Netpeak Spider — помощник при составлении технического аудита сайта
Мы решили поделиться еще одной программой, которая была написана нашим секретным подразделением программистов и ранее использовалась только внутри компании. Программа называется Netpeak Spider и она помогает составить технический аудит сайта. 
- сканировать сайты с помощью собственного робота;
- искать ошибки на сайтах (битые ссылки, неправильные редиректы, дублирование Title, Keywords и Description);
- анализировать входящие и исходящие внутренние ссылки для каждой страницы;
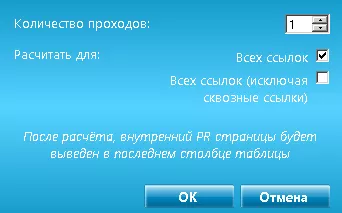
- рассчитывать внутренний PageRank;
- экспортировать данные в Excel.
Внешний вид главного окна программы выглядит так:
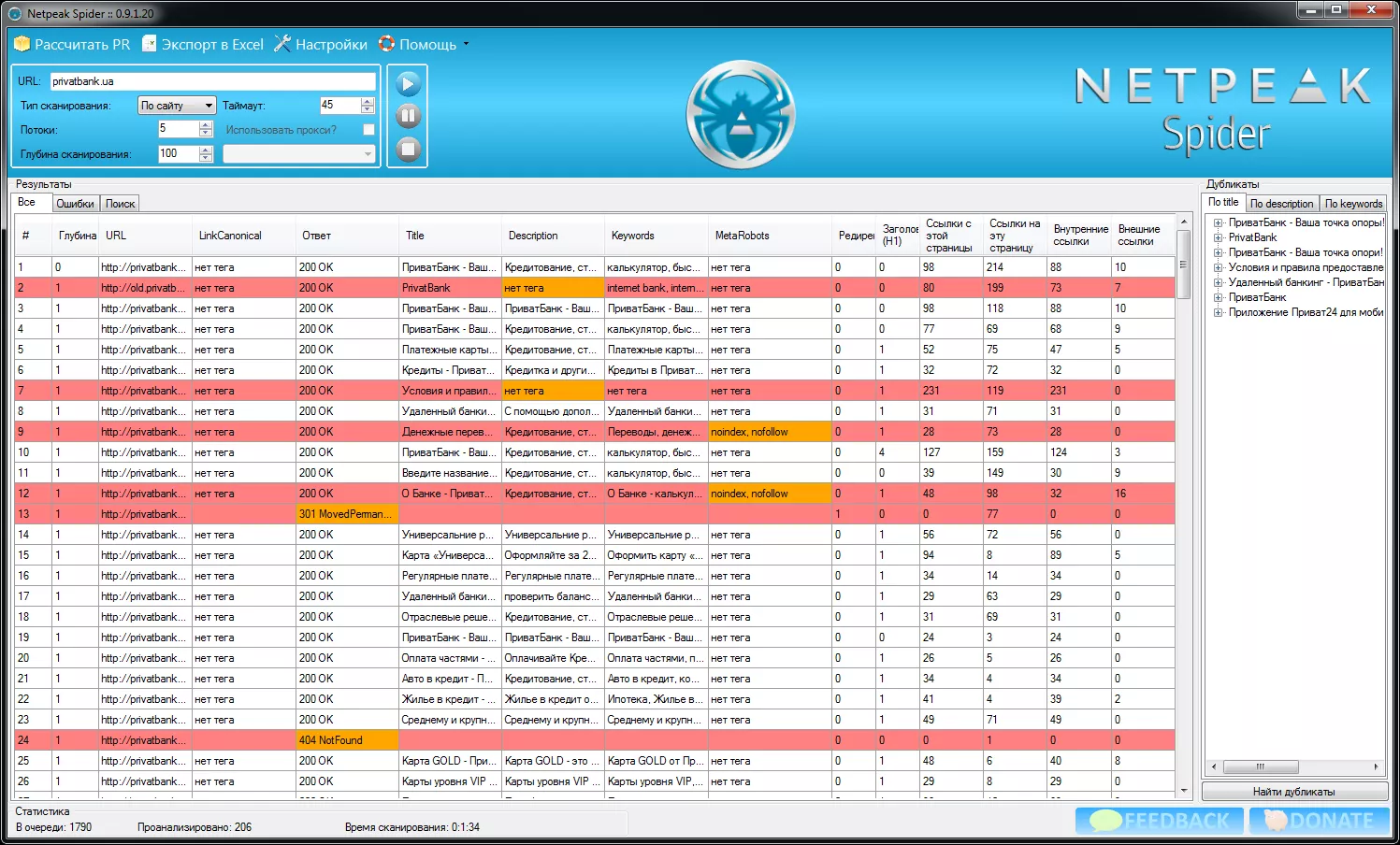
В настройках можно гибко настраивать количество потоков парсера, т.к. можно ненароком «уронить» сайты на некоторых хостингах. Есть возможность просканировать только определенный раздел сайта. То есть, если какая-то категория на сайте подверглась изменениям, то можно проверить на ошибки только ее.
Ошибки, найденные на сайте, вынесены в отдельный список:
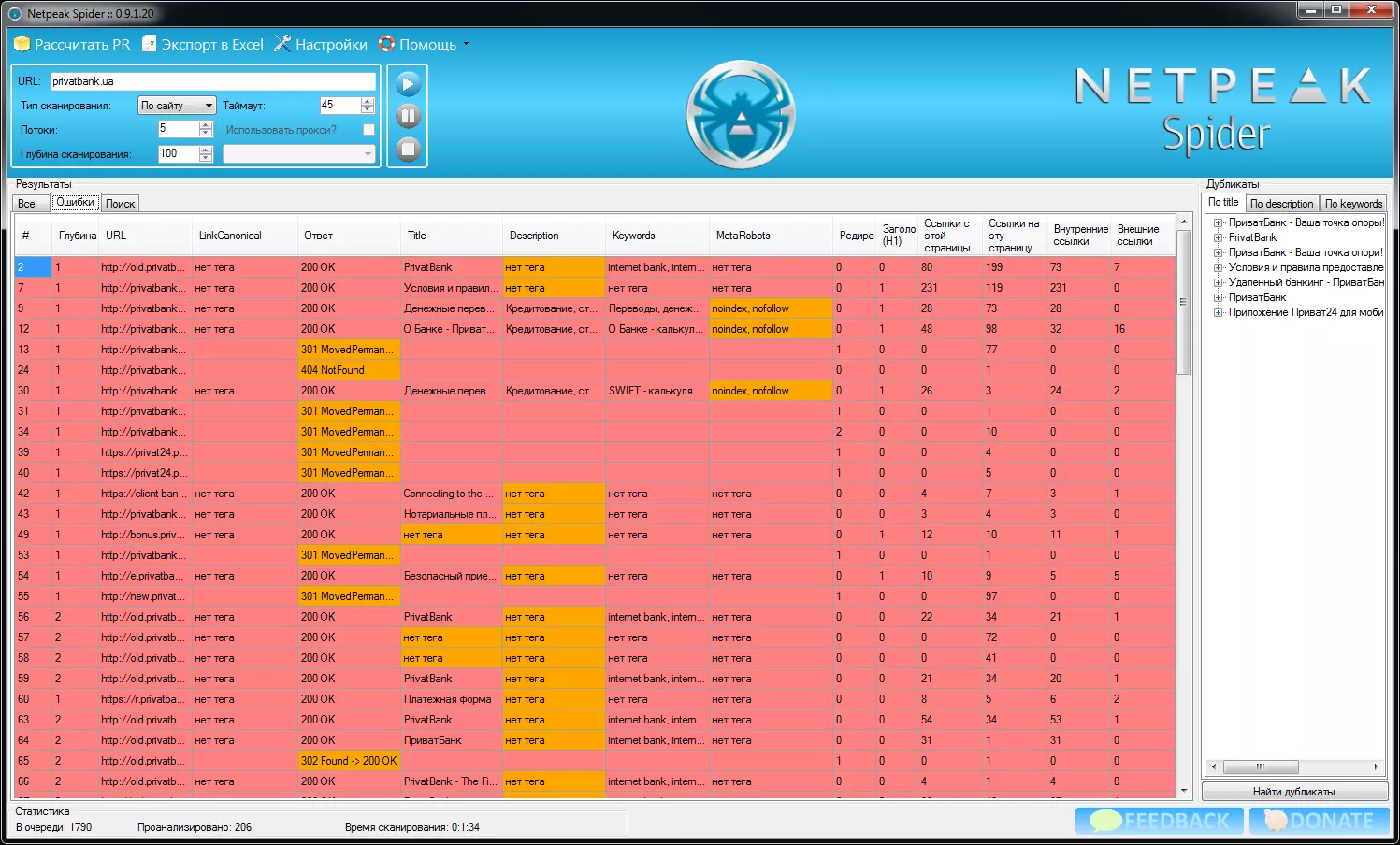
В настройках сканирования можно включать/отключать подсветку ошибок, сканирование поддоменов, использование robots.txt и т.д.: 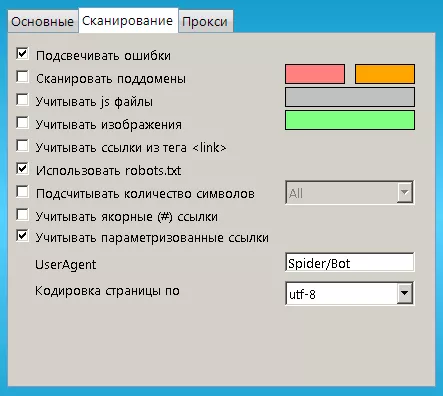

 12
12
 0
0
 0
0
Свежее
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок
Что такое активный пользователь в Google Analytics 4 и зачем его отслеживать
В этой статье я разберу, кого GA4 считает активным пользователем, по каким признакам определяет его статус и как применять этот параметр в анализе бизнес-результатов