Семантическая верстка: подробный гайд и важность для SEO
Качественный сайт — важный инструмент привлечения внимания к своему продукту. Семантическая верстка играет незаурядную роль в создании качественного веб-ресурса. Использование семантических тегов помогает построить логическую структуру страницы, организуя контент в блоки в зависимости от их значимости. Это положительно влияет не только на удобство использования, но и на работу поисковых систем, определяющих рейтинг сайта в результатах поиска.
Ниже я рассказываю все, что вам нужно знать о семантической верстке и ее важности. А также показываю пример, как правильно сверстать страницу с учетом принципов семантики.
- Что такое семантическая верстка?
- Важные семантические HTML-теги
- Иерархия семантических тегов в структуре разметки
- Как сверстать страницу с точки зрения семантики
- Зачем нужна семантическая верстка для SEO
- Популярные ошибки в применении семантических тегов
Что такое семантическая верстка?
Семантическая верстка — это подход к оформлению HTML-разметки документа, цель которого логично и упорядоченно разместить элементы (теги) в структуре страницы, учитывая значение и важность каждого.
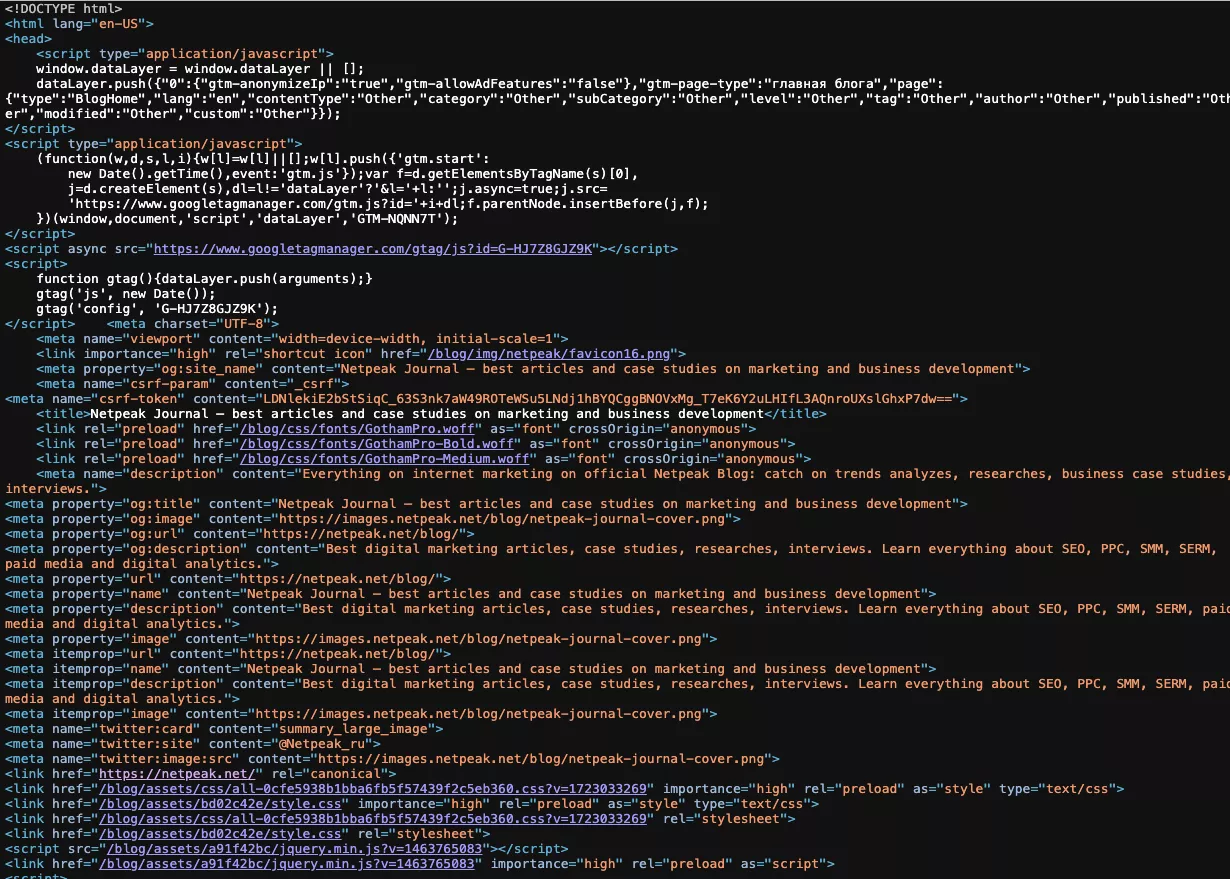
Пример HTML-разметки главной страницы Netpeak Journal
Кто-то заметит, что правильной структуры добиваются, используя обычные теги типа div или span, которые каждый специалист видел на практике.
Главная цель семантической верстки в том, чтобы с помощью HTML-тегов передавать значения содержащегося между ними контента. Такой подход позволяет предоставлять дополнительную информацию, которая признает роль и относительную иерархию отдельных частей/блоков страницы.
Важные семантические HTML-теги
Опишу основные семантические HTML-теги, которые чаще всего используются в современной верстке:
<header>
Элемент, обозначающий вводную часть блока, «шапка» или «голова». Используется для заголовков (h1–h6), содержания разделов/страниц, форм поиска, любых навигационных элементов, подсказок, контактной информации и т. п. Может быть размещен не один раз на странице.
<nav>
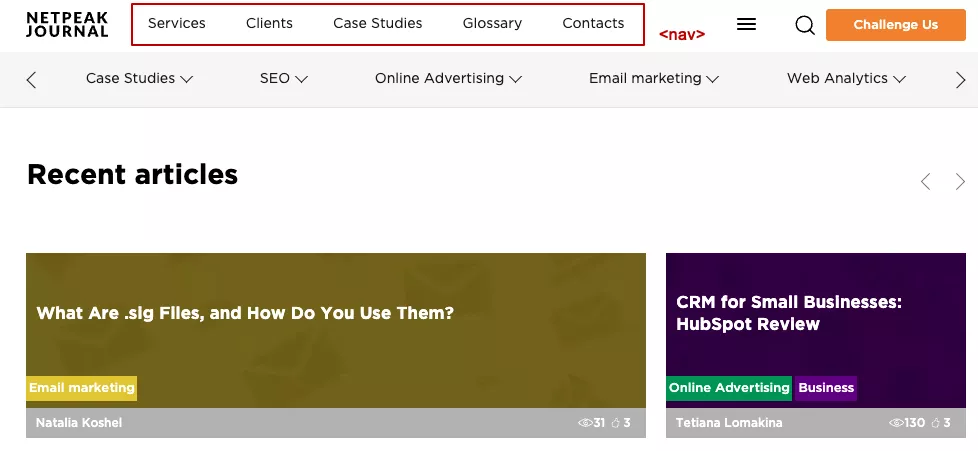
Элемент навигации обозначает часть страницы, которая ссылается на другие страницы или на части внутри страницы. Проще говоря, этим тегом часто помечают верхнее меню сайта. Ниже показываю пример внедрения навигационного тега в Netpeak Journal.
<main>
Элемент, представляющий основной или доминирующий контент на странице. Размещается только один раз. В него вкладывают другие блочные теги: <nav>, <header>, <section>, <article>.
<article>
Завершенный и самодостаточный тег. Он является частью композиции документа или сайта в целом. К примеру, этим элементом обозначают статью в блоге либо отдельный комментарий под статьей.
<section>
Элемент, который передает тематически сгруппированную часть контента — секцию документа или других частей страницы. Например, с помощью тега <section> статья <article> разделяется на несколько частей/разделов с заголовками и абзацами.
<footer>
Элемент выступает в качестве нижнего колонтитула, где в большинстве случаев содержится информация о секции или разделе, в котором он должен находиться. Например, данные об авторе, времени и месте публикации, об авторских правах и т. д.
Этот тег используется не только снизу элемента, внутри которого он находится, но и сверху. Можно даже продублировать его одновременно снизу и сверху.
<aside>
Боковой элемент, отображающий секцию, которая одновременно относится к основному контенту и отделена от него. Например, с помощью тега <aside> помечают рекламу, колонтитулы, боковую навигацию и т. д.
Приведу еще один пример: на странице о новостях в Украине сбоку добавление элемента <aside> позволит показать дополнительный материал о последних событиях Харькова.
<menu>
Элемент меню — это инструментальная панель, где перечисляются команды в виде ненумерованного списка с элементами <li>. Каждый из элементов представляет команду, которую пользователь может выполнить либо активировать. Элемент меню — семантическая альтернатива для тега <ul>. Главной особенностью этого тега является то, что он помогает Google Bot понимать, что внутри находится именно меню сайта.
<h1>, <h2>, <h3>
Эти элементы выступают заголовками для соответствующих разделов разного уровня. Элемент h1 предназначен для раздела верхнего уровня, h2 — для подраздела, h3 — для подраздела и так далее. Ниже приведу пример небольшой разметки
h1>Где найти мои носки/h1>
….вступительная часть
h2>ТОП мест, где вы могли потерять носки/h2>
….
h3>5 Место. Под одлеялом/h3>
…..
h3>4 Место. У себя на ноге/h3>
…..
Иерархия семантических тегов в структуре разметки
Самое главное в семантической верстке — придерживаться логики и правил иерархии, чтобы каждый элемент находился на своем месте.
Последовательные уровни размещения тегов в структуре разметки:
0 уровень
<div>, <span> — универсальные элементы, используемые в качестве контейнеров для группировки тегов.
1 уровень
<main>, <article> — наиболее значимые семантические элементы на странице.
2 уровень
<section>, <header>, <footer> — разбивают родительские блоки на отдельные смысловые части.
3 уровень
<h1-h6>, <p>, <ul>/ol> — используются для разделения фрагментов текста. Отдельно хочется выделить заголовки H1–H6, которые определяют тематику контента.
4 уровень
<a>, <img>, <button> — дополняют контент. В SEO тег <a> — один из важнейших в работе, потому что в него «окутывают» ссылки, SEO-специалисты часто с ними работают.
5 уровень
<strong>, <b> — отвечают за выделение важных частей текста и визуальное оформление.
Теперь, когда вы ознакомились с основами, рассмотрим реальный пример использования семантических тегов.
Как сверстать страницу с точки зрения семантики?
Приведу пример хорошей разметки на основе статьи Smashing Magazine.
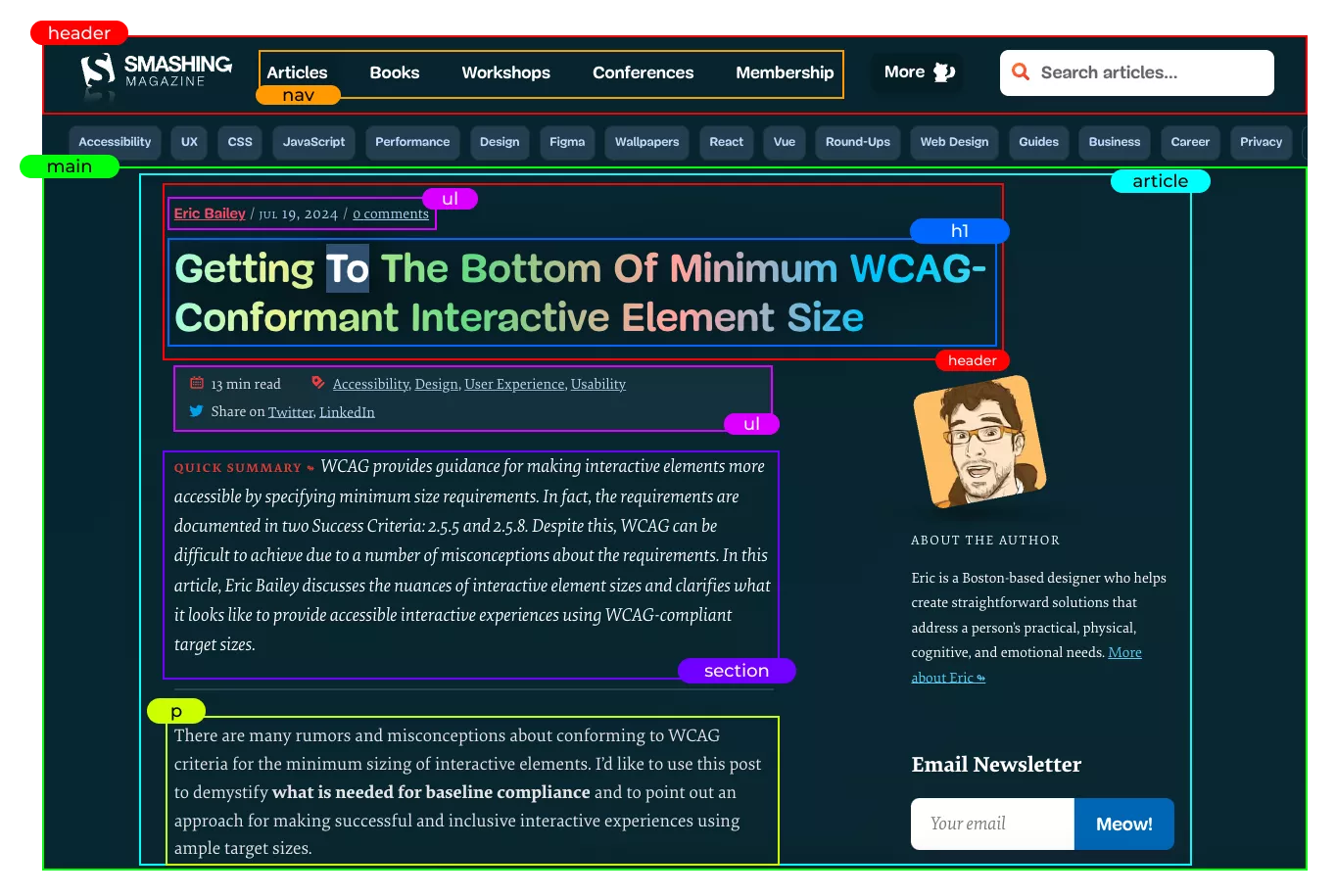
- Сначала идет шапка страницы, размещенная с помощью HTML-тега <header>. Внутри находится элемент <nav> — навигационное меню со ссылками на основные категории.
- Далее — главный контент страницы, помеченный тегом <main>.
- Внутри элемента <main> находится тег <article>, обозначающий статью в данном случае.
- Блог начинается с шапки <header>, где размещен список <ul> с данными об авторе, потом заголовок страницы H1 с темой статьи. Важно помнить, что на странице используем только один заголовок H1. Благодаря H1 поисковые роботы лучше понимают содержание страницы.
- Ниже находится еще один список <ul> с информацией о количестве времени для ознакомления и ссылками на социальные сети. Здесь уместно было бы использовать элемент <footer> вместо <ul>, поскольку именно тег <footer> предназначен для определения дополнительной информации о контенте статьи, раздела, страницы и т. п.
- Ниже открывается отдельная секция <section> с кратким итогом.
- И наконец начинается статья с блока <p>.
На деле все просто, но бывают страницы с более сложной структурой. В этом случае понадобятся действительно профессиональные верстальщики.
Визникает вопрос: как узнать, что контент на странице содержит конкретный тег? Для этого необходимо зайти на страницу, нажать правую кнопку мыши и из выпавшего списка выбрать пункт «Inspect».
Так выглядит интерфейс на Mac.

На Windows нужно выполнить аналогичные действия.
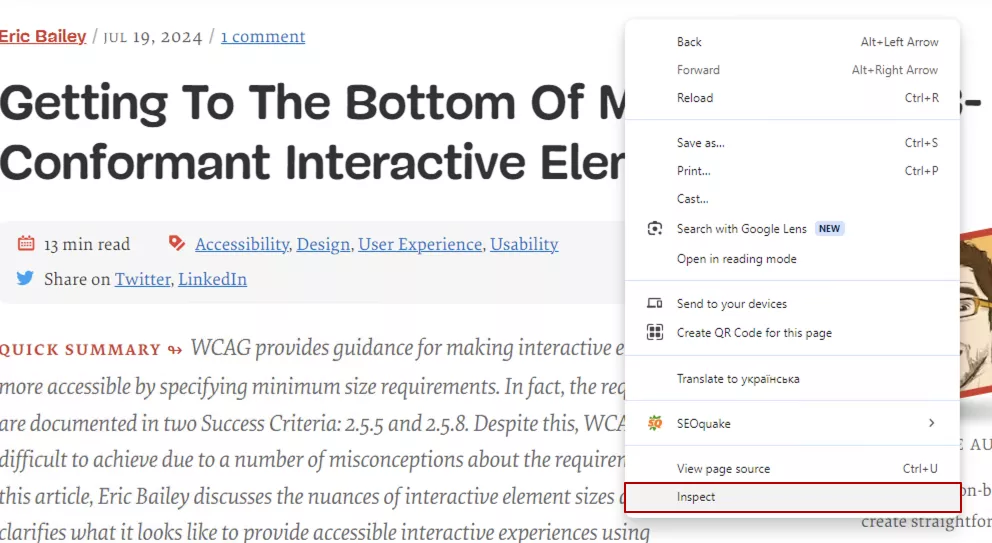
Справа появится окно Chrome DevTools.
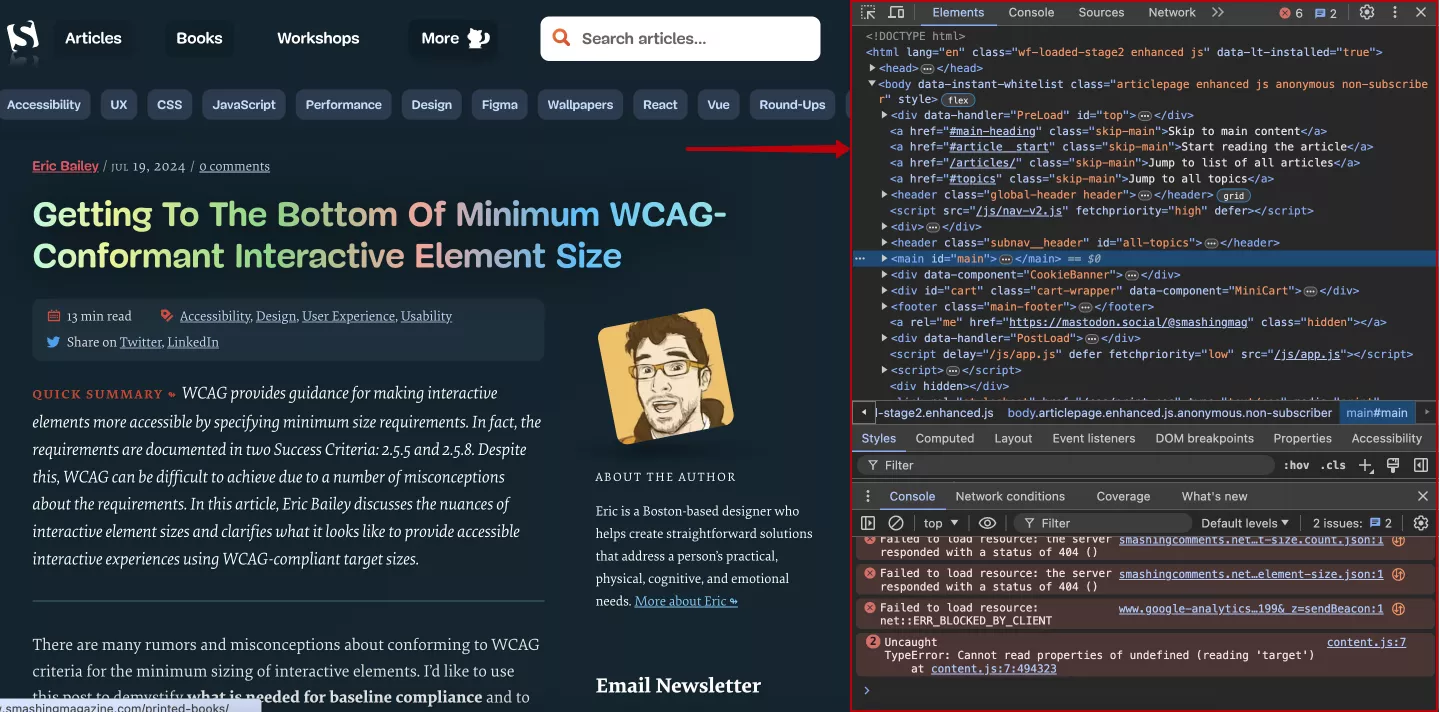
В нем, при наведении мышкой на HTML-теги, слева будет подсвечиваться контент на странице с соответствующим тегом. Например, с помощью стрелок напротив тегов, позволяющих раскрывать внутренние элементы, я нашел тег <header>.
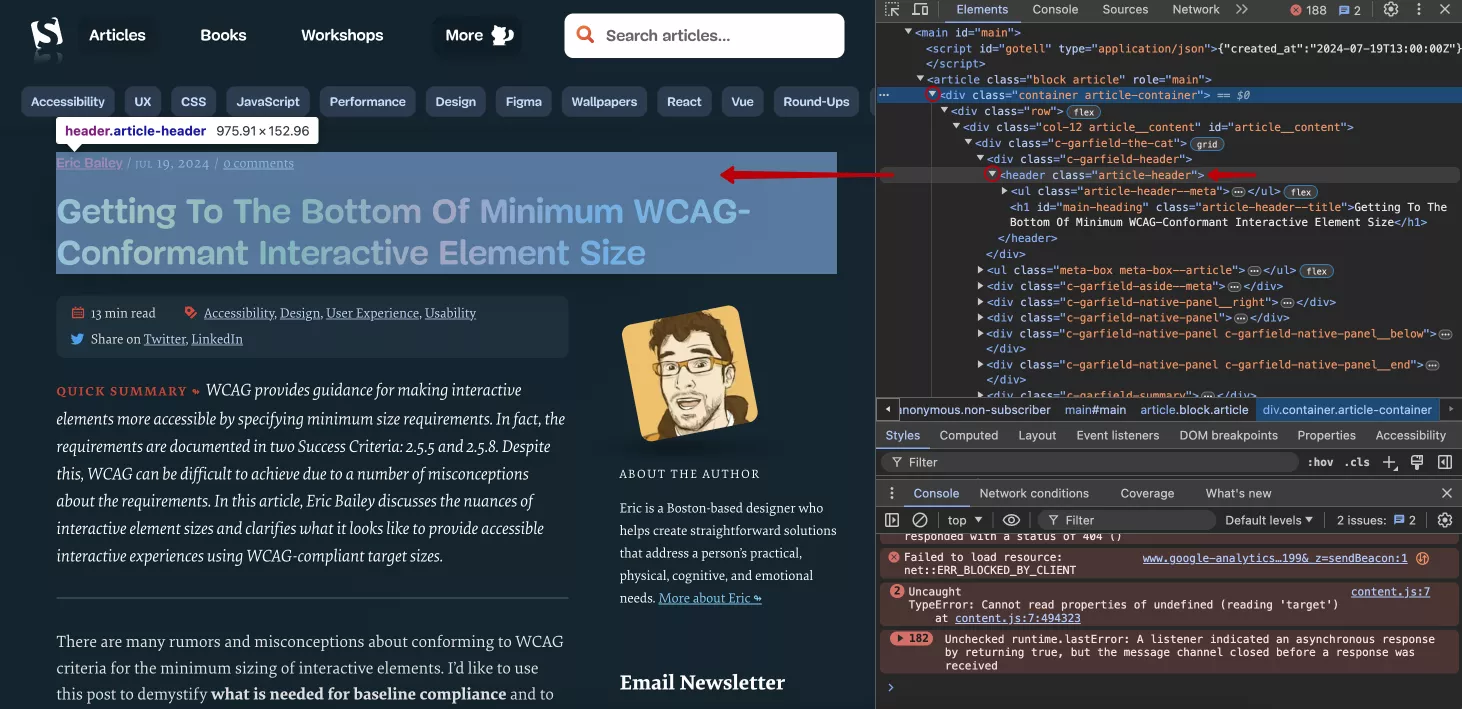
Есть еще один более простой способ «закрасить» элементы на странице. Для этого в Chrome DevTools сначала нажмите на стрелку с пунктирным квадратом сверху слева (инструмент Inspector), а затем на самой странице выберите интересующий вас элемент.
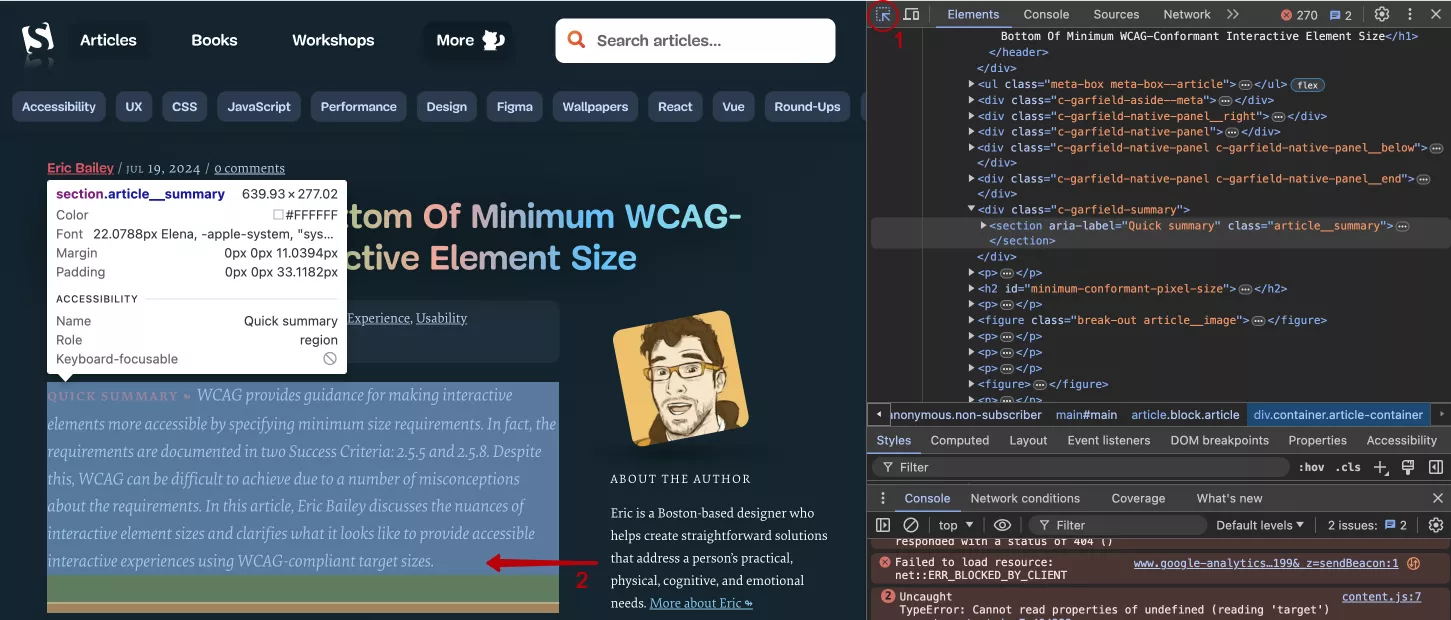
Если вам будет интересно, зайдите на любой другой сайт, откройте Chrome DevTools и нажимайте на все подряд. Не бойтесь что-нибудь сломать, потому что все изменения происходят только на вашей стороне. Это отличная возможность посмотреть на внутреннюю кухню показа сайтов в браузере.
Зачем нужна семантическая верстка для SEO
Семантическая верстка — это один из способов разметки страниц документов с помощью семантических HTML-тегов на основе определенной логики и иерархии. Не существует единого правила или шаблона, по которому веб-мастер верстает сайт.
Понятие «семантическая верстка» нигде не закреплено, это лишь способ, очерченный в рамках сообщества. Сейчас существует только один стандарт WHATWG, который был создан сотрудниками компаний Apple, Mozilla и Opera в 2004 году. В нем четко расписаны определения и правила взаимосвязи всех семантических тегов. Спецификация признана всеми известными сегодня корпорациями: Google, Apple, Mozilla, Opera.
Во-первых, семантическая верстка не является фактором ранжирования Google. Во-вторых, этот способ верстки — не панацея от проблем, связанных со сканированием страниц на вашем сайте. Это только один из проверенных на практике многими специалистами метод улучшения понимания Google Bot’ом вашего контента с последующими положительными последствиями.
Улучшенный анализ содержимого и структуры страницы для поискового бота
Семантический HTML предоставляет поисковым системам четкую структуру вашего контента. Дает им понять контекстные связи между разными его частями, правильно идентифицировать приоритетность содержимого.
Более простое определение важных частей страницы
Семантические теги указывают поисковым ботам на важную часть контента. Например, при правильном формировании заголовков H2 с релевантными ключевыми запросами попадаем в раздел «People Also Ask» в выдаче.
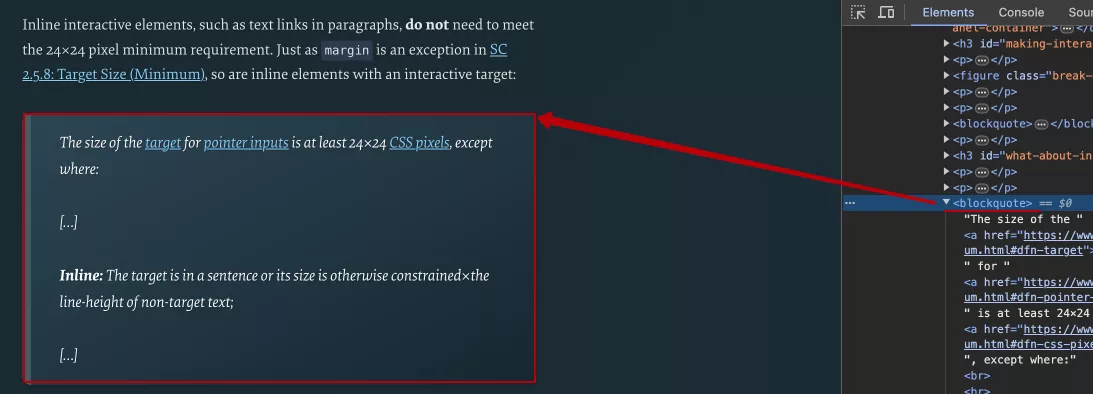
Или с помощью тега <blockquote> показывают, что текст внутри этого элемента является цитатой другого автора или источника. Это очень важный инструмент, сигнализирующий краулеру (поисковому боту), что определенный контент оригинальный и соответствует нормам авторского права. Например, на странице статьи, которую я приводил в качестве примера, ниже есть цитаты со всеми необходимыми ссылками на первоисточники, оформленные через семантический тег <blockquote>.
Облегченный парсинг страниц
SEO-специалистам намного проще находить блоки осмысленного кода, чем искать в бесконечных divʼах и spanʼах. Например, с помощью расширения браузера Chrome Xpath* легко парсить (собирать) содержание всех цитат из статьи, написав просто название тега вместо цепочек div.

*XPath расшифровывается как XML Path Language (язык путей XML). Это расширение использует синтаксис, отличный от XML, чтобы обеспечить гибкий способ адресации: указания на разные части XML-документа или, в нашем случае, HTML-документа.
Улучшенная доступность страницы
Семантические элементы HTML упрощают людям с инвалидностью потребление контента. Например, слабовидящие люди не видят фотографии на вашем сайте, но соответствующее программное обеспечение позволяет им слышать альтернативный текст, описывающий изображенное на фотографии. Альтернативный текст оформляется с помощью атрибута alt внутри тега <img>.
Этот фактор напрямую не влияет на SEO, но наличие данного функционала на вашем интернет-ресурсе улучшает опыт пользователей.
Популярные ошибки в использовании семантических тегов
Правильно применить семантический HTML в верстке умеет не каждый специалист. Довольно редко встречаются случаи, когда верстальщик логически использует весь необходимый арсенал соответствующих тегов при создании страниц. На это уйдет много времени и денег, так что зачем заморачиваться, когда под рукой есть много дешевых CMS-инструментов с минимальным взаимодействием с кодом.
Но на базовом уровне нужно знать, как работает тот или иной тег. Далее рассмотрю перечень самых частых ошибок, которые допускают веб-мастера при создании HTML-разметки.
Неправильно оформленные списки
Очень популярная ошибка, которая встречается при оформлении списков. Когда вместо тега <ul> или <ol> разработчики используют комбинацию тегов <span> и <p>. В обертку <div> добавляются параграфы, а перед каждым пунктом ставится линейный тег s<pan> с дефисом, как показано ниже.
<div>
<p><span>- </span>item 1</p>
<p><span>- </span>item 2</p>
<p><span>- </span>item 3</p>
</div>В таком случае список выглядит так.

Или в обертку <div> добавляются элементы, разделенные специальным тегом <br>, который соответствует новой строке.
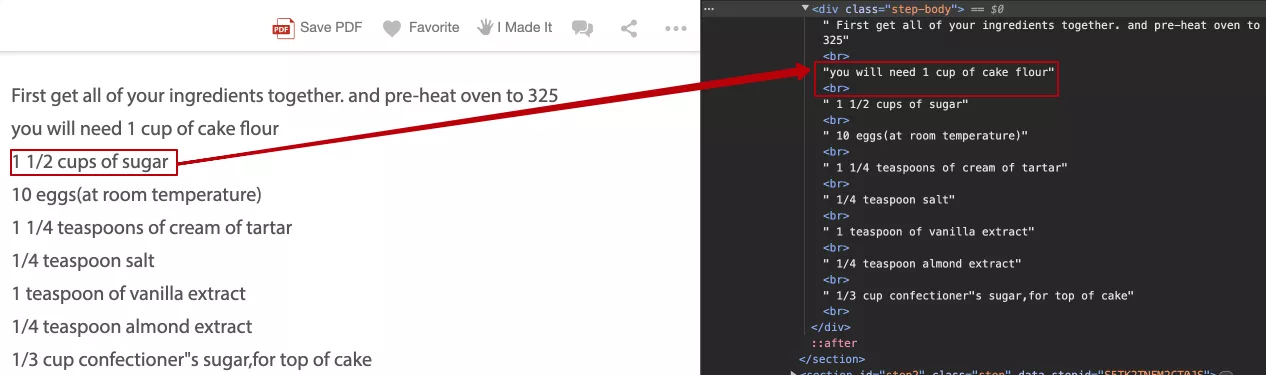
Чтобы не допускать подобных ошибок, необходимо использовать самый распространенный семантический тег <ul> для маркированного и <ol> для нумерованного списка, внутри которых нужно разместить теги li>, определяющие элементы списка.
<!-- Маркованный список -->
<ul>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
<!-- Нумерованный список -->
<ol>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
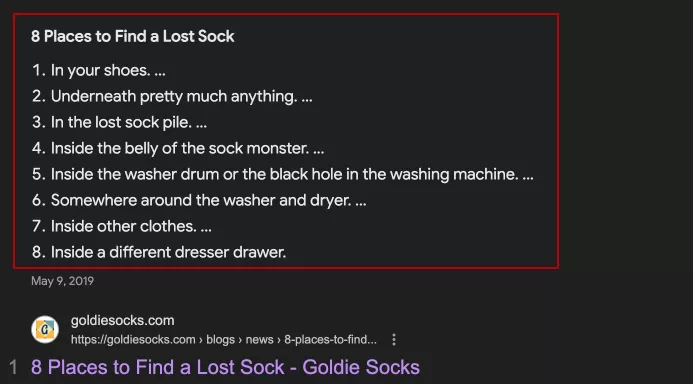
</ol>Выглядеть это будет вот так.

Правильное оформление списков позволяет получать отличные сниппеты (отрывки текста) в выдаче, которые привлекают потенциальных пользователей на страницу, увеличивая органический трафик.
Путаница со <strong> и <b>
Оба элемента предназначены для выделения текста жирным шрифтом. Они почти идентичны, но имеют разную цель. Бытует мнение, что тег <b> существует только для внешнего выделения текста, а тег <strong>, в свою очередь, для подчеркивания важности текста.
Эта практика не имеет ничего общего с правильной семантикой и спецификацией HTML, о которой я упоминал ранее в статье. Возможно, данный миф возник из-за практики в SEO-индустрии, когда пытались обмануть алгоритмы поисковиков и выделяли элементом strong все подряд. Из-за чего часто возникали случаи, когда сайт попадал под санкции Google из-за этого.
Анализируя стандарт HTML5 относительно тега <b> и тега strong>, видно четкую разницу между ними.
Элемент b предназначен для привлечения внимания с утилитарной целью:
- ключевые слова в аннотации к документу;
- названия продуктов в обзоре;
- слова-побуждения в интерактивном текстовом программном обеспечении;
- заглавие статьи.
Например:
<p>Наша компания занимается <b>продажей премиальной мебели</b> 10 лет</p>
Элемент strong предназначен для отделения действительно важной части текста от других частей контента:
- важность;
- серьезность;
- срочность.
Например:
<p>Благодарим за регистрацию. <strong>Никому не сообщайте ваш пароль!</strong></p>
Правильное использование даже таких, на первый взгляд, всем понятных тегов, дает вам преимущества. Для людей это просто выделенные жирным шрифтом части текста, а для поисковиков это четкие сигналы, на что нужно обратить внимание и какие ключевые фразы учесть.
Напоследок приведу пример своей версии разметки небольшого блока об IP-адресе.
<p>
<b>IP-адрес</b> — это уникальный числовой идентификатор для определения устройств в интернете или любой другой сети, использующей IP-протокол. IP-адреса позволяют устройствам обмениваться информацией между собой, находить и связываться друг с другом.
</p>
<p>
<strong>IP-адреса бывают двух типов</strong>: IPv4 (Internet Protocol version 4) и IPv6 (Internet Protocol version 6).
</p>
А вот так мы это видим:
IP-адрес — это уникальный числовой идентификатор для определения устройств в интернете или любой другой сети, использующей IP-протокол. IP-адреса позволяют устройствам обмениваться информацией между собой, находить и связываться друг с другом.
IP-адреса бывают двух типов: IPv4 (Internet Protocol version 4) та IPv6 (Internet Protocol version 6).
Использование JavaScript для ссылок вместо тега <a>
В некоторых случаях разработчики используют код JavaScript для оформления гиперссылок вместо соответствующего семантического тега анкор <a>.
К примеру, текст ссылки можно обернуть в тег <button> и в самом коде настроить событие клика:
<button id="myLink">Перейти на сторінку</button>
<script>
document.getElementById('myLink').addEventListener('click', function() {
window.location.href = 'https://example.com';
});
</script>Почему этот подход НЕ правильный? Следует разобраться:
- Индексация
Поисковые системы не сканируют и не индексируют JavaScript-ссылки так же эффективно, как традиционные ссылки с тегом <a> потому, что у краулеров нет возможности 100% выполнять код. Страницы, на которые ссылаются по JavaScript, не включаются в индекс поисковых систем. Это негативно влияет на видимость сайта. Иногда поисковые боты сталкиваются с трудностями при сканировании альтернативных языковых версий сайта, из-за чего в индекс не попадает почти половина всего ресурса. - Аналитика
Отслеживание нажатий на JavaScript-ссылки более сложное, поскольку аналитические инструменты эффективнее работают с традиционными ссылками. Это усложняет анализ пользовательского поведения на сайте. - Кроссбраузерная совместимость
JavaScript-ссылки работают по-разному в различных браузерах, полностью недоступны в более старых версиях браузеров или тех, которые имеют отключенный JavaScript по умолчанию.
Пустые заголовки
Бывают случаи, когда на странице есть пустые заголовки, и чаще всего это заголовки второго уровня H2. Причины возникновения этой ошибки разные: разработчик пропустил его во время верстки, или это баг, возникший при автоматическом создании страниц по шаблону.

Почему на такую незаметную с первого взгляда ошибку следует обращать внимание? Потому что заголовки H1–H3 — важные сигналы для поисковых ботов по определению тематики страницы. Пустое заглавие H2 вводит их в заблуждение, что негативно сказывается на индексации.
Старайтесь избегать подобных ситуаций: удаляйте пустые заголовки или заполняйте их, если на том месте должен находиться блок контента.
Ошибки с заголовком H1
Во-первых, элемент H1 используется на странице только один раз. Во-вторых, тег H1 должен открываться и закрываться, а внутри нужно добавить фразу, кратко описывающую содержание страницы, например: <h1>Как найти свои носки?/<h1>.
Относительно популярна ошибка, когда внутрь элемента H1 вписывают теги <img> или вообще целый параграф <p>. Это неправильно и лучше избегать подобной практики.
Выводы
- Семантическая верстка — это подход к размещению HTML-элементов с акцентом на логическое структурирование и значение контента. В ней используются семантические теги, которые передают содержание и иерархию частей страницы.
- Основные семантические HTML-теги:
- <header> — вступительная часть блока, которая включает заголовки, содержание, навигацию.
- <nav>— элемент навигации для ссылок на страницы или внутренние части страницы.
- <main> — основной контент страницы, который может содержать другие блочные теги.
- <article> — самостоятельный контент, например статья или комментарий.
- <section> — тематическая часть контента, например разделы статьи.
- <footer> — нижний колонтитул, содержащий информацию о секции или разделе.
- <aside> — боковой элемент, например для рекламы или дополнительного материала.
- <menu> — элемент меню, используемый для навигации или управления сайтом. Помогает Google Bot определять главное меню на страницах.
- Важно придерживаться логики и правил иерархии для правильной структуры страницы. Например, <main> и <article> — наиболее значимые элементы, тогда как <section> разбивает блоки на смысловые части.
4. Семантическая верстка имеет такие преимущества для SEO:
- помогает поисковикам лучше анализировать содержимое и структуру страницы;
- выделяет важные части контента;
- облегчает парсинг страниц и улучшает доступность для людей с ограниченными возможностями.

 2
2
 0
0
 2
2
Свежее
Почему сегментация — ключ к эффективному ecommerce-маркетингу
В этой статье я расскажу, как сегментация помогает превратить хаотичный маркетинг в точный и персонализированный
Как учитывать сезонность при разработке SEO-стратегии
Учет сезонных тенденций позволяет заранее подготовиться и «поймать волну» в нужные месяцы. Как именно это сделать, рассказываем в материале
Как вывести приложение из «мертвой точки» и увеличить количество органических просмотров на 142 730% в App Store
Три рынка, локальные поисковые привычки и системная работа с метаданными и видимостью в App Store