Делаем первичный сбор семантики грамотно, экономя время на чистках
При создании семантического ядра SEO-специалист большую часть времени тратит на чистку от нерелевантных фраз и кластеризацию. Когда я только начинала работать с семантическими ядрами, как и многие, собирала все фразы в один большой список. Далее начиналась долгая и мучительная работа по удалению нерелевантных фраз и кластеризация многотысячного списка.
Первым этапом по сокращению количества затраченного времени, стало использование на практике шагов, описанных в статье «8 шагов к очистке семантического ядра в Key Collector».
Со временем, перебирая в день многотысячные списки фраз, я выработала для себя еще несколько правил, которые сокращают время работы с нерелевантными фразами. Применяю их для сбора семантических ядр:
- Популярных тематик (ювелирные изделия, подборка фильмов, одежда и так далее);
- Если в разделе существует несколько категорий и подкатегорий. Например, ювелирные украшения:
- браслеты;
- броши;
- кольца;
- кулоны и подвески;
- серьги;
- цепочки.
Инструменты
- Планировщик ключевых слов.
- Serpstat.
- Key Collector.
- Google Sheets.
Принцип работы
Выполнить первичный сбор семантики так, чтобы тратить минимум времени на последующую очистку. Сюда относится также подготовка и настройка сбора.
Базовые запросы и их сбор
Любая работа по сбору семантики начинается с поиска базовых запросов.
Определив основные категории ассортимента товара, сайт конкурентов, переходим к сбору базовых запросов в инструментах: Keyword Planner или Планировщик ключевых слов и Serpstat. Главное правило — всегда пользуйтесь фильтрами.
Благодаря фильтрам я отсеиваю сразу ненужные запросы, составляю список стоп-слов и сокращаю время на чистку даже на этапе работы с базовыми фразами.
Фильтры и формирование списка стоп-слов
В Планировщике ключевых слов выполняю чистку семантики от нерелевантных запросов с помощью списка уточнения фраз и фильтров.
Список «Уточнить ключевые слова»
Список «Уточнить ключевые слова» расположен на боковой панели справа. Благодаря сформированным группам определяю популярные запросы, которые нерелевантны для моей задачи и нахожу будущие категории и кластеры.
Уточнения генерируется автоматически в зависимости от тематики собираемой семантики. Например, для тематики «Ювелирные изделия», сразу убираю нерелевантные бренды (olx, prom) и нерелевантные группы слов, например, «советские ювелирные изделия».
На скриншоте можно увидеть, что планировщик сгенерировал несколько списков с учетом характеристик в заданной ему тематике. Чтобы увидеть все уточняющие фразы, нужно нажать «Развернуть все» — в этом случае все списки развернутся сразу, или каждый список по отдельности, нажав на стрелочку.
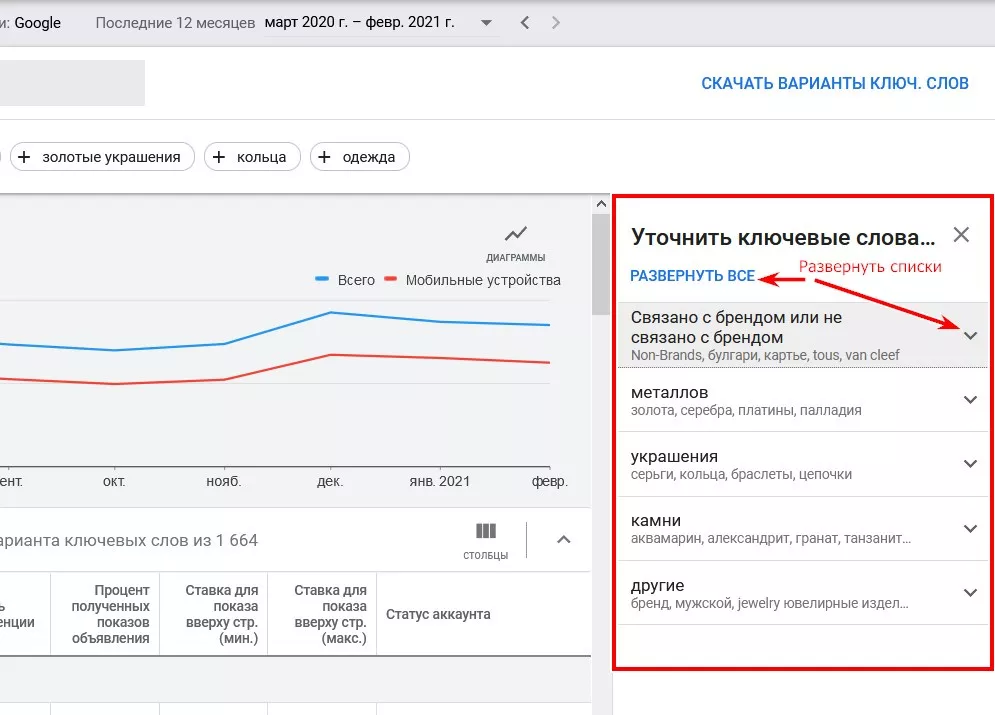
Пример развернутого списка:

Многие фразы могут встречаться уже после расширенного сбора, поэтому выписываю их, сохраняю нерелевантные фразы, формируя список стоп-слов уже сейчас.
Тут важно понимать, что планировщик определяет не все бренды или другие параметры. Это может быть связано с неправильным написанием, редким использованием, а также новыми для рекламы фразами. Google Ads — это прежде всего площадка для настройки рекламы.
Применение фильтров
Для более глубокой чистки базовых фраз использую «Фильтры», которые расположены на средней панели главного окна «Плана ключевых слов».
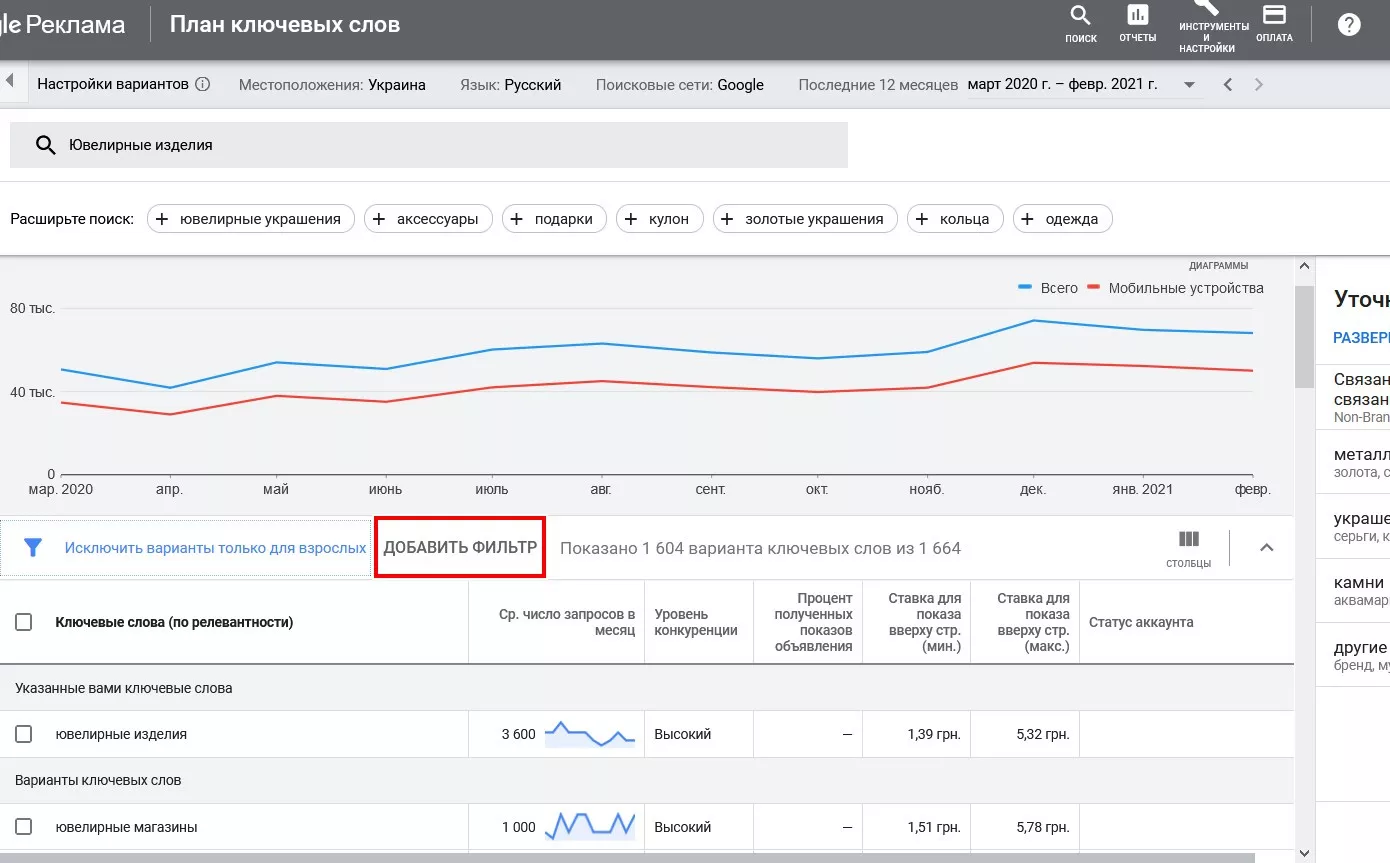
После нажатия на «Фильтр», появится окно со списком фильтров от Google Ads:

Для сбора базовых запросов семантики достаточно использовать только два фильтра:
- «Ключевое слово». Выбирая «Текст не содержит» ввожу список слов, которые не подходят для моей семантики.
- «Среднее число запросов в месяц». Использую базисы, у которых есть частота. Выбираю значение >= 10.
Выгружаю, и готовый очищенный список базовых запросов готов.
Стоп-слова в выгрузке запросов
Самый непопулярный, но простой способ отсеять фразы, не используя фильтры и список «Уточнить ключевые слова», в самом инструменте.
Сразу выгружаю запросы из планировщика ключевых слов и сохраняю на Google Диск. В крайних колонках выгруженной таблицы нахожу те самые значения, которые находила в инструменте «Уточнить ключевые слова». Далее аналогичную работу, как в предыдущих пунктах, по очистке списка выполняю фильтрами Google Sheets.
Пример:
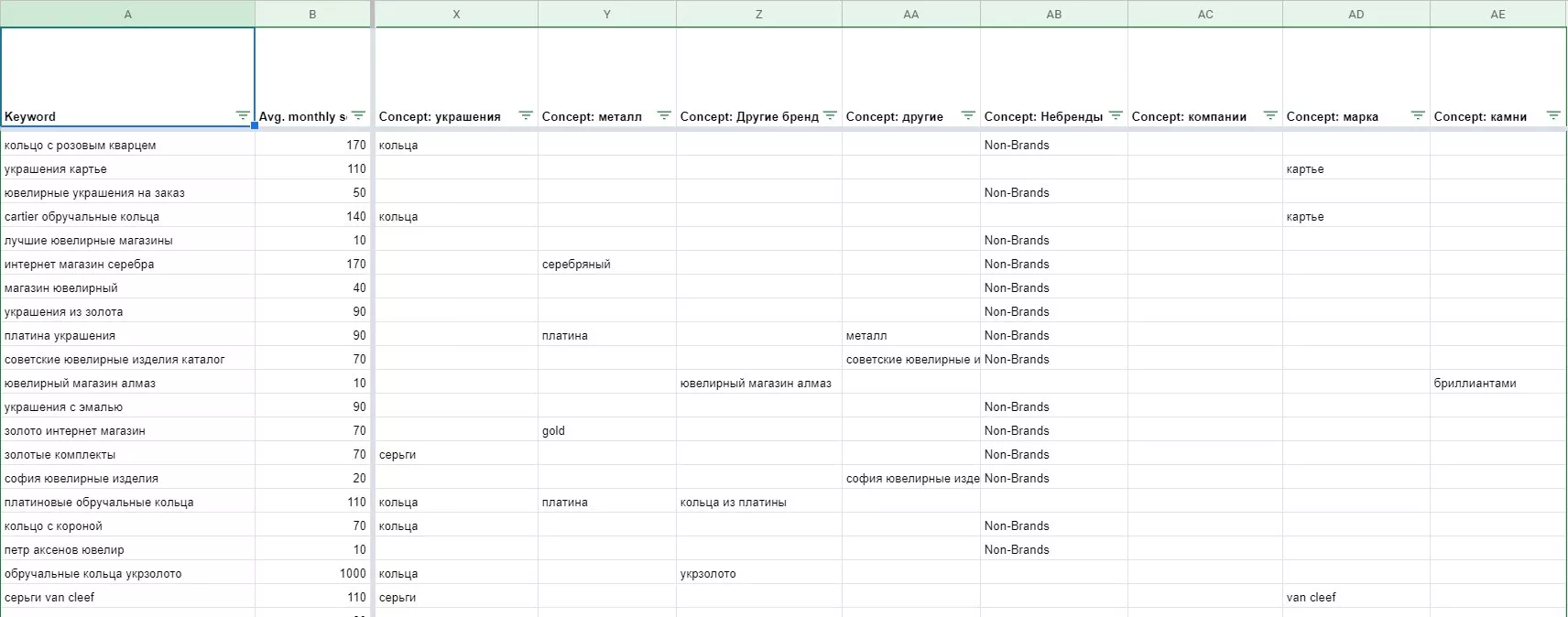
Этот метод более удобный для сохранения стоп-слов и формирования структуры кластеров.
Составление структуры кластеров
Собрался внушительный список базисов, и я начинаю прорабатывать структуру будущих кластеров — кластеризацию собранных базовых фраз. Эти действия помогут наглядно показать будущую структуру и для каких кластеров нужно выполнить дополнительный сбор базовых фраз.
Начинаю работать с фильтрами в Google Sheets с ранее выгруженной таблицей — сортирую и переношу фразы по основным характеристикам, максимально прорабатывая будущие кластеры.
Неструктурированные базовые фразы для темы «Ювелирные изделия»:
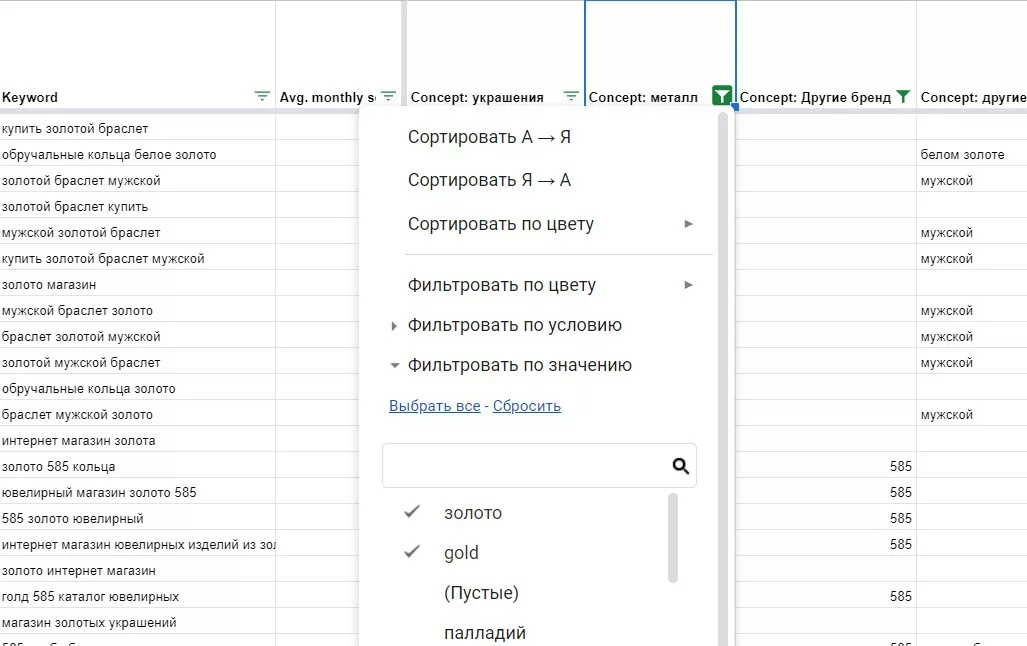
Привожу к такому виду:

На примере видно, что после названия группы стоят двоеточия и базовые запросы расположены в другом столбце на уровень ниже. Это необходимо не только для визуального восприятия, но и для загрузки в Key Collector в режиме «Группа: Ключ», что ускорит процесс добавления базисов в программу.
Чтобы быстрее проработать структуру кластеров и автоматизировать этот процесс, используйте кластеризацию от Serpstat. С её помощью можно сортировать автоматически до 50 000 фраз, основываясь на результатах топ-30 выдачи. Это помогает понять интент поискового запроса. Также для каждой фразы указана частотность для приоритизации работы над страницами. А гибкая настройка позволит точно распределить фразы постранично для избежания каннибализации и избавления от лишних ключей. Кластеризация отправит непохожие фразы в «неотсортированные», а вы решите, нужны ли они на сайте.
Сбор синонимов из Serpstat
Образовавшиеся кластеры расширяю релевантными синонимами, используя инструмент Serpstat, SEO-анализ, похожие фразы.
После кластеризации видно, какой кластер необходимо расширить базисными запросами.
Например, в моём списке кластер «Цепочки женские» содержит мало запросов и отсутствуют коммерческие запросы «купить», «цена» и подобные, а также нет синонимов и принадлежности к ювелирным изделиям. Поэтому данный кластер нужно расширить запросами.
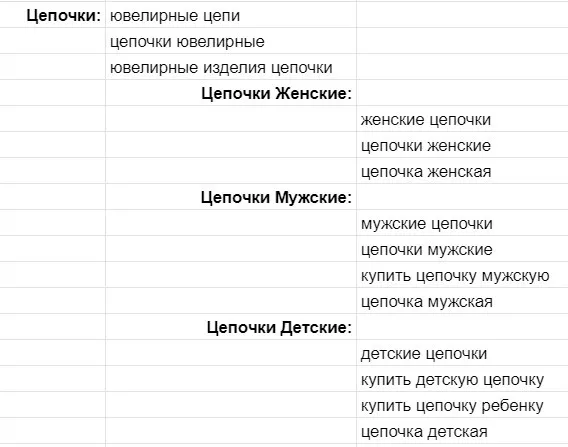
В инструменте Serpstat обязательно пользуюсь фильтрами — они существенно упрощают поиск в большом списке фраз.
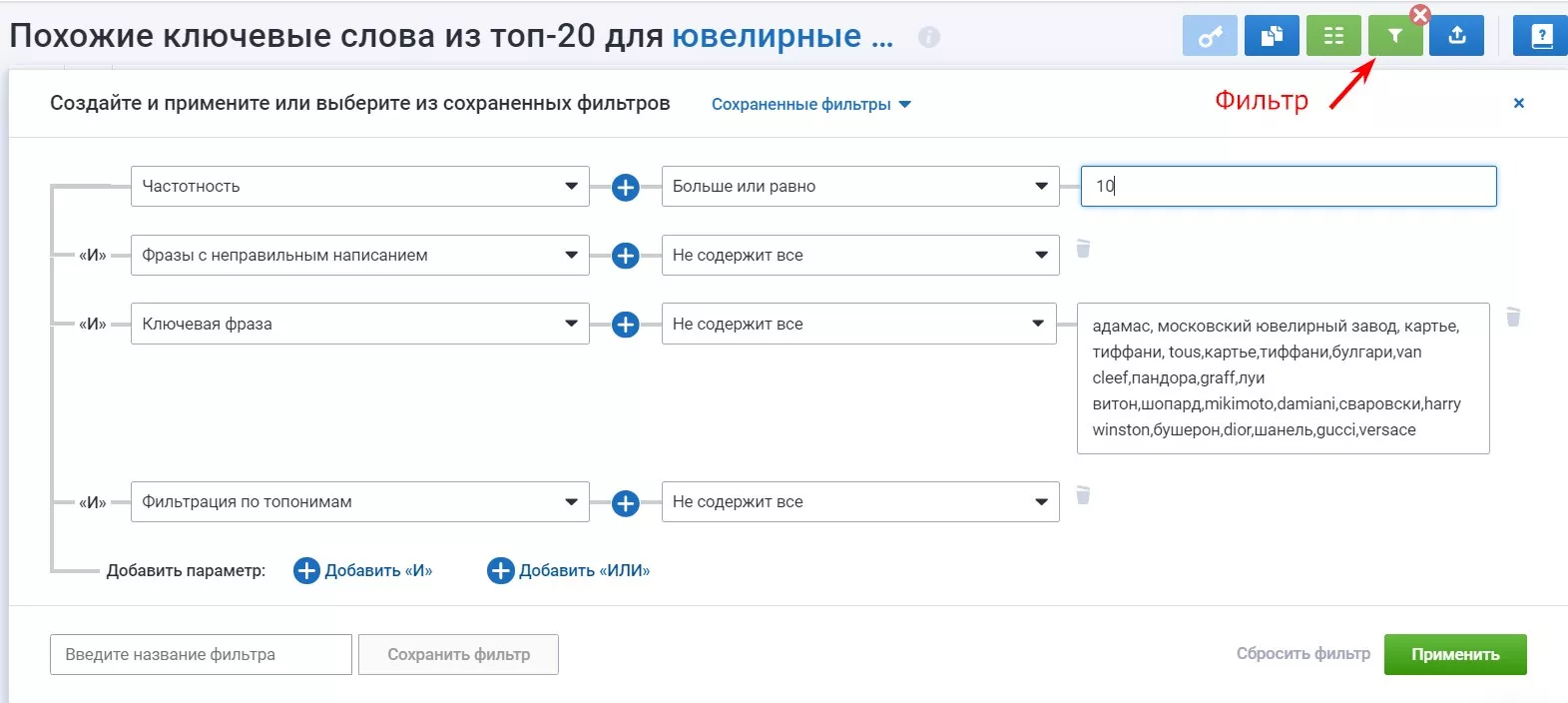
Мой стандартный набор фильтров при работе с любой семантикой в Serpstat:
- «Частотность» — «Больше или равно» — 10: убирает запросы с «0» частотой. При очень обширной тематике пользуюсь сортировкой частоты «Между» — низкочастотными (НЧ) и высокочастотными (ВЧ) запросами. ВЧ запросы здесь отсекаю, потому что они точно попали в список на предыдущих этапах сбора. НЧ запросы определяю как запросы с частотой ниже 10. Высокочастотная фраза может быть разной для каждой тематики, определить которые можно индивидуально просмотром частот фраз в выдаче планировщика или Serpstat.
- «Фразы с неправильным написанием» — «Не содержит все»: убирает большую часть фраз, написанных с ошибками.
- «Ключевые слова» — «Не содержит все»: список стоп-слов, которые собраны ранее. Вводить фразы нужно через запятую.
- «Фильтрация по топонимам» — «Не содержит все»: уберет из списка «Похожих фраз» топонимы, если их не нужно использовать.
Так я прохожусь по списку, дополняя каждый кластер базовыми фразами, где это необходимо.
Подготовка сбора в Key Collector
Чтобы ускорить загрузку групп, я структурировала и оформила базовые фразы в формате «Название группы: фраза» на предыдущих этапах. Теперь в настройках «Добавить фразы» активирую:
- «Использовать режим импортирования «Группа: ключ»;
- «Добавлять фразы в последнюю заданную группу (группой-ключом).
Пример настройки:
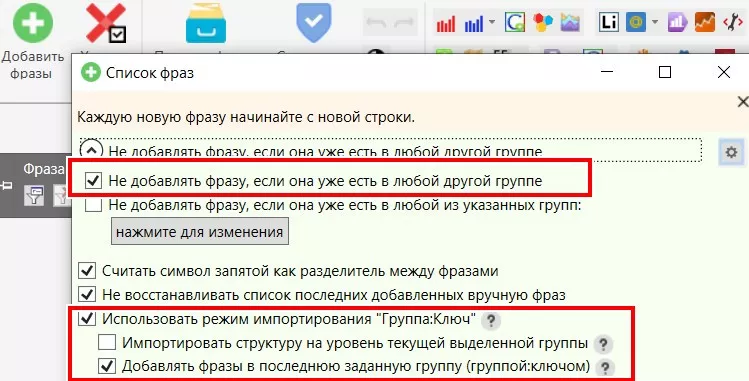
Чтобы исключить попадание случайных дублей при добавлении фраз, использую настройку «Не добавлять фразу, если она уже есть в любой другой группе».
После копирую подготовленный список базовых запросов из таблицы в окно «Добавить фразы»:

В результате полный список маркерных запросов со всей структурой добавляется в проект Key Collector всего за минуту. Пример такого результата:

Настройки автоматического сбора в Key Collector
Для пакетного сбора ключевых слов из планировщика Google Ads использую настройки:
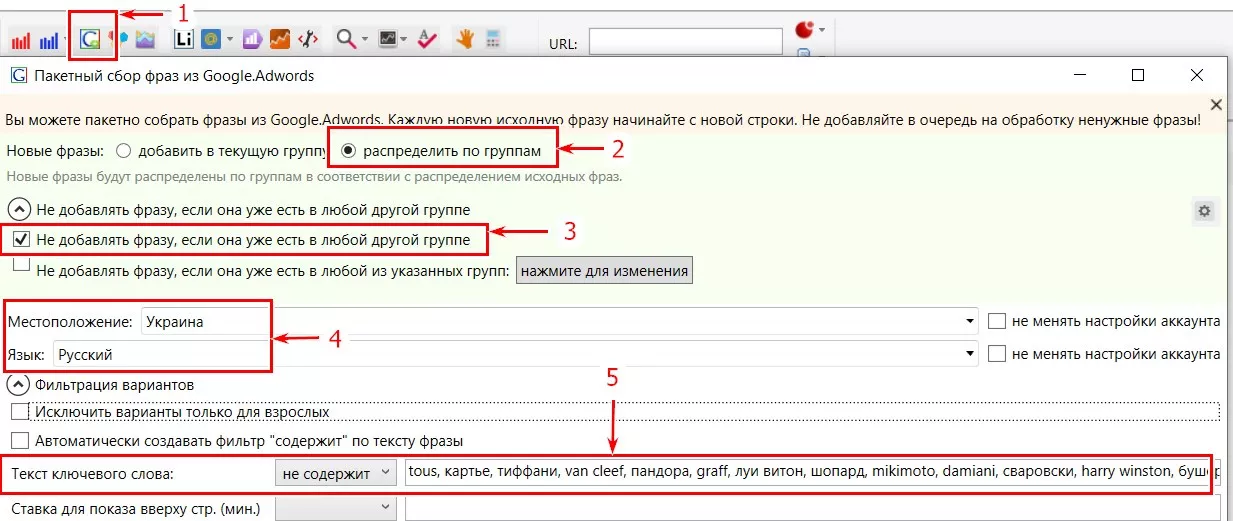
- Режим «Распределить по группам» — запросы будут распределяться в группы, которые соответствуют исходным фразам в уже созданной группе. Это уменьшит количество времени на дальнейшую кластеризацию.
- «Не добавлять фразу, если она уже есть в любой другой группе» — избавит от дублей в разных группах.
- Выставляю регион и язык.
- «Текст ключевого слова» — «Не содержит»: сюда вводим список только самых популярных стоп-слов из сформированного ранее списка. Данная функция сокращает время на чистку от нерелевантных фраз.
Порядок сбора Key Collector
Сбор выполняю поэтапно, начиная с узконаправленных категорий и заканчиваю более широкими категориями. На примере кластеров для ювелирных изделий:

У запросов «ювелирные изделия цепочки» и «цепочки ювелирные» расширения и на другие кластеры, как «цепочки мужские» или женские. Поэтому, если сначала запустить сбор для широконаправленных категорий, соберутся запросы в том числе и для нижних вложенностей этой категории в одну папку. Это приведет к дополнительным действиям по переносу фраз.
В свою очередь, если запустить сбор для узконаправленных категорий, расширений будет гораздо меньше для категории высшего уровня и это не будет настолько затратным по времени переноса.
Для запуска выбираю сначала узконаправленные категории «Добавить выбранные группы в качестве допустимых разделов и наполнить их содержащимися внутри группы фраз».
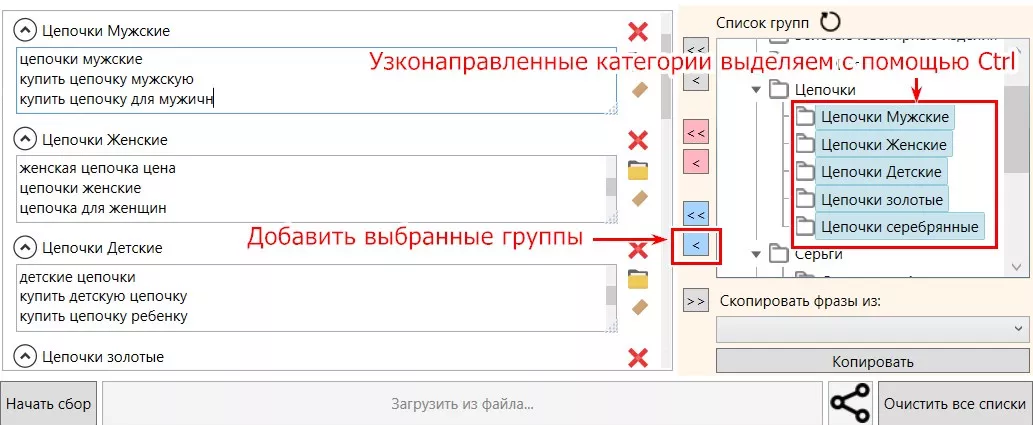
Нажимаем «Начать сбор» и ждем результат. После чего повторяем действия для широконаправленных категорий.
Выводы
- На этапе сбора базовых фраз применение фильтров помогает сократить время работы с их подбором и кластеризацией, а формирование списка стоп-слов облегчит чистку от нерелевантных фраз уже собранной семантики.
- Применение базовых запросов с частотой сократит время сбора и уменьшит попадание нерелевантных фраз при сборе.
- Максимальная проработка структуры кластеров поможет избежать упущенных фраз и уменьшит время на кластеризацию большого списка после сбора семантики.
- Правильная настройка сбора в Key Collector минимизирует дубли.
- Поэтапный сбор фраз, начиная с узконаправленных категорий, помогает исключить попадание в группу фраз, релевантных для другой группы проекта.
Использование такого подхода к сбору семантических ядер не избавит вас полностью от нерелевантных фраз в собранном списке, но к концу сбора у вас будет частично прокластеризованная семантика и подготовлен список стоп-слов. Таким образом, следующая чистка отнимет значительно меньше времени.

 13
13
 3
3
 8
8
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок