В мире поисковой оптимизации (SEO) индексация является одной из ключевых фаз, которая определяет видимость веб-сайта и его отдельных страниц в поисковых системах — Google, Bing, Yahoo и других. В этой статье я расскажу, что такое индексация и как она работает, как проверить индексирование сайта и как правильно закрыть от этого процесса сайт.
Что такое индексация простыми словами
Индексация — процесс, в котором поисковые роботы (поисковые пауки или боты) сканируют веб-сайты для сбора информации об их содержании. Эти роботы переходят по ссылкам между страницами и анализируют контент. После сбора данных они добавляют информацию в индекс поисковой системы.
Индекс — это большая база, в которой содержатся собранные данные о страницах веб-сайтов. Он помогает поисковым системам быстро находить страницы, соответствующие запросам пользователей. Чем больше качественного и релевантного контента собрано в индексе, тем эффективнее будет поиск для пользователей.
Как проходит индексирование сайта
Чтобы разобраться в теме «Как запретить индексацию сайта?», стоит сначала понять процесс индексирования.
Поисковые роботы начинают индексацию с перехода на сайт. Представим, что вы работаете с сайтом https://netpeak.net/ и хотите его проиндексировать. Для этого есть следующие этапы:
- Поисковый робот начинает со сканирования стартовой страницы сайта. Он проверяет HTML-код, изображения, ссылки и другие элементы на странице.
- Переход по ссылкам на другие страницы. Поисковый робот переходит по ссылкам, найденным на главной странице, и сканирует другие. Например, если на главной странице есть линк на https://netpeak.us/blog/category/seo/, робот перейдет на него.
- Поисковый робот анализирует содержимое посещенных страниц, собирая текст, изображения, видео и другие элементы содержимого. На странице https://netpeak.us/blog/category/seo/ есть перечень статей и другая информация. Именно это и нужно роботу.
- После сбора информации поисковый робот добавляет страницу в свой индекс. Это помогает поисковой системе находить ее при введении пользователем соответствующих запросов.
- Обновление и переиндексация. Поисковые роботы периодически возвращаются на каждый сайт, чтобы обновить информацию и найти новый контент. Они сканируют эти изменения и обновляют индекс.
- Показ в результатах поиска. Когда пользователь вводит запрос в поисковую систему, она использует свой индекс для поиска наиболее подходящих страниц. Например, когда пользователь ищет «How to Create SEO-Friendly Website Architecture», поисковая система использует индекс для нахождения страницы https://netpeak.us/blog/how-to-create-seo-friendly-website-architecture-best-practices/ и отображает ее в результатах:
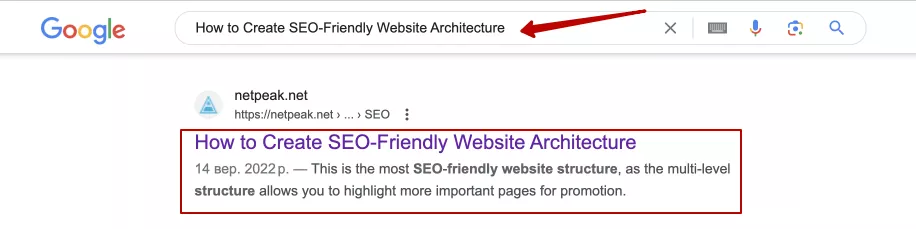
Индексация сайта — сложный процесс, который позволяет поисковым системам эффективно находить и отображать релевантные страницы в результатах поиска. Это помогает как SEO-специалистам, так и владельцам сайтов улучшить видимость и обеспечить оптимальное взаимодействие с поисковыми роботами.
Как проверить индексирование сайта
Проверка индексации важна, поскольку позволяет убедиться, что поисковые системы корректно понимают веб-сайт и содержимое, которое передается пользователям. Узнать, проиндексирован ли сайт можно следующими методами:
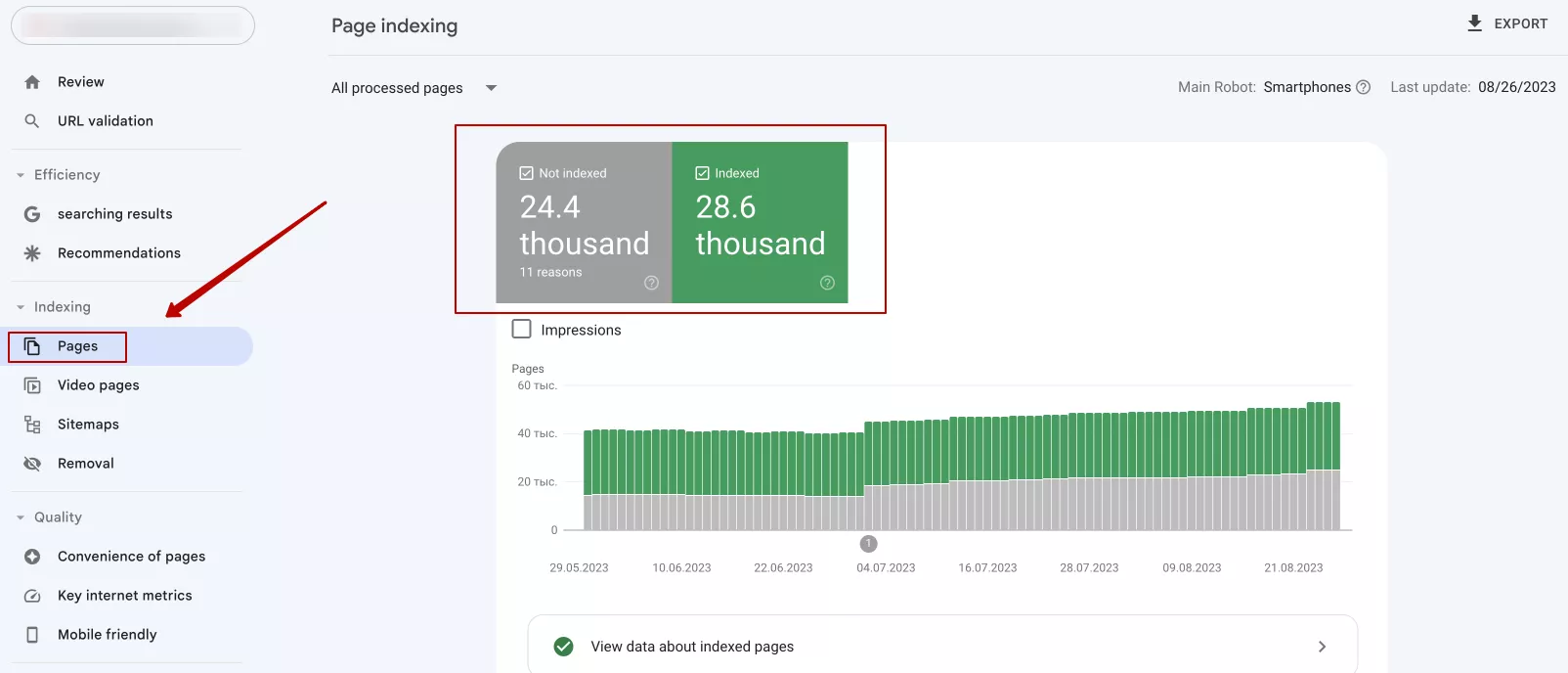
1. Использовать Google Search Console. Если вы владелец сайта, обязательно зарегистрируйте его в Google Search Console. Это бесплатный инструмент от Google. Он предоставляет информацию о том, как Google видит ваш вебсайт, отчеты об индексации страниц, обнаружении ошибок и многое другое. Чтобы проверить индексирование через Google Search Console, перейдите во вкладку «Pages». Там можно увидеть, сколько страниц проиндексировано, а также с какими есть проблемы:
2. Использовать команду «site:» в поисковых системах. Она позволяет проверить, сколько страниц конкретного сайта проиндексировано в определенной поисковой системе. Например, ввод «site: netpeak.net» в Google покажет все страницы, которые индексированы с этого сайта:
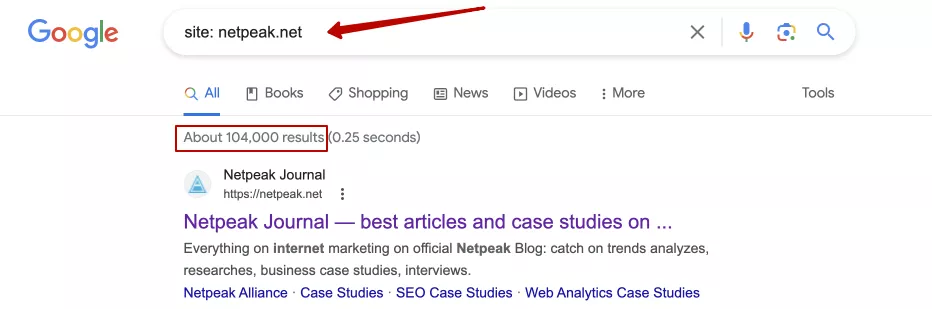
Впрочем, это довольно неточный способ получения информации об индексации сайта и его отдельных страниц. Но при этом — это полезный метод, ведь в комплексе с другими операторами, позволяет найти определенные страницы с вложениями/параметрами, которые должны быть скрытыми от индексации на нашем сайте. Также этот способ позволяет узнать об индексации отдельных страниц или сайта конкурентов.
3. Существуют также различные сервисы, которые информируют об индексации сайта. Например, Netpeak Checker позволяет выяснить, есть ли сайт или страницы в выдаче. Другие сервисы: Ahrefs, SEMrush и т. д. — помогают отслеживать индексацию и выявлять возможные проблемы.
Собственно, почитайте более подробно о шести способах проверки индексации сайта.
Как закрыть сайт от индексации: эффективные методы
Надлежащий контроль того, как веб-сайт и его содержимое индексируются поисковыми системами, является важной частью SEO-оптимизации. В определенных случаях закрытие страниц от индексации может быть уместным и полезным. Речь о таких страницах:
- Тестовый или разработческий контент. Такая страница часто является незавершенной, непригодной для публичного просмотра или может содержать ошибки. Закрыв эти страницы от индексации, исчезает вероятность случайной публикации недоделанного контента.
- Страницы с конфиденциальной информацией. Конфиденциальность данных всегда является приоритетом, и если на сайте есть страницы с личной, финансовой или другой конфиденциальной информацией, их следует закрыть от индексации. Это может быть страница с учетными данными пользователей, платежные данные и т. д.
- Дублированный контент. Если на сайте есть страницы с контентом, который повторяется на других страницах, это может привести к проблемам с ранжированием в поисковых системах. Закрытие дублированного контента от индексации поможет обеспечить лучшую видимость и последовательность основной страницы.
- Внутренние административные страницы. Нужны для управления содержимым сайта или его настройками и не должны быть доступны широкой публике. Закрытие от индексации позволит избежать возможного риска несанкционированного доступа и сохранит контроль над административной частью.
- Пользовательские страницы покупки или регистрации. Если на сайте есть страницы с корзиной покупок, регистрацией, оформлением заказа, страницы поиска, сравнения, сортировки, фильтров по цене и выводом количества товаров на страницах, их стоит закрыть от индексации. Ведь они формируют дубли.
Понимание процесса индексации поможет в эффективной оптимизации сайта, ведь таким образом происходит открытие и закрытие важных и неважных страниц сайта.
Как закрыть сайт от индексации
Есть 4 основных метода, которые помогают управлять индексацией.
Метатег «robots»
Метатег «robots» является одним из самых распространенных способов контроля индексации веб-страниц. Есть 4 главных правила, которые можем использовать в метатеге «robots»:
- «index» — разрешаем боту индексацию;
- «noindex» — запрещаем индексацию;
- «follow» — разрешаем боту переходить по внутренним ссылкам;
- «nofollow» — запрещаем переход по ссылкам.
Добавление метатега со значением «noindex» в код страницы в блоке <head> запрещает поисковым системам индексировать ее. Он прописывается так:
<meta name= «robots» content= «noindex, follow» />Где «noindex» — правило, запрещающее индексацию страницы поисковыми системами. Стоит добавить правило «follow», позволяющее перейти работу по ссылкам на другую страницу и продолжить исследовать сайт.
Пример использования:

Еще один вариант реализации этого правила, а именно:
<meta name= «robots» content= «noindex, nofollow» /> Где «nofollow», соответственно, запрещает работу переход по ссылкам на другие страницы сайта.
Если заменить «robots», например, на «bing», инструкция будет распространяться только на робота поисковой системы Bing. Но если определенная страница должна быть скрыта от индексации, рекомендую прописывать инструкцию для всех поисковых роботов.
Метатег «robots» особенно полезен для отдельных страниц, которые необходимо защитить от общего доступа.
Важно! Google справка утверждает: «Чтобы правило «noindex» работало, файл robots.txt не должен блокировать поисковому роботу доступ к странице. Иначе он не сможет обработать ее код и не обнаружит правило noindex. В результате контент с такой страницы по-прежнему будет появляться в результатах поиска, например, если на нее ссылаются другие ресурсы».
X-Robots-Tag в ответе сервера
Заголовок «X-Robots-Tag» может быть установлен на уровне сервера или на уровне отдельных страниц для управления индексацией поисковыми системами. Он указывает поисковым системам, как обрабатывать конкретную страницу или ресурс. Заголовок «X-Robots-Tag» может содержать те же директивы, что и метатег «robots»:
X-Robots-Tag: noindex, nofollowЗаголовок указывает поисковым системам не индексировать страницу ( «noindex») и не переходить по ссылкам на ней ( «nofollow»). Правило можно прописать в разных вариациях.
Установить «X-Robots-Tag» для конкретной страницы или ресурса на сервере можно в настройках к серверу или использовать файл конфигурации, который указывает на HTTP-заголовки, которые нужно установить для конкретных запросов.
Чтобы настроить X-Robots-Tag для Apache сервера, нужно добавить следующий код в файл .htaccess:
Header set X-Robots-Tag «noindex, nofollow»Этот пример устанавливает заголовок X-Robots-Tag для всех страниц сайта и запрещает их индексацию и переход по ссылке.
После внесения изменений в .htaccess Apache, нужно перезагрузить веб-сервер чтобы изменения вступили в силу.
Для настройки X-Robots-Tag для Nginx сервера, нужно использовать дополнительный модуль nginx, который называется «add_header». Этот модуль позволяет добавлять HTTP заголовки к ответам сервера.
- Откройте конфигурационный файл для вашего сайта.
- Найдите блок «server», соответствующий вашему сайту, и добавьте или отредактируйте строку «add_header» в этом блоке, чтобы добавить заголовок X-Robots-Tag. Например:
add_header X-Robots-Tag «noindex, nofollow»В этом примере, как и в предыдущих, заголовок X-Robots-Tag установлен как «noindex, nofollow», что запрещает индексацию и переход на другие страницы сайта по ссылке. После внесения изменений в конфигурационный файл, нужно перезагрузить веб-сервер Nginx, чтобы изменения вступили в силу.
После установки «X-Robots-Tag» поисковые системы будут придерживаться указанных директив по индексации и переходу по ссылкам на указанной странице или ресурсе.
HTTP-код 403 (Forbidden)
HTTP-код 403 (Forbidden) указывает на то, что запрос к серверу был корректным, но сервер отказался обрабатывать его из-за ограничения доступа. Этот код можно использовать для закрытия страницы от индексации поисковыми системами, и вот как это обычно делается:
1. Создание страницы для отображения сообщения о запрете. Сначала можно создать страницу, на которую будут перенаправляться пользователи в случае отказа в доступе. Например, страница «forbidden.html» и содержимое, которое стоит отобразить пользователям, когда они пытаются получить доступ к запрещенной странице. Если пользователь зайдет на такую страницу, она должна иметь соответствующее оформление. И если разместить на ней ссылку на главную (например), пользователь не потеряется, а просто перейдет на другую страницу сайта.
Можно прописать информацию: «Извините, но вы не имеете доступа к этой странице. Свяжитесь, пожалуйста, с администратором сайта для получения доступа». Стоит отметить, что 403 код можно использовать, чтобы закрыть не только определенные страницы от индексации, а и весь сайт. Это может быть полезным, например, когда нужно ограничить доступ пользователям из других регионов/стран.

2. Использование HTTP-кода 403 и настройка robots.txt. Нужно настроить сервер так, чтобы он посылал код ответа сервера403 при попытке доступа к запрещенной странице и, одновременно, указать поисковым системам не сканировать эту страницу в файле robots.txt:
- HTTP-код 403. Следует настроить веб-сервер (например, через файл «.htaccess» для Apache) так, чтобы он посылал HTTP-код 403 для запрещенной страницы;
<Файлы «forbidden page.html»>
Приказ разрешить, запретить
Отрицать от всех
</Files>где «forbidden page.html» — это путь к странице, которую нужно запретить.
- Файл robots.txt. В файле robots.txt следует добавить следующую строку для страницы, которую надо запретить к сканированию.
User-agent: *
Disallow: /forbidden page.htmlЭта запись указывает поисковым системам, что страницу /forbidden page.html следует игнорировать и не сканировать.
После выполнения этих шагов, когда пользователи попытаются получить доступ к запрещенной странице, сервер отправит им код ответа 403 и может перенаправить на созданную страницу «forbidden.html». Поисковые системы также будут игнорировать эту страницу через настройки в файле robots.txt, и она не будет индексирована в их базе данных.
Важно! Справка Google рекомендует не злоупотреблять 403 кодом для управления индексацией. В будущем такая страница может быть удалена из Google поиска. Когда робот попадает на страницу с 403 кодом, он видит ошибку на стороне пользователя, следовательно, нужно вернуться позже. После повторных посещений и получения того же кода ответа, эти страницы могут быть удалены из Google поиска.
Защита страниц паролем
Если нужно ограничить доступ к страницам не только для поисковых систем, но и для пользователей, можно использовать защиту паролем. Она предполагает, что пользователь должен ввести правильный логин и пароль для получения доступа к сайту или отдельной странице.
Такой метод особенно полезен в случаях:
- Когда нужно защитить административный интерфейс. Если есть административная панель или другой раздел сайта, к которому должен иметь доступ только ограниченное количество пользователей (например, администраторы), HTTP-аутентификация поможет обеспечить доступ только этим пользователям.
- Тестовые или разработочные сайты, страницы. В случае разработки или тестирования сайта можно использовать HTTP-аутентификацию.
- Специализированные услуги или ресурсы. Некоторые веб-сайты предоставляют специализированные услуги или ресурсы, к которым должны иметь доступ только определенные группы пользователей. HTTP-аутентификация помогает обеспечить этот ограниченный доступ.
- Защита от публичного индексирования. Если нужно защитить страницу или каталог от индексации поисковыми системами, HTTP-аутентификация может быть использована как дополнительный слой безопасности после запрета сканирования в файле robots.txt.
Этот способ обеспечивает высокий уровень безопасности и конфиденциальности для пользователей и обеспечивает доступ только тем, кто имеет соответствующие учетные данные.
Выводы
Индексация — неотъемлемая часть SEO-стратегии, которая помогает обеспечить надлежащую видимость и релевантность веб-сайта для целевой аудитории. Важно проверять индексацию, чтобы убедиться, что поисковые системы корректно понимают содержание, которое передается пользователям.
Однако есть страницы, которые по ряду причин стоит закрыть от индексации. Для этого используются следующие методы:
- метатег «robots»;
- X-robots-tag;
- HTTP-код 403 (Forbidden);
- защита страниц паролем.
Они помогают эффективно контролировать процесс индексации сайта и обеспечивают защиту конфиденциальной информации.

 0
0
 0
0
 0
0
Свежее
GA4 для eCommerce: какие показатели действительно влияют на доход, а какие — просто «для отчета»
Как перестать быть пассивным наблюдателем и начать искать в GA4 точки роста
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок
Meta (Facebook) Pixel Helper: что это такое и как его настроить?
В этой статье подробно рассмотрю, что это за инструмент, принцип его работы и как с его помощью проверить установку Pixel и передачу событий с сайта в кабинет Meta