка
Мы реализовали 3 типа сортировки: по возрастанию (по умолчанию), по убыванию и «сброс сортировки», когда вы третий раз нажимаете на одну и ту же колонку.
Разграничение основных таблиц
Мы разграничили таблицы «All», «Issues» и «Filters» на отдельные, полностью независимые друг от друга таблицы. Теперь изменение порядка/ширины колонок в одной таблице не потянет за собой синхронизацию с другими таблицами.
Подсказки
Если в таблице не хватает места, чтобы показать всю информацию, вы увидите троеточие (...). Попробуйте навести на ячейку с троеточием и моментально увидите подсказку с полным значением данных внутри ячейки (заметьте, что если вы видите полностью все данные, то подсказка всплывать не будет). Это позволяет не расширять каждый раз колонки, когда вы сталкиваетесь с ситуацией, что сразу не видно всех данных.
Горячие клавиши
Мы реализовали поддержку внутренних таблиц специальными горячими клавишами: F1-F8. Попробуйте открыть контекстное меню, нажав правой кнопкой мыши в области таблицы: там вы найдёте все доступные комбинации.
4. Изменения в настройках сканирования
4.1. Новый подход к работе с настройками
Теперь настройки сканирования по умолчанию общие для всех проектов. Однако, если вы начали сканирование, то за этим проектом сохранятся отдельные настройки, а в следующий раз, когда будете переключать проекты, вам будет задаваться вопрос в стиле «Текущие настройки отличаются от тех, которые указаны в выбранном проекте. Применить последние настройки из выбранного проекта?».
Таким образом станет легче работать с индивидуальными настройками для каждого проекта, при этом так же легко будет работать с общими настройками для всех проектов, если у вас от сайта к сайту настройки не меняются.
4.2. Сравнение и автосохранение настроек
Теперь настройки сохраняются автоматически при закрытии окна или нажатии на кнопку «OK». Это позволит больше не сомневаться, применились ли настройки, которые вы изменяли в разных вкладках.
А чтобы закрыть вообще все вопросы относительно сложных настроек сканирования, мы реализовали функцию сравнения настроек → теперь, если у вас настройки по разным проектам не отличаются, то вы сможете без каких-либо всплывающих предупреждений переключаться между ними. Но как только настройки не будут совпадать, вы получите предупреждение.
4.3. Новые настройки
General
Теперь здесь вы сможете отключить краулинг всех MIME типов, кроме HTML. Это полезно, когда вы не хотите сканировать, к примеру, RSS-файлы или документы формата PDF.
Parameters
Новая вкладка, на которой расположены все параметры, которые можно сканировать, а также подсказки, откуда берутся эти параметры и какие ошибки в них могут присутствовать.
Advanced
- Добавлена настройка учёта инструкций из поля X-Robots-Tag в HTTP-заголовках ответа сервера → «Consider: X-Robots-Tag instructions»
- Изменена логика работы с Canonical → теперь при включённом учёте Canonical Link Element, Netpeak Spider учитывает значение этого поля из HTTP-заголовков ответа сервера и присваивает ему приоритет выше, чем у аналогичного значения в <head> страницы
- Добавлена настройка, позволяющая парсить все выбранные параметры у страниц, которые возвращают 4xx ошибки: будьте внимательны, по умолчанию настройка «Retrieve 4xx error pages content» отключена
5. Экспорт результатов
- Улучшен экспорт в Excel → теперь данные выгружаются с максимальной скоростью
- Добавлен экспорт в CSV → обратите внимание на этот тип выгрузки, так как он идеально подходит для большого количества данных
- Добавлена автоматическая генерация имени экспортируемого файла → теперь в имени по умолчанию сразу будет видно, в какой таблице вы работали и какой способ группировки использовали
- Убрано отдельное диалоговое окно с настройкой экспорта → это было сделано как минимум для того, чтобы сократить путь пользователя до финального результата (то есть экспортного файла) и как максимум потому, что старая функция выбора параметров для экспорта теперь перенесена в настройки параметров в Crawling Settings
6. Новая структура проектов, система хранения данных и краулинг
- Реализован абсолютно новый краулинг → теперь его скорость напрямую зависит от выбранных параметров сканирования
- Полностью изменена структура сохранения результатов → к сожалению, с обновлённой и оптимизированной структурой нам не удалось в короткие сроки провести миграцию старых проектов к новой структуре, потому мы вынуждены сообщить, что старые сохранённые результаты не смогут быть открыты в новой версии Netpeak Spider 2.1: приносим свои искренние извинения
- Реализовано сжатие для сохранённых результатов → размеры файлов в среднем уменьшились в 4 раза
- Скорость парсинга увеличена в 3 раза
- Внедрена система хранения всех «тяжёлых» данных на жёстком диске → это поможет значительно уменьшить потребление оперативной памяти и позволит с лёгкостью сканировать большие сайты
7. Другие изменения
- В силу всех вышеперечисленных изменений и полностью новой архитектуры программы, мы были вынуждены отключить подсчёт внутреннего PageRank на непродолжительный срок. Уже в ближайшем обновлении Netpeak Spider 2.1.3 ждите новый оптимизированный алгоритм расчёта внутреннего PageRank!
- Реализовано сессионное сохранение фильтров для внутренних таблиц: Issues info, Redirects, Links, h1-h6 headers, Images
- Переработан параметр Status Code, улучшена его информативность. Также теперь этот параметр поддерживает все коды, то есть теперь не будет ситуации, когда этот параметр возвращает «429 429»
- При загрузке результатов сканирования в статус-бар загружаются параметры Crawling URLs и Crawling Duration, чтобы показать, сколько URL было просканировано и за сколько времени
- Загрузка программы теперь происходит более плавно
Будущее не определено!
Именно вы можете существенно повлиять на развитие Netpeak Spider – оставляйте отзывы, задавайте любые волнующие вас вопросы или делитесь своими идеями любым удобным для вас способом:
Ну а если совсем коротко
Netpeak Spider становится более мощным, гибким и удобным. Убедитесь сами! В новой версии 2.1:
- Реализовано определение более чем 50 видов ошибок
- Внедрены 24 новых параметра и возможность их выбирать/настраивать
- Интегрирована абсолютно новая таблица с результатами
- Добавлены новые внутренние таблицы и логика работы с данными
- Оптимизированы экспорт результатов и архитектура приложения
- Изменён подход к работе с таблицами и настройками сканирования
Если вы раньше не пользовались Netpeak Spider, попробуйте наш бесплатный 14-дневный триал с полным функционалом. Если же вы уже хорошо знакомы с нашей программой, успейте на глобальное тестирование продукта, которое длится до 19 августа 2016 года.
Попробовать продукты Netpeak Software
Я горжусь тем, что мы сделали, и очень хотел бы получить ваш фидбек и советы, как можно ещё улучшить программу!

 20
20
 2
2
 0
0
Свежее
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок
Что такое активный пользователь в Google Analytics 4 и зачем его отслеживать
В этой статье я разберу, кого GA4 считает активным пользователем, по каким признакам определяет его статус и как применять этот параметр в анализе бизнес-результатов