Выдача ответов на поисковый запрос на странице поиска за долю секунды только верхушка айсберга. В «черном ящике» поисковых систем — просканированные и занесенные в специальную базу данных миллиарды страниц, которые отбираются для представления с учетом множества факторов.
Страница с результатами поиска формируется в результате трех процессов:
- сканирования;
- индексирования;
- предоставления результатов (состоит из поиска по индексу и ранжирования страниц).
В этом выпуске «Азбуки SEO» речь пойдет о сканировании или краулинге страниц сайта.
Как работает сканирование (краулинг) сайта?
Если кратко, краулинг (сканирование, crawling) — процесс обнаружения и сбора поисковым роботом (краулером) новых и обновленные страницы для добавления в индекс поисковых систем. Сканирование — начальный этап, данные собираются только для дальнейшей внутренней обработки (построения индекса) и не отображаются в результатах поиска. Просканированная страница не всегда оказывается проиндексированной.
Поисковый робот (он же crawler, краулер, паук, бот) — программа для сбора контента в интернете. Краулер состоит из множества компьютеров, запрашивающих и выбирающих страницы намного быстрее, чем пользователь с помощью своего веб-браузера. Фактически он может запрашивать тысячи разных страниц одновременно.
Что еще делает робот-краулер:
- Постоянно проверяет и сравнивает список URL-адресов для сканирования с URL-адресами, которые уже находятся в индексе Google.
- Убирает дубликаты в очереди, чтобы предотвратить повторное скачивание одной и той же страницы.
- Добавляет на переиндексацию измененные страницы для предоставления обновленных результатов.
При сканировании пауки просматривают страницы и выполняют переход по содержащимся на них ссылкам так же, как и обычные пользователи. При этом разный контент исследуется ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
Например, в Google существуют роботы для обработки разного типа контента:
- Googlebot — основной поисковый робот;
- Googlebot News — робот для сканирования новостей;
- Googlebot Images — робот для сканирования изображений;
- Googlebot Video — робот для сканирования видео.
В
Кстати, именно с robots.txt и начинается процесс сканирования сайта — краулер пытается обнаружить ограничения доступа к контенту и ссылку на карту сайта (Sitemap). В карте сайта должны находиться ссылки на важные страницы сайта. В некоторых случаях поисковый робот может проигнорировать этот документ и страницы попадут в индекс, поэтому конфиденциальную информацию нужно закрывать паролем непосредственно на сервере.

Просматривая сайты, бот находит на каждой странице ссылки и добавляет их в свою базу. Робот может обнаружить ваш сайт даже без размещения ссылок на него на сторонних ресурсах. Для этого нужно осуществить переход по ссылке с вашего сервера на другой. Заголовок HTTP-запроса клиента «referer» будет содержать URL источника запроса и, скорее всего, сохранится в журнале источников ссылок на целевом сервере. Следовательно, станет доступным для робота.
Как краулер видит сайт
Если хотите проверить, как робот-краулер видит страницу сайта, отключите обработку JavaScript при включенном отладчике в браузере. Рассмотрим на примере Google Chrome:
1. Нажимаем F12 — вызываем окно отладчика, переходим в настройки.
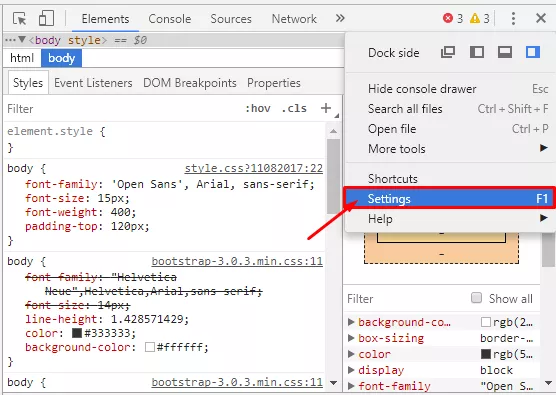
2. Отключаем JavaScript и перезагружаем страницу.
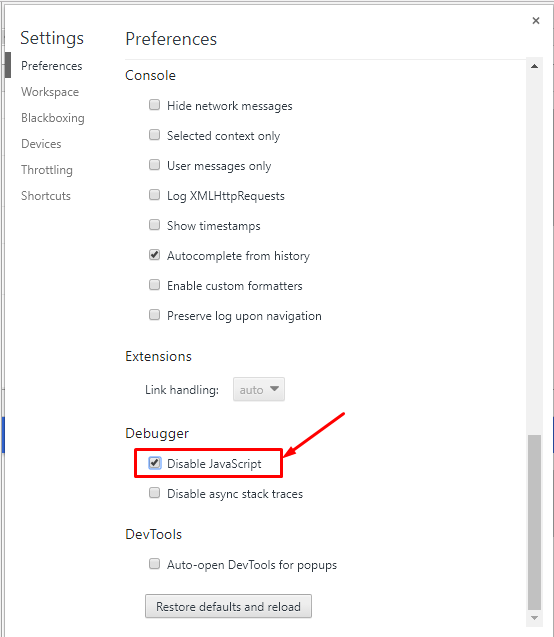
Если в целом на странице сохранилась основная информация, ссылки на другие страницы сайта и выглядит она примерно так же, как и с включенным JavaScript, проблем со сканированием не должно возникнуть.
Второй способ — использовать инструмент Google «Просмотреть как Googlebot» в Search Console.
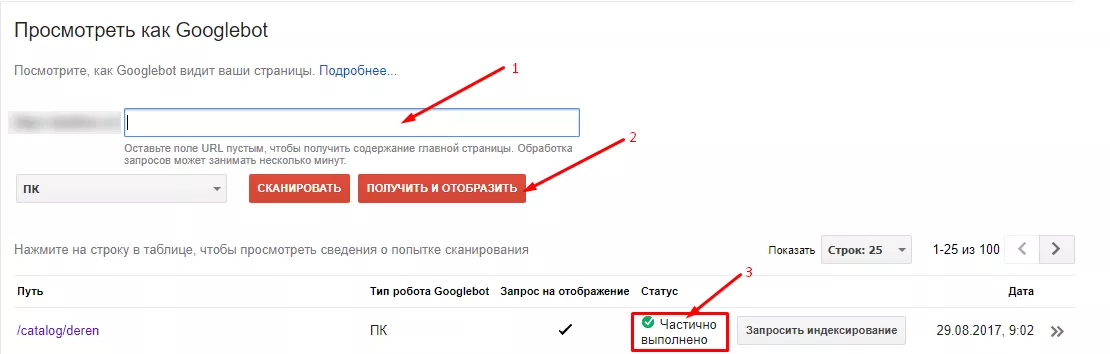
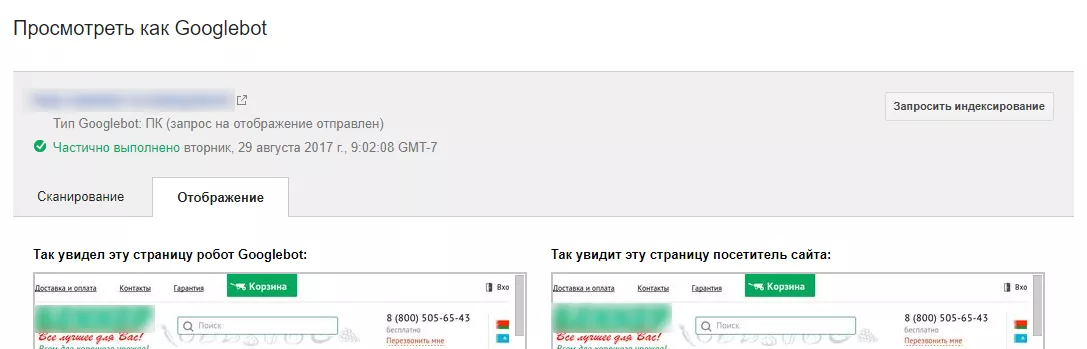
Если краулер видит вашу страницу так же, как и вы, проблем со сканированием не возникнет.
Третий метод — специальное программное обеспечение. Например, Netpeak Spider показывает более 50 разных видов ошибок, найденных при сканировании, и разделяет их по степени важности.
Если страница не отображается так, как вы ожидали, стоит проверить, доступна ли она для сканирования: не заблокирована ли она в robots.txt, в файле .htaccess.
Проблемы со сканированием могут возникать, если сайт создан с помощью технологий
Как управлять сканированием страниц
Запуск и оптимизация сканирования сайта
Существует несколько методов пригласить робота-паука к себе на сайт:
- Разрешить сканирование сайта, если он был запаролен на сервере, и передать информацию об URL c помощью HTTP-заголовка «referer» при переходе на другой ресурс.
- Разместить ссылку на ваш сайт на другом ресурсе, например, в соцсетях.
- Зарегистрироваться в панелях вебмастеров Google.
- Сообщить о сайте поисковой системе напрямую через кабинет вебмастеров Google.
- Использовать внутреннюю перелинковку страниц для улучшения навигации и сканирования ресурса, например, хлебные крошки.
- Создать карту сайта с нужным списком страниц и разместить ссылку на карту в robots.txt.
Запрет сканирования сайта
- Для ограничения сканирования контента следует защитить каталогов сервера паролем. Это простой и эффективный способ защиты конфиденциальной информации от ботов.
- Ставить ограничения в robots.txt.
- Использовать метатег <meta name=”robots”/>. С помощью директивы “nofollow” стоит запретить переход по ссылкам на другие страницы.
- Использовать HTTP-заголовок X-Robots tag. Запрет на сканирование со стороны сервера осуществляется с помощью HTTP заголовка X-Robots-tag: nofollow. Директивы, которые применяются для robots.txt, подходят и для X-Robots tag.
Больше информации о использовании http-заголовка в справке для разработчиков.
Управление частотой сканирования сайта
Googlebot использует алгоритмический процесс для определения, какие сайты сканировать, как часто и сколько страниц извлекать. Вебмастер может предоставить вспомогательную информацию краулеру с помощью файла sitemap, то есть с помощью атрибутов:
- <lastmod> — дата последнего изменения файла;
- <changefreq> — вероятная частота изменений страницы;
- <priority> — приоритетность.
К сожалению, значения этих атрибутов рассматриваются роботами как подсказка, а не как команда, поэтому в Google Search Console и существует инструмент для ручной отправки запроса на сканирование.
Выводы
- Разный контент обрабатывается ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
- Для улучшения процесса сканирования нужно создавать карты сайтов и делать внутреннюю перелинковку — чтобы бот смог найти все важные страницы.
- Закрывать информацию от индексирования лучше с помощью метатега <meta name="robots" content="nofollow"/> или http-заголовка X-Robot tag, так как файл robots.txt содержит лишь рекомендации по сканированию, а не прямые команды к действию.
Читайте больше

 34
34
 8
8
 0
0
Свежее
Почему сегментация — ключ к эффективному ecommerce-маркетингу
В этой статье я расскажу, как сегментация помогает превратить хаотичный маркетинг в точный и персонализированный
Как учитывать сезонность при разработке SEO-стратегии
Учет сезонных тенденций позволяет заранее подготовиться и «поймать волну» в нужные месяцы. Как именно это сделать, рассказываем в материале
Как вывести приложение из «мертвой точки» и увеличить количество органических просмотров на 142 730% в App Store
Три рынка, локальные поисковые привычки и системная работа с метаданными и видимостью в App Store