Как восстановить трафик на важные страницы интернет-магазина с помощью Web Archive
Владельцы сайтов и менеджеры, которые наполняют каталог интернет-магазина, не сильно заботятся об адресах страниц сайта. И это выливается в проблемы для SEO-специалистов. Дело в том, что когда меняются URL основных страниц, они вылетают из индекса поисковых систем и теряют длительной работой накопленное «доверие» и ссылочный вес.
В этой статье мы расскажем, как восстановить трафик на сайт с помощью крупнейшего хранилища копий сайтов.
Но вначале давайте разберемся, что такое Web Archive.
Web Archive и чем он полезен
Архив интернета — некоммерческая организация, основанная Брюстером Кейлом в 1996 году в Сан-Франциско. Сервис собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение, обеспечивая собранным материалам долгосрочное архивирование и бесплатный доступ к данным.
По-настоящему доступными для широкой публики сохраненные материалы стали в 2001 году, когда был запущен сайт Wayback Machine. Контент сайтов периодически фиксируется c помощью бота веб-архива. Также пользователи могут вручную указать адрес страницы для создания ее копии.
Сервис позволяет проследить историю изменений любого ресурса. Например, можно обнаружить причины каких-либо отклонений в аналитике, трафике или поведенческих показателях сайта. То есть проверить метатеги, тексты, расположение кнопок заказа и так далее. Можно посмотреть старый вариант дизайна своего сайта или скопировать дизайн любого «мертвого» сайта.
Также с мертвых ресурсов заимствуют контент, который может хорошо ранжироваться. Многие интернет-архив только так и используют. Причем настолько часто, что выгруженные тексты обязательно следует проверять на уникальность.
А еще Web Archive будет практически единственной возможностью восстановить сайт, если вы не делали бэкап.
Впрочем, в поисковой оптимизации интернет-магазинов мы используем интернет-архив с другой целью — для восстановления URL-адресов категорий и других важных страниц. Дело в том, что владельцы сайтов или менеджеры, которые наполняют каталог интернет-магазина, не следят за сменой адресов основных страниц сайта. В результате они вылетают из индекса поисковых систем, теряют накопленное доверие и ссылочный вес.
Как восстановить адреса страниц с помощью Web Archive
Следует очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса. После этого — настроить 301 редиректы со старых адресов на актуальные. Во-первых, поисковые системы при 301 редиректе передают практически полностью ссылочный вес со старых URL. Во-вторых, пользователи при переходе по старым ссылкам будут в итоге попадать на релевантную страницу сайта.
Конечно, можно попробовать вытащить страницы из кеша Яндекса или Гугла, но если ресурс недоступен уже очень давно, то такие мертвые ссылки открываются только в archive.org. Правда, и там их может не оказаться: у ботов веб-архива ограниченные ресурсы. Вероятность и частота сканирования сайта с маленьким трафиком крайне низкая. Но все-таки попробовать стоит.
Алгоритм действий:
1. Открываем веб-архив и вводим адрес сайта в строку поиска

Если сайт есть в веб-архиве, рекомендуем выбрать несколько копий сайта за разные даты в течение двух лет.
2. Для каждой выбранной даты делаем выгрузку URL-адресов
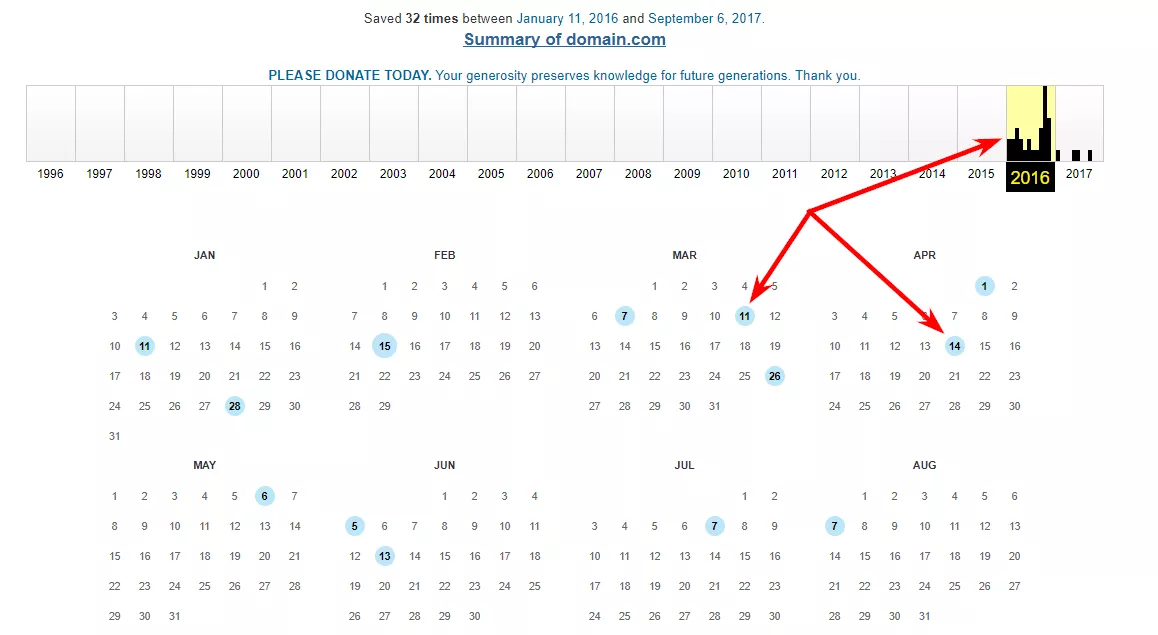
3. Выгружаем адреса с помощью Netpeak Spider, Web Scraper или вручную
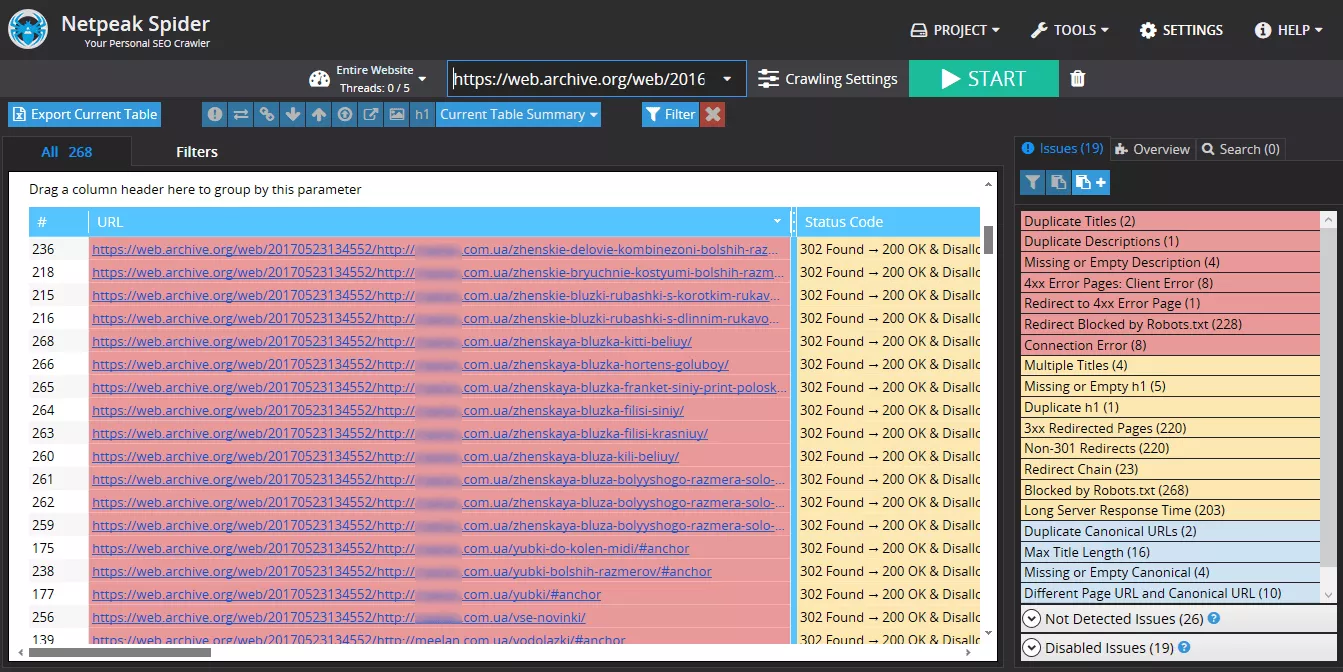
Как выгружать URL-адреса c помощью Netpeak Spider
Указываем в Netpeak Spider директорию, которую нужно сканировать, дополнительно задаем правила, например, возможность исключить карточки товаров.
Затем сканируем и выгружаем таблицу. Проделываем это для каждой даты.
Важно: изменение адресов карточек товаров целесообразно проверять в том случае, если они приносили существенный трафик.

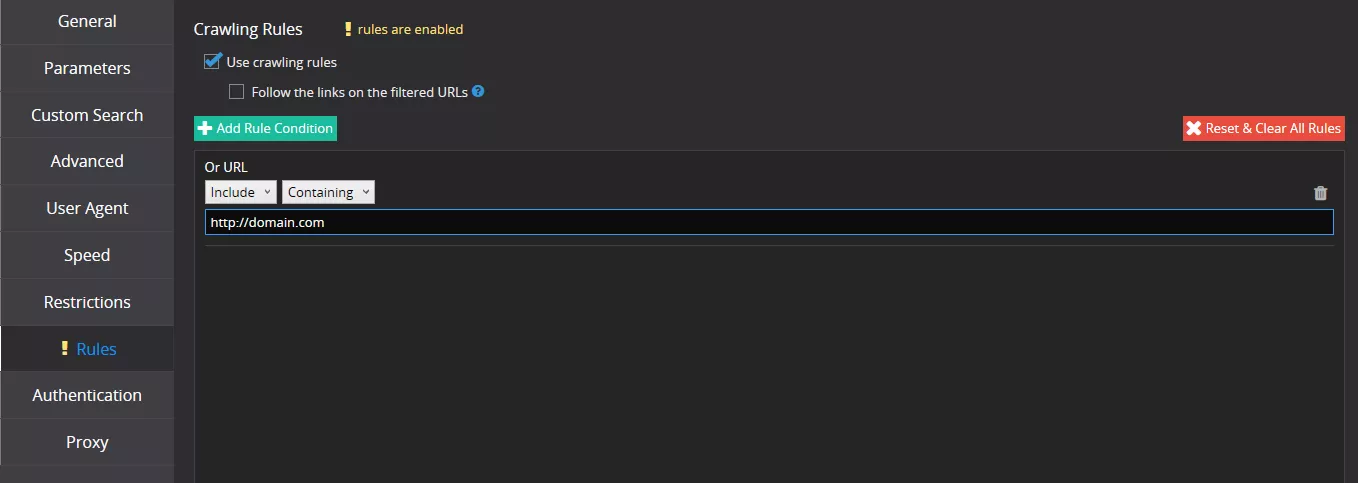
Если указывать в Netpeak Spider URL-адрес в формате https://web.archive.org/web/12345678901234/https://domain.com/, в правилах сканирования необходимо задать домен сайта, URL которого нужно получить, чтобы не сканировать весь веб-архив и его служебные страницы:
Получаем таблицу:
Как выгружать URL-адреса c помощью Web Scraper
Открываем веб-архив на нужной дате и консоль разработчика на той странице, где в коде есть все нужные URL-адреса. Например, каталог или карта сайта.
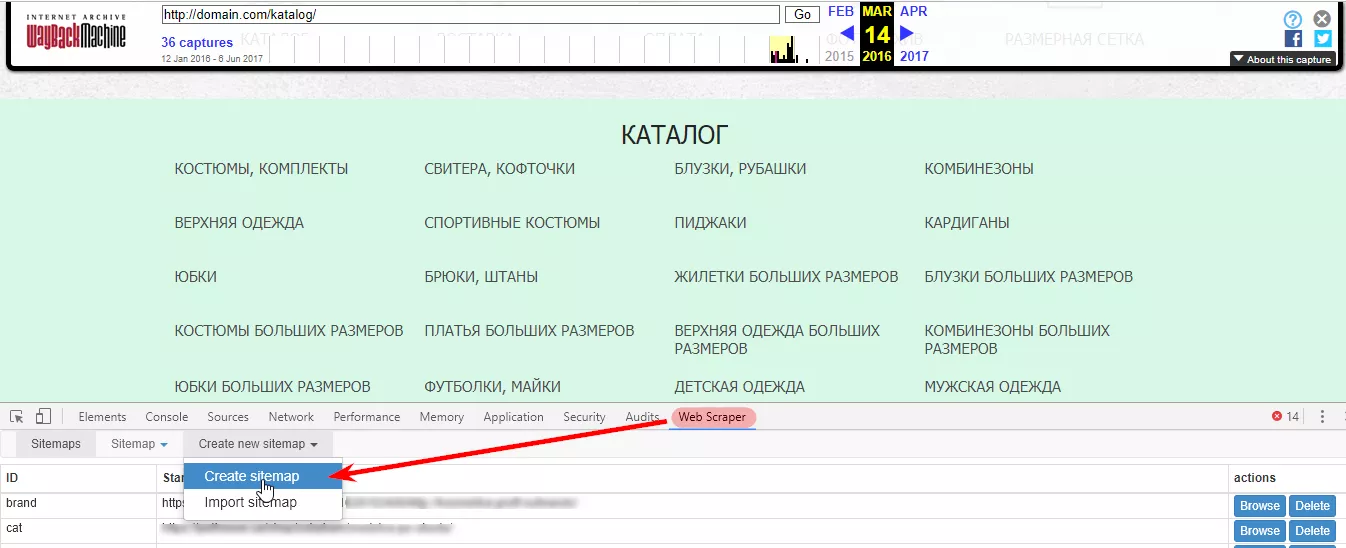
Задаем название и начальный URL для сканирования:
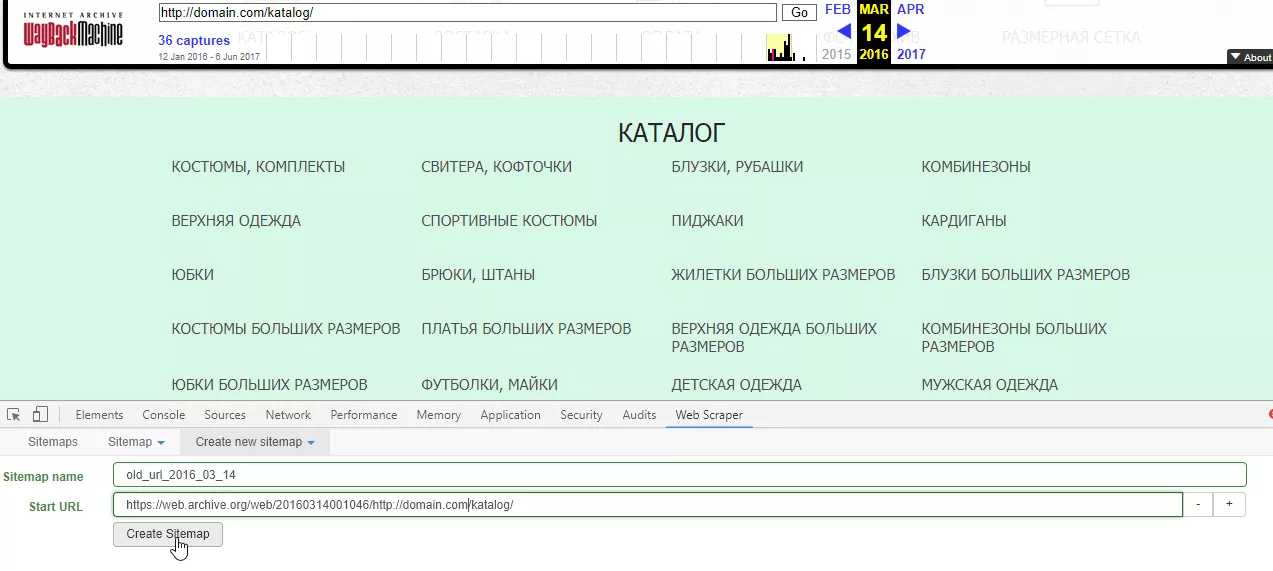
Добавляем новый селектор:
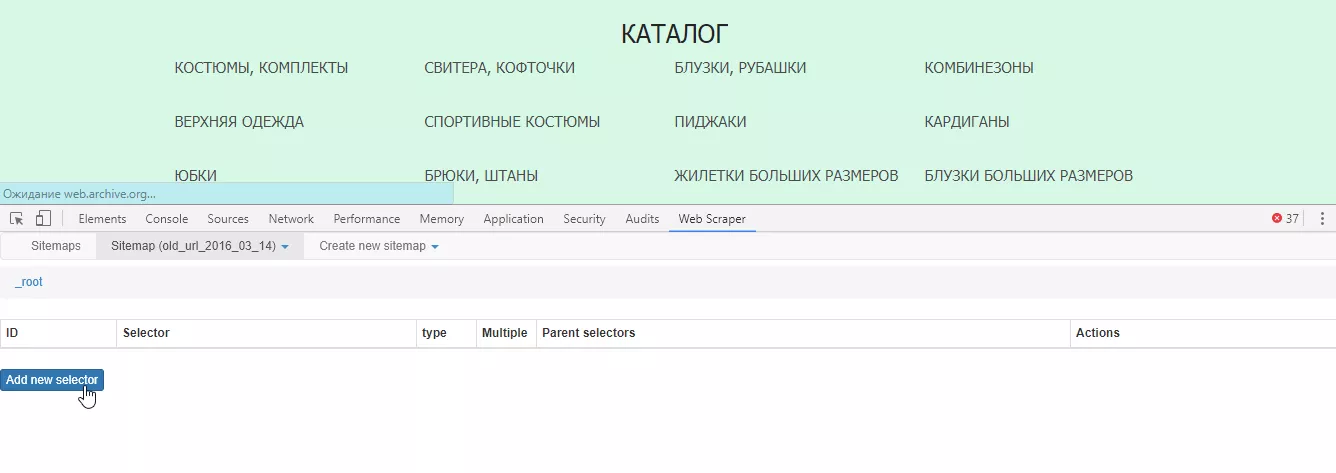
Для селектора задаем любое название (Id), выбираем тип селектора (Type) — Link, нажимаем «Select» и отмечаем на сайте все необходимые категории. При выборе более двух ссылок автоматически формируется общий селектор.
Важно: для URL разных уровней (например, категорий и их подкатегорий) необходимо создавать отдельные селекторы.
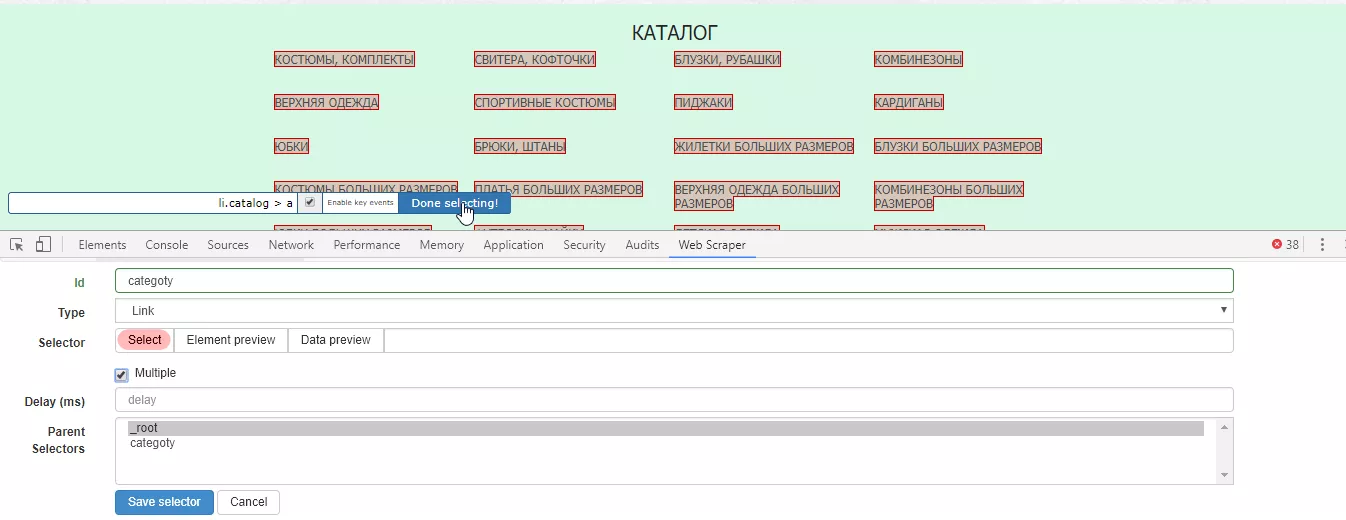
Нажимаем «Done selecting» и «Save selector». Когда все необходимые селекторы созданы, запускаем Web Scraper:
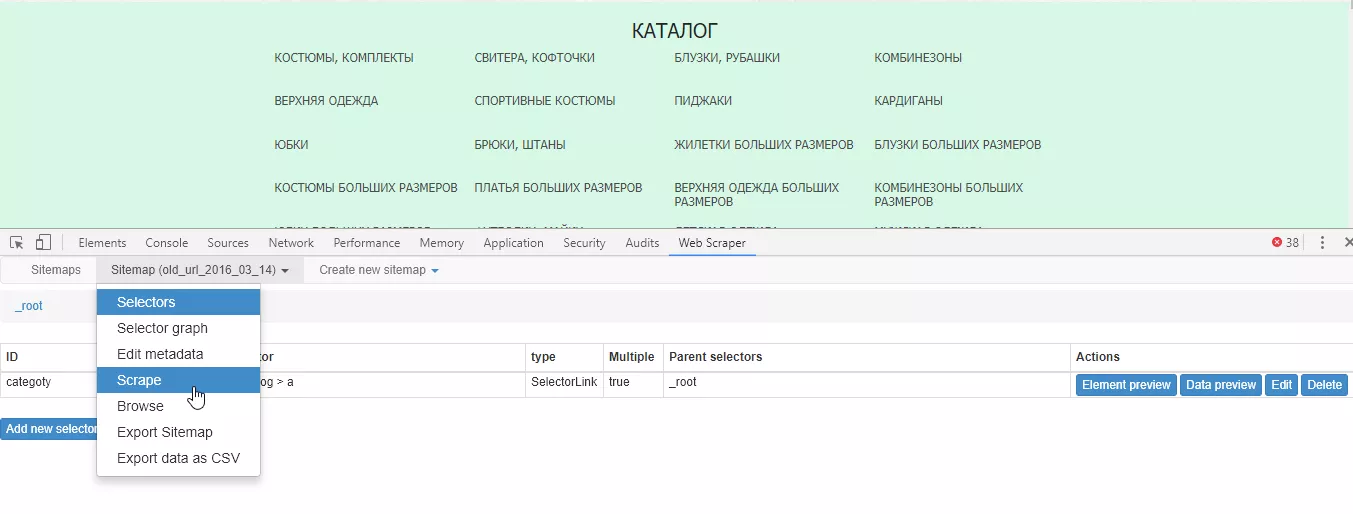
Выгружаем или копируем полученную таблицу:
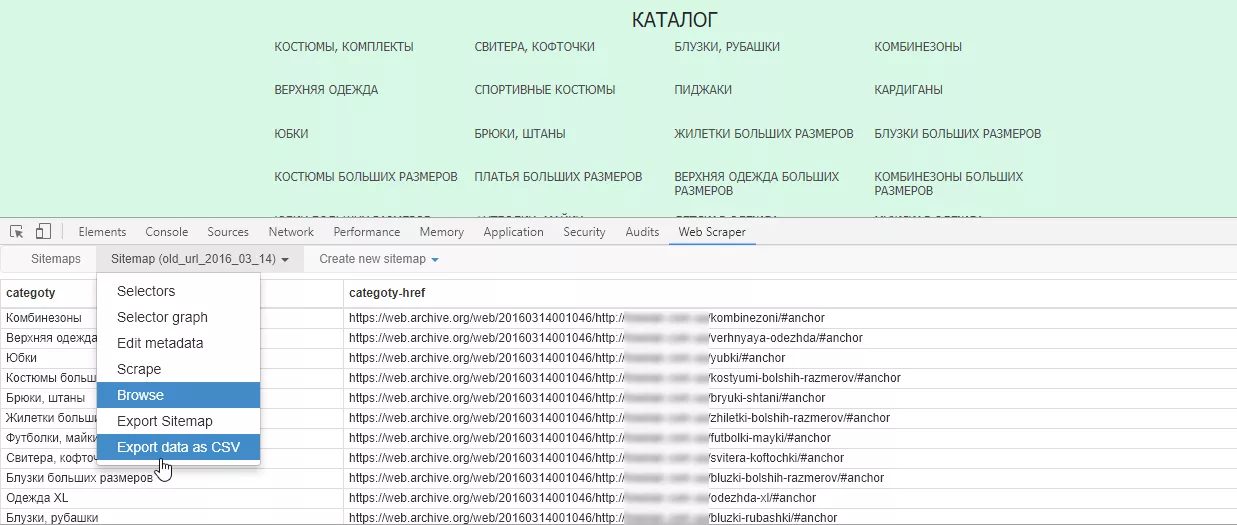
Web Scraper позволяет выгрузить URL только категорий, даже если в URL нет общей части.
Как выгружать URL-адреса вручную
Открываем исходный код страницы веб-архива, находим код с ссылками на страницы самого сайта в формате https://web.archive.org/web/*/https://domain.com/url, копируем и очищаем от лишнего кода с помощью регулярных выражений в Notepad++:
- убираем все пробелы в скопированном коде с помощью выражения «\s»;
- все URL размещаем в начале новой строки с помощью замены https://web.archive.org/web/*/ на регулярное выражение «\n»;
- все символы после кавычки удаляем (заменяем «“.*» на пустую строку).
После получения списка URL в формате https://web.archive.org/web/*/https://domain.com/url простой заменой или с помощью регулярных выражений приводим его к виду https://domain.com/url.
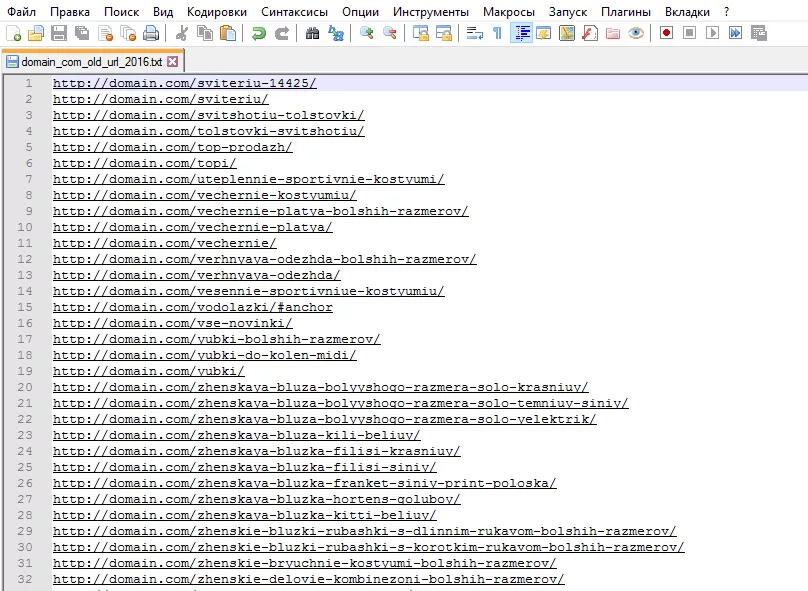
Подготавливаем URL-адреса для простановки редиректов
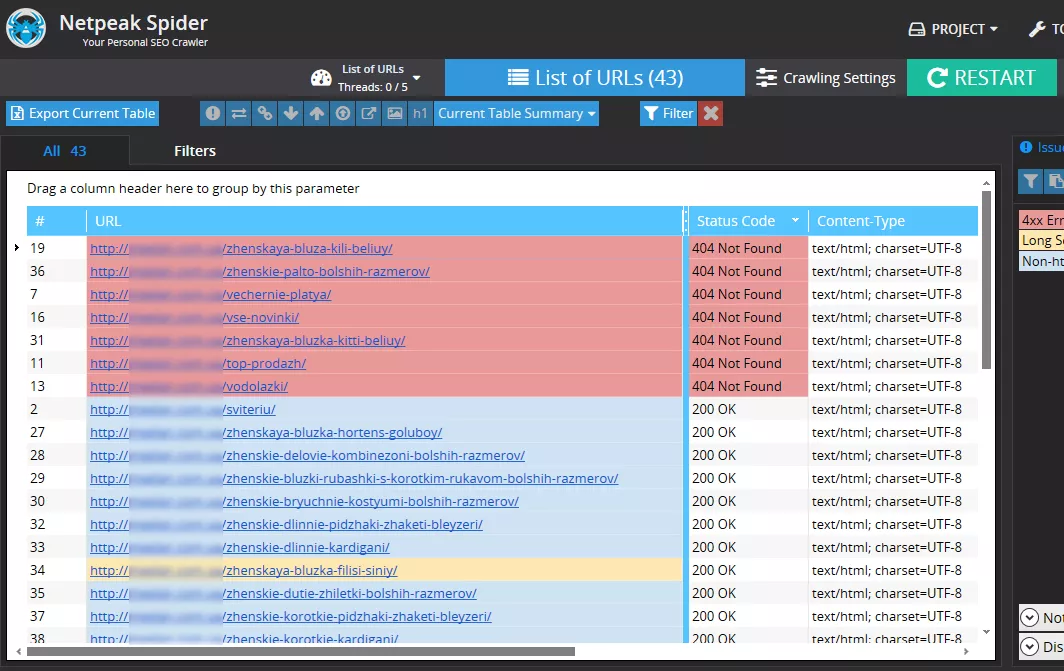
Загружаем в Netpeak Spider полученную базу и сканируем код ответа сервера. Если страница отдает код 200 или редиректит на страницу с кодом 200, все хорошо и с этими URL-адресами ничего делать не нужно.
Страницы с кодом 404 выделяем отдельно, проверяем при этом, чтобы все URL-адреса в этом списке были уникальными. Особенно это актуально, если выгружались URL-адреса для нескольких дат.
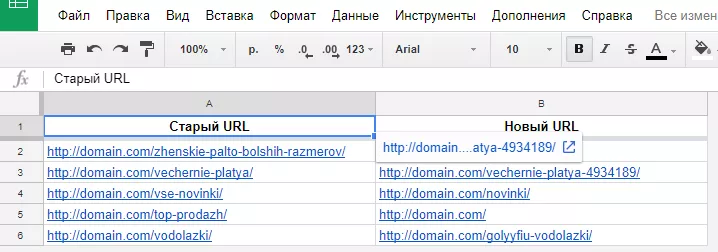
Если на текущей версии сайта не меняли заголовки Н1, можно выгрузить список необходимых адресов страниц с Н1 и сопоставить два списка с помощью простой функции VLOOKUP в таблицах Google.
Готовый список для настройки редиректов со старых URL-адресов на новые отправляем программисту.
Запомнить
Часто
Алгоритм простой:
- Находим сайт в Web Archive.
- Выбираем несколько копий сайта за разные даты в течение двух лет.
- Выгружаем адреса с помощью Netpeak Spider, Web Scraper или вручную.
- Подготавливаем базу URL-адресов для простановки редиректов.
- Отдаем программисту список для простановки редиректов со старых адресов на новые.

 23
23
 7
7
 0
0
Свежее
Как увеличить трафик на 286% в категории ботинок: кейс магазина обуви Miraton
Вывели ключевую категорию бренда в топ-3 поиске из-за расширения структуры сайта и работы с индексацией
Что такое MCP и как AI-агент может анализировать маркетинговые отчеты вместо вас
В этой статье я покажу, как работает архитектура такого агента, и объясню, как он автоматизирует маркетинговую аналитику
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок