Как работать с оконными функциями в Google BigQuery — подробное руководство
Количество данных стремительно растет. Растет и интерес к сервисам для их хранения и обработки. Один из сравнительно новых и качественных инструментов в области хранения и обработки больших массивов информации — облачная база данных Google BigQuery. Инструмент способен обрабатывать сотни тысяч строк в секунду. Если верить открытым источникам, среди множества инструментов, направленных на обработку Big Data, Google BigQuery предпочитают «М.Видео», «Юлмарт», «Связной», Ozon.Travel, «Эльдорадо», Onlinetours, Anywayanyday и «Вымпелком».
В работе BigQuery — более простой инструмент, чем MySQL и PostgreSQL, да и большинство других. Все потому, что в инструменте отсутствует часть работы, связанная с администрированием сервера. Оптимизацией работы базы занимается непосредственно Google. Второй приятный бонус — вам не придется тратиться на дорогостоящие сервера, так как вся информация в данном случае хранится и обрабатывается на серверах Google. Относительный минус — учебного материала по работе с BigQuery очень мало. На русском языке его практически нет. Я решил исправить сей обидный факт, поэтому знакомлю вас с некоторыми возможностями этой базы данных. Для дальнейшей работы вам необходимо скачать csv файл, который мы сейчас загрузим в BigQuery.
Загрузка данных в Google BigQuery из CSV файла
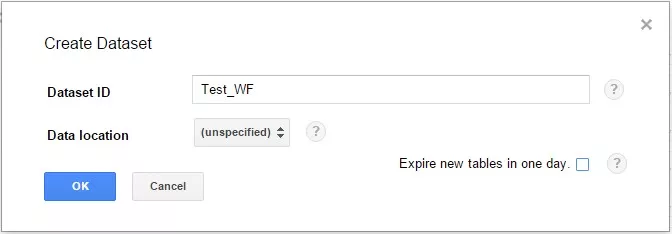
Научимся загружать данные в BigQuery. Этот навык пригодится для отработки на практике всех примеров запросов, описанных далее в статье. 1. Выбираем проект, в который нам необходимо загрузить таблицу. Жмем на кнопку меню напротив названия проекта и выбираем пункт «Create new dataset». 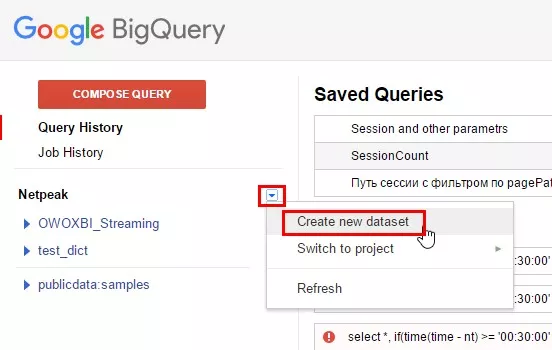
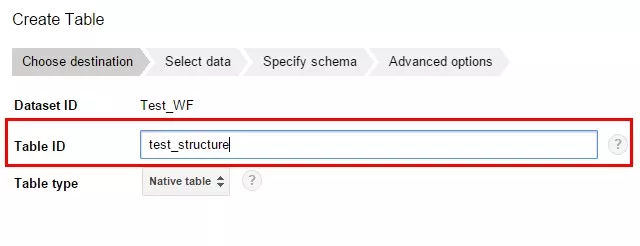
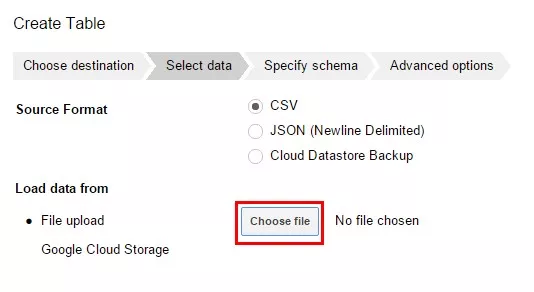
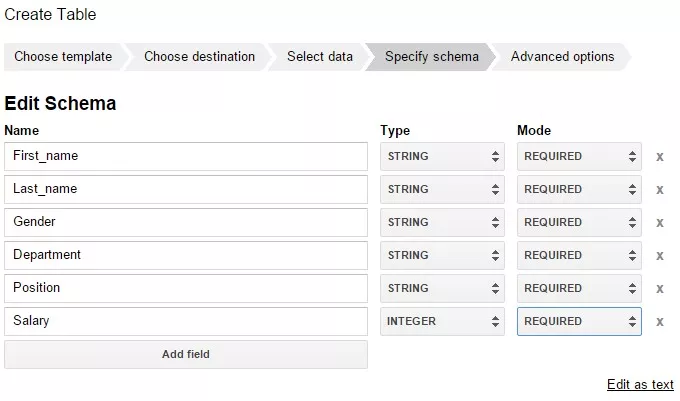
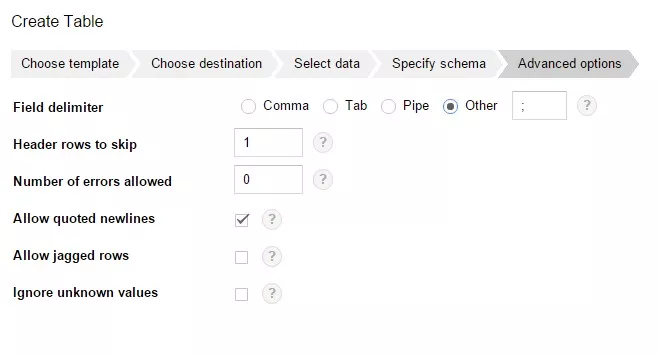

select *from Test_WF.test_structure

Оконные функции в Google BigQuery
Оконные функции — самые полезные в BigQuery. По сути, их действие схоже с агрегирующими функциями. Разница заключается в том, что при использовании агрегирующих функций необходимо группировать результат по полям, к которым агрегирующие функции не применяются. А оконные функции выполняют подобные вычисления без группировки, возвращая агрегированный нужным вам способом результат для каждой строки. Таким образом, этот тип функций не меняет выборку, а лишь добавляет в нее необходимую информацию. Давайте разберемся, что в данном случае подразумевается под окном.
Схематически работу оконной функции можно показать следующим образом. Возьмем функцию SUM (Salary) OVER (PARTITION BY Department), запущенную на загруженных ранее тестовых данных. Результат: 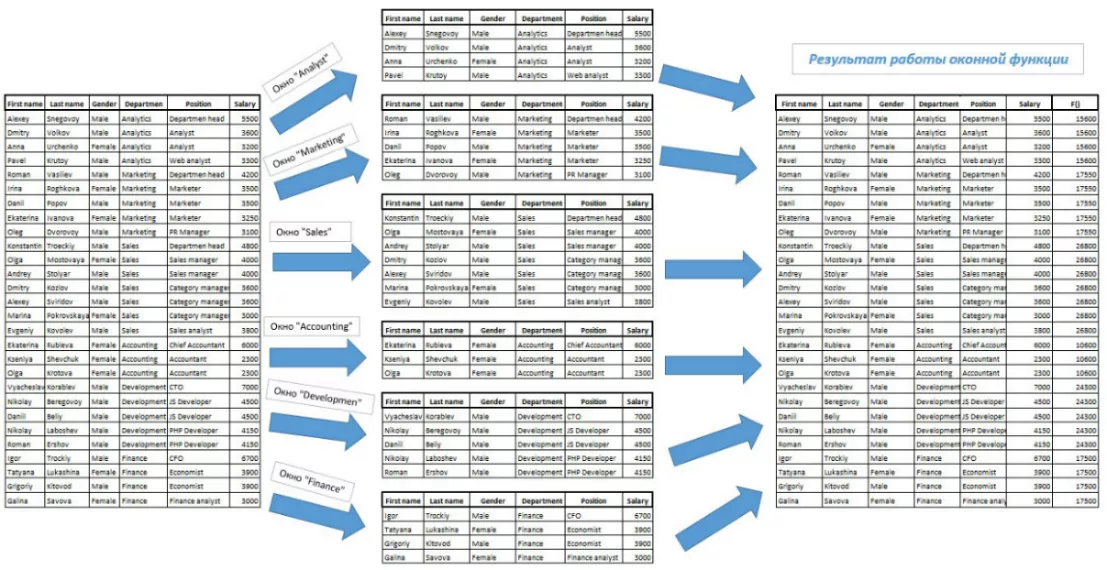
- Partition позволяет указать признак формирования окна, то есть признак, по которому вы будете разделять данные для агрегирования.
- Order позволит вам задать сортировку внутри окна.
- Window Frame дает возможность устанавливать смещение строк внутри окна по различным признакам, например, по времени.
Синтаксис оконных функций выглядит так: 
1. PARTITION BY
Определяет, по какому принципу будет разделен массив данных на окна. Вам необходимо прописать перечень полей, по которым вы хотите разделить таблицу, к которой обращается запрос. При использовании оконных функций вы не можете группировать данные с помощью GROUP BY в том же подзапросе, в котором применяется оконная функция. Если вам необходимо сгруппировать полученный результат, используйте GROUP BY в подзапросе, который находится на уровень выше. Более подробно об этом я расскажу немного позже.
2. ORDER BY
ORDER BY позволяет задавать сортировку внутри каждого созданного с помощью PARTITION BY окна.
3. WINDOW FRAME
С помощью этой необязательной опции вы можете задавать смещение внутри каждого окна. Например, вам нужно просуммировать текущую строку таблицы с двумя предыдущими. Синтаксис функции будет выглядеть так:
sum(Salary) over (ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)Синтаксис опции Window Frame можно описать отдельно, он выглядит следующим образом:
{ROWS | RANGE} {BETWEEN start AND end | start | end}Описание Window Frame начинается с одного из ключевых слов, ROWS или RANGE.
3.1. ROWS
Используется, когда вам необходимо применить межстрочное вычисление. Например, просуммировать текущую строку таблицы с несколькими предыдущими. Для этого достаточно задать количество строк, которые необходимо агрегировать. Пример использования ROWS на наших тестовых данных:
sum(Salary) over (ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)3.2. RANGE
Дает возможность указать диапазон значений для вычислений. Например:
sum(Salary) over (order by Salary RANGE BETWEEN 1000 PRECEDING AND CURRENT ROW)Формула просуммирует зарплаты сотрудников со всеми зарплатами, которые попадают в диапазон «на 1000 меньше», чем у сотрудника в текущей строке в рамках каждого окна. С выбранным ключевым словом ROW или RANGE, как вы уже могли заметить из примеров, необходимо задавать диапазон агрегирования по схеме:
BETWEEN start AND end3.3. BETWEEN START AND END
Start описывает начальное смещение в рамках окна относительно текущей строки. Start принимает следующие значения:
{UNBOUNDED PRECEDING | CURRENT ROW | expr PRECEDING | expr FOLLOWING}где:
- UNBOUNDED PRECEDING — первая строка текущего окна;
- CURRENT ROW — текущая строка;
- expr PRECEDING — определяет количество предыдущих, участвующих в расчетах строк. Вместо expr вы должны указать количество предыдущих участвующих в расчетах строк относительно текущей строки;
- expr FOLLOWING — определяет количество строк для агрегации из числа тех, что следуют за текущей строкой.
End описывает конечное значение диапазона смещения и принимает такие же значения, как и Start. Например:
{UNBOUNDED FOLLOWING | CURRENT ROW | expr PRECEDING | expr FOLLOWING}UNBOUNDED FOLLOWING в данном случае используется для того, чтобы задать в качестве последней строки агрегации последнюю строку текущего окна. Пример описания Between Start and End в функции:
sum(Salary) over (ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)В данном случае Start — это «2 PRECEDING» а End — «CURRENT ROW». Эта функция говорит просуммировать в рамках текущего окна поля Salary две предыдущие строки и текущую. Поскольку пункт PARTITION BY не описан, текущим окном является вся таблица.
Главное отличие оконных функций от агрегирующих в том, что они не группируют результат, а указывают агрегированное значение для каждой отдельной строки. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов.
Например, результат следующего запроса выведет нарастающий итог по пяти строкам.
SELECT name, value, SUM(value) OVER (ORDER BY value)
AS RunningTotalFROM(SELECT "a" AS name, 0 AS value),
(SELECT "b" AS name, 1 AS value),
(SELECT "c" AS name, 2 AS value),(SELECT "d" AS name,
3 AS value),(SELECT "e" AS name, 4 AS value);Результат: 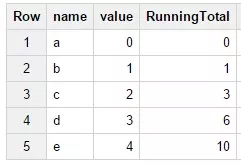
SELECTCONCAT(First_name, " ", Last_name)
as fullName,Salary,SUM(Salary) OVER (ORDER BY fullName)
as runningTotalFROM Test_WF.test_structureРезультат: 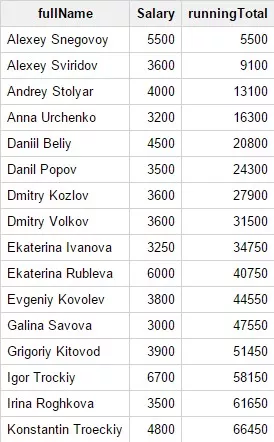
Внимание: чтобы получить в результате нарастающий итог, описывайте пункт ORDER BY, иначе напротив каждой строки будет указываться сумма зарплат всех сотрудников.
Еще один пример использования функции sum как оконной, а не агрегирующей. Например, мы хотим узнать, какая часть фонда заработной платы в каждом отделе приходится на начальника. Запрос:
SELECTDepartment,Position,round(Salary / departmentSalarySum * 100 , 2)
as headSalaryPercentFROM(SELECTPosition,Department,Salary,SUM(Salary)
OVER (PARTITION BY Department) as departmentSalarySumFROM Test_WF.test_structure)
WHEREPosition in('Department head','CTO','CFO','Cheif Accountant') Результат: 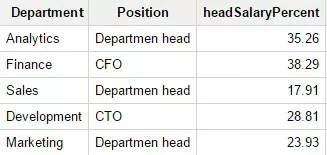
SELECTPosition,Department,Salary,SUM(Salary)
OVER (PARTITION BY Department) as
departmentSalarySumFROM Test_WF.test_structure Подзапрос возвращает следующий результат:

Далее мы уже работаем с данными, который вернул представленный выше подзапрос. Вычисляем процент зарплаты сотрудников от фонда зарплаты отдела:
SELECTDepartment,Position,round(Salary / departmentSalarySum * 100 , 2) as headSalaryPercentПотом остается только отфильтровать результат запроса, чтобы итоговая таблица содержала данные только по руководителям отделов.
WHEREPosition in('Department head','CTO','CFO','Cheif Accountant')Рассмотрим все существующие на момент написания статьи оконные функции BigQuery.
1. Функции AVG(numeric_expr), COUNT(*), COUNT([DISTINCT] field), MAX(field), MIN(field), STDDEV(numeric_expr), SUM(field)
Список стандартных агрегирующих функций, доступных для использования в виде оконных функций. Их синтаксис при этом не меняется, только добавляется описание окна с помощью пункта OVER.
- AVG — среднее арифметическое;
- COUNT — количество значений;
- COUNT[Distinct] — количество уникальных значений;
- MAX — максимальное значение;
- MIN — минимальное значение;
- STDDEV — среднеквадратичное отклонение;
- SUM — сумма значений.
Пример запроса:
SELECT Department, AVG(Salary) OVER (PARTITION BY Department) as winAvg,
COUNT(Salary) OVER (PARTITION BY Department) as winCount,
COUNT(DISTINCT Position) OVER (PARTITION BY Department)
as winCountDistinct, MAX(Salary) OVER (PARTITION BY Department)
as winMax, MIN(Salary) OVER (PARTITION BY Department) as winMin,
STDDEV(Salary) OVER (PARTITION BY Department) as winStDev,
SUM(Salary) OVER (PARTITION BY Department)
as winSumFROM Test_WF.test_structure Результат запроса: 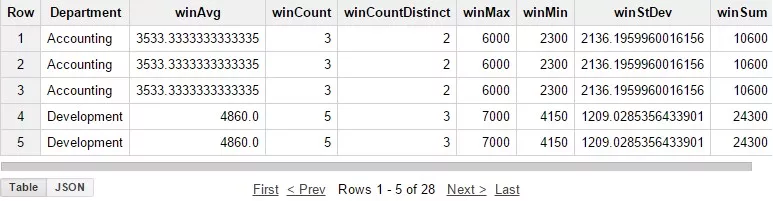
2. Функция CUME_DIST()
Возвращает кумулятивное распределение значения группе значений. Рассчитывается по формуле <количество предыдущих строк окна, включая текущую> / <общее количество строк окна>. Для данной функции описание ORDER BY в пункте OVER обязательно. Пример запроса:
SELECT Department, Salary, CUME_DIST(Salary)
OVER (PARTITION BY Department ORDER BY Salary)FROM
Test_WF.test_structureWHERE Department = 'Finance'Результат запроса: 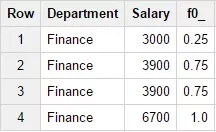
- 1 / 4 = 0,25 (1 строка окна делится на общее количество строк в окне);
- 3 / 4 = 0,75 (количество предыдущих строк окна — это 1 + 2, так как значение второй строки окна (3900) встречается дважды. Делится на общее количество строк окна — 4.
- Расчет третьей строки полностью идентичен второй строке. Значение поля Salary в них одинаковое.
- 4 / 4 = 1 (количество предыдущих значений — 3 плюс 1, так как значение новой строки уникально и ранее учтено не было. Делится на общее количество значений данного окна.
3. Функция DENSE_RANK()
Возвращает ранг значения текущей строки относительно значений всего окна, исходя из заданной сортировки. Для данной функции описание сортировки в пункте OVER с помощью ORDER BY обязательно. Пример запроса:
SELECTDepartment,Salary,DENSE_RANK(Salary)
OVER (PARTITION BY Department
ORDER BY Salary)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales')Результат запроса: 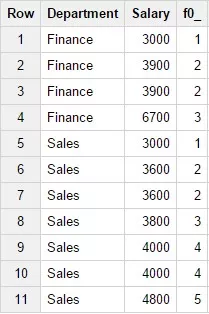
4. Функция FIRST_VALUE(field_name)
Возвращает значение первой строки окна, согласно указанной сортировке. При этом для данной функции описание ORDER BY не обязательно. Пример запроса:
SELECTDepartment,Salary,FIRST_VALUE(Salary)
OVER (PARTITION BY Department)
FROM Test_WF.test_structureWHERE Department
in ('Finance','Sales')Результат запроса: 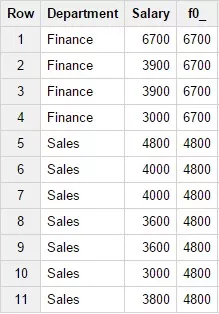
5. Функция LAG
Синтаксис:
LAG (field_name[, offset[, default_value]])Возвращает значение строки по указанному полю, при этом поле смещено на указанное в функции количество строк до текущей строки. Если строка не найдена будет возвращено значение по умолчанию заданное в , значение по умолчанию обязательно должно иметь формат INT64, то есть указано с помощью функции INTEGER(expr). Пример запроса:
SELECTDepartment,Salary,LAG(Salary, 2) OVER
(PARTITION BY Department)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales') Результат запроса: 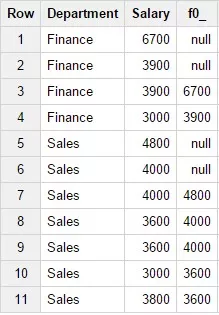
6. Функция LAST_VALUE(field_name)
По смыслу функция похожа на функцию FIRST_VALUE, но в данном случае функция возвращает значение из последней строки окна. Пример запроса:
SELECTDepartment,Salary,LAST_VALUE(Salary) OVER
(PARTITION BY Department)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales')Результат запроса: 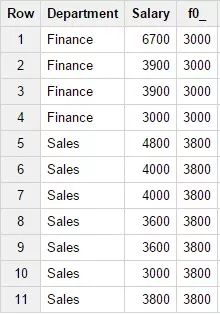
7. Функция LEAD
Синтаксис:
(expr [, offset[, default_value]])По смыслу похожа на функцию LAG, но возвращает значение со смещением на указанное количество строк в после текущей строки. Значение по умолчанию должно указываться в формате INT64, то есть быть завернуто в функцию INTEGER(), как показано в примере к данной функции. Пример запроса:
SELECTDepartment,Salary,LEAD(Salary, 2, INTEGER(0)) OVER
(PARTITION BY Department)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales') Результат запроса: 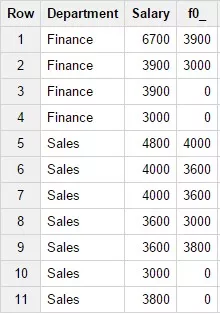
8. Функция NTH_VALUE(expr, n)
Возвращает значение из строки окна, соответствующей заданному индексу внутри этого окна. В случае, если окно содержит меньше строк, чем вы указали в качестве индекса, функция вернет null. Пример запроса:
SELECTDepartment,Salary,NTH_VALUE(Salary, 2)
OVER (PARTITION BY Department)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales') Результат запроса: 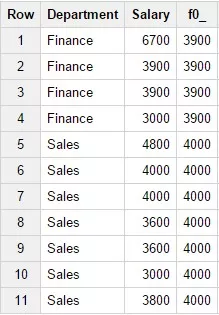
9. Функция NTILE(num_buckets)
Делит окно на заданное в num_buckets количество одинаковых по количеству строк разделов и возвращает номер раздела окна для каждой строки. Пример запроса:
SELECTDepartment,Salary,NTILE(4) OVER
(PARTITION BY Department)FROM Test_WF.test_structureWHERE
Department in ('Finance','Sales') Результат запроса: 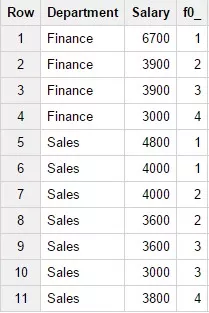
10. Функция PERCENT_RANK()
Возвращает ранг текущей строки относительно других строк раздела в процентом выражении. Возвращает значение от 0 до 1 включительно, первое значение окна всегда равно 0.0, последние 1.0. Для данной функции описание ORDER BY обязательно. Пример запроса:
SELECTDepartment,Salary,PERCENT_RANK(Salary) OVER
(PARTITION BY Department ORDER BY Salary)FROM
Test_WF.test_structureWHERE Department in
('Finance','Sales') Результат запроса: 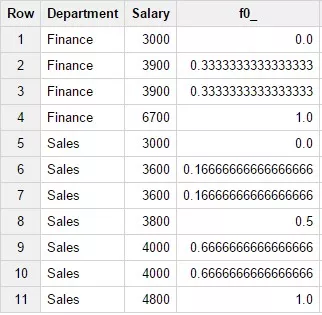
Индекс текущей строки / индекс последней строки. В нашем случае 0/6 = 0.0.
Шестая строка содержит новое уникальное значение поля Salary. Индекс данной строки в этом случае рассчитывается так же, как индекс предыдущей, плюс один пункт, и равен единице. Следовательно, функция вернет значение по формуле:
индекс текущей строки / индекс последней строки. В нашем случае 1 / 6 = 0.16.
Поскольку значение в строке 7 повторяется, то и индекс для этой строки так же повторяется и будет равен 1. Соответственно, функция вернет значение 1 / 6 = 0.16. Восьмая строка вновь содержит уникальное значение. Её индекс должен быть увеличен относительно индекса прошлой строки на количество тех предыдущих строк, в которых значение повторялось. В нашем случае значение 3600 повторялось в двух предыдущих строках. Значит, индекс прошлой первой строки мы должны увеличить на 2 и получить индекс восьмой строки равный 3. Расчет значения будет 3 / 6 = 0.5. Девятая строка также содержит новое значение, 4000. Увеличиваем индекс на 1, так как значение прошлой строки не повторялось и содержится только в одной строке. Индекс текущей строки — 3 + 1 = 4, а значение, которое возвращает функция: 4 / 6 = 0.66. Десятая строка содержит такое же значение поля Salary, как и предыдущая. Соответственно, индекс остается 4 и значение поля рассчитывается так: 4 / 6 = 0.66. Одиннадцатая строка содержит новое значение, равное 4800, поскольку прошлое значение поля Salary повторялось. Дважды увеличиваем индекс на 2. 4 + 2 = 6. Значение поля, возвращаемое функцией PERCENT_RANK: 6 / 6 = 1.0
11. Функция PERCENTILE_CONT(percentile)
Возвращает значения, основанные на линейной интерполяции между значениями группы, после сортировки, описанной в пункте ORDER BY. Процентиль должен иметь значение в диапазоне от 0 до 1. Для данной функции описание пункта ORDER BY обязательно. Пример запроса:
SELECTDepartment,Salary,PERCENTILE_CONT(0.5) OVER
(PARTITION BY Department ORDER BY Salary)FROM
Test_WF.test_structureWHERE Department in
('Finance','Sales') Результат запроса: 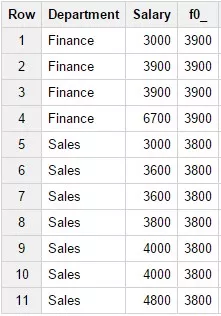
12. Функция PERCENTILE_DISC(percentile)
Возвращает значение с наименьшим кумулятивным распределением, большее или равное указанному в процентилю. Для данной функции описание пункта ORDER BY обязательно. Пример запроса:
SELECTDepartment,Salary,PERCENTILE_DISC(0.25)
OVER (PARTITION BY Department ORDER BY Salary)
FROM Test_WF.test_structureWHERE Department in
('Finance','Sales') Результат запроса: 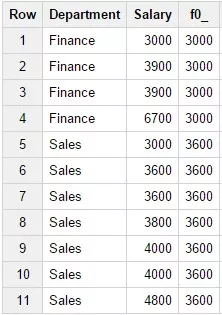
13. Функция RANK()
Возвращает ранг значения на основе сравнения с другими значениями в рамках окна. Равнозначные значения отображаются с одинаковым рангом. Ранг следующего значения увеличивается на количество значений, соответствующих прошлому рангу. Например, если два значения имеют ранг 2, то ранг следующего по величине значения будет 4.
Если вам необходимо получить непрерывное ранжирование, используйте функцию DENSE_RANK ().
Параметр ORDER BY в пункте OVER для данной функции обязательно. Пример запроса:
SELECTDepartment,Salary,RANK(Salary) OVER
(PARTITION BY Department ORDER BY Salary)FROM
Test_WF.test_structureWHERE Department in
('Finance','Sales') Результат запроса: 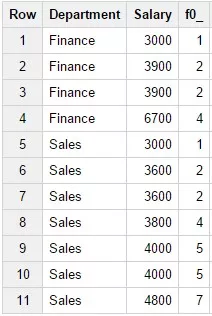
14. Функция RATIO_TO_REPORT()
Возвращает отношение текущего значения к сумме значений указанного поля в данном окне. Пример запроса:
SELECTDepartment,Salary,RATIO_TO_REPORT(Salary) OVER
(PARTITION BY Department ORDER BY Salary)FROM
Test_WF.test_structureWHERE Department in
('Finance','Sales') Результат запроса: 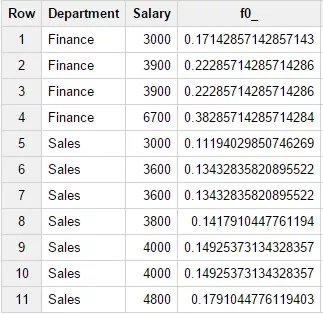
15. Функция ROW_NUMBER()
Возвращает номер текущей строки в окне. Нумерация начинается с единицы. Пример запроса:
SELECTDepartment,Salary,ROW_NUMBER()
OVER (PARTITION BY Department)FROM
Test_WF.test_structureWHERE Department
in ('Finance','Sales')Результат запроса: 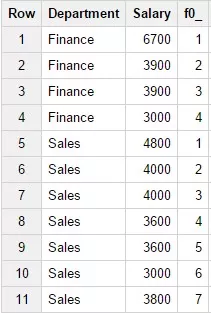
Читайте статью по теме: «Интеграция Google BigQuery с BI-платформами и электронными таблицами».

 36
36
 0
0
 0
0
По теме
Как отслеживать события с помощью Google Analytics 4: подробный мануал
Как настраивать события, какими они бывают, как работают — подробный гайд по настройке и работе с событиями
Всемогущая функция Query — подробное руководство
Как пользоваться одной из самых важных функций Google Таблиц — подробное руководство по Query
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок