Автоматичний аналіз клієнтських даних (RFM-аналіз) за допомогою Google BigQuery
Чим краще бізнес знає вподобання й поведінку клієнтів, тим ефективніше створює власну маркетингову стратегію і покращує обслуговування.
Розкажу про RFM-аналіз — як він допомагає виявляти найцінніших користувачів і оптимізувати ресурси для утримання і залучення нових покупців.
Що таке RFM
Уперше його застосували понад 25 років тому в США компанії, що займалися продажем за каталогами — Land’s End, Charles Tyrwhitt і JCPenney. Вони використовували RFM для мінімізації витрат на доставлення і підвищення прибутку від продажів.
RFM-аналіз — це перевірений метод сегментації клієнтів за давністю останньої транзакції, частотою покупок і розміром витрат. Він допомагає аналізувати поведінку клієнтів і виділяти різні сегменти, зокрема найцінніші, для оптимізації маркетингових стратегій.
Клієнти класифікуються за трьома основними критеріями:
- Recency — чи давно купував клієнт.
- Frequency —з якою частотою користувач купує.
- Monetary — скільки коштів клієнт витрачає.
Які дані потрібні для сегментації
Більший датасет — точніші результати. Щоби не створювати окрему базу під RFM, використовуйте Google Analytics 4. Він надає потужний інструментарій для відстеження метрик відвідуваності й поведінки користувачів на вашому сайті чи в застосунку.
Процес збору й завантаження даних із Google Analytics 4 до Google BigQuery може бути автоматизований за допомогою інтеграції між цими двома інструментами. Після встановлення інтеграції дані автоматично потрапляють до вказаної бази даних Google BigQuery.
Для обробки показників і сегментації використовуйте мову Python і бібліотеки:
- pandas —для завантаження й обробки даних;
- scikit-learn—для аналізу й машинного навчання;
- numpy —для роботи з масивами даних;
- matplotlib і seaborn —для візуалізації результатів аналізу.
Читайте докладніше, Як обходити ліміт в 1 млн івентів вивантаження даних з Google Analytics 4 до Google BigQuery.
Підготовка даних: приклад на основі ecommerce-бізнесу
Ефективність RFM-аналізу значною мірою залежить від якості підготовки даних. Помилки або пропуски на цьому етапі можуть суттєво вплинути на результати, що, своєю чергою, призведе до неправильних висновків. Розгляну покроковий процес підготовки даних для ecommerce-бізнесу, що аналізує покупки користувачів.
Етапи підготовки даних:
- Завантаження й обробка.
За допомогою бібліотеки pandas завантажте дані у форматі csv, які отримали з Google Analytics 4.
data = pd.read_csv("output_data.csv", parse_dates=[’event_date’],
date_parser=lambda x: pd.to_datetime(x, format=’%Y%m%d’), dtype=dtype_mapping)
- Аналіз структури.
Розгляньте набір даних, який містить інформацію про транзакції в онлайн-магазині. Кожен запис у датасеті відображає покупку користувача та містить такі ключові змінні.
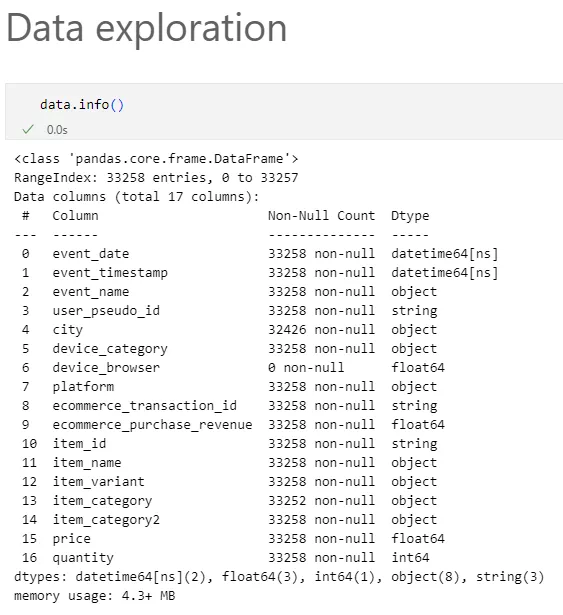
Цей датасет містить 33258 записів і 17 змінних із різними типами даних: числові (ціни, кількість), категоріальні (місто, браузер, категорія товару, дата)
- Аналіз унікальних значень.
Перевірка кількості унікальних значень у кожній не числовій змінній дає зрозуміти, наскільки різноманітні дані.
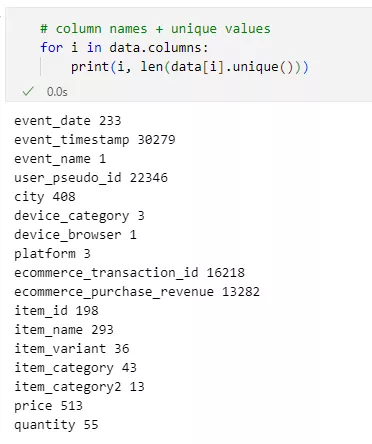
Змінна device_browser містить одне унікальне значення, отже, не буде впливати на результат та може бути видалена. Оскільки вона не містить жодної варіативності, її включення в аналіз не додає жодної інформативності про сегментації клієнтів або аналізі їх поведінки. У змінній event_name також один унікальний показник, що дорівнює «purchase». Тобто вхідний набір даних вже був відфільтрований, і він містить лише користувачів, які здійснили покупку.
- Аналіз пропущених даних.
Пропущені значення в змінних можуть суттєво впливати. Тому важливо їх знайти та обробити.
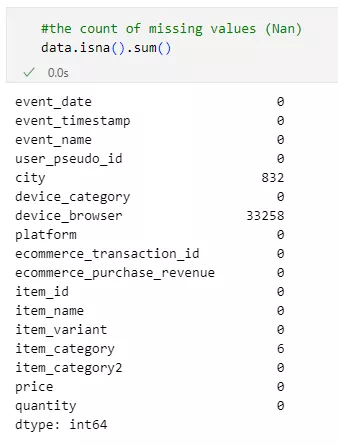
Пропущені значення знайдено в змінних city, item_category і device_browser
- Описова статистика.
Після перевірки структури та унікальності значень даних важливо оцінити числові показники.
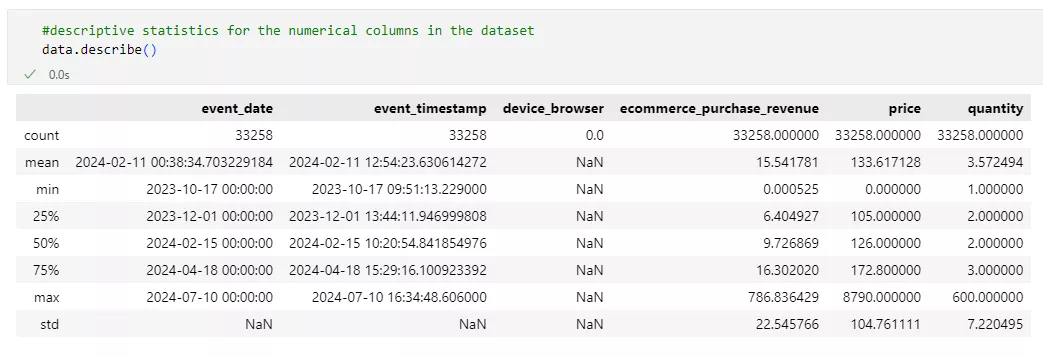
Описова статистика дозволяє зрозуміти розподіл основних змінних та виявити можливі аномалії. Особливо це важливо для полів, пов’язаних із доходом та ціною, оскільки значні відхилення можуть впливати на якість сегментації користувачів.
Аналізуючи отримані показники, можна зробити такі висновки.
Наявні дані охоплюють приблизно дев’ять місяців, що свідчить про досить об’ємну вибірку для виявлення тенденцій і оцінки поведінки клієнтів у тривалий період.
Мінімальне значення ecommerce_purchase_revenue (Дохід від покупки): 0,000525. Такий низький показник може вказувати на наявність тестових транзакцій, мікроплатежів або некоректно оброблених операцій. Це важливо, оскільки подібні записи можуть спотворювати середні значення доходу, впливати на сегментацію окремих груп користувачів.
Високе стандартне відхилення (22,55) вказує на велику варіативність доходів, що підтверджує значні коливання в сумі покупок різних клієнтів. Це може бути наслідком як природного розподілу витрат, так і аномальних значень, які також важливо врахувати при подальшій обробці даних.
Наявність нульових або дуже низьких цін (price) може свідчити про помилки в записах або промоції, котра надає товар безплатно. Максимальне значення price — 8790,0. Це вказує на наявність кількох дуже дорогих товарів, що буває через помилки у даних або рідкісні предмети з надзвичайно високими цінами.
Максимальний показник quantity (Кількість): 600 показує наявність деяких аномально великих замовлень або є результатом помилок у даних.
З урахуванням цих висновків наступним етапом стане обробка всіх виявлених аномалій, включаючи низькі та нульові значення доходу, екстремальні варіації у ціні та кількості замовлень. Це дозволить усунути можливі помилки, забезпечити коректність аналізу та покращити точність RFM-аналізу.
- Очищення і підготовка даних.
device_browser видаляється, оскільки містить всі пропущені значення.

Пропущені дані в колонках city та item_category заповнюються значенням «Unknown».
Обробка аномальних значень:
- для ecommerce_purchase_revenue і price використовуються 1-й і 99-й процентилі для визначення допустимого діапазону значень;
- для quantity встановлюється максимальний показник на основі 99-го процентиля.
Після завершення обробки даних все готове до виконання RFM і подальшої сегментації користувачів.
Практична цінність RFM-аналізу
Він допомагає:
- Визначити найвідданіших клієнтів.
- Розробити персоналізовані маркетингові стратегії.
- Оптимізувати витрати на маркетинг.
- Підвищити задоволеність покупців.
Приклад коду для виконання RFM на зібраних даних:
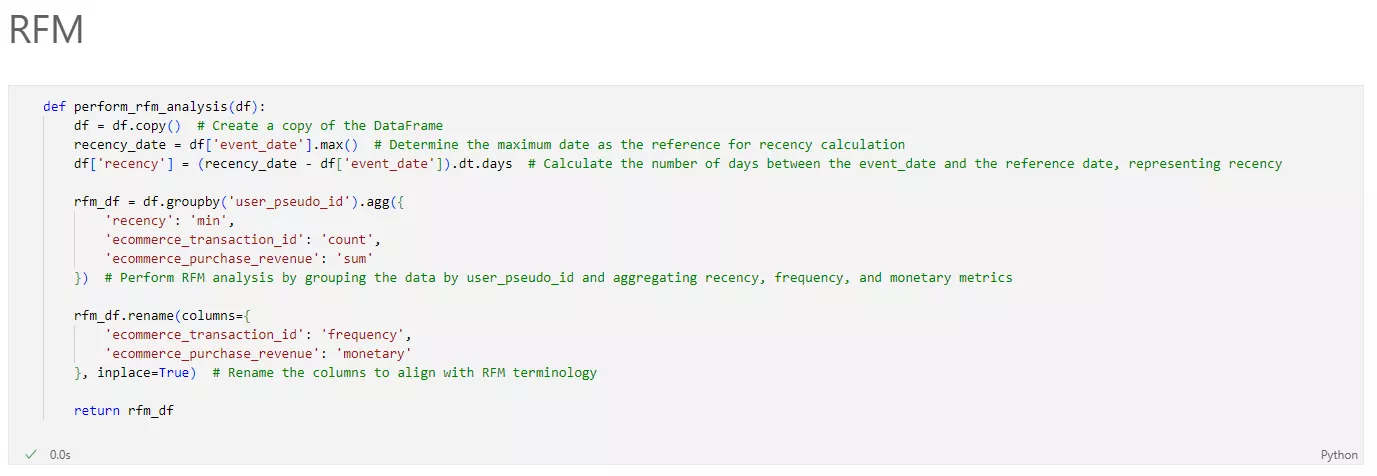
Візуалізація результатів RFM-аналізу
Для цього використовуються коробкові діаграми (boxplot) і гістограми — перші показують розподіл даних і виявляють аномалії, а другі демонструють частоту значень.
Аналіз результатів
Отримані результати допомагають зрозуміти поведінку клієнтів і їхню цінність для бізнесу:
- Recency —покупці з малими значеннями recency є найбільш активними.
- Frequency — клієнти з високими показниками frequency купують часто.
- Monetary — користувачі з високим monetary приносять найбільший дохід.
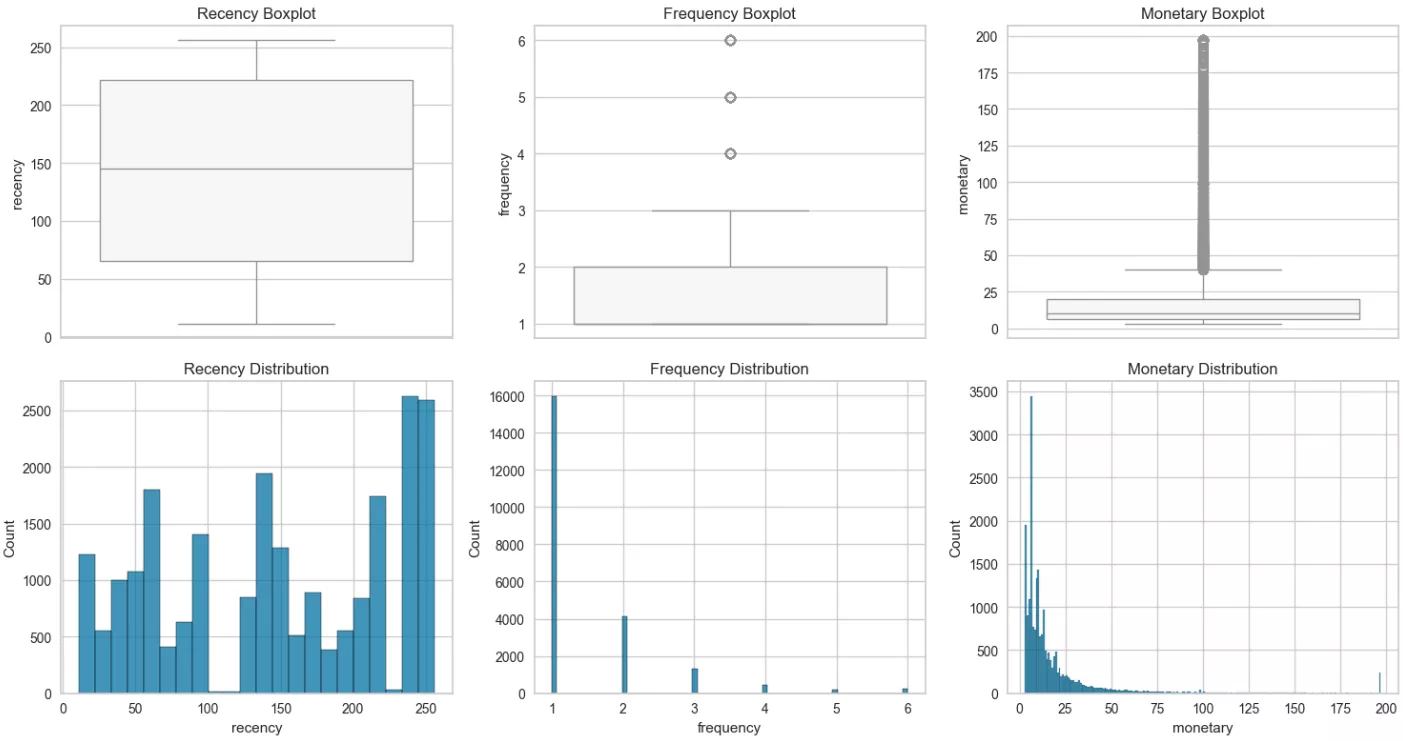
Отримані дані квартилів для кожної з метрик (recency, frequency, monetary) вказують на наступне:
- Recency. Значення медіани (145 днів) вказує на середній період активності клієнтів, а дані 75-го процентиля (222 дні) демонструють, що деякі користувачі могли купувати до семи місяців тому.
Максимальне значення (256 днів) показує досить великий інтервал останньої купівлі для найменш активних покупців. Тут потрібно враховувати сезонність покупок. - Frequency. Частота покупок вказує на те, що більшість клієнтів здійснює лише одну або дві покупки упродовж усього періоду. Медіана, яка дорівнює 1,0, підтверджує це, оскільки значна частина користувачів купувала дуже рідко.
Максимальне значення (6) показує, що деякі клієнти могли купувати до шести разів. Схоже, ці покупки за потребою, що характерно для товарів нещоденного споживання. - Monetary. Показники на 25-му процентилі (6,43) і медіана (10,34) свідчать про те, що більшість покупок мають відносно невелику вартість.
Значення 75-го процентиля (19,99) вказує на те, що значна частина покупців витрачає більше. Деякі показники досягають максимуму (196,96) —це може бути зумовлене специфікою сфери й свідчить про великі разові замовлення.
Кластеризація за допомогою K-Means
Потужний інструмент аналізу даних, котрий дає змогу розділити велику кількість клієнтів або товарів на групи за схожими ознаками.
Цей підхід дає змогу знайти об’єкти з аналогічною поведінкою і характеристиками, що дає можливість застосовувати спеціалізовані маркетингові й продуктові стратегії для кожної з таких груп.
Якщо сегментувати користувачів за категоріями товарів і часом останньої трансакції, можна виявити таких, які потребують акцій для збільшення частоти замовлень. А також користувачів, котрих можна заохотити повернутися до покупок за допомогою спеціальних пропозицій
Спершу потрібно підготувати дані:
- Кодування категоріальних змінних. Алгоритм може оперувати лише числовими даними. Тому потрібно спочатку перетворити всі рядкові змінні. Наприклад, місто, тип пристрою чи категорія товару.
- Масштабування числових даних. Числа, котрі представляють частоту покупок, суму чи час, що пройшов з останньої купівлі, потрібно привести до одного масштабу.
Використовуючи цей інструмент, зробити RFM сегментацію для свого бізнесу простіше, ніж розкрити зоряну карту для гороскопа. І в такий спосіб визначити, що всі Водолії — інфантильні, Діви — душніли, а Champions — стабільні покупці. :)
Приклади сегментації:
- Champions (high R, high F, high M). Активні й щедрі, вони постійно повертаються за новими покупками й не бояться витратити багато грошей. Найвідданіші клієнти, завжди готові спробувати новинки.
- Loyal Customers (medium R, high F, medium M). Активні й комунікабельні, часто купують за помірним чеком. Вони люблять акції й знижки, і завжди готові повернутися за вигідною пропозицією.
- Big Spenders (low R, high F, high M). Обережні та надійні, нечасто купують, але зазвичай витрачають великі суми. Вони цінують якість і готові платити за неї.
- Perfectionists (medium R, medium F, high M). Регулярно роблять покупки за високим чеком. Вони ретельно обирають товари й завжди повертаються до улюблених брендів.
- Dreamers (low R, low F, medium M). Рідко купують, але витрачають небагато. Вони люблять комфорт і зазвичай обирають те, що приносить їм задоволення.
Вибір кількості кластерів за допомогою «методу ліктя»
Під час налаштування алгоритму важливо визначити оптимальну кількість груп, щоб уникнути надто дрібного поділу клієнтів зі схожими характеристиками. Або, навпаки, створення занадто великих груп із різнорідними даними. Ідеальний результат, коли на графіку відстань між групами максимальна, а всередині кожної групи — мінімальна. Це забезпечує чітке розмежування між сегментами.
«Метод ліктя» допомагає знайти оптимальну кількість груп для аналізу даних. На графіку цей метод демонструє, як змінюється внутрішня варіація зі збільшенням кількості груп. Важливо визначити точку, де зменшення варіації стає незначним.
Виконання кластеризації й аналіз результатів
Після визначення кількості груп застосуйте алгоритм K-Means. Він розділить дані на кластери й надасть для кожного клієнта мітку — позначку групи, до якої він належить. Проаналізувавши групи, ви виділите різні типи покупців і виявите шляхи покращення їхнього обслуговування.
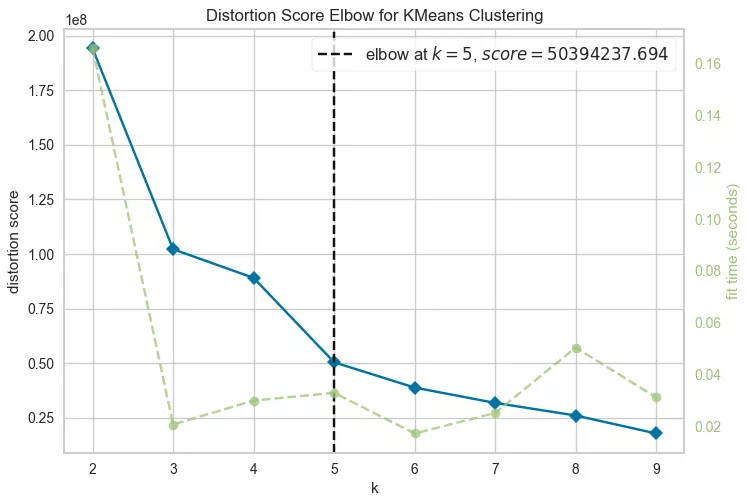
Алгоритм визначив оптимальним п’ять кластерів для ваших даних.
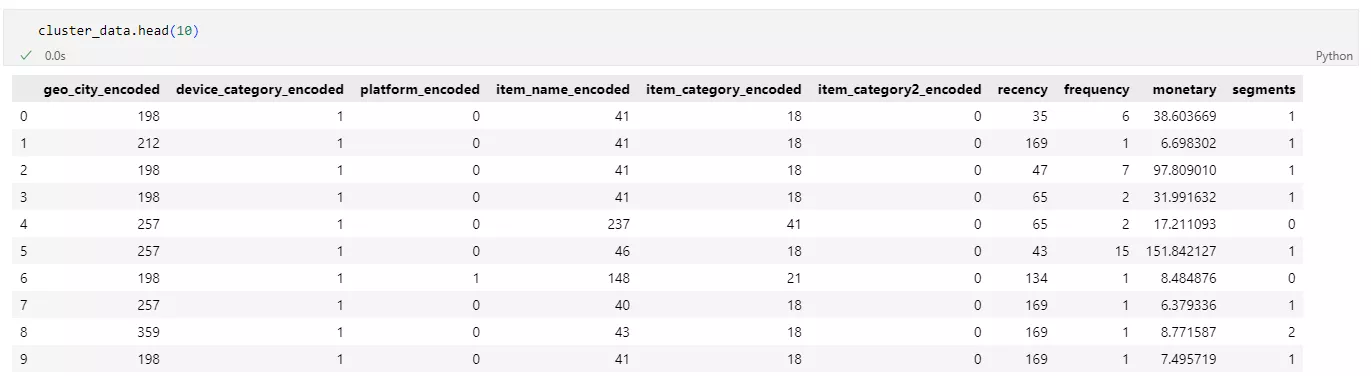
Приклад результату
Кожен рядок у вихідних даних має певні значення для закодованих категоріальних і числових змінних, а також належить до певного кластера (segments).
Візуалізація результатів кластеризації.
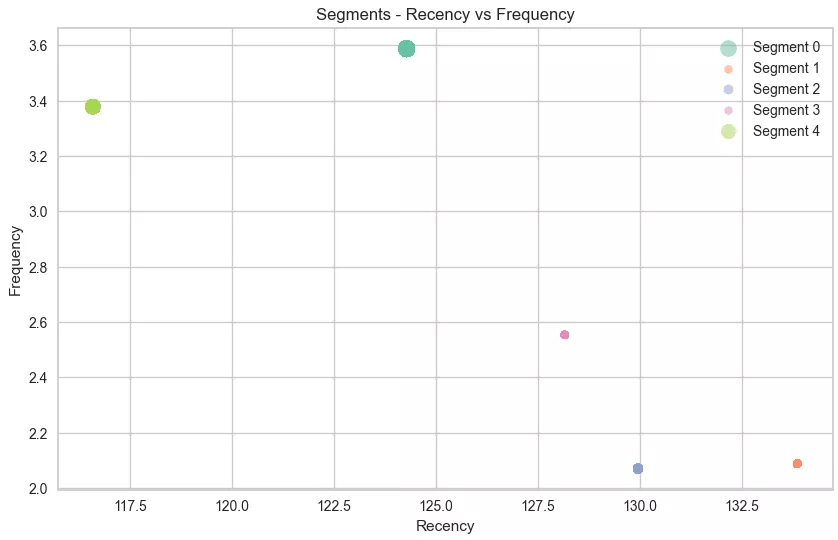
Результати кластеризації показують характеристики кожного з сегментів за трьома основними метриками:
- recency —остання активність користувача;
- frequency —частота покупок;
- monetary —сума покупок, закодована в діаметрі сегмента.
Проаналізую отримані дані.
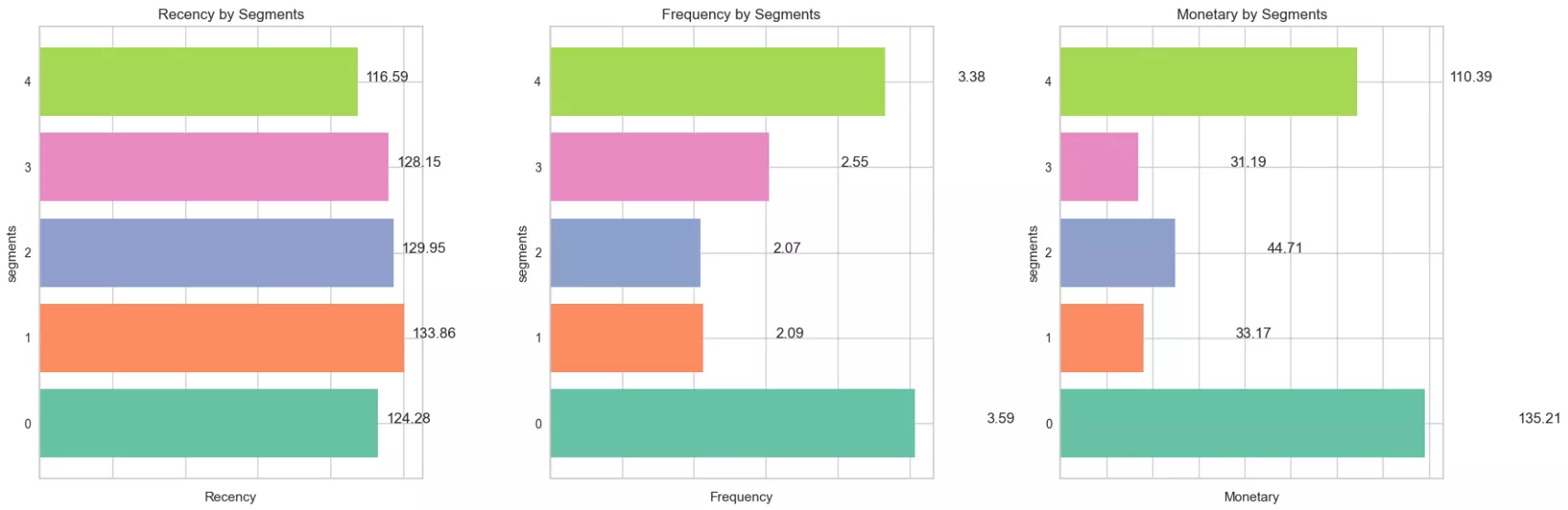
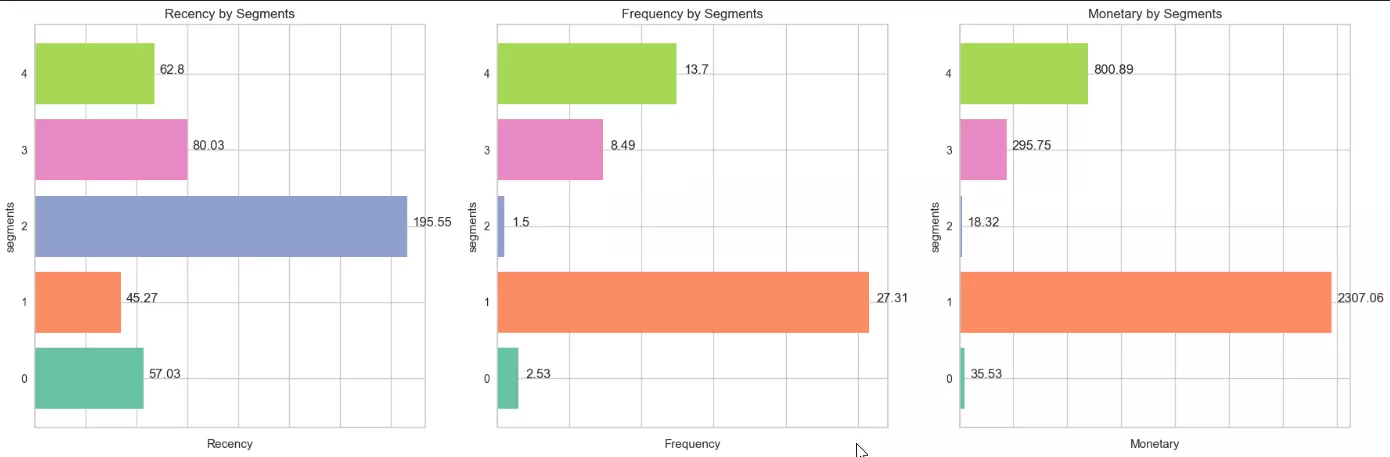
Кластер 0: Moderately Active Customers (Medium R, High F, High M).
Кількість клієнтів: 5805.
Користувачі регулярно купують на великий чек. Вони віддані бренду й часто повертаються для нових покупок, що робить їх важливими для утримання.
Кластер 1: Irregular Customers (High R, Low F, Low M).
Кількість клієнтів: 18296.
Покупці цього сегменту давно і зрідка купували, витрачали мало грошей. Вони можуть втратити цікавість, тому потребують активного залучення для повернення.
Кластер 2: Highly Active Customers (High R, Low F, Medium M).
Кількість клієнтів: 3514.
Давно здійснювали останнє замовлення і рідко брали щось, хоча витрачали середні суми. Вони можуть бути зацікавлені в придбаннях, але потребують додаткового стимулу для більшої активності.
Кластер 3: Inactive Customers (High R, Medium F, Low M).
Кількість клієнтів: 4389.
Такі люди купували давно, але робили це періодично, витрачали невеликі суми.
Кластер 4: Top Spenders (Medium R, High F, High M).
Кількість клієнтів: 1254.
Купували порівняно недавно, робили це часто і витрачали великі суми. Вони є найціннішими для бізнесу, їх варто підтримувати й заохочувати для подальших покупок.
Кластеризація з використанням PCA
Principal Component Analysis (PCA) — метод статистичного аналізу, що допомагає зменшити складність даних водночас зберігає основну інформацію. Особливо корисний, коли у вас багато змінних або взаємозалежних ознак.
Основна мета PCA — зменшити обсяг вимірів даних, тобто чинників або ознак, перетворивши їх у меншу кількість нових змінних (головних компонентів).
Як це працює:
- Ідентифікація основних напрямів. PCA досліджує дані й визначає нові напрями (компоненти), у яких показники мають найбільшу дисперсію. Це означає, що нові компоненти зможуть пояснити найбільшу частину варіацій у значеннях.
- Проєкція даних. Дані проєктуються на ці нові напрями.
- Зменшення розмірності. Замість працювати з усіма оригінальними змінними можна зосередитися на кількох основних компонентах, які містять більшість інформації.
Переваги PCA:
- Спрощення даних. Зменшення кількості вимірів допомагає спростити моделі й аналізи, знижує шум і покращує ефективність алгоритмів машинного навчання.
- Зменшення обчислювальних витрат. Менша кількість змінних означає менше обчислювальних ресурсів для аналізу і візуалізації.
- Виявлення структури. PCA допомагає виявити основні структури й шаблони в даних, що складно побачити у високорозмірних просторах.
Аналіз результатів PCA-кластеризації.
За допомогою PCA ви зміните розмірність даних.
В прикладі початковій сегментації використано для кожного клієнта дев’ять характеристик, які перетворили на три показники.
Після зменшення розмірності даних за допомогою PCA виконуйте кластеризацію.

Приклад даних після PCA
Візуально такі дані не дають корисної інформації. Плюс на обробку вручну потрібно багато часу. Алгоритми K-Means швидко аналізують показники й розподіляють їх на сегменти.
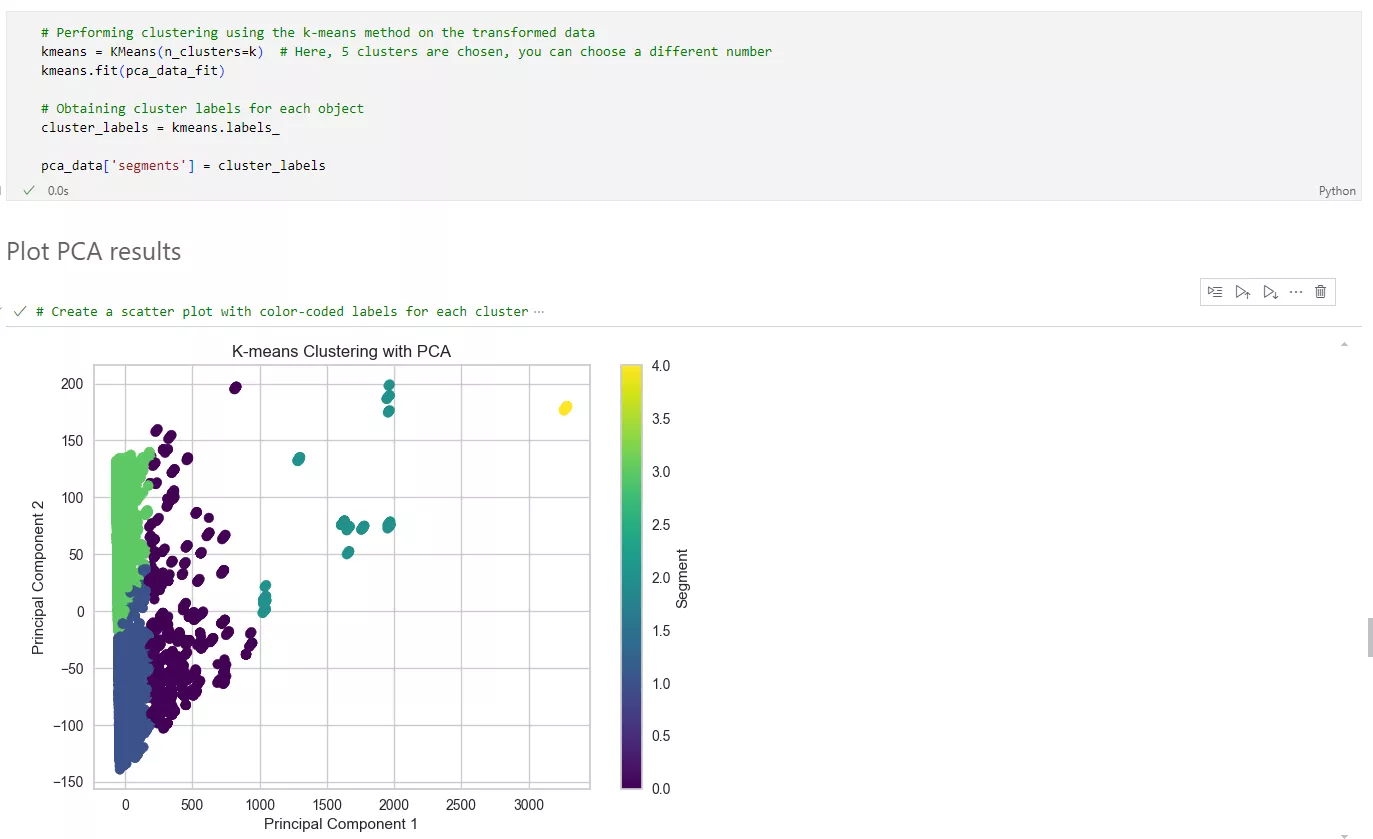
Приклад кластеризації PCA даних
На графіку кожна точка позначає певного клієнта, а колір — клас, до якого він належить. Кожен сегмент можна відділити один від одного, а це означає, що користувачі відрізняються за унікальними ознаками.
Використовуючи новий розподіл на кластери, повертайтеся до метрик RFM-аналізу.
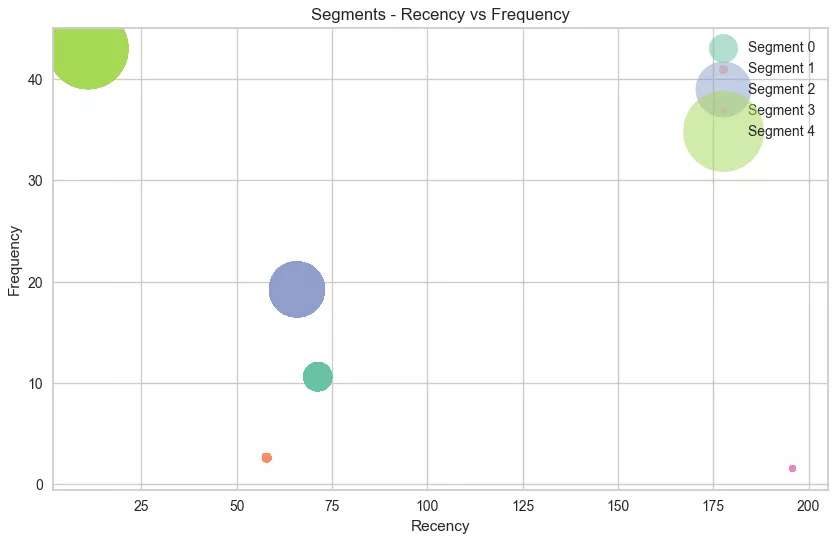
Кластер 0: Infrequent Low Spenders (Medium R, Low F, Low M).
Кількість клієнтів: 14010.
Купують із помірною регулярністю, але витрачають незначні кошти. Їх варто заохочувати робити часті й великі купівлі.
Кластер 1: High-Frequency Big Spenders (Low R, High F, High M).
Кількість клієнтів: 144.
Такі люди купують часто й за великим чеком. Вони є цінними для бізнесу й потребують особливої уваги для підтримання лояльності.
Кластер 2: Dormant Low Spenders (High R, Low F, Low M).
Кількість клієнтів: 17373.
Давно не купували і взагалі рідко купують, чеки невеликі. Ці користувачі потребують активного залучення і стимулювання для повернення.
Кластер 3: Occasional Medium Spenders (Low R, Medium F, Medium M).
Кількість клієнтів: 1406.
Нещодавно здійснювали покупки, роблять це періодично і витрачають середні суми.
Кластер 4: Moderately Frequent Medium Spenders (Medium R, Medium F, Medium M).
Кількість клієнтів: 325.
Ці люди купують із помірною регулярністю і за середнім чеком. Вони мають потенціал для збільшення витрат за умови належної мотивації.
Застосування PCA значно покращило якість кластеризації: знижений вплив кореляції між метриками й виділені основні компоненти, що несуть найбільшу варіативність даних. Це дало змогу краще розподілити користувачів за сегментами.
Отримані дані збережено для побудови звіту.
Висновки
Ефективний бізнес завжди орієнтується на клієнта. Знання його потреб, поведінки й переваг є ключем до створення успішних маркетингових стратегій і підвищення якості обслуговування.
- RFM-аналіз —перевірений метод, що дає класифікувати користувачів за частотою покупок, розміром витрат і давністю останньої трансакції. Такий підхід допомагає зосередитися на найцінніших сегментах аудиторії.
- RFM вимагає якісного датасету, що може бути отриманий з Google Analytics 4. Інтеграція GA4 з Google BigQuery автоматизує збір даних для подальшої обробки.
- Підготування даних — критично важливий етап для отримання коректних результатів. Містить очищення від пропусків, нормалізацію значень, видалення аномалій і структурування показників.
- З використанням Python і бібліотек pandas, scikit-learn, numpy, matplotlib і seaborn можна автоматизувати обробку даних, створити RFM-моделі й отримати цінні інсайти.
- RFM-аналіз дає змогу:
- виявити найвідданіших клієнтів;
- розробити персоналізовані стратегії;
- оптимізувати маркетингові витрати;
- підвищити рівень задоволення покупців.
- Завдяки RFM можна сегментувати покупців на групи, наприклад, Champions, Loyal Customers, Big Spenders, Perfectionists, Dreamers тощо. Кожна з них має унікальні потреби й потенціал для бізнесу.
- Для глибшої сегментації користувачів можна використовувати метод K-Means, який групує їх за схожими характеристиками й дає адаптувати маркетингові стратегії для кожного кластеру. Тому RFM-аналіз допомагає значно підвищити ефективність бізнес-процесів, орієнтуючись на поведінку клієнтів.

 4
4
 4
4
 0
0
Свіжі
Meta (Facebook) Pixel Helper: що це таке і як його налаштувати?
У цій статті детально розгляну, що це за інструмент, принцип його роботи та як за його допомогою перевірити встановлення Pixel і передачу подій із сайту в кабінет Meta
GA4 для eCommerce: які метрики справді впливають на дохід, а які — просто «для звіту»
Як перестати бути пасивним спостерігачем і почати шукати в GA4 точки зростання
Чому сегментація — ключ до ефективного ecommerce-маркетингу
У цій статті я розповім, як сегментація допомагає перетворити хаотичний маркетинг на точний і персоналізований