Партиционирование таблиц в Google BigQuery — понятная инструкция
Знаете, как максимально продуктивно и экономно работать с данными в Google BigQuery с помощью разделения больших таблиц на партиции? В этой статье я расскажу, как создавать партиции и обращаться к конкретной партиции на обоих SQL-диалектах BigQuery.
Google BigQuery — это облачная база данных для хранения и быстрой обработки больших объемов информации. Как правило, стоимость использования облачной базы данных не превышает $5 в месяц даже при хранении и обработке достаточно больших объемов данных. Но при неправильном и неэффективном использовании инструментария оплата обходится в сумму в десять раз большую, чем вы ожидали.
Партиционирование — это разделение большой таблицы на части (партиции). Логически вы работаете с таблицей разбитой на партиции точно так же, как и с обычной, но физически эта таблица состоит из отдельных файлов (разделов) и в нужный момент вы получаете данные из тех разделов, в которых хранится запрашиваемая информация.
Такое разделение таблицы нужно для экономии ресурсов и ускорения работы запросов, а в случае с BigQuery — еще и для экономии денег за оплату обработанных данных.
Если вы не делите таблицу на партиции, то запрос будет сканировать все строки таблицы перед тем, как отдать вам результат. Если таблица разделена на партиции, и вам необходимо обработать данные из нескольких партиций, то запрос обратится за данными именно к этим частям таблицы, и объем данных для обработки будет значительно меньше.
Как создать таблицу с партициями в Google BigQuery
Создать таблицу из нескольких частей очень просто. Для этого в интерфейсе BigQuery при создании новой таблицы в опциях укажите формирование партиций по дням.
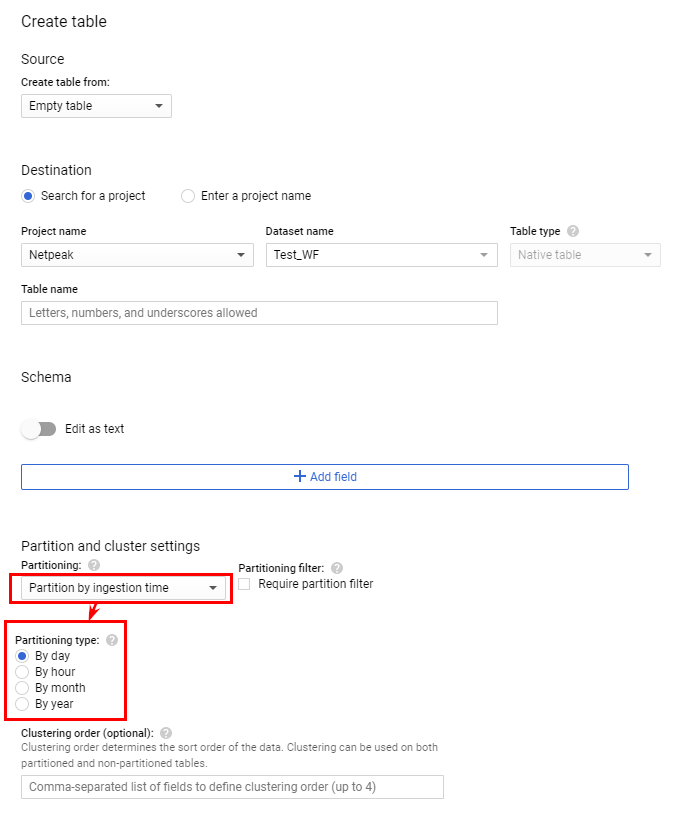
Таблица с такой опцией будет содержать дополнительный столбец _PARTITIONTIME с датой записи строки в таблицу. Именно по значению этого поля автоматически сформируются партиции.
Название поля _PARTITIONTIME — зарезервированное. Поэтому обратиться к нему без присвоения псевдонима нельзя. Воспользуйтесь командой AS, чтобы получить значения данного поля.
Пример запроса:
SELECT _PARTITIONTIME AS pt, id, value
FROM Test_WF.part_testПример результата выполнения запроса:
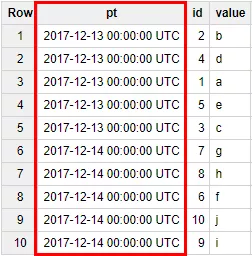
По результату запроса видно, что столбец pt (это переименованный с помощью команды AS виртуальный столбец _PARTITIONTIME) содержит два значения: «2017-12-13 00:00:00 UTC» и «2017-12-14 00:00:00 UTC».
Таблица Test_WF.part_test на данный момент разделена на две партиции:
- строки с id 1-5 и значением «2017-12-13 00:00:00 UTC» — первая часть (эти данные загружены в таблицу 13 декабря 2017 года);
- строки с id 6-10 и значением «2017-12-14 00:00:00 UTC» входят во вторую партицию (данные загружены в таблицу 14 декабря 2017 года).
На первый взгляд, для пользователя это обычная таблица с физическим разделением (данные хранятся в разных файлах), но пользователь работает со всеми частями точно так же, как и работал бы с одной.
По умолчанию вся информация будет записываться в партицию, которая соответствует дате загрузки данных в таблицу. Для загрузки информации в партиции, сформированные в прошлом периоде, укажите партицию вместе с названием набора данных и таблицы через специальный знак разделитель $.
Например, для добавления записи в таблицу партиции от 1 декабря 2017 года запишем в Test_WF.part_test$20171201.
Как обращаться к партициям
BigQuery поддерживает два SQL-диалекта, поэтому рассмотрим, как обращаться к конкретной партиции на обоих диалектах.
В Legacy SQL укажите нужную партицию после имени таблицы через знак $.
Пример запроса:
SELECT *FROM Test_WF.part_test$20171213Пример результата выполнения запроса:
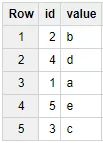
Этот запрос вернул все строки из партиции, в которую были загружены данные 13 декабря 2017 года.
В стандартном SQL вы можете обращаться к партициям в блоке WHERE.
Пример запроса:
SELECT *
FROM Test_WF.part_test
WHERE _PARTITIONTIME = "2017-12-13"Пример результата выполнения запроса:
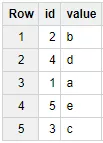
Чтобы получить данные сразу из нескольких партиций, обратитесь к полю _PARTITIONTIME в блоке WHERE. Этот способ работает как в Standart ,так и в Legacy SQL.
SELECT *
FROM TABLE_DATE_RANGE(Test_WF.my_table, TIMESTAMP("2017-12-13"), TIMESTAMP("2017-12-14"))Пример результата выполнения запроса:
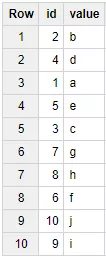
Функции подстановки таблиц (Table Wildcard Function) поддерживаются только в Legacy SQL. Используйте виртуальное поле _TABLE_SUFFIX для обращения к отдельным партициям из таблицы, разбитой на разделы описанном в этом блоке способом.
Пример запроса:
SELECT *
FROM `Test_WF.my_table*`
WHERE _TABLE_SUFFIX BETWEEN "20171213" AND "20171214"Пример результата выполнения запроса:
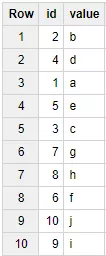
Для перечисления любых суффиксов таблиц используйте поле _TABLE_SUFFIX и оператор IN.
Пример запроса:
SELECT *
FROM `Test_WF.my_table*`
WHERE _TABLE_SUFFIX IN ("20171213", "20171214")Пример результата выполнения запроса:
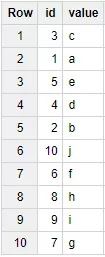
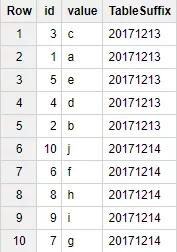
Название партиции удобно выводить в результате запроса.
Пример запроса:
SELECT *, _TABLE_SUFFIX as TableSuffix
FROM `Test_WF.my_table*`
WHERE _TABLE_SUFFIX BETWEEN "20171213" AND "20171214"Пример результата выполнения запроса:
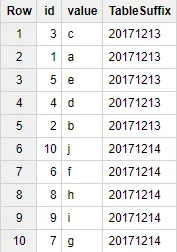
{kind=link}
Как пользоваться партиционированием таблиц
Партиции здорово помогают при составлении оперативной отчетности за фиксированный период, например, за последние 7 или 30 дней.
Для экономии ресурсов вы можете создать представление, которое будет возвращать данные за определенное количество дней, например за последние 7 или 30 дней.
Представление в SQL — это виртуальная таблица без данных с текстом SQL-запроса. Вы можете работать с результатом выполнения этого запроса, как с обычной таблицей базы данных.
Для создания представления в Google BigQuery напишите в редакторе запросов текст SQL-запроса и нажмите «Save View».
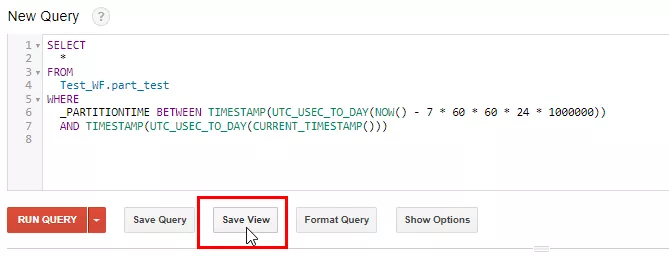
Укажите DataSet, в котором будет создано представление, и задайте имя представления.
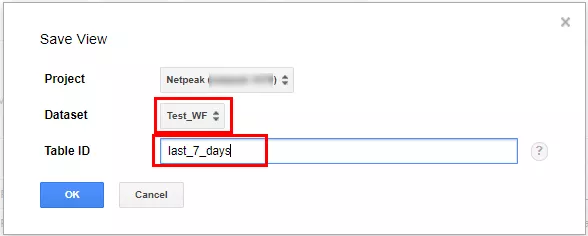
Готово! Созданное вами представление появится в указанном наборе данных и вы сможете обращаться к нему, как обычной таблице.
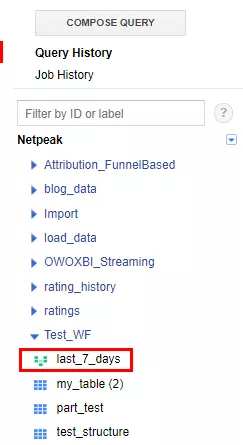
Преимущество такого подхода очевидно: хранение данных в партициях, к которым вы не обращались более 90 дней, стоит в BigQuery на 50% дешевле. При этом счетчик времени сбрасывается при любом обращении к партиции: будь-то запрос, изменение, запись или копирование данных.
Для реализации подхода и получения данных за последние 7 дней воспользуйтесь примерами запросов для Legacy- и Standart-диалектов.
В Legacy SQL запрос будет выглядеть так:
SELECT *
FROM Test_WF.part_test
WHERE _PARTITIONTIME BETWEEN
TIMESTAMP(UTC_USEC_TO_DAY(NOW() -
7 * 60 * 60 * 24 * 1000000)) AND
TIMESTAMP(UTC_USEC_TO_DAY(CURRENT_TIMESTAMP()))В Standart SQL условие WHERE будет выглядеть немного иначе:
SELECT *
FROM Test_WF.part_test
WHERE _PARTITIONTIME BETWEEN
TIMESTAMP_TRUNC(TIMESTAMP_SUB(CURRENT_TIMESTAMP(),
INTERVAL 7 * 24 HOUR),DAY) AND TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(),DAY)Выводы
Партиционировать таблицы очень просто. Для этого в интерфейсе BigQuery при создании новой таблицы в опциях укажите формирование партиций по дням. Затем при запросе данных из таблицы с помощью соответствующего SQL-диалекта задайте нужную партицию после имени таблицы через символ $ или дату в формате ГГГГММДД.
При работе с партициями учитывайте ограничения:
- одна таблица может иметь не более 2500 разделов (партиций);
- партицию можно обновлять не более 2000 раз в сутки;
- частота обновлении партиции не более 50 обновлений в течении 10 секунд.
Партиционирование для таблиц с большим количеством строк сэкономит ваши деньги и повысит производительность выполнения запросов к данным. Стоимость хранения разделов, которые не обновлялись более 90 дней на 50% дешевле, чем хранение данных, которыми вы пользуетесь регулярно.
Этот пост впервые опубликован в 2018 году. Обновлен в 2021-ом. Если вы обнаружили здесь неактуальную информацию, напишите об этом в комментариях.

 61
61
 7
7
 42
42
По теме
Как отслеживать события с помощью Google Analytics 4: подробный мануал
Как настраивать события, какими они бывают, как работают — подробный гайд по настройке и работе с событиями
Всемогущая функция Query — подробное руководство
Как пользоваться одной из самых важных функций Google Таблиц — подробное руководство по Query
Свежее
Рост продаж магазина инженерного оборудования в Германии на 77%: кейс Shopping-Kobolde
Продвижение технического ecommerce с ограниченной CMS и необходимостью конкурировать за органический трафик с маркетплейсами
21 канал с миллионной аудиторией в украинском Telegram
Кто сегодня возглавляет рейтинг крупнейших Telegram-каналов Украины? Какие из них продемонстрировали наибольший рост, а какие потеряли аудиторию?
Обновляемый дайджест изменений в AI-поиске
Дайджест главных обновлений AI и их влияния на рынок