11 функций таблиц Google в помощь SEO-специалистам
При оптимизации сайта не обойтись без обработки огромного количества данных — и чаще всего для этого используют таблицы Google. Для многих на данном этапе начинается рутинная рутина, хотя если вы знаете функции, таблицы могут практически заменить отдельные сервисы или дополнения.
Расскажу про 11 функций таблиц Google, которые упрощают работу с массивами данных.
1. Зачем нужна функция CONCATENATE
CONCATENATE ([ячейка_1];[ячейка_2]) объединяет две строки или ячейки. Это могут быть как два аргумента, так и текстовые блоки, добавленные в формулу, или закрепленные в ячейках.
В SEO эта функция, например, позволяет упростить формирование файла с некачественными доменами для инструмента Google Disavow Links Tool. Синтаксис необходимого документа предполагает формат domain:site.com. При этом также рекомендуется добавлять домены с www. Исходными данными в такой задаче, как правило, является список доменов. Например:

Вначале приводим список доменов к единому формату site.com (без www и протокола) с помощью простой замены,
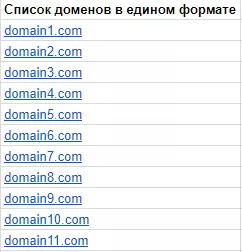
Теперь можно применить функции к готовому списку:
=CONCATENATE("domain:";[адрес_ячейки])=CONCATENATE("domain:www";[адрес_ячейки])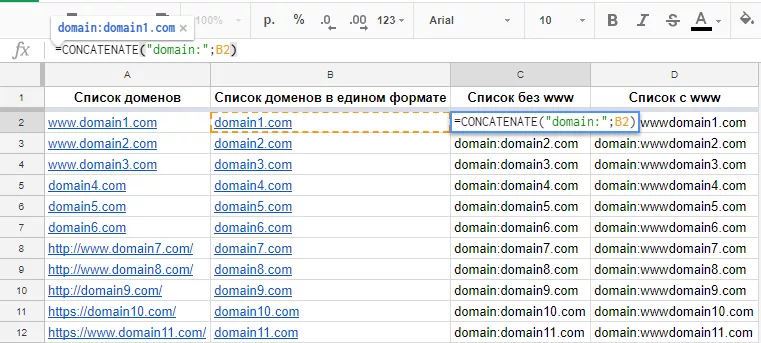
Протягиваем первую формулу в столбике С, а вторую — в столбике D. Объединив две колонки, получаем готовый список для Google Disavow Links Tool.
Разумеется, для формулы можно найти и другое применение. Например, если нет возможности настроить шаблон генерации метатегов на сайте, функция CONCATENATE поможет сгенерировать метатеги вручную. Затем их можно внедрить через админку сайта.
2. Что делает функция VLOOKUP
VLOOKUP ([запрос];[диапазон];[номер_столбца];[тип_поиска]) производит поиск по первому столбцу диапазона и возвращает значение из найденной ячейки. Если есть две таблицы с общими данными в одном из столбцов (например, URL), но эти данные в разном формате, функция позволяет их свести в одну таблицу.
Первый параметр, [запрос], определяет, по какому значению необходимо найти совпадения. В нашем примере это будет URL. Второй параметр, [диапазон] — таблица с данными, которые нужно свести к первому списку. Третий параметр [номер_столбца] — номер столбца во второй таблице, из которого необходимы значения. Важно, чтобы в данной таблице первый столбец содержал параметры [запроса]. Если необходимо точное совпадение, а именно это чаще всего и нужно, в четвертом параметре указываем «0» (логическое значение ЛОЖЬ).
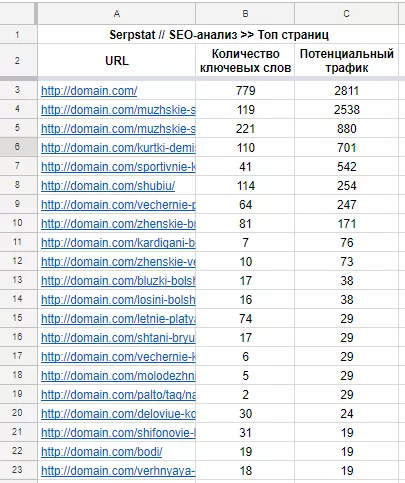
Рассмотрим функцию на примере. В Serpstat существует отчет по страницам с наибольшим потенциальным трафиком, то есть страницам, оптимизация которых может принести лучший результат. Для работы с такими страницами важно понимать их текущий уровень оптимизации, например, объем ссылочной массы, метатеги. Даже если остановиться только на этих параметрах, у нас уже три разных отчета. Их необходимо привести к одному знаменателю. Итак, выгружаем все три таблицы, используя отчеты Serpstat «SEO-анализ — ТОП страниц», «Анализ ссылок — Страницы-лидеры» и сервис Netpeak Spider для выгрузки метатегов.
Таблицу Serpstat «SEO–анализ — ТОП страниц» сортируем по столбцу «Потенциальный трафик»:
Для всех URL данной таблицы сканируем и получаем метатеги:
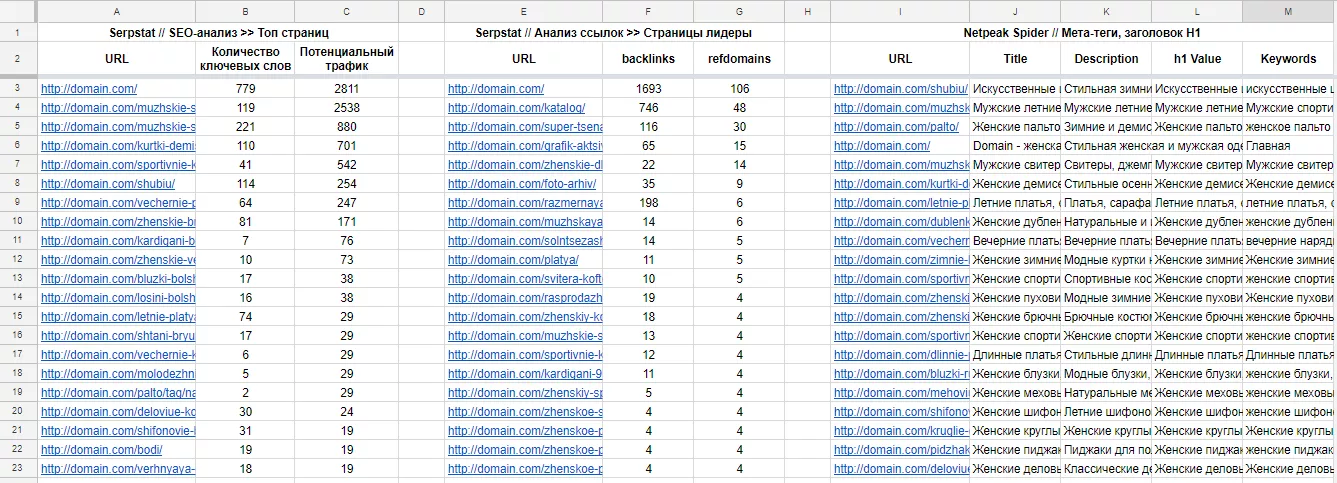
Для сводной таблицы нам нужны следующие данные:
- URL;
- потенциальный трафик;
- обратные ссылки (backlinks);
- ссылающиеся домены (refdomains);
- заголовок Н1;
- Title, Description и Keywords.
Переносим в новую таблицу все URL и потенциальным трафик, а далее настраиваем функцию VLOOKUP:
- в качестве первого аргумента указываем URL (для которого ищем данные) из нашей новой сводной таблицы;
- вторым аргументом будет диапазон всей таблицы, данные из которой нужны — не забываем закрепить ее, чтобы при «растягивании» функции данные не поплыли;
- третий аргумент — номер столбика из выбранного диапазона, в котором располагаются искомые данные.
Проделываем эти настройки для всех столбцов-параметров:
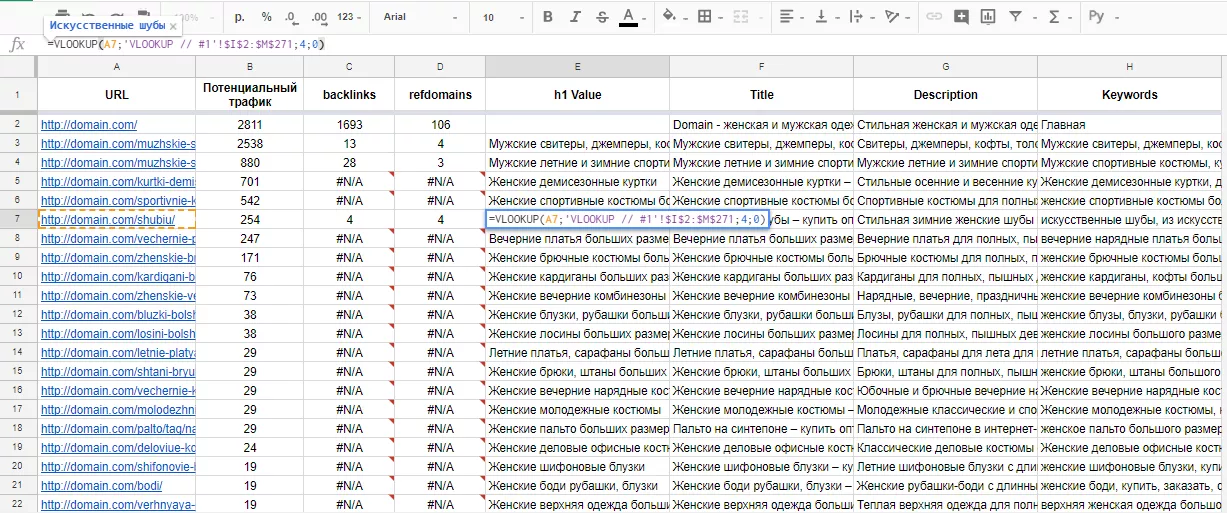
Если функция возвращает #N/A, значит в таблице с данными отсутствует URL, по которому осуществлялся поиск. Логично, что у нас не все URL имеют обратные ссылки. Анализируем и делаем выводы.
3. Как использовать функцию UNIQUE
UNIQUE ([диапазон]) возвращает уникальные строки в указанном диапазоне, убирая дубликаты. Строки возвращаются в том же порядке, в котором они располагаются в диапазоне.
Например, есть список URL, которые отдают 404 ошибку и для которых нужно настроить редирект на новые URL. Если список выгружен из одного источника и в наличии порядка 20-50 URL, никакой проблемы не возникает. А вот если список из разных источников и в наличии более 1000 URL-адресов, велика вероятность, что в списке присутствуют дубли. Выбрать уникальные адреса легко с помощью функции UNIQUE:
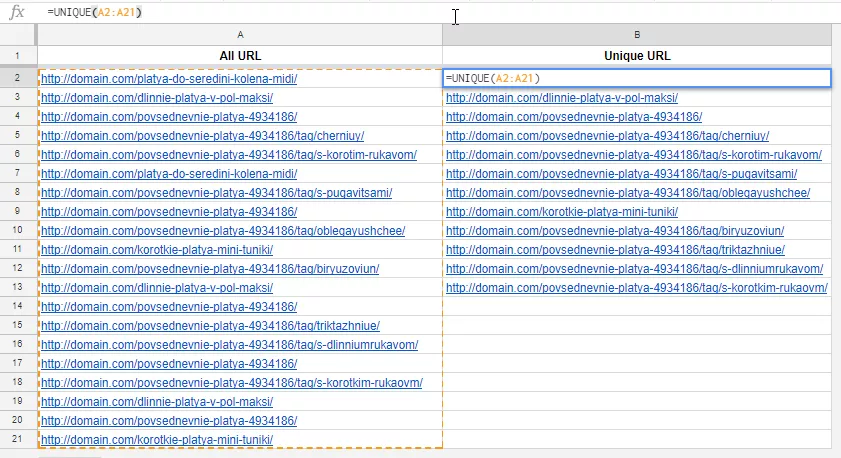
4. Зачем нужна функция COUNTIF
COUNTIF ([диапазон]; [критерий]) подсчитывает количество ячеек в диапазоне, соответствующих заданному условию.
Пример практического применения функции — поиск потенциальных доноров среди сайтов–конкурентов (которые, конечно, ранжируются лучше). Используем Serpstat для поиска конкурентов и выгружаем актуальный ссылочный профиль из Ahrefs или Serpstat (отчет «Анализ обратных ссылок») по каждому из конкурентов:
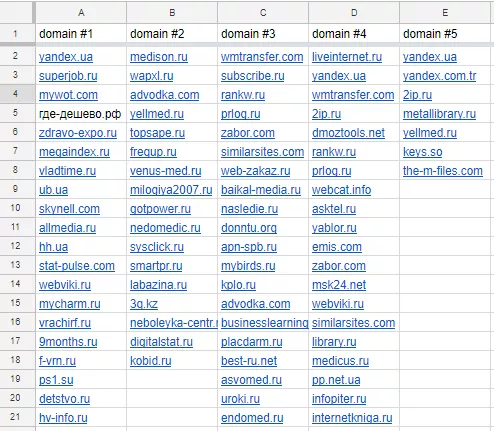
Формируем все домены в единый столбец (в нашем случае G). В соседнем столбце H применяем функцию UNIQUE. В следующем столбце применяем COUNTIF, где первый аргумент — закрепленный диапазон всех доноров всех конкурентов, а второй — ячейка с уникальным донором. Таким образом получаем таблицу «донор — количество вхождений среди группы конкурентов»:
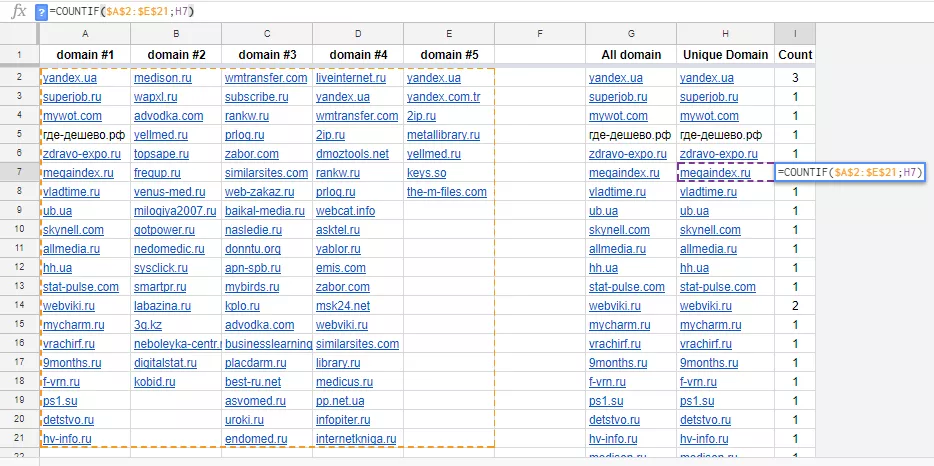
Отсортировав данную таблицу по убыванию, получаем рабочий список с потенциальными донорами для проекта. Важно учитывать:
- анализируемые ссылочные профили конкурентов должны быть актуальными (снятие ссылок никто не отменял);
- конкуренты должны хорошо ранжироваться, иначе существует вероятность собрать список мусорных доноров, которые в лучшем случае никак не повлияют на сайт;
- среди таких площадок 100% будут сайты-анализаторы, мусорные каталоги. Их, к сожалению, придется чистить вручную;
- зависит от задачи, но, скорее всего, не понадобятся доноры, с которых уже есть ссылки, поэтому их следует исключить в процессе работы (пригодится простая функция IF).
5. В чем польза функции LEN
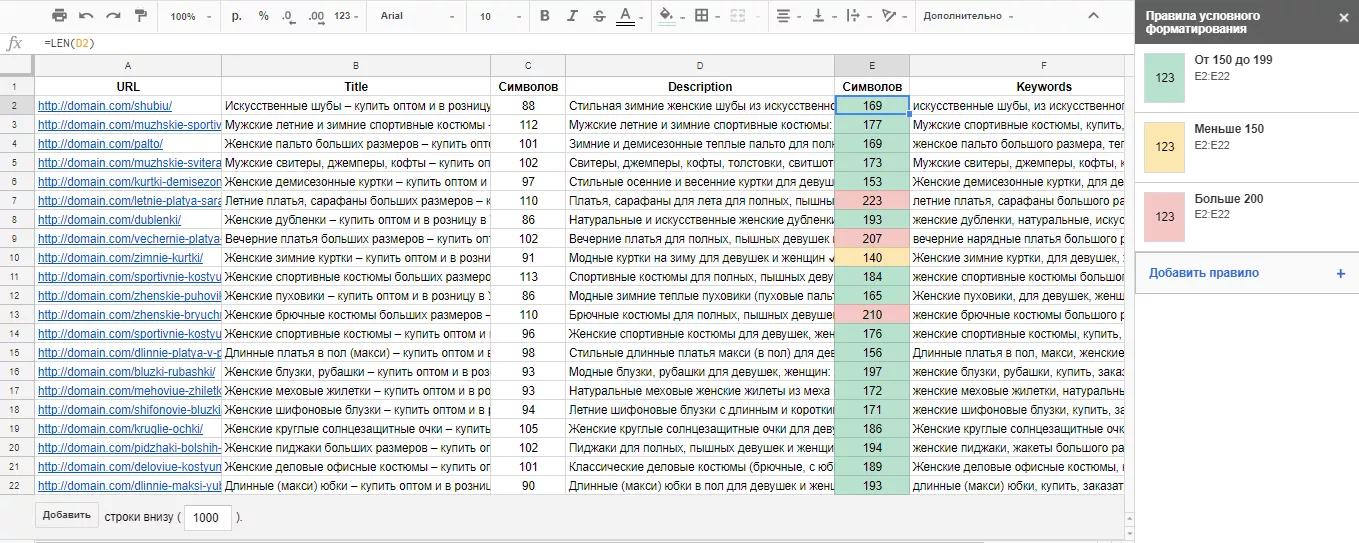
LEN ([ячейка_с_текстом]) вычисляет длину строки с учетом пробелов. Функция будет полезна при формировании метатегов (проверка превышения максимально рекомендуемой длины тега) или текстового контента на страницах сайта.
Итак, берем выгрузку URL с метаданными. Рядом с каждым тегом добавляем столбец с функций LEN. Применив к столбцам условное форматирование, можем выделить те теги, где есть превышение по рекомендуемой длине.
6. Что делают функции IMPORTHTML, IMPORTXML
IMPORTHTML ("[URL_страницы]";"[тег_из_которого_нужно_извлечь_данные]"; [порядковый_номер_тега_на_странице]) импортирует данные из таблицы или списка на странице.
IMPORTXML ("[URL_страницы]";"xpath_запрос") — импорт данных из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
Например, можно выгрузить заголовки Н1 со страниц (xpath-запрос в данном примере — //*/h1) или количество просмотров (xpath запрос //*/span[@class='icon–views']):

7. Зачем нужна функция SPLIT (или Data — Text to Columns)
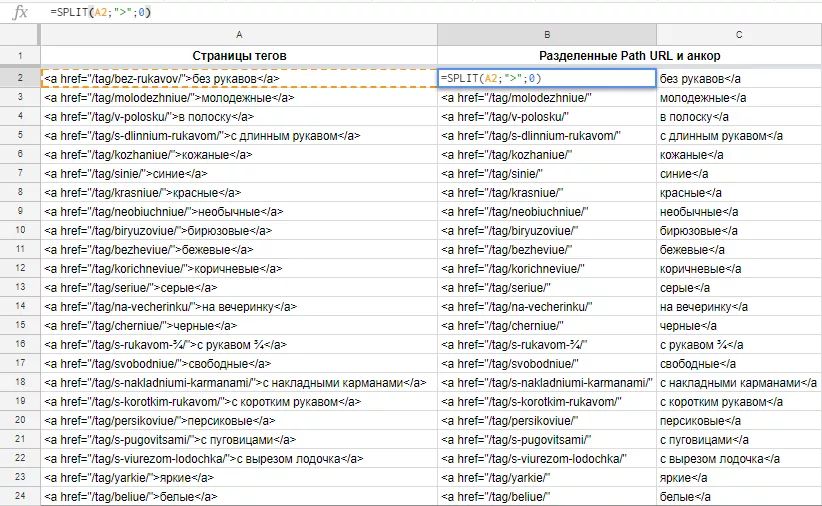
SPLIT ([ячейка_с_данными]; "[разделитель]"; TRUE) выводит текст, разделенный определенными символами, в разные ячейки.
Крайне полезная функция, которая позволяет разбивать различные массивы на составляющие по отдельным столбцам. В качестве разделителя можно использовать любой символ (слеш, точку, запятую) или набор символов. Если указать в качестве третьего аргумента TRUE или 1, в качестве разделителя будет считаться каждый из указанных символов. Если указать FALSE или 0, разделителем будет считается вся комбинация символов.
Допустим, в категориях есть теги. Задача — выгрузить все теги и проверить их на дубли, адекватность и упущенные теги. Для этого нужны:
- список категорий (URL), где есть теги;
- path-запрос, который позволит вытянуть со страниц URL и анкоры тегов;
- сервис для сканирования (например, Netpeak Spider).
Часть итоговой таблицы (URL и анкоры страниц тегов):

Работать с такими ячейками сложно: нельзя просканировать на наличие метатегов или товаров, проверить код ответа страниц тегов. Для решения указанных подзадач необходимы полные URL страниц тегов.
Вначале применяем к каждой ячейке формулу SPLIT, в качестве разделителя можно указать символ «>», который поделит таблицу на две части. Затем с помощью регулярных выражений или функций сможем привести оба столбца к нужному виду.
Данную формулу можно заменить опцией таблиц Google: Data > Text to Columns (Данные > Разделить на колонки). Перед применением следует выделить весь диапазон, к которому нужно применить функционал.
8. Как использовать функции REGEXMATCH, REGEXEXTRACT, REGEXREPLACE
Функции REGEXMATCH, REGEXEXTRACT, REGEXREPLACE позволяют использовать регулярные выражений для проверки, извлечения или замены части текста ячейки.
REGEXEXTRACT ([ячейка];"[регулярное_выражение]") извлекает определенную часть текста, соответствующую регулярному выражению.
В качестве практического примера воспользуемся последней таблицей. Из части кода с URL извлечем относительный URL, регулярное выражение для этого примера — “/.*/”. Усложним задачу, добавив CONCATENATE и получив таким образом готовый абсолютный URL:
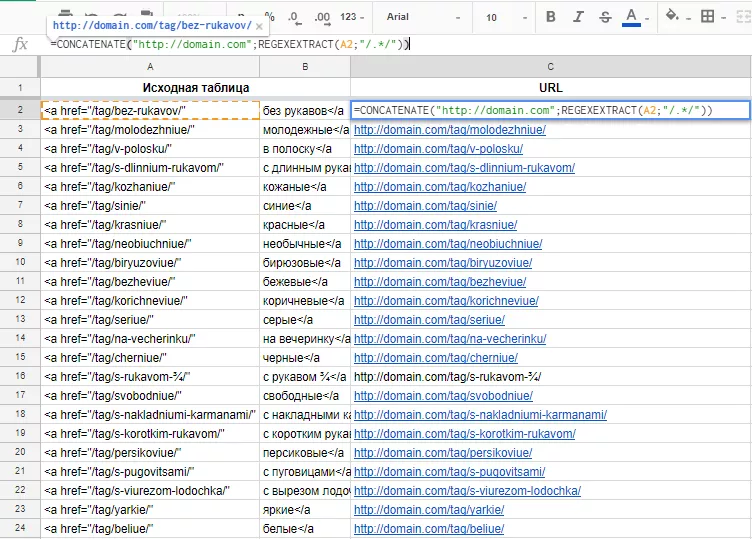
В данном примере задача упрощена — все теги первого уровня, без привязки к категории.
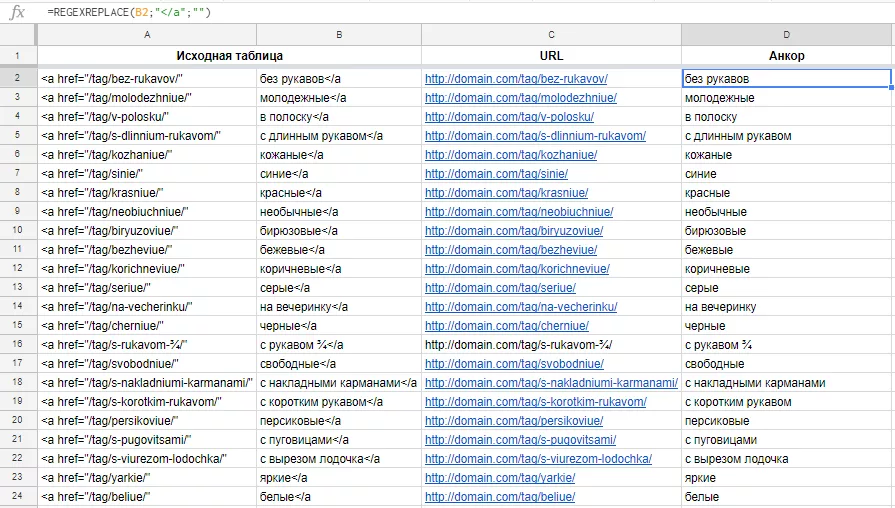
Теперь необходимо получить «чистые» анкоры данных страниц тегов — зовем на помощь функцию REGEXREPLACE.
REGEXREPLACE ([ячейка]; "[символы_которые_нужно_заменить]"; "[символы_на_котторые_выполняется_замена]") заменяет часть строки на другой текст с помощью регулярного выражения.
В данном случае регулярное выражение не потребуется. Необходимо найти символы «</a» и удалить их:
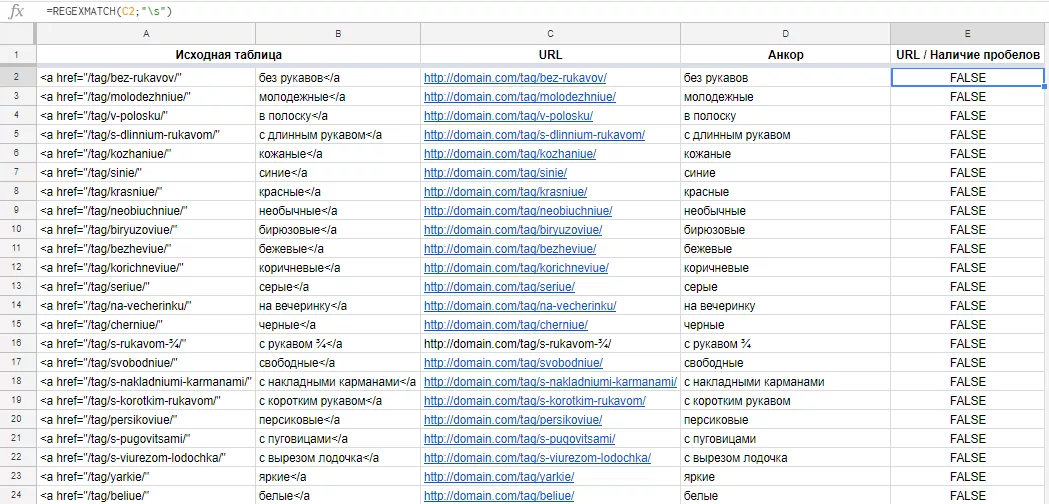
REGEXMATCH ([ячейка];"[регулярное_выражение]") проверяет, соответствует ли текст регулярному выражению.
Проверим, чтобы в URL-адресах не было пробелов:
9. Что такое функция SPARKLINE
SPARKLINE ([диапазон_данных];[параметры_графика]) создает миниатюрную
Данную функцию удобно использовать при анализе сезонности для наглядного отображения высокого и низкого сезона в нише.
Например, для категории «УЗИ аппараты» берем запросы «узи аппараты», «купить узи аппараты», «узи сканеры», «купить узи сканеры» (в идеальном варианте следует взять все релевантные категории запросы). Вытягиваем из Планировщика ключевых запросов от Google Рекламы частотности данных фраз по месяцам. Затем суммируем частотность данных фраз в разрезе каждого месяца. В отдельном столбце задаем функцию SPARKLINE, в качестве диапазона данных задаем суммарную частотность по месяцам, а для параметров графика формируем отдельную таблицу (рекомендуем на отдельном листе).
В нашем примере диаграмма столбчатая, цвет столбиков — зеленый, а максимальное значение — голубое. Не забывайте фиксировать параметры графика:
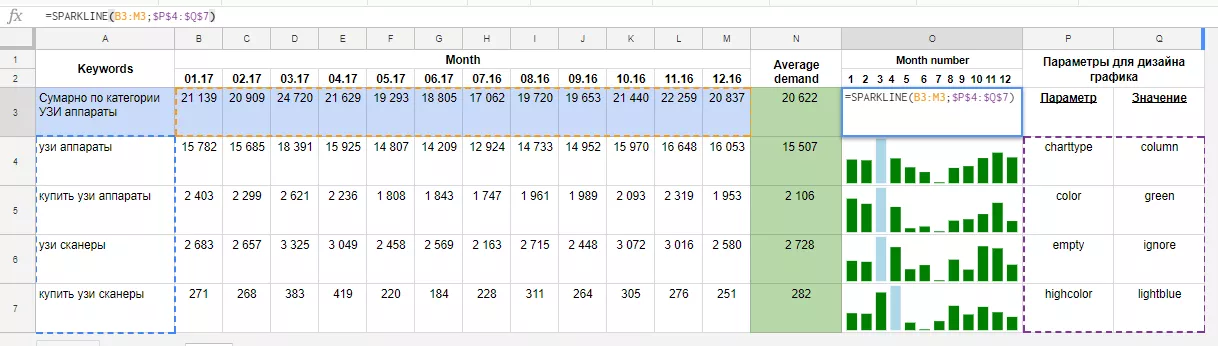
На графике видно, что высокий сезон для данной категории — март-апрель и ноябрь, а низкий — с мая по июль.
10. Зачем нужна функция IMPORTRANGE
IMPORTRANGE ("[Ссылка_на_электронную_таблицу]";"[Название_листа]![Диапазон_ячеек]") – импортирует диапазон ячеек из одной электронной таблицы в другую.
Функция полезна, если по проекту выгружаются данные из разных источников и в итоге их нужно свести в одну таблицу.
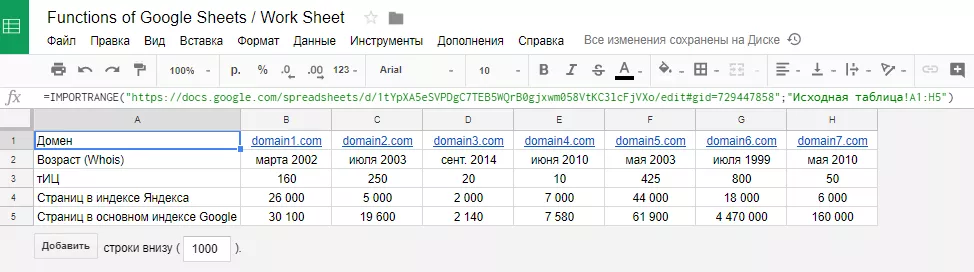
Когда необходимо выгрузить на один лист несколько таблиц из разных файлов, важно сразу резервировать место для каждой из них, чтобы они не накладывались друг на друга.
11. Как использовать функцию TRANSPOSE
TRANSPOSE ([массив_данных]) меняет местами строки и столбцы в массиве ячеек.
Если необходимо проанализировать несколько конкурентов, их удобно сравнивать между собой, когда домены будут распределены по столбцам, а параметры — по строкам.
![]()
При пробивке параметров (рекомендуем использовать Netpeak Checker) итоговая таблица будет обратной: домены — по строкам, параметры по столбцам. Если вы цените время, вручную форматировать таблицу плохой вариант. Лучше собрать все необходимые данные и в свободном пространстве (новом листе) ввести формулу TRANSPOSE, аргументом которой будет вся таблица с исходными данными:
![]()
Выводы
Функции таблиц Google можно использовать для:
- формирования файла с некачественными доменами;
- проверки URL и поиска адресов, которые отдают 404 ошибку;
- поиска потенциальных доноров среди конкурентов;
- формирования метатегов или текстового контента;
- проверки тегов на дубли;
- анализа сезонности и отображения высокого/низкого сезона в нише.
Кстати, для четкости в таблицах Google не забывайте использовать дополнение Crop Sheet, которое в один клик удаляет лишние (пустые) столбцы и строки в файле.
Функции SPARKLINE, IMPORTXML, IMPORTHTML, IMPORTRANGE работают исключительно в таблицах Google, у остальных есть русские аналоги, которые можно использовать в Microsoft Excel. Подробнее об этих функциях можно прочитать в справке Google.
Кто дочитал, ловите бонус — Google Docs с примерами функций.
Я рассказала только про некоторые варианты применения функций — не ограничивайте фантазию и делитесь своими примерами в комментариях.

 102
102
 0
0
 37
37
По теме
Как отслеживать события с помощью Google Analytics 4: подробный мануал
Как настраивать события, какими они бывают, как работают — подробный гайд по настройке и работе с событиями
Всемогущая функция Query — подробное руководство
Как пользоваться одной из самых важных функций Google Таблиц — подробное руководство по Query
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок