Сбор семантики предполагает большие объемы поисковых фраз и затраты времени на их сбор, чистку от нерелевантных запросов и структурирование результатов работы. На этапе чистки, как правило, начинается монотонная ручная работа. Возможности таблиц Google позволяют ускорить и облегчить обработку данных без дополнительных платных инструментов.
В этой статье я расскажу о 12 функциях таблиц Google, актуальных для семантистов. В конце вы найдете таблицу с примерами использования описанных функций.
1. Функция Unique
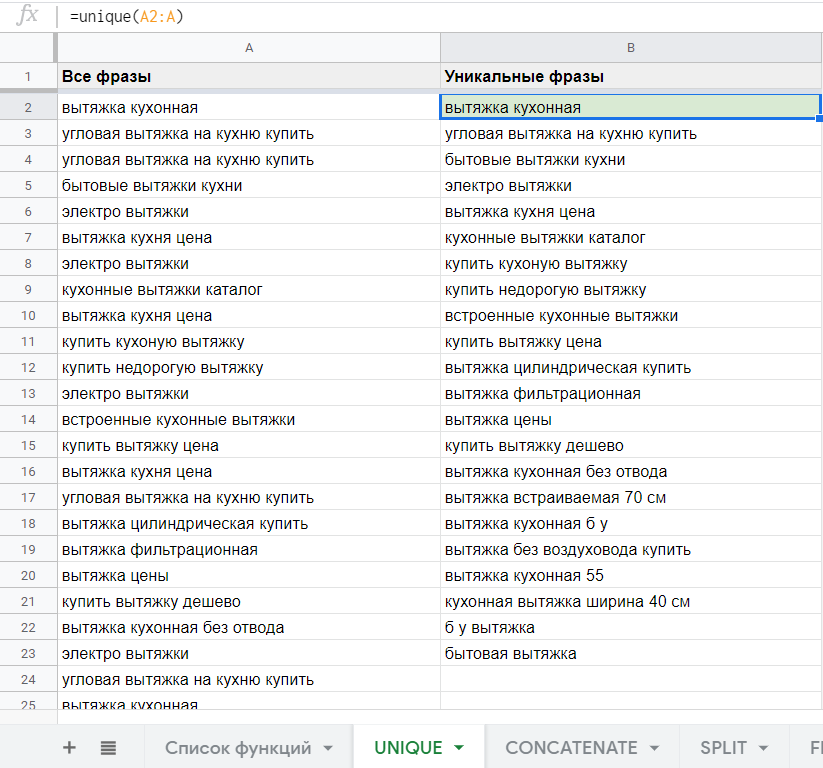
Функция Unique (диапазон) возвращает уникальные строки в указанном диапазоне, удаляя дубликаты. Строки возвращаются в том же порядке, в котором они расположены в диапазоне.
Семантисту эта функция позволяет удалить дубли поисковых фраз при сборе семантики из разных источников (планировщик ключевых слов Google, Serpstat, поисковые подсказки).
С помощью этой функции можно решить такую задачу: в колонке A есть список фраз агрегированных из разных сервисов статистики, и, скорее всего, некоторые поисковые запросы повторяются. Укажем в качестве аргумента диапазон с исходными фразами и получим список уникальных фраз.
{kind=link}
2. Функция Concatenate
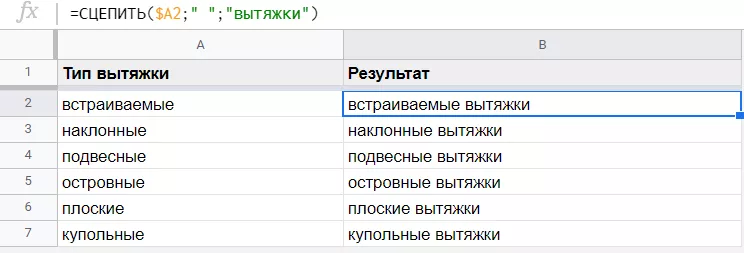
Concatenate (строка1, [строка2, ...]) объединяет две строки.
При работе с
Маркерный запрос (базовый запрос, маркер) — запрос, наиболее точно описывающий страницу сайта (главную страницу, категорию, подкатегорию). По маркерам происходит сбор расширений поисковых фраз для страницы.
Рассмотрим составление маркерных запросов на примере вытяжек для кухни. В качестве исходных данных есть тип вытяжки в столбце A. В аргументах функции укажем адрес ячейки с типом вытяжки, пропишем в английских двойных кавычках слово «вытяжки» и не забудем про пробел «" "» между ними, иначе получится сплошной текст.
{kind=link}
3. Функция Split
Функция Split (текст; разделитель; [тип_разделителя]; [удаление_пустых_ячеек]) выводит текст, разделенный определенными символами, в разные ячейки. Разделителем может выступать запятая, точка с запятой, точка, пробел и любой другой пользовательский разделитель. При этом указанный символ разделителя возвращен не будет.
С помощью функции Split можно получить список названий страниц сайта, разделив URL адреса на элементы по колонкам.
В колонке A есть список URL адресов категорий, для которых нужен сбор семантики. Чтобы получить названия категорий для удобной дальнейшей работы, пропишем в качестве первого аргумента функции ячейку с URL адресом категории, а в качестве разделителя — символ слеш и протянем функцию вниз.
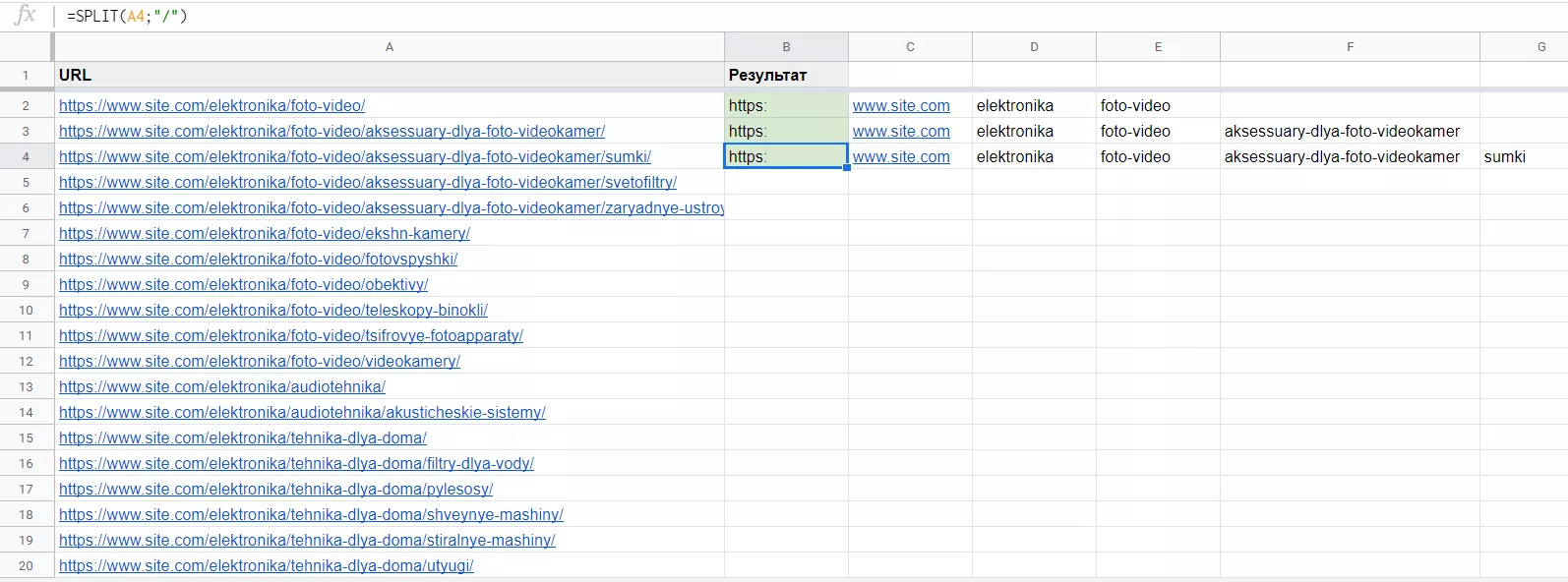
В колонках F и D мы получили названия категорий, которые можно использовать для дальнейшей работы с семантикой. К примеру, транслитерировать в кириллицу с помощью этого конвертера и использовать в качестве названий групп в программе Key Collector или для оформления кластеров.
4. Функция ArrayFormula
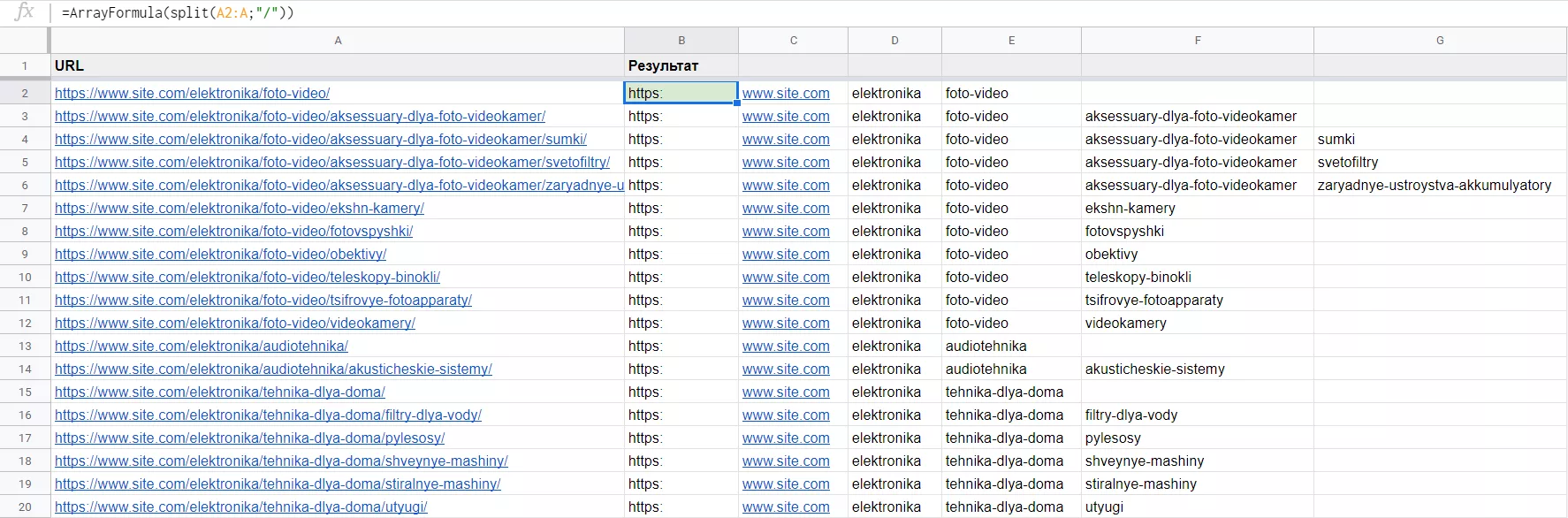
ArrayFormula (формула_массива) — это операционная функция, которая упрощает работу с другими функциями. С использованием ArrayFormula нет необходимости протягивать функцию вручную, чтобы она применилась ко всем ячейкам.
Рассмотрим на примере функции Split из предыдущего пункта и соединим её с функцией ArrayFormula. Отличие в том, что первым аргументом в функции Split надо указать не одну ячейку с URL адресом категории, а диапазон ячеек. Заключим нашу формулу массива Split в ArrayFormula, как на скриншоте, и в один клик получим такой же результат, как в предыдущем пункте.
5. Функция FILTER
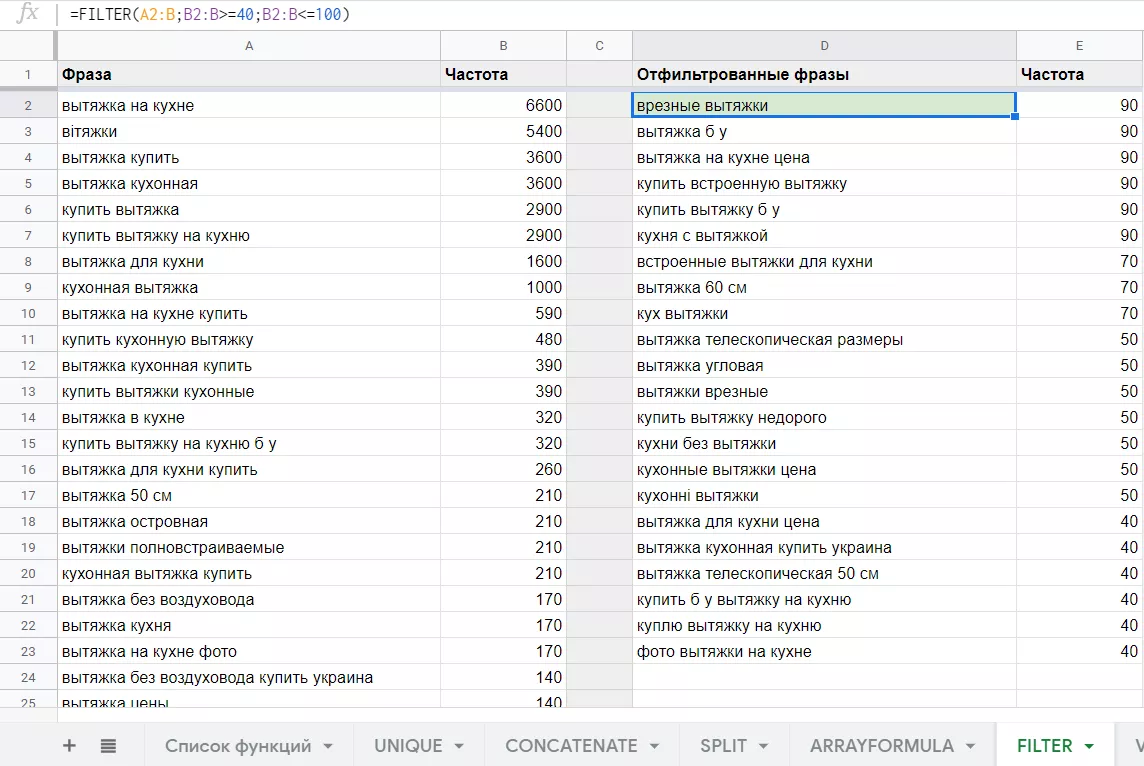
Filter (диапазон; условие1; [условие2; ...]) отображает только соответствующие заданным условиям строки или столбцы в диапазоне. При работе с семантикой эта функция понадобится, например, для того, чтобы отфильтровать поисковые запросы с нужной частотой.
Исходные данные: фразы в колонке A и их частота в колонке B. Необходимо отфильтровать фразы с частотой меньше или равно 100 и больше или равно 40. Пропишем диапазон столбцов с фразами и частотой первым аргументом функции. Второй и третий аргументы — условия для частоты из колонки B, указанные при помощи знаков «больше», «меньше» и «равно». В результате получим список фраз с заданной частотой.
6. Функция Vlookup
Vlookup (запрос; диапазон; индекс; [отсортировано]) производит поиск по первому столбцу диапазона и возвращает значение из найденной ячейки в другом столбце таблицы. То есть функция сопоставляет данные, производя поиск по вертикали.
Эту функцию можно использовать, например, чтобы подставить частоты из разных источников к одному списку семантики. В столбцах A и D — одинаковые поисковые запросы в разном порядке; в столбце B — статистика из сервиса Ahrefs; в столбце E — частота из планировщика ключевых слов Google. Вернем в колонку F частоту Ahrefs из столбца B, чтобы было удобнее работать с поисковыми фразами и их статистикой.
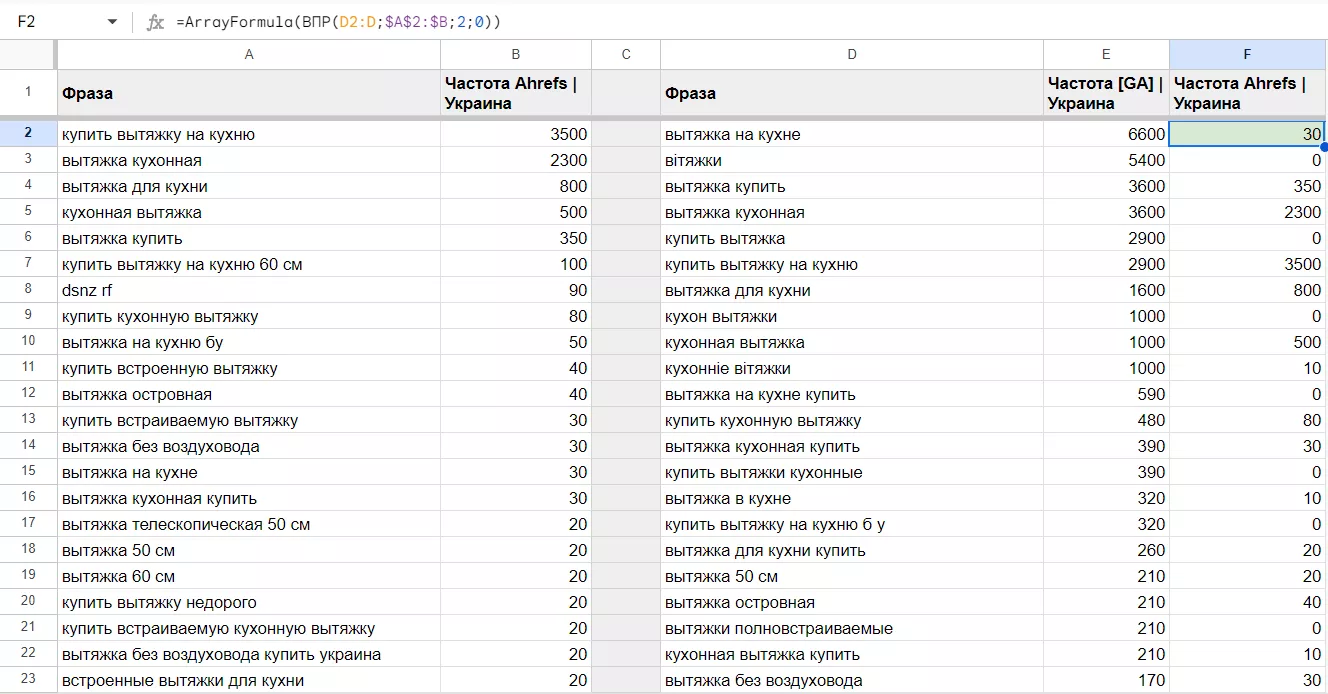
Для этого пропишем аргументы функции:
- первый аргумент — запрос, который мы будем искать. В данном случае — фразы из колонки D;
=ArrayFormula(ВПР(D2:D;$A$2:$B;2;0))
- второй аргумент — диапазон, в первом столбце которого мы будем искать фразы. У нас это закрепленный диапазон A:B;
=ArrayFormula(ВПР(D2:D;$A$2:$B;2;0))
- третий аргумент — индекс, то есть номер столбца от начала диапазона, из которого нужно взять искомое значение. Так как нам надо подставить частоты Ahrefs, в нашей функции индекс — это второй столбец из диапазона A:B;
=ArrayFormula(ВПР(D2:D;$A$2:$B;2;0))
- четвертый аргумент — отсортировано — зависит от того, отсортированы ли данные в первой колонке из указанного диапазона и какое совпадение надо вернуть — точное или ближайшее к запрошенному. Рекомендуется указывать значение FALSE, или 0.
=ArrayFormula(ВПР(D2:D;$A$2:$B;2;0))
Затем воспользуемся функцией ARRAYFORMULA, которую мы рассмотрели выше, и получим в колонке F статистику Ahrefs.
=ArrayFormula(ВПР(D2:D;$A$2:$B;2;0))
7. Функция importxml
Importxml (ссылка; запрос_xpath) импортирует данные из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML с помощью языка запросов XPath.
У функции широкий спектр применения. При работе с семантикой её можно использовать, например, для импорта мета-тегов title, description и заголовков h1-h6 с сайтов конкурентов для составления маркерных запросов.
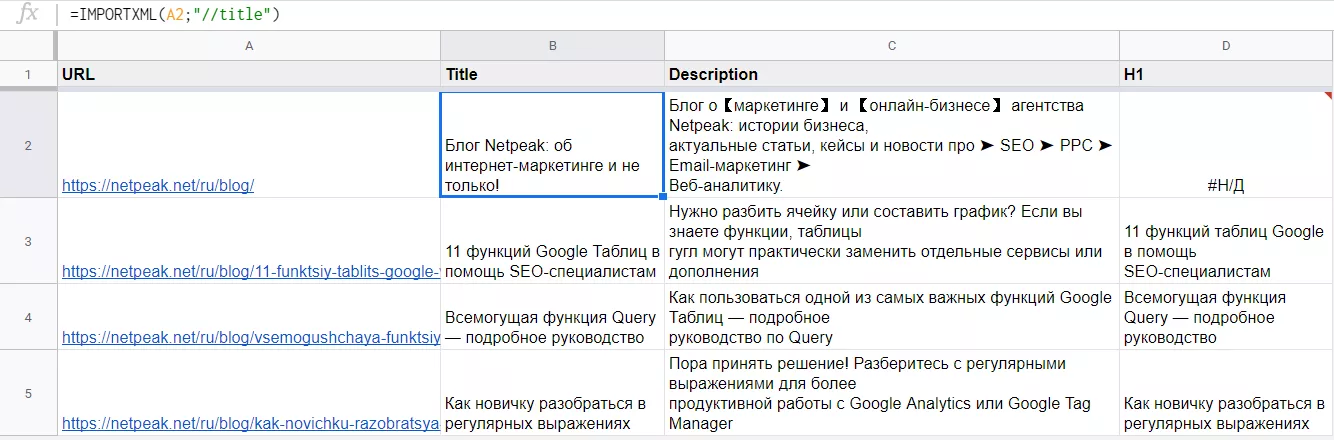
В столбце A есть список URL-адресов. Импортируем мета-теги:
- в столбец B мета-тег title, для этого пропишем в функции запрос XPath: "//title";
- в колонку C выгрузим description: "//meta[@name='description']/@content";
- в столбец D — заголовок h1: "//h1".
8. Функция Googletranslate
Googletranslate (текст; [язык_оригинала; язык_перевода]) переводит текст с одного языка на другой.
Функция актуальна при работе с семантикой по мультиязычным проектам.
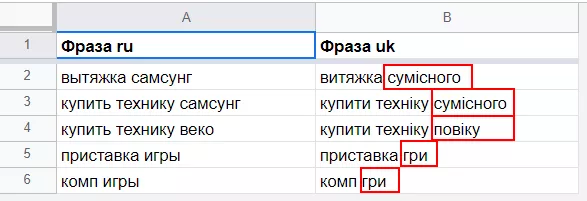
Переведем русскоязычную семантику из столбца A на украинский язык. Первым аргументом укажем ячейку, содержащую текст, который надо перевести. Второй и третий аргументы — код языка оригинала и языка перевода соответственно. Если вы не знаете язык оригинала текста, его можно определить автоматически, указав «auto» в качестве аргумента.
Для отображения результата во всех ячейках столбца функцию Googletranslate надо протянуть вручную, так как она не взаимодействует с функцией ArrayFormula, описанной выше.

Обязательно проверьте результат работы функции, особенно если исходная семантика содержит имена собственные, так как машинный перевод не совершенен. Вот некоторые примеры некорректного перевода:
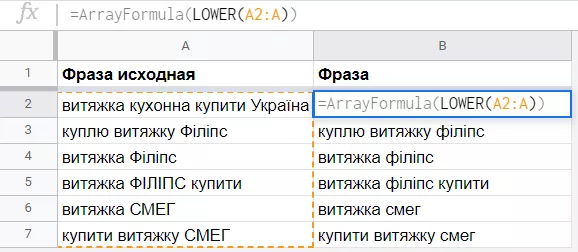
9. Функция lower
Lower (текст) переводит символы заданной строки в нижний регистр.
Эта функция может пригодиться после использования функции Googletranslate, которая иногда преобразовывает в верхний регистр первые буквы слов или некоторые слова целиком, чаще всего топонимы и названия брендов. В аргументе функции Lower укажем диапазон ячеек, содержащий текст, который необходимо перевести в нижний регистр, и воспользуемся ArrayFormula, чтобы не протягивать функцию вручную.
10. Функция DETECTLANGUAGE
Detectlanguage (текст_или_диапазон) определяет язык текста.
Функция понадобится для работы с семантикой по мультиязычным проектам и регионам. Например, при парсинге русскоязычной семантики по региону «Украина» собираются фразы и на украинском языке. Чтобы их определить, можно воспользоваться функцией Detectlanguage, которая вернет код языка.
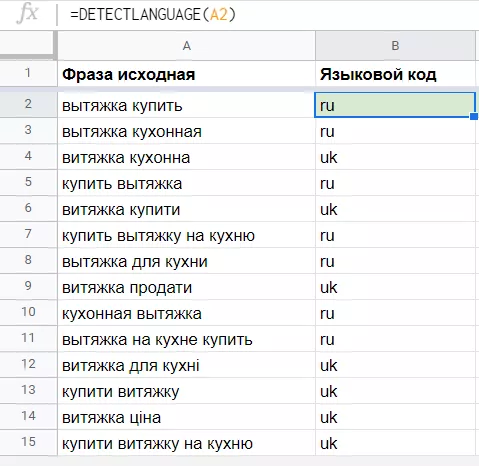
В аргументе функции указана одна ячейка, а не диапазон, потому что detectlanguage возвращает языковой код для первого фрагмента в диапазоне, а у нас он мультиязычный. Так как функция не взаимодействует с функцией arrayformula, описанной выше, протянем ее вручную.
Результат работы функции Detectlanguage стоит проверить, особенно если исходные фразы происходят из одной языковой подгруппы и/или содержат имена собственные, так как автоматическое определение текста может быть неточным.
11. Функция IF
If (источник; значение_при_соблюдении_условия; значение_при_несоблюдении_условия) возвращает различные значения в зависимости от результата логической проверки. Для работы с семантическим ядром функцию можно использовать, например, для приведения данных к другому виду.
В колонке A содержатся названия кластеров и поисковые запросы, между кластерами — пустая строка. Чтобы получить в колонке B только названия кластеров, пропишем в функции If условие: если ячейка A2 пустая, то вывести ячейку A3, а если условие не соблюдено, то вывести пустую ячейку.
=IF(A2="";A3;"")
Протянем функцию и получим названия кластеров без фраз.

Можно и наоборот, вывести только фразы без названия кластеров. Функция будет выглядеть так:
=IF(A2="";"";A3)

Функцию If часто сочетают с другими функциями. Рассмотрим на примере с Detectlanguage, описанной выше. Эта функция возвращает языковой код фразы, а работать с ним не очень удобно. Чтобы получить сами фразы на русском языке, а не только код, добавим условие — функцию IF, следуя логике: если ячейка содержит текст на русском языке, то выводим текст из этой ячейки, а если нет — пустую ячейку. Формула будет выглядеть так:
=IF(DETECTLANGUAGE(A2)="ru";A2;"")
Первый аргумент функции IF — функция DETECTLANGUAGE и условие для неё в виде кода русского языка.
=IF(DETECTLANGUAGE(A2)="ru";A2;"")
Второй аргумент — значение при соблюдении условия — ячейка с текстом.
=IF(DETECTLANGUAGE(A2)="ru";A2;"")
Третий аргумент — значение при несоблюдении условия — пустая ячейка.
=IF(DETECTLANGUAGE(A2)="ru";A2;"")
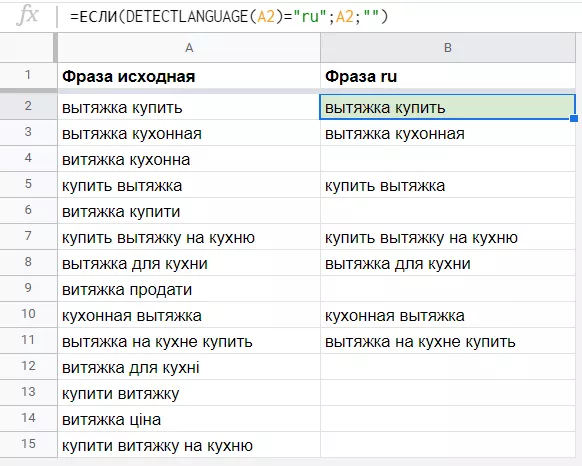
И снова напомню, что результат работы функции Detectlanguage стоит проверить.
12. Функция Query
Query (данные; запрос; [заголовки]) выполняет запросы на базе языка запросов API визуализации Google.
Семантист может использовать функцию Query, например, для приведения данных к определенному формату.
Например, исходными данными являются листы с семантикой такого вида:

Одному листу соответствует один URL, на каждом листе три колонки: URL, фраза, частота.
Выгрузим на отдельный лист данные о количестве фраз, сумме частот, а также максимальной, минимальной и средней частоте поисковых запросов по каждому URL. Функция Query позволяет получить эти данные несмотря на то, что их нет на листах с семантикой.
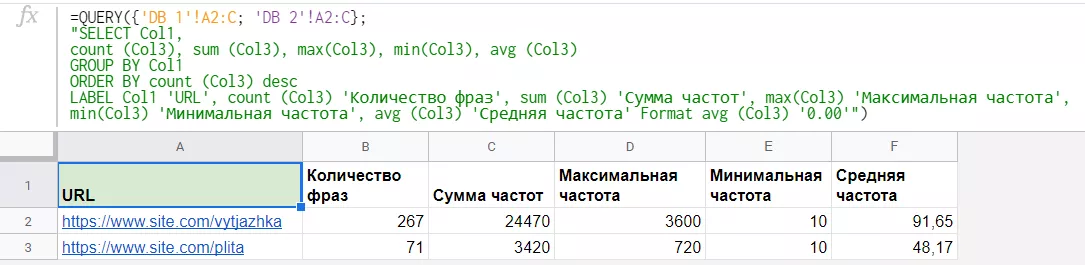
Первым аргументом функции Query будут названия листов и диапазон ячеек, из которых нужны данные. Всё это надо взять в фигурные скобки. Второй аргумент — SQL-запрос — выглядит следующим образом:
- с помощью кляузы Select укажем номер колонки, которую должен вернуть запрос. В нашем случае это колонка с URL-адресом, то есть первая;
- затем пропишем агрегирующие функции: count() — для количества фраз на листе, sum() — для суммы частот, max() — для максимального значения частоты, min() — для минимального значения частоты, avg() — для среднего значения частоты. Все эти функции применяются к третьей колонке, которая содержит частоту;
- кляуза Group by необходима, чтобы сработали агрегирующие функции. Укажем в ней первую колонку, содержащую URL;
- кляуза Label не обязательна. Она позволяет переименовать столбцы в итоговой таблице;
- завершает SQL-запрос кляуза Format, с помощью которой для удобства округлим данные в столбце “Средняя частота” до сотых.
Бонус
Функции таблиц Google особенно важны, если у вас нет платных инструментов для создания и кластеризации семантического ядра, как, например, Key Collector. В этой таблице вы найдете функции, соответствующие некоторым фильтрам фраз в Key Collector. Они облегчат и ускорят базовую чистку собранных поисковых запросов от нерелевантных фраз.
Чтобы воспользоваться фильтрами для вашего списка фраз, скопируйте себе эту таблицу, воспользовавшись меню «Файл» и выбрав в нем пункт «Создать копию», и вставьте ваш список фраз, начиная с ячейки A2. Автоматически в каждом столбце появятся отобранные фразы, соответствующие условиям фильтрации.
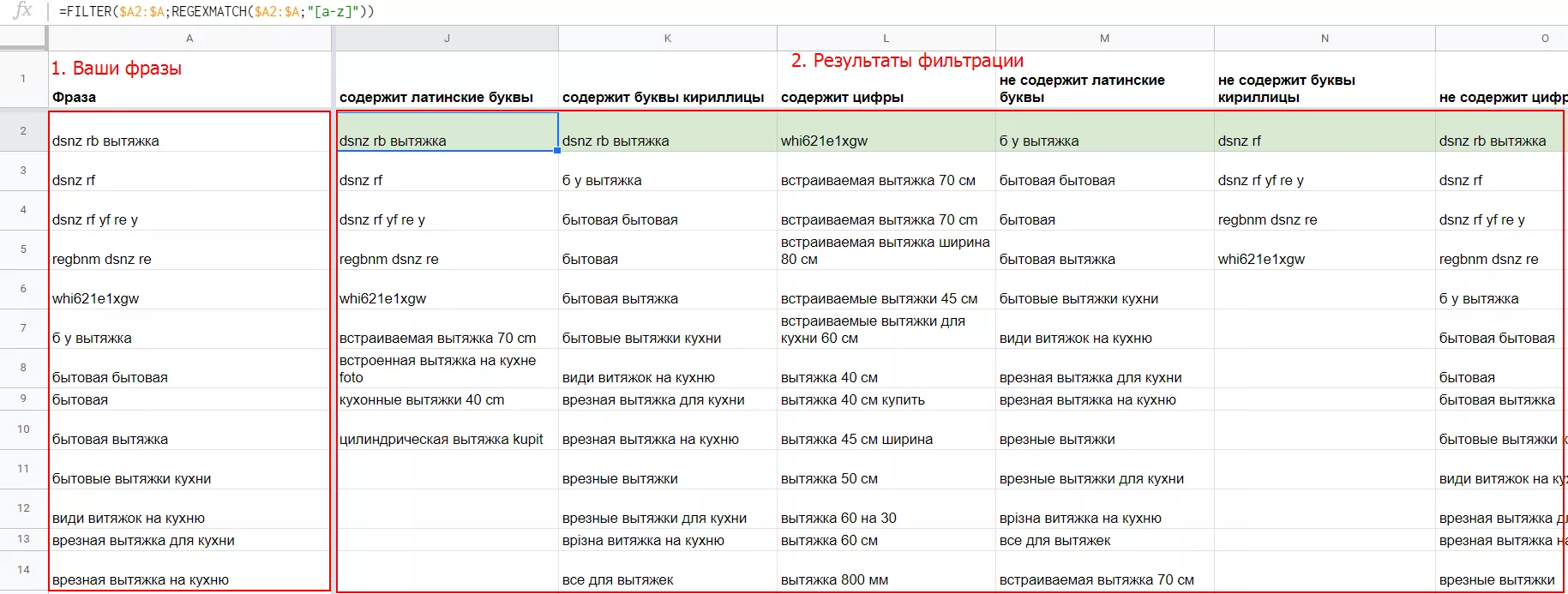
Для того, чтобы вставить отобранные фразы в нужный вам документ, воспользуйтесь вставкой без форматирования. Для Windows это сочетание клавиш Ctrl+Shift+V.
Выводы
Функции таблиц Google упрощают и ускоряют обработку семантического ядра. Комбинируя их друг с другом, семантист адаптирует функции под особенности проекта и свои потребности.
При работе с семантикой функции таблиц Google можно использовать для:
- удаления дублей поисковых запросов;
- составления маркерных запросов;
- формирования единого списка поисковых запросов с частотами из разных источников;
- импорта мета-тегов;
- работы с мультиязычными проектами;
- приведения данных к определенному виду и формату.
И ещё один бонус для тех, кто прочел статью до конца: таблица с примерами вышеописанных функций.

 12
12
 2
2
 0
0
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок