Веб-архив — это проект web.archive.org, на котором хранятся разные версии всех сайтов с момента их создания при условии, что нет запрета на сохранение ресурса. Благодаря наличию сохраненных копий в веб-архиве, доступно восстановление сайта даже при отсутствии резервной копии. Также в веб-архиве можно найти интересный контент из закрытых сайтов конкурентов, который активно используют создатели PBN-сеток сайтов.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
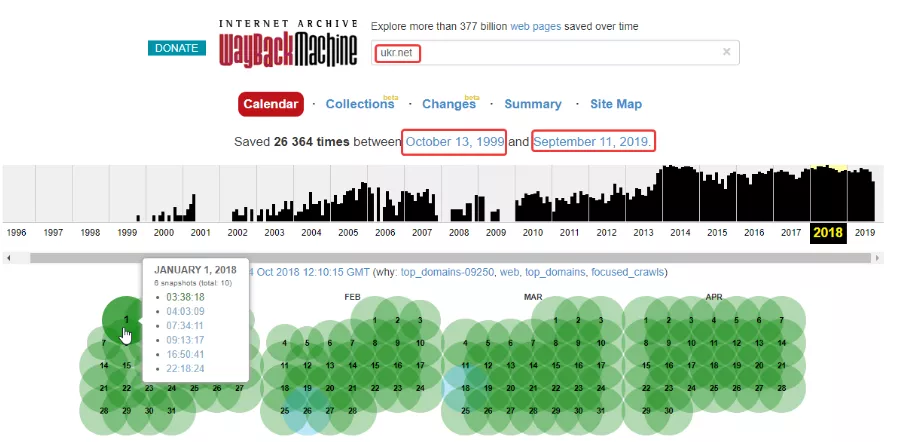
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
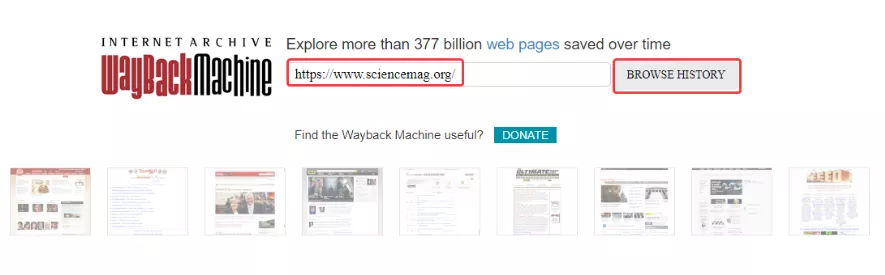
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
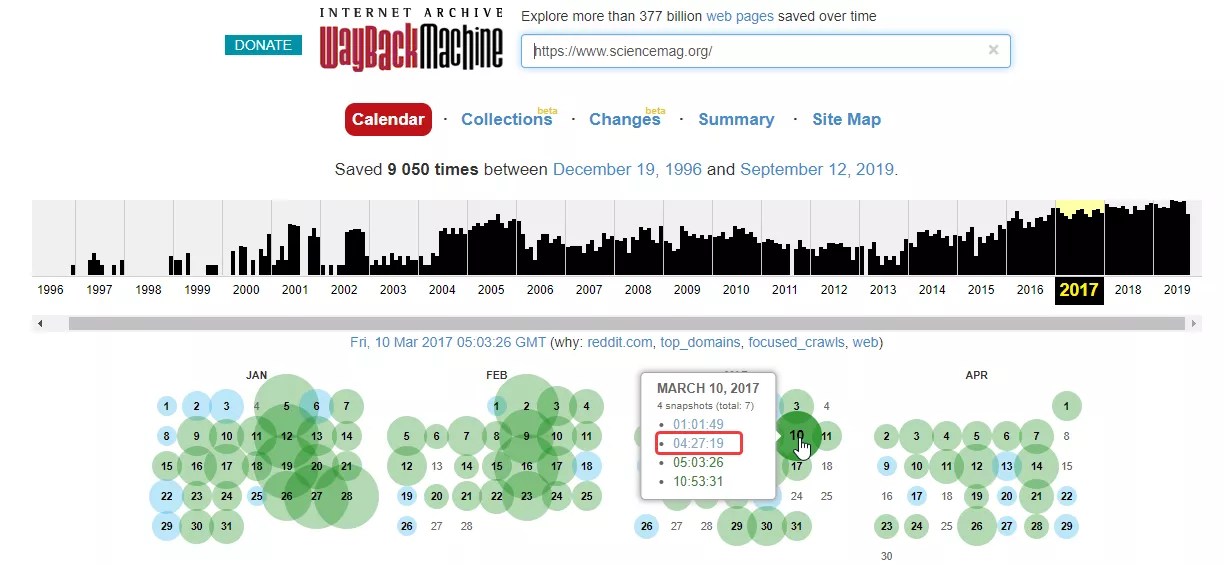
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Как добавить современную версию сайта в веб-архив
Для уверенности в том, что все нужные версии собственного проекта будут сохранены в веб-архиве, желательно самостоятельно инициировать сканирование сайта. Для этого введем в разделе «Save Page Now» домен сайта и нажмем «Save page»:
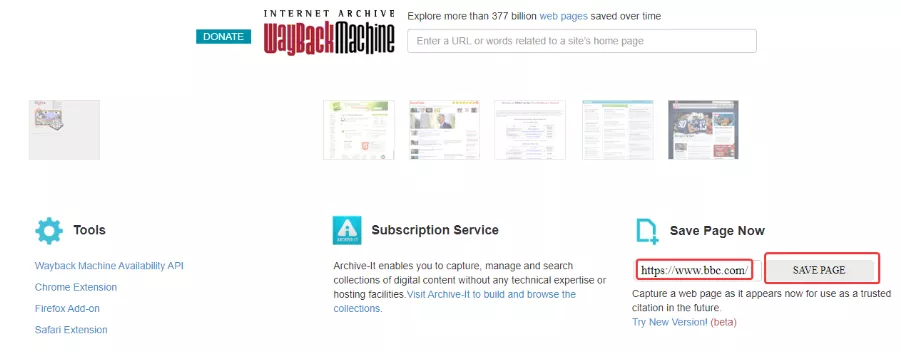
После этого в архив будет добавлена текущая версия сайта. На всякий случай повторяйте подобную процедуру перед всеми существенными изменениями сайта и после их осуществления.
Как запретить добавление сайта в веб-архив
Чтобы сайт не был доступен в веб-архиве, пропишите запрет в файле robots.txt. Для этого нужно зайти в корневой каталог сайта на панели управления хостинг-провайдера и выбрать редактирование данного файла:
Запрет устанавливается с помощью такого кода:
User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: /После этого удалятся существующие версии проекта, а также не будет осуществляться копирование сайта в архив пока домен функционирует и в файле robots.txt присутствуют данные настройки. Когда закончится регистрация доменного имени старые версии сайта вновь станут доступны в веб-архиве.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
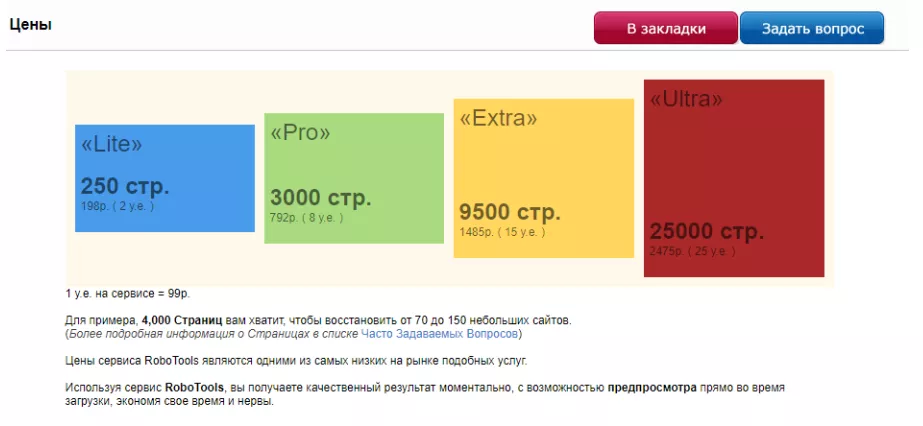
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в демо-версии, после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
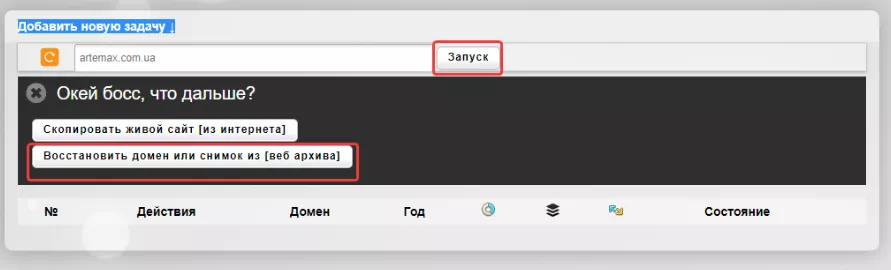
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
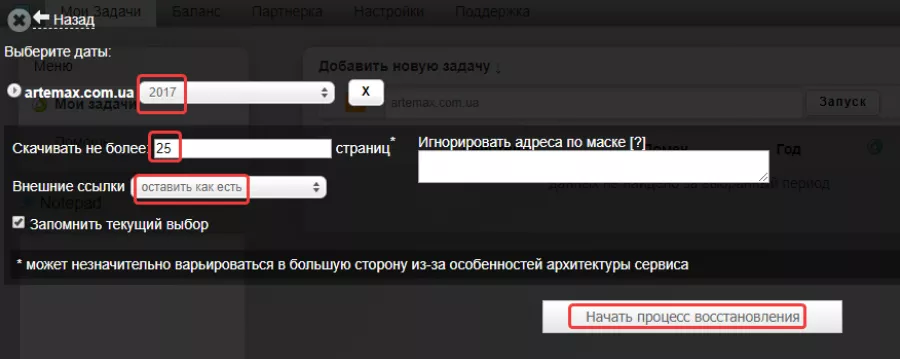
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
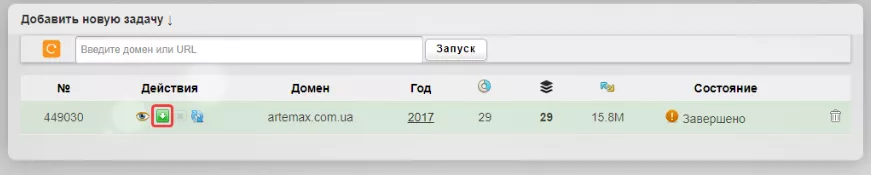
Затем нажимаем «Все ОК, собрать ZIP-архив»:
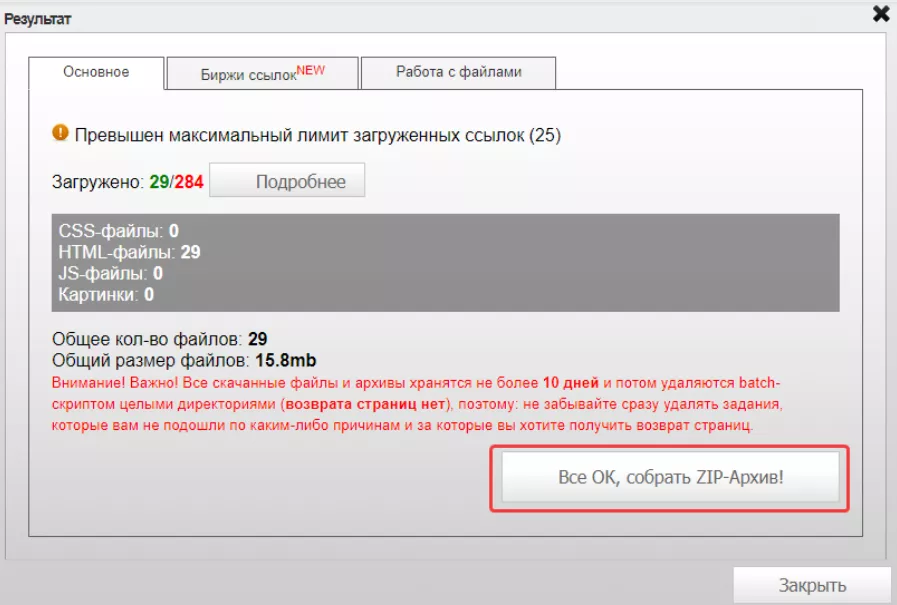
После этого нажимаем «Скачать архив»:
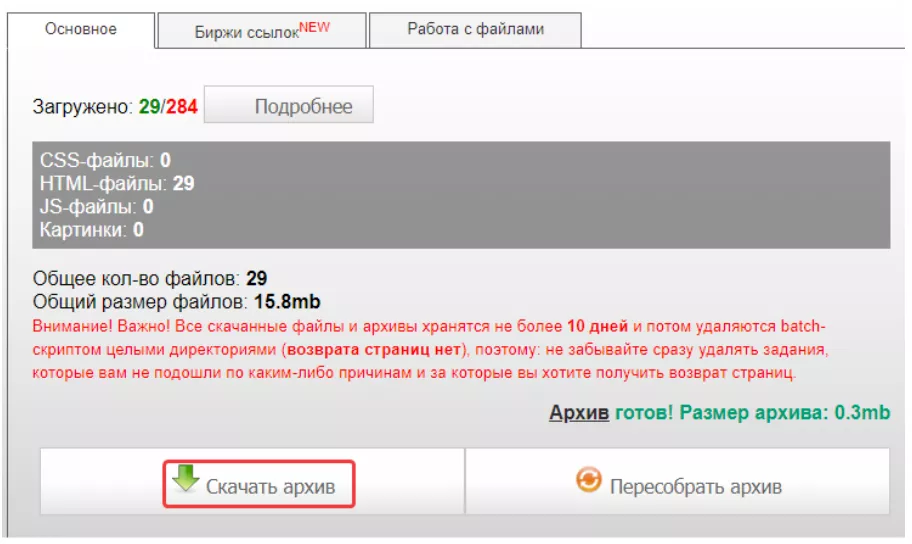
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
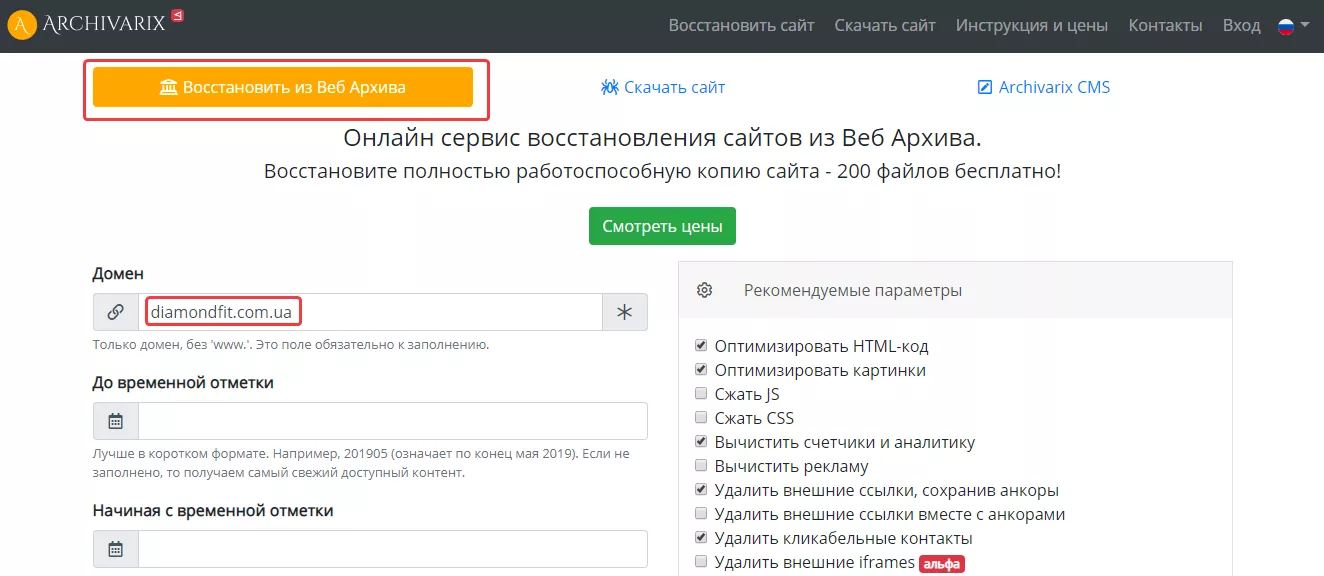
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
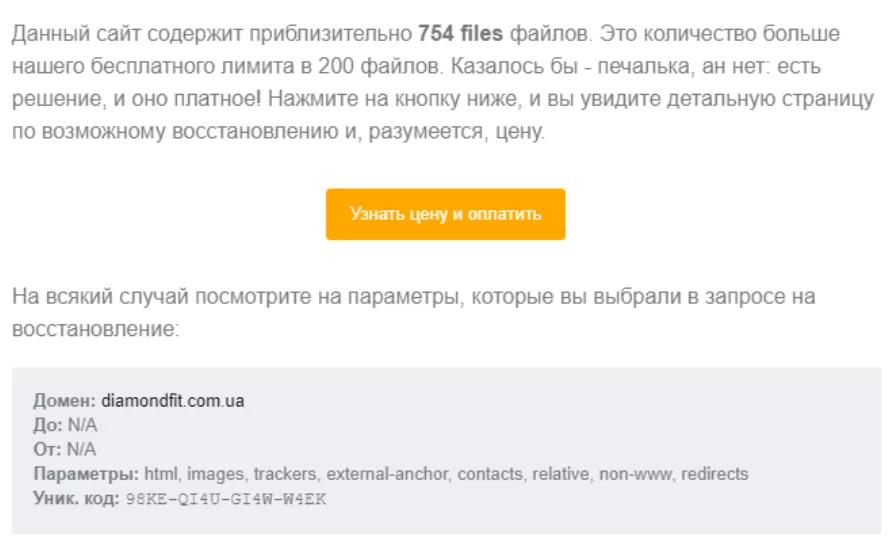
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
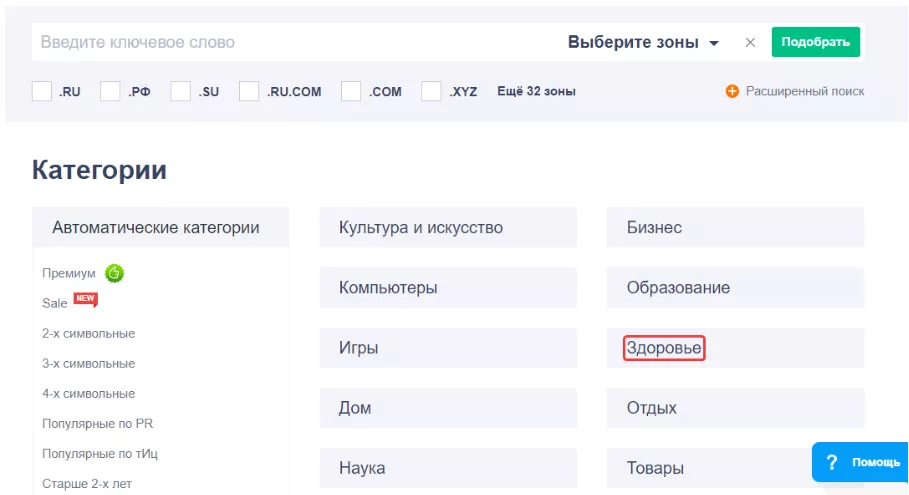
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
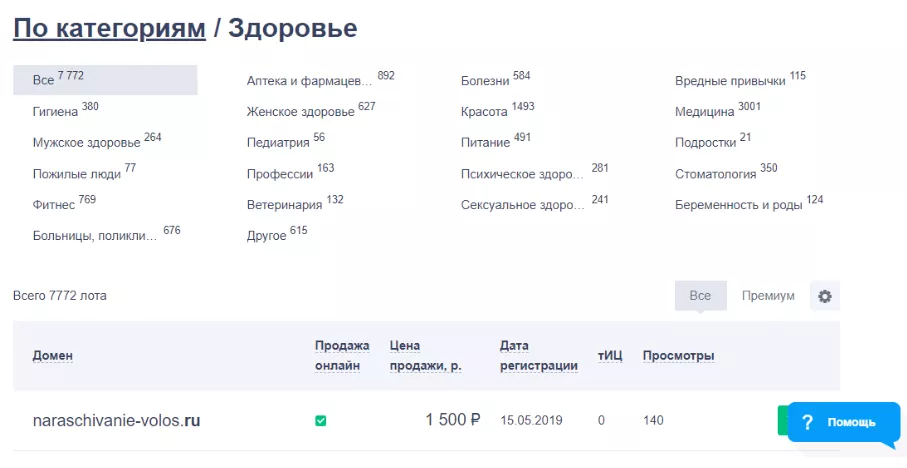
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Запомнить
- Веб-архив — масштабный бесплатный проект, созданный для сохранения всего контента, представленного в интернете, даже после его удаления на исходном сайте.
- Веб-архив полезен для анализа сайтов клиентов и конкурентов, отслеживания изменений на собственном проекте, проверки доменов перед покупкой.
- Используя данные веб-архива, полученные с помощью онлайн-сервисов, доступно восстановление сайта без бэкапа.
- В веб-архиве много контента, в том числе уникальные статьи почти на любую тематику.

 8
8
 2
2
 2
2
Свежее
Невидимый маркетинг: как интерфейс и коммуникация влияют на выбор клиента
Как перестать терять клиентов и увеличить прибыль без раздувания расходов
От «бизнеса по залету» до экосистемы из трех десятков компаний: 20 лет Netpeak
За 20 лет Netpeak стала уверенным игроком на международном рынке, в частности в Европе, на Ближнем Востоке, в Центральной Азии и в Америке, с 600 сотрудниками и офисами в Украине, Болгарии, Казахстане и США
7 ошибок в Google Ads, которые влияют на результаты рекламной кампании
В этой статье разберу типичные ошибки, с которыми часто приходится сталкиваться: пять базовых и две неочевидные. Для каждой покажу, как выявить проблему, исправить её и отследить, какое влияние она оказывает на рекламные кампании