Локалізація текстових метаданих для App Store: вплив культурних та національних особливостей
Згідно зі звітом Mobile Market Forecast 2021-2025 платформи Sensor Tower, найбільшими світовими ринками мобільних додатків є Азіатський, Європейський, Північноамериканський, Латиноамериканський, Близькосхідний та Австралійський. Кожен із регіонів значно відрізняється від інших традиціями, світоглядом місцевих жителів і навіть законодавчою системою, що впливає на специфіку ведення бізнесу у цих регіонах. ASO, як частина маркетингу, також працює з урахуванням регіональних відмінностей. Його завданням є грамотна адаптація текстових та графічних метаданих під кожну конкретну цільову країну.
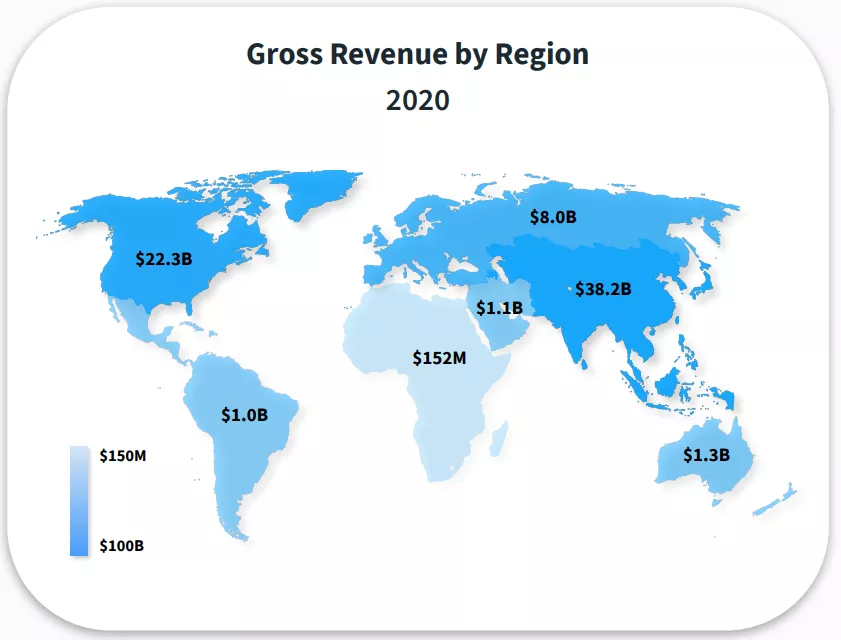
App Store Consumer Spending by Region
App Store Downloads by Region
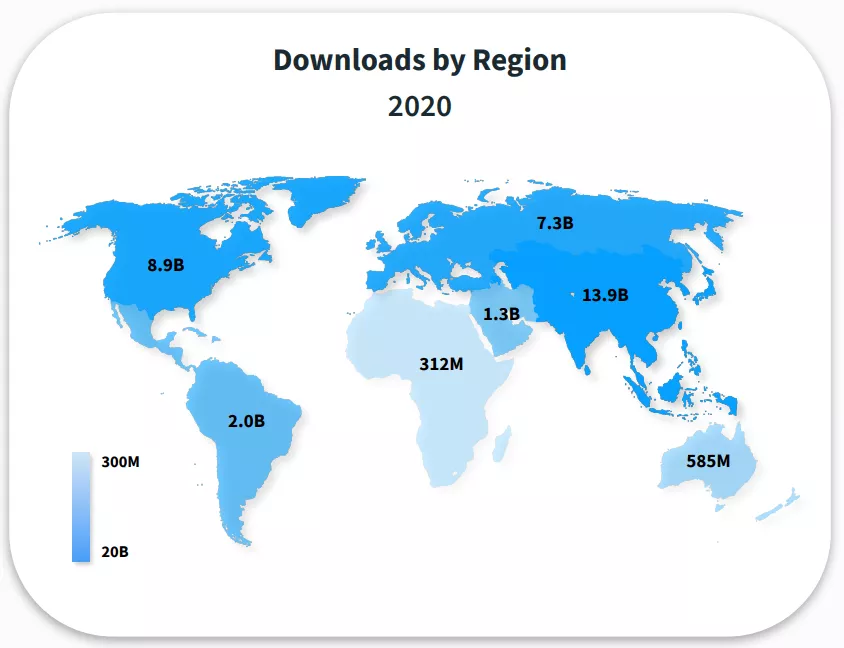
У цій статті спеціаліст RadASO розповідає, як культурні та національні особливості різних регіонів впливають на процес складання текстових метаданих для App Store (Title, Subtitle та Description, що не індексується, але впливає на конверсію) і як подолати труднощі, що виникають у процесі локалізації сторінки застосунку.
Локалізація метаданих під азіатський регіон
Ключовими країнами регіону за кількістю завантажень та прибутковості є Китай, Японія та Корея, тому в цьому розділі максимальна увага буде приділена особливостям саме цих держав.
1. Особливості конкуренції на регіональному ринку
Однією з особливостей регіону є те, що на ринку мобільних застосунків місцеві розробники мають досить сильні позиції, тому при локалізації сторінок додатків орієнтуйтесь саме на них. Як приклад наведу список топових додатків за кількістю інсталлів у ніші бебі-трекерів у Великій Британії, США та Японії:
Великобританія
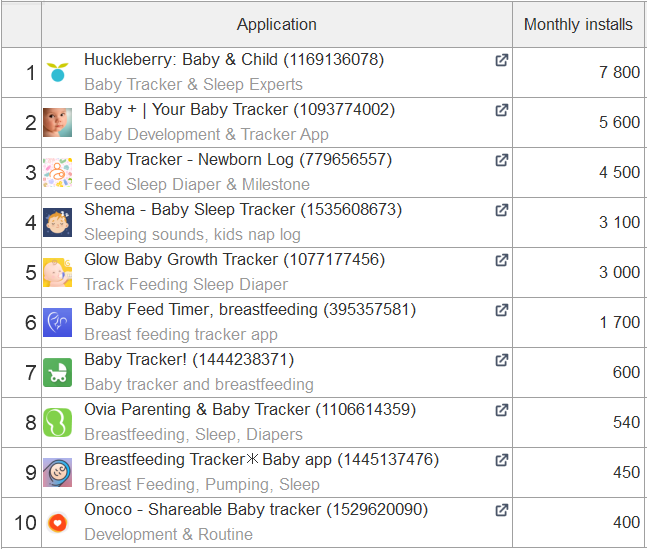
![]()
США
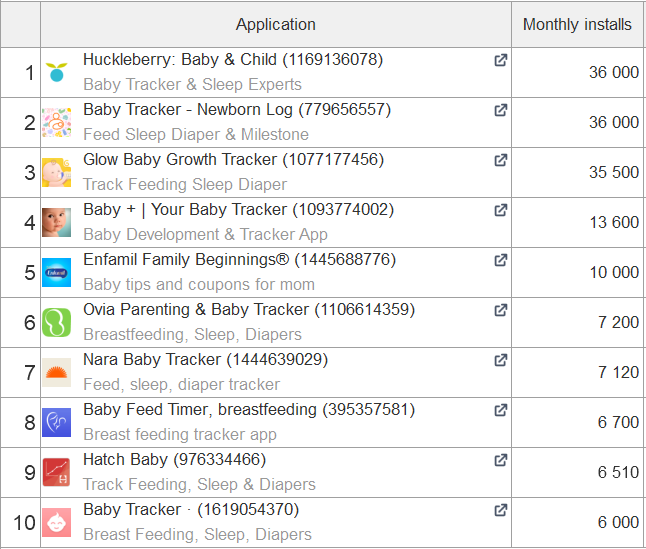
Японія
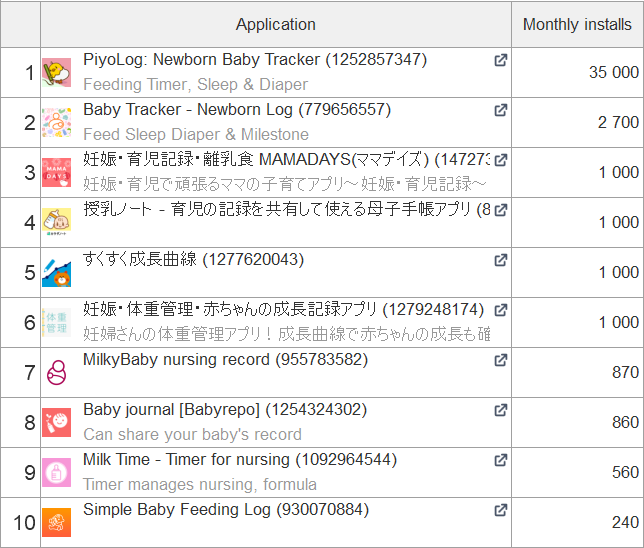
Як бачите, пошукова видача має суттєві відмінності: у країнах Заходу переважають глобальні конкуренти, тоді як у Японії — локальні.
2. Локалізація бренд-неймів у державах регіону
Користувачі країн Азіатського регіону люблять використовувати місцеві варіанти назв відомих брендів. А в Китаї, наприклад, чистота рідної мови активно підтримується урядом, зокрема, законодавчо. Назви застосунків часто також локалізовані. Для цього можуть бути використані два підходи: передача звучання назви та передача змісту.
При передачі звучання перекладач намагається зберегти фонетичну ідентичність, те, як назва бренду чується споживачеві. При цьому зміст адаптованої назви нерідко змінюється. Нижче наведено приклад адаптації назви застосунку Le Baby — breastfeeding, sleep для Китаю:
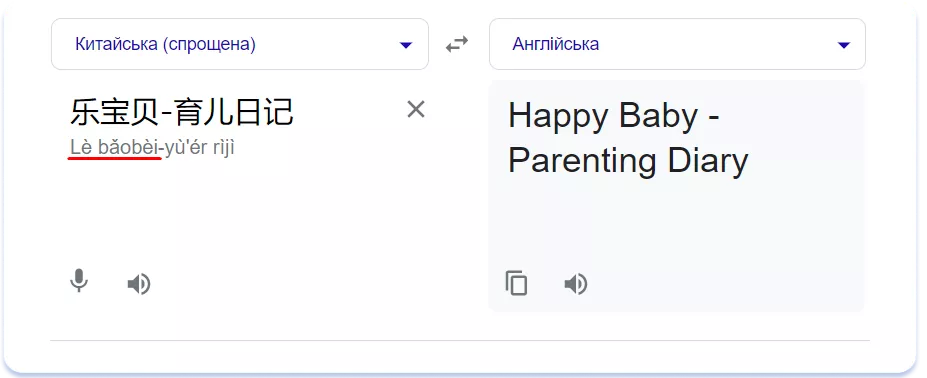
Звучання назви залишилося незмінним, а смислове значення хоч і змінилося, але все одно звучить добре.
А ось вже приклад смислової адаптації назви застосунку TinyLog на китайську:
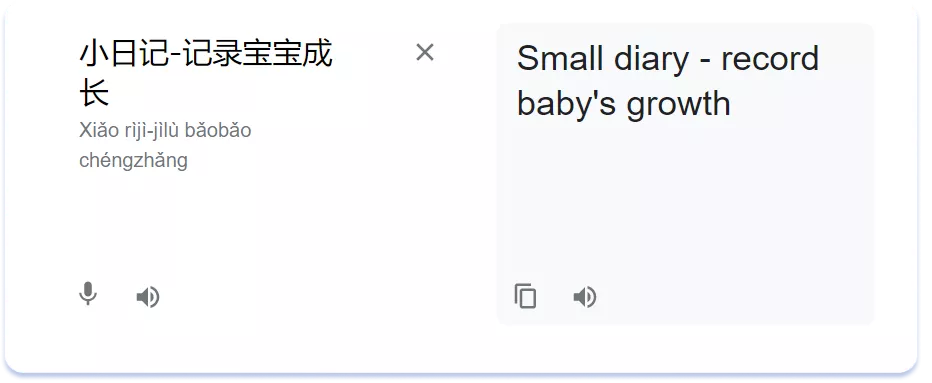
У Японії процес адаптації назв ускладнюється існуванням у мові трьох систем письма: кандзі — традиційних ієрогліфів китайського походження, а також двох складових абеток — хірагани та катакани. Останні часто використовуються для транслітерації іноземних слів, у тому числі назв брендів, японською мовою. Причому всі три системи письма можуть бути присутніми в одному японському реченні.
Ось приклад адаптації японською назви застосунку PiyoLog: Newborn Baby Tracker:
![]()
Як бачимо, для передачі звучання назви «PiyoLog» використали відразу дві складові абетки.
Варто відмітити, що Азіатський регіон культурно дуже різноманітний. Локалізація назв застосунків може суттєво відрізнятись у кожній окремій країні. Правильно адаптувати бренд-нейм або назву додатку вам допоможе ретельне вивчення місцевого ринку та допомога носія мови, що добре розуміє культурний контекст своєї держави.
3. Лексична різноманітність східних мов
Регіональні мови країн Азіатського регіону мають досить багатий словниковий запас, що значно впливає і на семантичне ядро: існує безліч варіантів написання різних слів і понять. Для прикладу наведемо різні варіанти передачі слова «baby» китайською та корейською мовами:
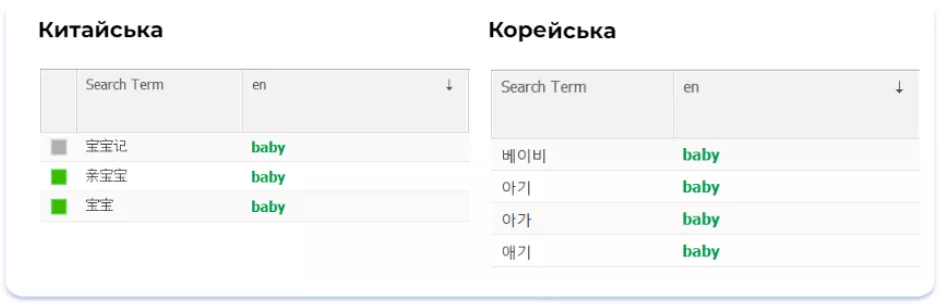
Зрозуміти, який із можливих варіантів виглядає в тексті найбільш органічно, — складне завдання, впоратися з яким під силу лише людині, глибоко зануреній у відповідну мовну культуру. Ми рекомендуємо під час підготовки текстових метаданих для мов Азіатського регіону користуватися послугами нейтів-спікерів — носіїв мови. Знань та навичок навіть професійних перекладачів може бути недостатньо для грамотної локалізації метаданих для цього складного регіону.
4. Особливості пунктуації мов Сходу
Важливою особливістю мов Азіатського регіону є незвична для європейців система розділових знаків.
Одними з найбільш значних особливостей, що впливають як на зовнішній вигляд текстових метаданих, так і на ранжування застосунку за пошуковими запитами, що входять у метадані, є особливі правила використання пробілів у східних мовах. У традиційній китайській та японській писемності пробіли не використовуються, слова в реченні пишуться поспіль, розділяючись лише розділовими знаками при необхідності. Наприклад, ось як виглядає назва одного з додатків для відстеження посилок на сторінці стора:
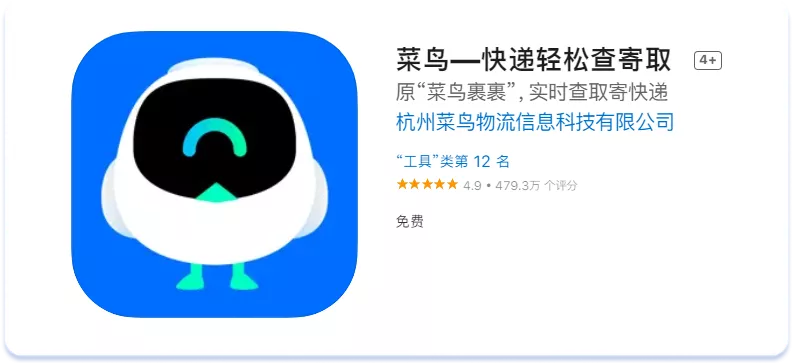
А так ця назва виглядатиме з розбивкою на окремі слова:
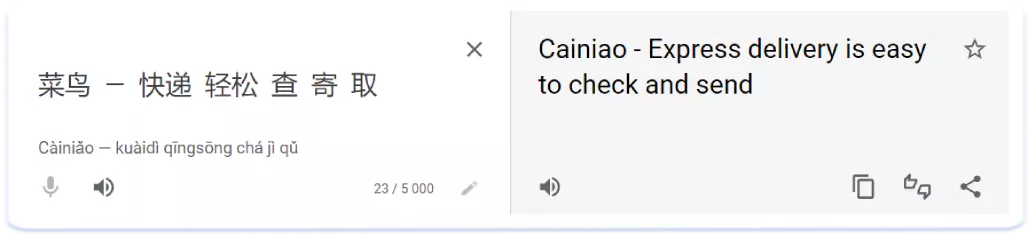
Цікаво, що включивши кожне з цих окремих «слів» у текстові метадані в App Store, додаток буде ранжуватися і за написаною разом фразою. Наприклад, щоб отримати індексацію за наведеним вище запитом «菜鸟—快递轻松查寄取» потрібно додати у полі keywords окремі ключі з цього запиту: 菜鸟,快递,轻松,查,寄,取. Ця особливість робить текстові метадані та тексти китайською та японською в цілому ємними, насиченими ключовими словами. Рекомендуємо не додавати їх надмірну кількість до полів Title та Subtitle азійських локалей, щоб уникнути rejection від App Store за переспам ключовими словами.
Дещо по-іншому виглядає ситуація з тайською. У цій мові пробіли використовуються лише для поділу речень, а між словами всередині речення їх немає. Наприклад, тайська сторінка одного з додатків трекера посилок виглядає так:

А ось розбивка наведеного вище subtitle на окремі слова:
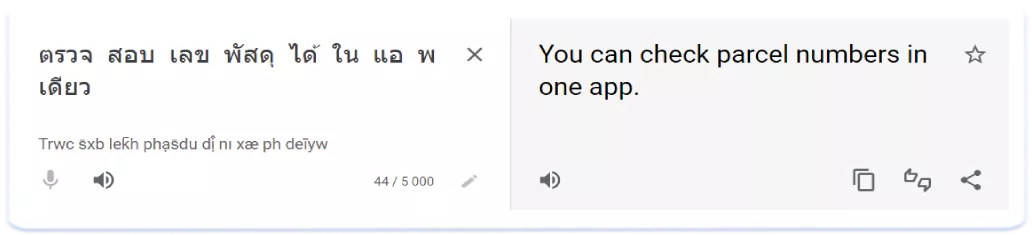
Але, на відміну від мов з ієрогліфічною писемністю, додавши в метадані всі окремі слова, що входять у запит, ранжування за разом написаною фразою ви, швидше за все, не отримаєте. Тобто, щоб ранжуватися за запитом, наприклад, «เช็คพัสดุ» («check the parcel»), його доведеться додати в метадані повністю. На щастя, більшість пошукових запитів є окремими реченнями, які можуть бути записані через пробіл в Title і Subtitle або кому в keywords. Наступний додаток буде ранжуватися за двома релевантними запитами: «ติดตามพัสดุ» («parcel tracking») та «เช็คเลขพัสดุ» («check parcel number»), завдяки тому, що ці запити були прописані в заголовку окремо, будучи, по суті, незалежними реченнями:
ติดตามพัสดุ เช็คเลขพัสดุ ย์ไทย
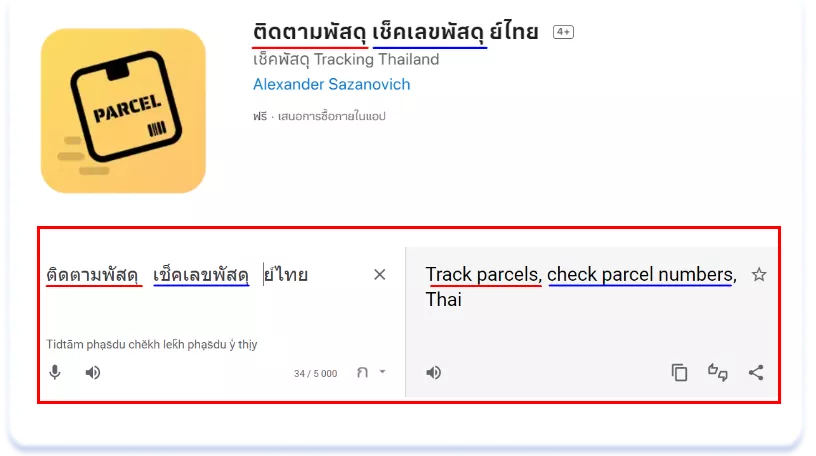
Відмінності у пунктуації між європейськими та азійськими мовами не обмежуються лише нюансами використання пробілів. Мови регіону містять свою власну систему розділових знаків і правил їх використання. Як приклад — фрагмент опису додатка трекера грудного годування:

У тексті є використання специфічних знаків китайського та японського ієрогліфічного письма: краплеподібної коми «、» та китайської крапки «。». У той же час використовуються і звичні для нас «європейські» коми та тире. Але це не зовсім так. У китайській і японській писемності ширина розділових знаків повинна відповідати ширині ієрогліфа, тому розділові знаки вже містять «вбудований» пробіл, що створює необхідний відступ до наступного ієрогліфа. При цьому і розділовий знак, і «вбудований» пробіл вважаються одним символом. Ми в RadASO називаємо такі символи «суперсимволами». Їх короткий список:
- китайська крапка «。»;
- китайська кома «,»;
- каплеподібна кома «、»;
- двокрапка «:»;
- тире «-»;
- крапка з комою «;»;
- знак оклику «!»;
- знак запитання «?»;
- інтерпункт «・».
Використовуйте їх для економії місця у двох китайських та японській локалях. Також можна використовувати ці символи і в інших локалізаціях, але ми помітили, що частина з них «склеюють» слова, що розділяються. Наприклад, при використанні китайської коми ось у такій конструкції: «baby,milestone tracker» отримаєте ранжування за запитом «babymilestone tracker». Але за запитами з ключами «baby» та «milestone» додаток ранжуватися перестане. Докладніше про використання «суперсимволів» читайте в Telegram-каналі RadASO:
У мовах Азіатського регіону існує також безліч інших розділових знаків, не згаданих у цій статті: специфічні різновиди лапок, дужок (в японській, наприклад, їх існує 14 різновидів), символів повторення ієрогліфів. Розібратися в хитросплетінні азіатських мов допоможе лише носій мови, людина глибоко занурена у мовний та культурний контекст відповідної країни.
5. Світоглядні відмінні риси регіону
Працюючи з текстовими метаданими, необхідно пам’ятати і про ментальні особливості жителів країн Азіатського регіону. Якщо для країн Європи, Північної Америки та Австралії характерні чіткість і лаконічність формулювань, індивідуалізм, для писемного мовлення азіатських народів — поважніша манера спілкування та акцент на взаємодії людей. Крім того, тексти часто виглядають більш пишно і багато, не так лаконічно, як у Західному світі. Найбільш наочно різницю між західним та східним підходом до складання текстів (і текстових метаданих зокрема) демонструє порівняння американського та японського варіантів сторінок додатку:
![]()
Переклад Title та Subtitle японської версії сторінки:
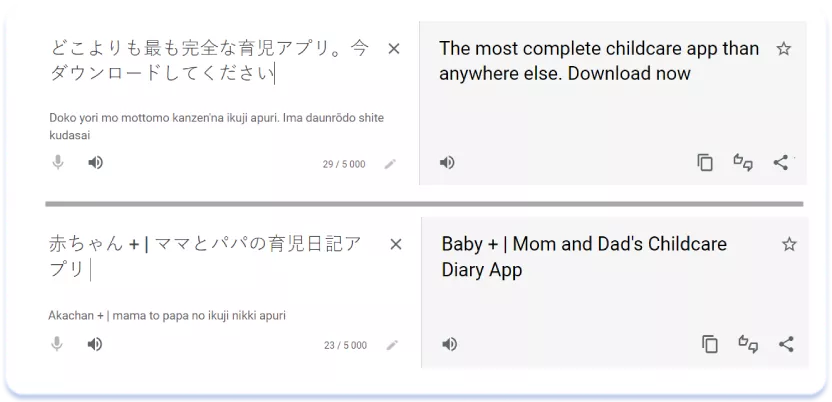
Більш «багатий» стиль створення текстів Title і Subtitle у японському варіанті пояснюється, частково, ємним характером японської писемності та можливістю вмістити більше інформації у допустимі 30 символів. Але й різний тон звернення до аудиторії теж цілком очевидний. Ті ж тенденції демонструє порівняння опису іншого трекера розвитку My Baby — Newborn Tracker на американській та японській версіях сторінки застосунку:
Опис у локалізації English (U.S.)
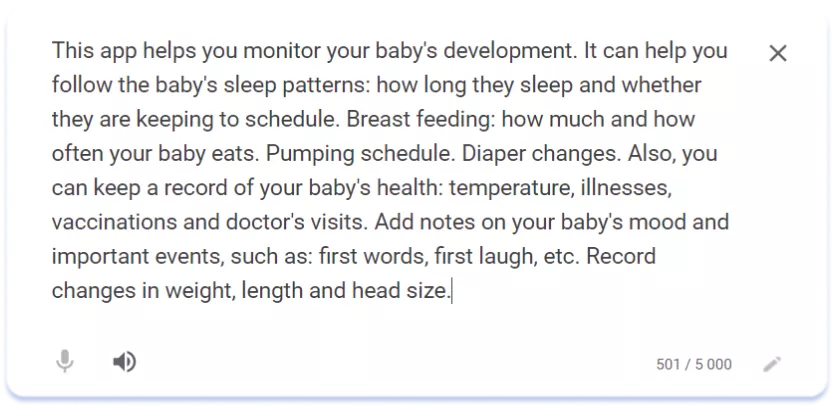
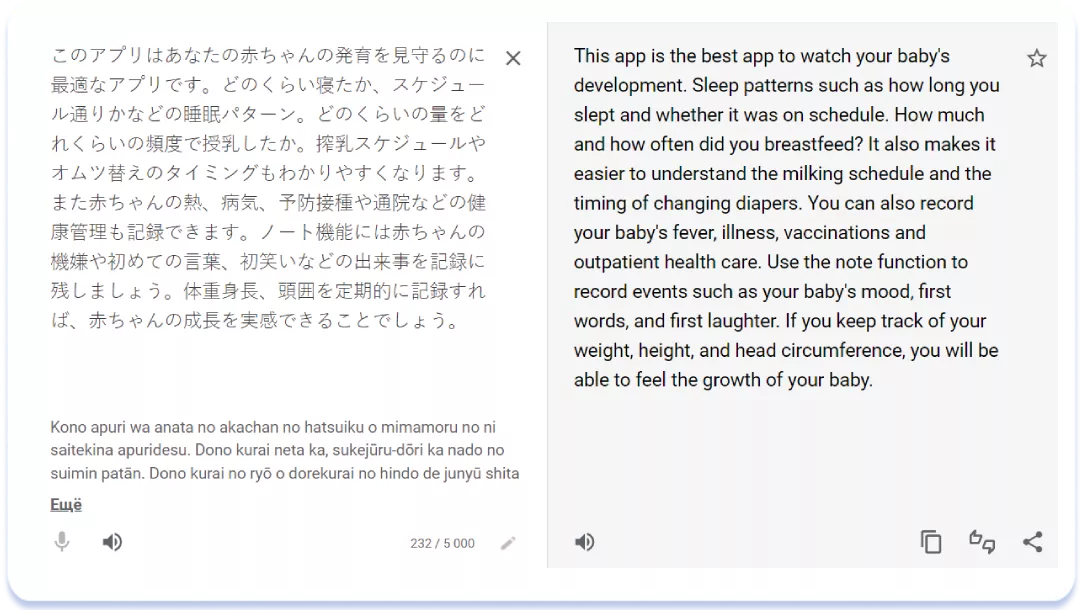
6. Регіональні відмінності китайської мови
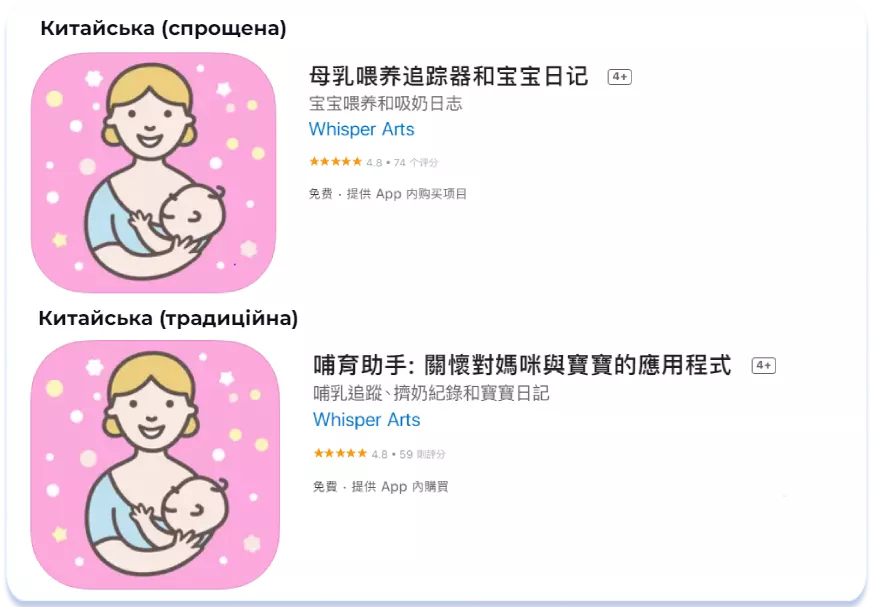
На завершення розгляду особливостей Азіатського регіону коротко торкнемося питання регіональних відмінностей китайської мови. Відомо, що в App Store існують дві локалізації китайської мови: Chinese (Simplified), що діє в Китаї, Сінгапурі та США та Chinese (Traditional) — у Гонконгу, Тайвані й Макао. Всі ці регіони мають значні політичні, економічні, історичні відмінності. Виконуючи локалізацію сторінки застосунку на китайську, орієнтуйтеся на семантичне ядро, конкурентів та культурні особливості найбільш пріоритетної для вас країни. Нижче наведено приклад відмінностей оптимізації метаданих додатку Breastfeeding Newborn tracker для Китаю, де використовується Chinese (Simplified) та Тайваню з Chinese (Traditional):
Chinese (Simplified) & Chinese (Traditional)
Особливості локалізації у західному світі: Європейський, Американський та Австралійський регіони
Зазначені регіони мають величезну кількість історичних зв’язків, і, як наслідок, дуже схожі між собою в культурному плані. Розглянемо їх основні особливості.
1. Вплив лексичних відмінностей мов на формування метаданих
Описуючи особливості країн Азіатського регіону ми згадували про багатший, пишніший стиль писемного мовлення в державах регіону. Але ментальні відмінності між державами Сходу та Заходу — далеко не основна причина того, що текстові метадані на локалізованих під західні мови сторінках додатків виглядають сухо та лаконічно в порівнянні з їх східними варіантами. Основна причина — у довжині слів у європейських мовах. Оптимізуючи сторінку застосунка під європейські локалі, ви не зможете вмістити велику кількість пошукових запитів у метадані (нагадаєю, що кожне з полів Title та Subtitle має обмеження в 30 символів). Порівняйте сторінки застосунку для проєктування та декору інтер’єрів Room Planner — Home Design 3D, оптимізовані для локалей Italian та Chinese (Traditional):
Italian & Chinese (Traditional)
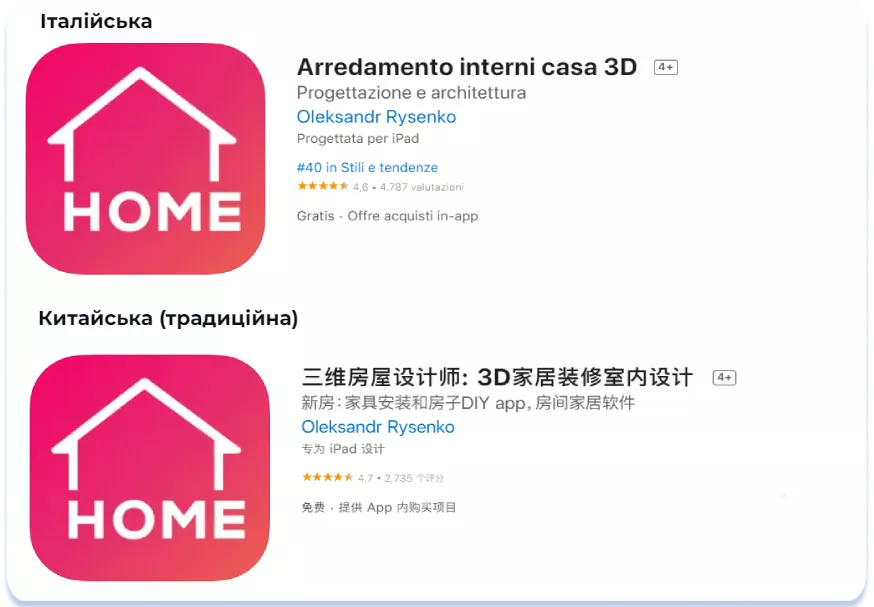
Незважаючи на те, що Title та Subtitle в італійській версії мають більшу довжину (27 та 28 символів відповідно), ніж у китайській (19 та 24 символи), у плані інформативності та насиченості ключовими словами китайська версія має перевагу. Нижче наведено переклади Title локалізацій Italian та Chinese (Traditional):
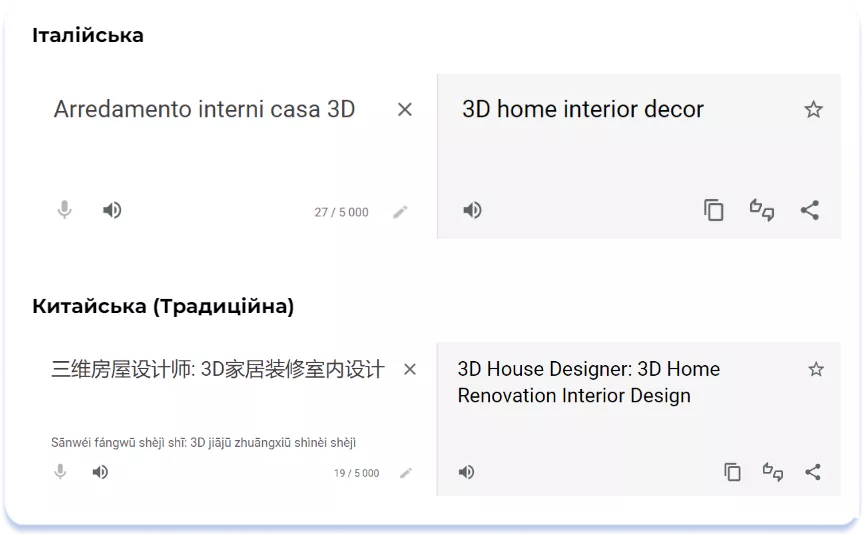
Найбільші проблеми з насиченням метаданих ключовими словами виникають при оптимізації сторінки застосунку для локалей романських мов: французької, іспанської, італійської, португальської, а також низки мов германської групи: німецької, нідерландської. Англійська ж серед усіх західних мов — одна з найкоротших і найбільш пристосованих для оптимізації ключових слів. Компанія Alconost склала статистичну таблицю, що показує, наскільки різною буде довжина тексту при передачі однієї й тієї ж інформації різними мовами. Ось її фрагмент:
|
Мова оригіналу |
Мова перекладу |
На скільки текст мовою перекладу більше (+) або менше (-) оригіналу |
|---|---|---|
|
Англійська |
Французька |
21.18% |
|
Англійська |
Іспанська |
19.52% |
|
Англійська |
Італійська |
17.91% |
|
Англійська |
Німецька |
16.67% |
|
Англійська |
Нідерландська |
13.80% |
|
Англійська |
Португальська (Португалія) |
14.29% |
|
Англійська |
Португальська (Бразилія) |
12.96% |
|
Англійська |
Польська |
9.33% |
|
Англійська |
Російська |
9.11% |
|
Англійська |
Чеська |
3.70% |
|
Англійська |
Арабська |
-6.25% |
|
Англійська |
Японська |
-39.68% |
|
Англійська |
Корейська |
-44.04% |
|
Англійська |
Китайська (Спрощена) |
-61.97% |
|
Англійська |
Китайська (Традиційна) |
-63.80% |
2. Використання локальної та англійської семантики при вузькому семантичному ядрі
Європа складається з великої кількості держав, серед яких багато невеликих за чисельністю населення: держави Скандинавії, Балтії та Бенілюксу, велика кількість країн Центральної Європи. Збираючи семантичне ядро для них, ми стикаємося з проблемою відсутності достатньої для заповнення метаданих кількості семантики на місцевих мовах. Рішенням може стати використання більш численної семантики англійською, але обираючи цей підхід варто враховувати різний ступінь проникнення англійської в культуру кожної конкретної держави. Wikipedia наводить карту рівня володіння англійською мовою в Європі:
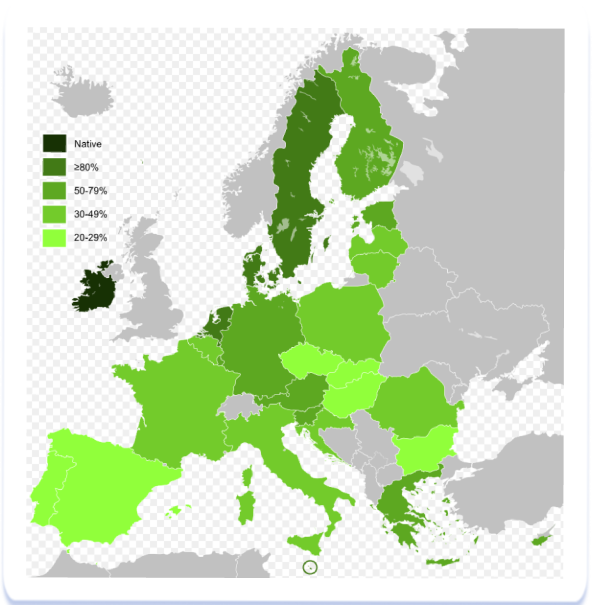
Як бачите, найбільша кількість людей, які розмовляють англійською, зафіксована в Скандинавії, а також державах, чиї мови споріднені з англійською: Німеччині, Австрії, Нідерландах. У країнах Східної та Південної Європи позиції англійської слабші.
Подивіться, як впливає рівень поширення англійської мови на текстові метадані на прикладі застосунку Clockmaker: Mystery Match 3. Ось фрагменти сторінки додатку для локалі English (U.K.), що діє у всіх країнах Європи, а також для локалей мов кількох малонаселених країн, де семантичне ядро також невелике.
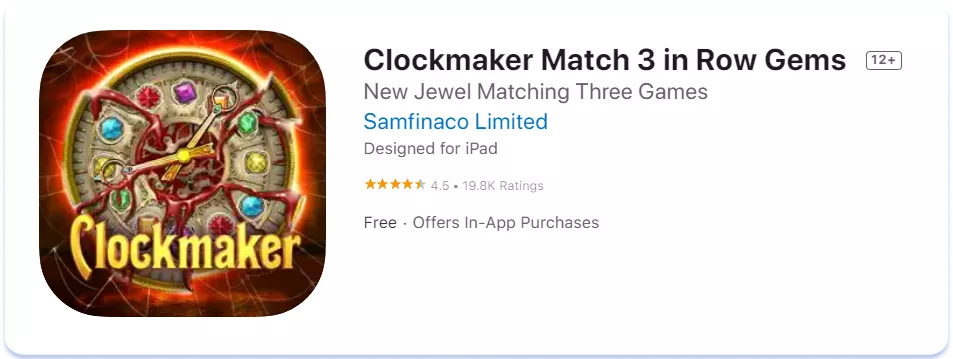
Поле Title локалей Данії та Нідерландів, де сильні позиції англійської, насичено частотними ключами з англійської семантики: logic, puzzle, jewel. Нагадаю, що ключі, зазначені в цьому полі, мають найбільшу вагу. У нідерландській локалі, крім того, поле Subtitle взагалі цілком складено з англійських ключів:
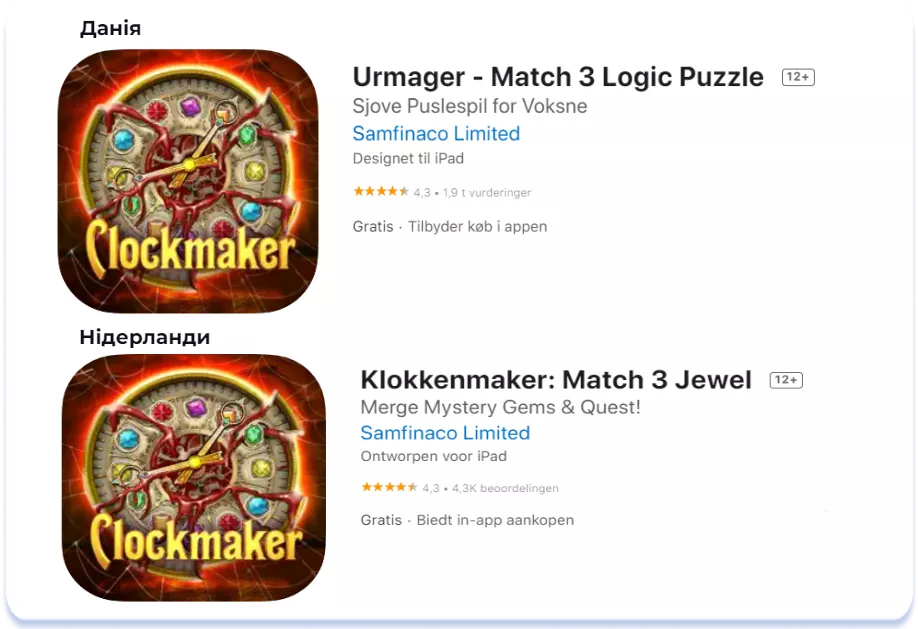
У той же час Title угорської та словацької локалей складається із місцевої низькочастотної семантики. Виняток складає ключ «match 3» у локалі Словаччини, але він і так уже покритий у локалі English (U.K.). При цьому, Subtitle угорської локалі повністю складено угорською, а словацької — повністю англійською.
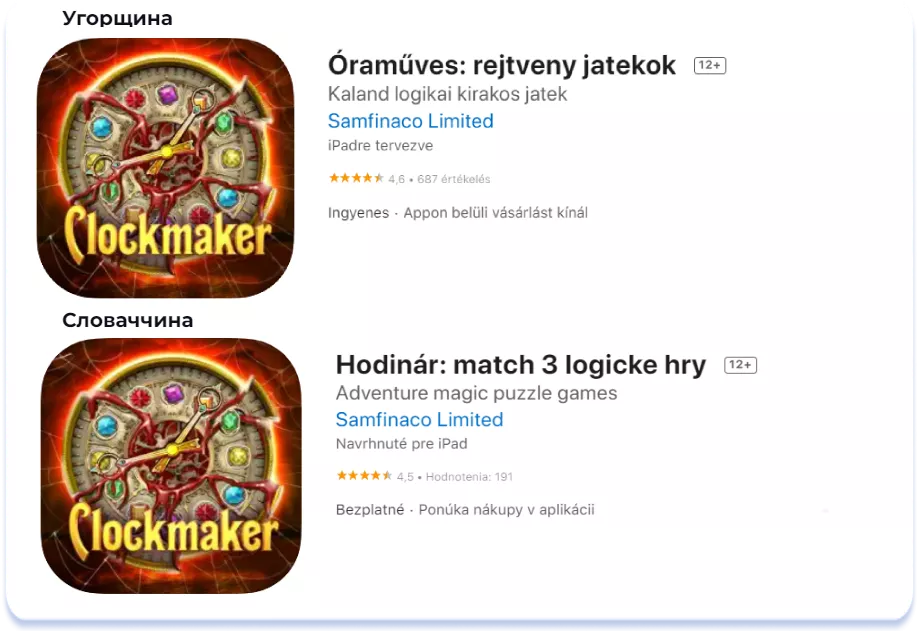
У ряді додатків при нестачі семантики локальними мовами поля Title та Subtitle заповнюються з використанням англійських ключів, а текст Description локалізується на місцеву мову (в App Store поле Description не індексується):
Kitten Match (локаль Czech)

Обираючи цей підхід, пам’ятайте — отримавши виграш в оптимізації ключових слів (більш частотна англійська семантика в полях Title і Subtitle), в той же час можете знизити конверсію у встановлення. Бо більшість користувачів віддають перевагу контенту рідною мовою.
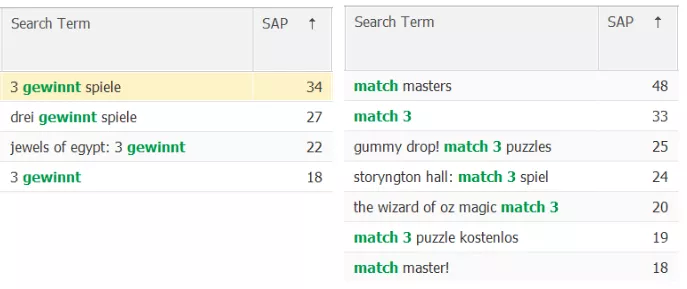
У кожній з держав є також низка національних та нішевих особливостей у використанні англомовної лексики, визначити які допоможе докладний аналіз семантичного ядра та конкурентів. Наприклад, у Німеччині для позначення ігор геймплею «Match-3» одночасно із запитом «match 3» також широко використовується національний варіант позначення подібних ігор «3 gewinnt»:

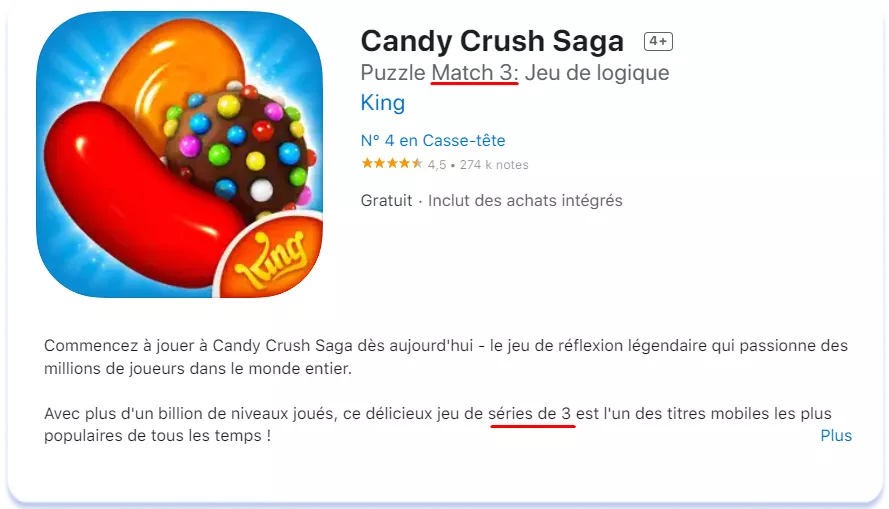
У той самий час у Франції, де рівень знання англійської нижчій, ніж у Німеччини, і де населення часто неохоче говорить англійською (дається взнаки вікове суперництво двох держав) англомовний термін «match 3» використовується у якості основного. На прикладі нижче національний варіант найменування геймплею «séries de 3» використовується в полі Description, яке не індексується в App Store, а в Title використаний англійський варіант:
3. Регіональні відмінності англійської, французької, португальської та іспанської
Ще однією особливістю Європейського, Американського та Австралійського регіону є широка географія поширення його головних мов: англійської, французької португальської та іспанської. В App Store для різних варіантів цих популярних мов навіть створені окремі локалізації, наприклад, для англійської це English (U.K.), English (U.S.), English (Canada) та English (Australia). Докладніше про покриття країн локалізаціями дивіться у таблиці. В результаті регіональні версії цих мов можуть значно відрізнятися між собою словниковим складом, мовними зворотами і навіть правилами граматики. Наприклад, незважаючи на спільне історичне минуле США та Великобританії, національні варіанти англійської в цих країнах істотно відрізняються граматично:
- закінчення слів «-or» у США перетворюється на «-our» у Великобританії: «colour», «favour», «flavour» чи «behaviour»;
- закінчення «-er» у Великобританії перетворюється на «-re»: «centre», «theatre»;
- подвоєння літери «l» у багатьох словах в американській англійській: skillful, fulfill, enroll (skilful, fulfil, enrol у британському варіанті).
До того ж відрізняється і лексика у двох варіантах мови. Нижче наведено порівняння популярності пошукових запитів (SAP) «truck games»/«lorry games» (ігри з вантажівками) та «jail games»/«prison games» (тюремні ігри) у США та Великобританії:
|
Search term |
Translation |
SAP* English (U.S.) |
SAP* English (U.K.) |
|---|---|---|---|
|
truck games |
ігри з вантажівками |
62 |
39 |
|
lorry games |
ігри з вантажівками |
- |
32 |
|
jail games |
тюремні ігри |
29 |
8 |
|
prison games |
тюремні ігри |
32 |
24 |
*Search Ads Popularity (SAP) — демонструє популярність пошукового запиту від 5 до 99.
Термін «lorry games» використовується виключно у британській англійській, в той час, як «jail games» — типовий саме для американської англійської.
Часом буває й інше: один і той самий вираз може позначати різні поняття у різних регіональних варіантах мови. Подивіться на пошукову видачу запиту «coin price» у США та Великобританії. Зазначу, що значення популярності запиту (SAP) у двох країнах не надто відрізняється: 8 — у США та 5 — у Великобратинії.

Як бачите, у США запит стосується у першу чергу сфери нумізматики і тільки один застосунок з 10-ки кращих відноситься до ніші криптовалют — CoinMarketCap: Crypto Tracker. У Великобританії навпаки: пошукова видача складається майже повністю з додатків зі сфери криптовалют. Єдине виключення — застосунок PCGS CoinFacts Coin Collecting, що втім займає першу позицію.
Значні регіональні відмінності притаманні й іншим розповсюдженим світовим мовам. Наведу порівняння популярності пошукових запитів (SAP) «soldes» і «aubainerie» у Франції та Канаді, що ілюструє лексичну несхожість канадського та французького варіантів французької мови:
|
Search term |
Translation |
SAP* French |
SAP* French (Canada) |
|---|---|---|---|
|
soldes |
розпродаж |
25 |
5 |
|
aubainerie |
розпродаж |
- |
14 |
*Search Ads Popularity (SAP) — демонструє популярність пошукового запиту від 5 до 99.
Докладніше про регіональні особливості французької та англійської в Канаді, а також про особливості локалізації додатків для канадського ринку читайте у статті від Alconost.
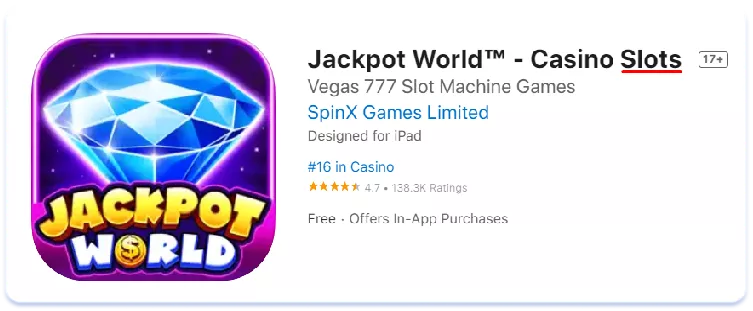
Лексичні відмінності впливають і на сторінки додатків у сторі. Для прикладу порівняйте текстові метадані американської та австралійської локалізацій англійської мови для топ-3 додатків за кількістю встановлень на австралійському ринку в ніші соціальних казино. Мова про імітацію ігор, які можна знайти в залах казино, водночас виграти реальні гроші в таких додатках не можна:
English (Australia)
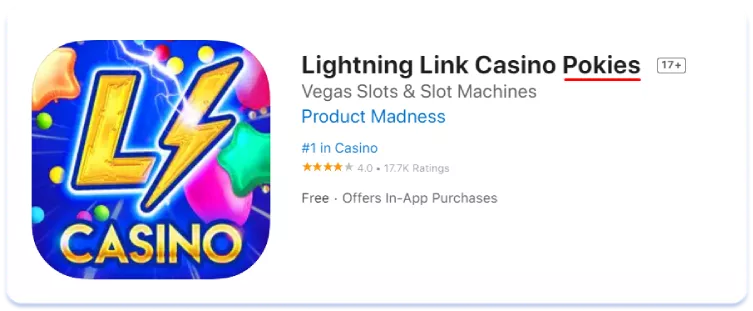
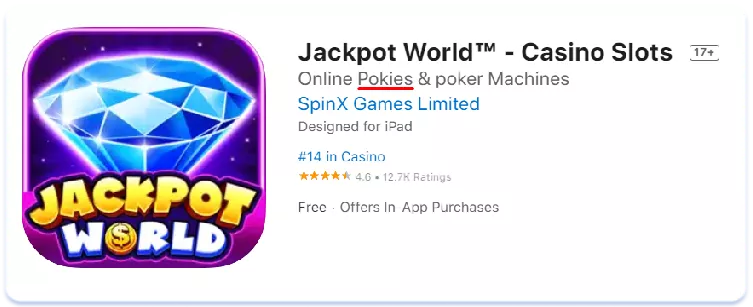

English (U.S.)
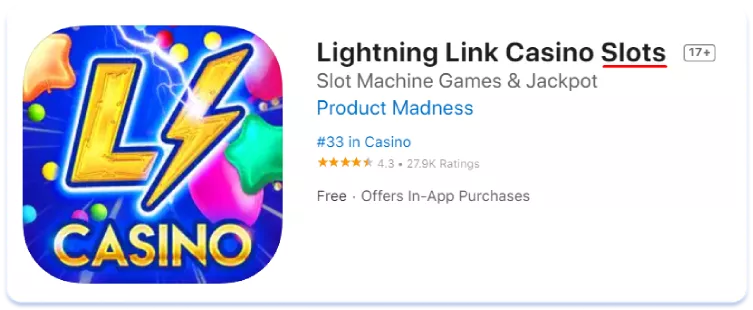
Cashman Casino Las Vegas Slots
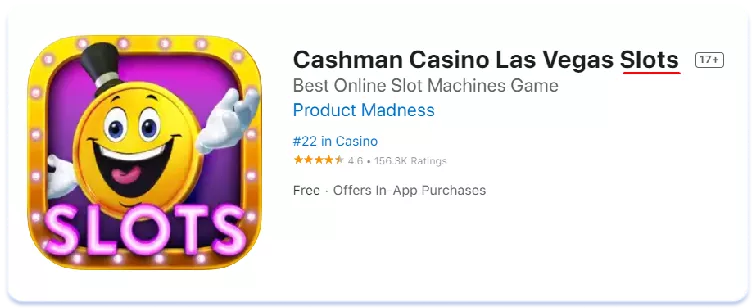
В Австралії для позначення гральних автоматів частіше застосовується термін «pokies», ніж його американський аналог «slots». Висновок тут простий: семантичне ядро, зібране для однієї регіональної версії мови, може бути зовсім неактуальним для іншої. Завжди ретельно збирайте та аналізуйте семантику для кожної з країн, для яких проводите локалізацію, якими б схожими в плані мови та культури вони не здавалися на перший погляд.
Особливості локалізації в регіонах Близького Сходу
Близький Схід — цікавий у плані бізнесу регіон, у якому середній дохід на одного користувача (ARPU) один із найвищих у світі. До того ж, згідно із вже згаданим звітом Mobile Market Forecast 2021-2025 платформи Sensor Tower, регіон динамічно розвивається і до 2025 року досягне зростання в 208% за показником прибутковості порівняно з 2020 роком:
App Store Consumer Spending by Region

Знаходячись між Європейським та Азіатським, регіон у культурному плані виявляє схожість із ними. Зупинюсь на культурних особливостях Близького Сходу, що впливають на метадані для App Store.
1. Регіональні відмінності арабської мови
Подібно до Західного світу, близькосхідний регіон має домінуючу мову — арабську, яка широко розповсюджена також у Північній Африці і має значну кількість регіональних відмінностей:
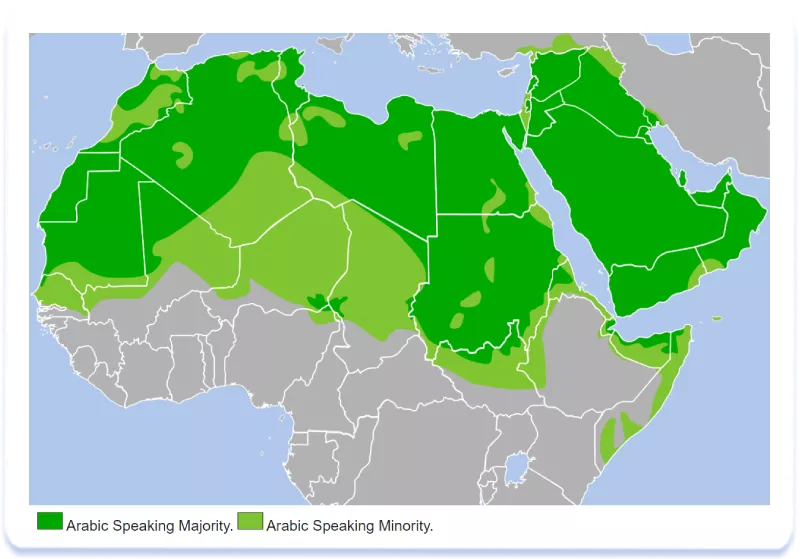
Приблизно в цих же державах діє і арабська локалізація App Store (докладніше про покриття локалізаціями дивіться в нашій таблиці). Хороша новина полягає в тому, що працюючи з текстовою інформацією, в тому числі і метаданими, для однієї з країн з діючою арабською локаллю, ми використовуємо стандартну арабську мову (Modern Standard Arabic або MSA), а не місцеві діалекти арабської. Відповідно, і локалізація в App Store для арабської створена теж лише одна. У той же час, процес збору семантики арабською нагадує роботу з англійською, іспанською, французькою та іншими мовами, що набули широкого географічного поширення: семантичне ядро збирається для пріоритетної для просування додатка держави. Семантичне ядро, зібране, наприклад, для Єгипту буде неефективним при оптимізації сторінки додатку, якщо цільовою з точки зору бізнесу державою є Саудівська Аравія.
2. Локалізація назв додатків та бренд-неймів на арабську
Необхідність локалізацій назв додатків та брендів на арабську залежить від ніші. Наприклад, вважається, що назви ігор зазвичай залишають написаними англійською. Ми перевірили це на прикладі ніші ігор із геймплеєм «Match-3» у Саудівській Аравії. З топ-10 додатків за кількістю установок тільки чотири мають локалізовану на арабську сторінку додатка.



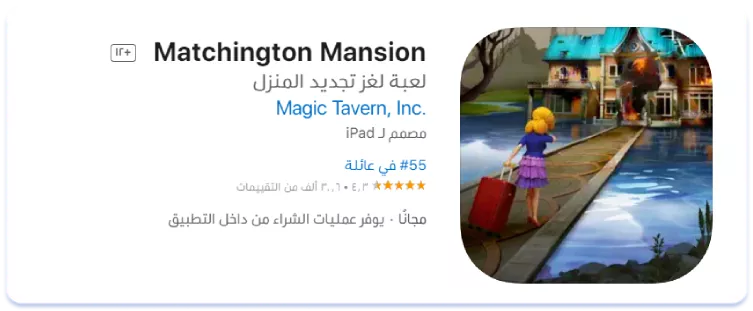
Справді, у всіх наведених вище прикладах назви додатків були залишені написаними англійською. Але ситуація виявилася іншою в ніші трекерів дитячої активності. З трійки лідерів за кількістю завантажень у двох із них назва виявилася повністю локалізованою на арабську, в одного — частково:
![]()
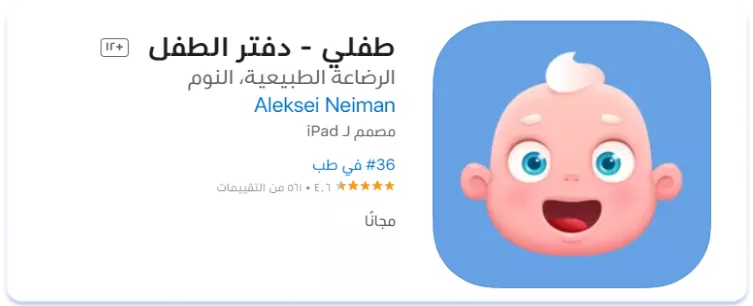

Тобто, локалізації сторінки застосунку на арабську передує вивчення ніші та конкурентів. Єдиного правила щодо локалізації назв додатків на арабську немає.
На завершення розділу ще один важливий нюанс. В арабській та івриті напрямок писемності — справа наліво. При цьому цифри і частини, написані латиницею, читаються зліва направо. В одному з наведених вище прикладів текст у Title читається так:

При цьому заголовки такого змішаного типу можуть відображатися некоректно в пошуку App Store: частина латиницею буде відображена повністю, незалежно від її розташування в Title, а арабська — може не поміститися повністю. Абсолютно коректно буде відображено текст або повністю латиницею, або повністю арабською.
3. Багатий словниковий запас арабської мови
Арабська — лексично багата мова. Існують різні варіанти написання одних і тих же самих термінів та назв:
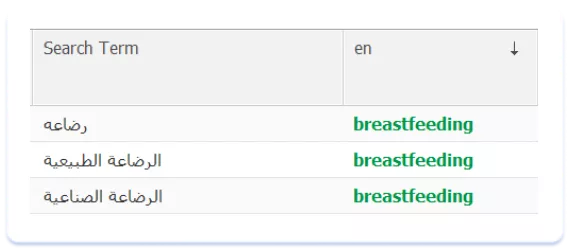
Подібна ситуація, нагадаю, в Азіатського регіоні. В арабському ця проблема вирішується так само — залученням до роботи над локалізацією носія мови. Тільки нейтів спікер допоможе з кількох варіантів вибрати той, який найбільш органічно впишеться в текстові метадані.
4. Формулювання, яких слід уникати в текстових метаданих арабською
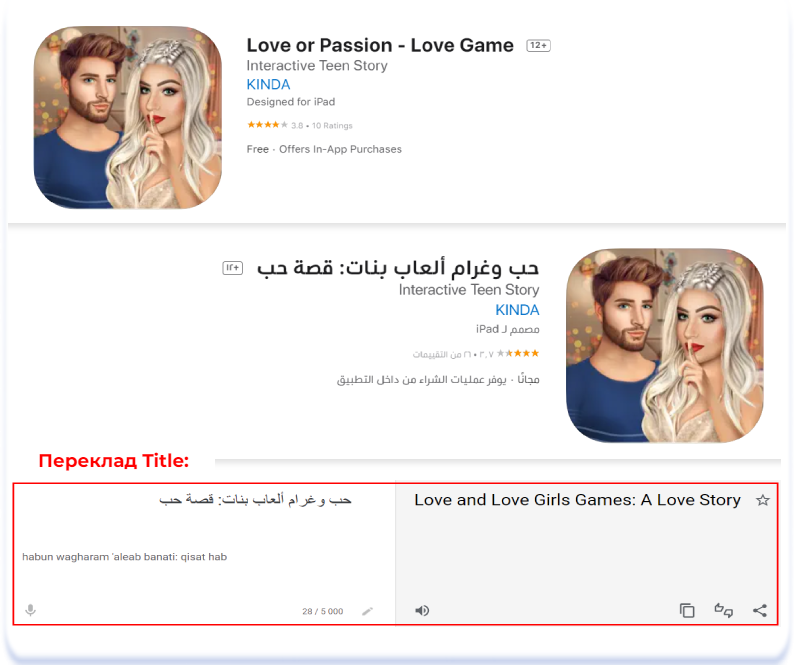
В арабській культурі існує велика кількість тем, які необхідно уникати: занадто відверте зображення людських взаємин, теми алкоголю, наркотиків, жорстокості, містики та азартних ігор. При локалізації сторінок додатків для арабського ринку, носій мови допоможе визначити доречність тих чи інших формулювань у метаданих. Раніше я писав, що при локалізації ігор назви, як правило, залишають англійською. Нижче наведено приклади ігор, назви яких були локалізовані на арабську для уникнення неоднозначних формулювань у Title:
Love or Passion — Love Game (English [U.S.]) & حب وغرام ألعاب بنات: قصة حب
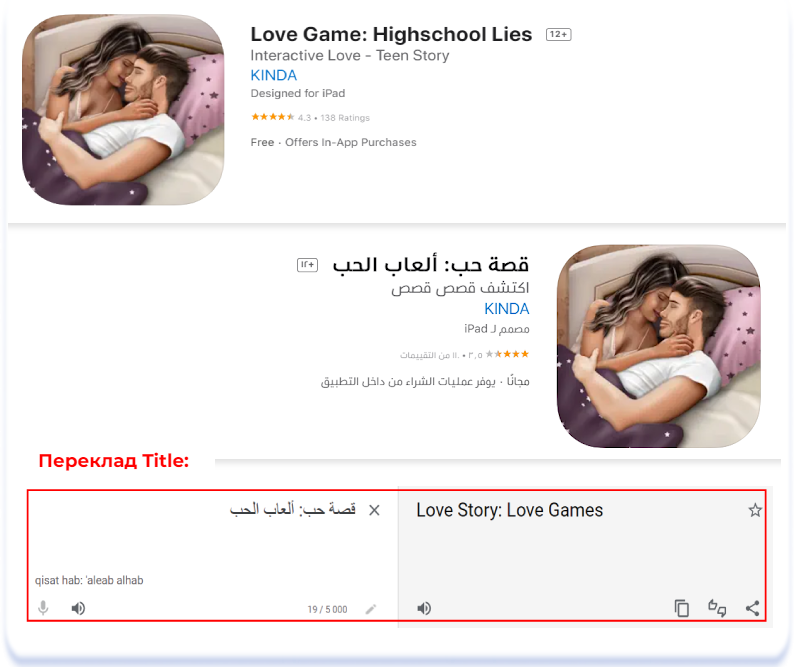
Love Game: Highschool Lies (English [U.S.]) & قصة حب: ألعاب الحب
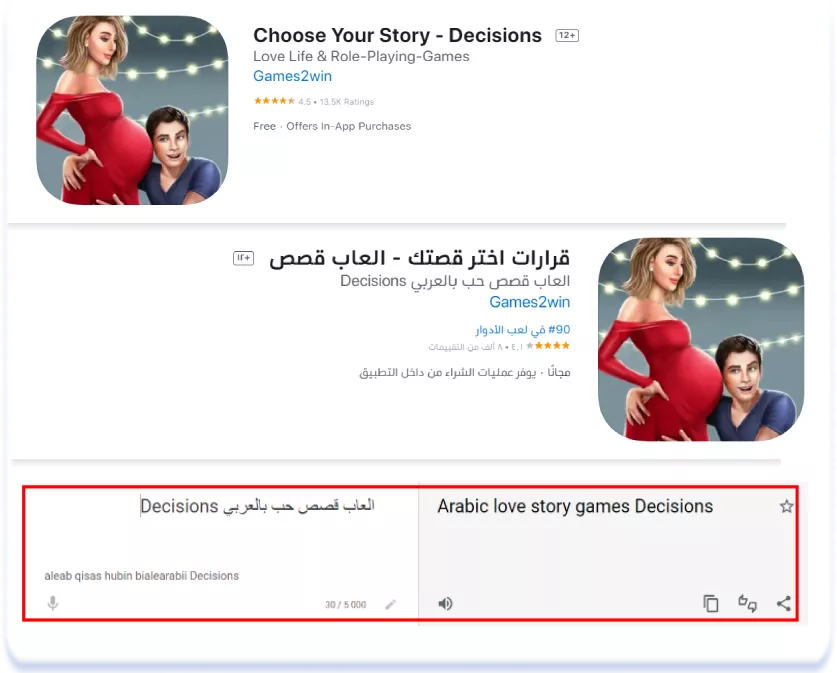
А на прикладі нижче для того, щоб надати додатку ще більш місцевий характер, гра перетворилася на «арабську» історію кохання:
Choose Your Story — Decisions (English [U.S.]) & قرارات اختر قصتك — العاب قصص
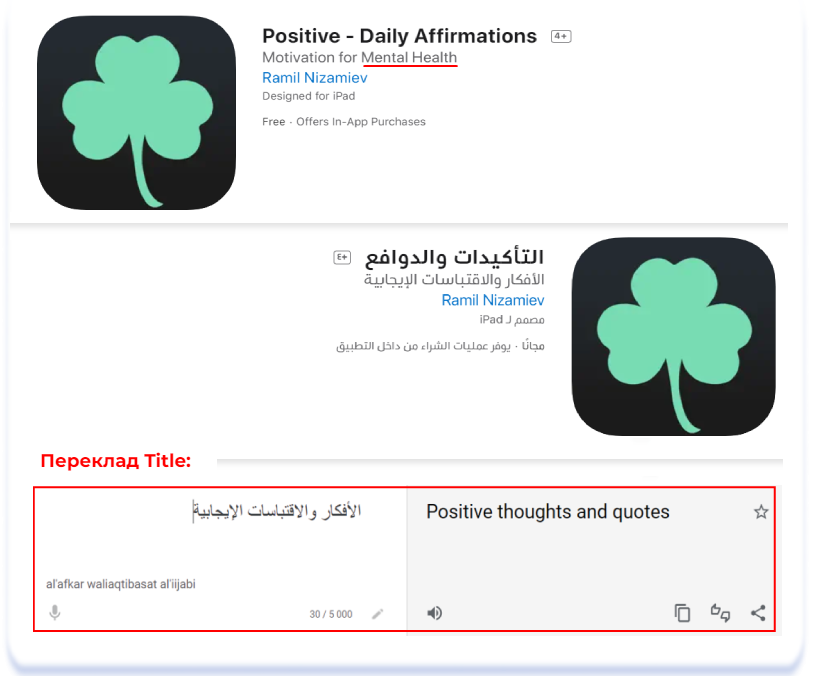
Часом теми, яких необхідно уникати, є неочевидними для людей із західним світоглядом. Наприклад, навколо цілком нешкідливих тем психології, психотерапії та ментальних практик в арабській культурі досі існує табу. Про психічне здоров’я не прийнято говорити, а роль психолога покладена на релігійного діяча чи лікаря. Нижче — приклади того, як при локалізації на арабську були замінені табуйовані в арабській культурі формулювання «ментальне здоров’я», «коучинг», «когнітивно-поведінкова терапія (CBT)» і навіть «медитація»:
Meditopia: Meditation, Sleep (English [U.S.]) & Meditopia — ميدوتوبيا
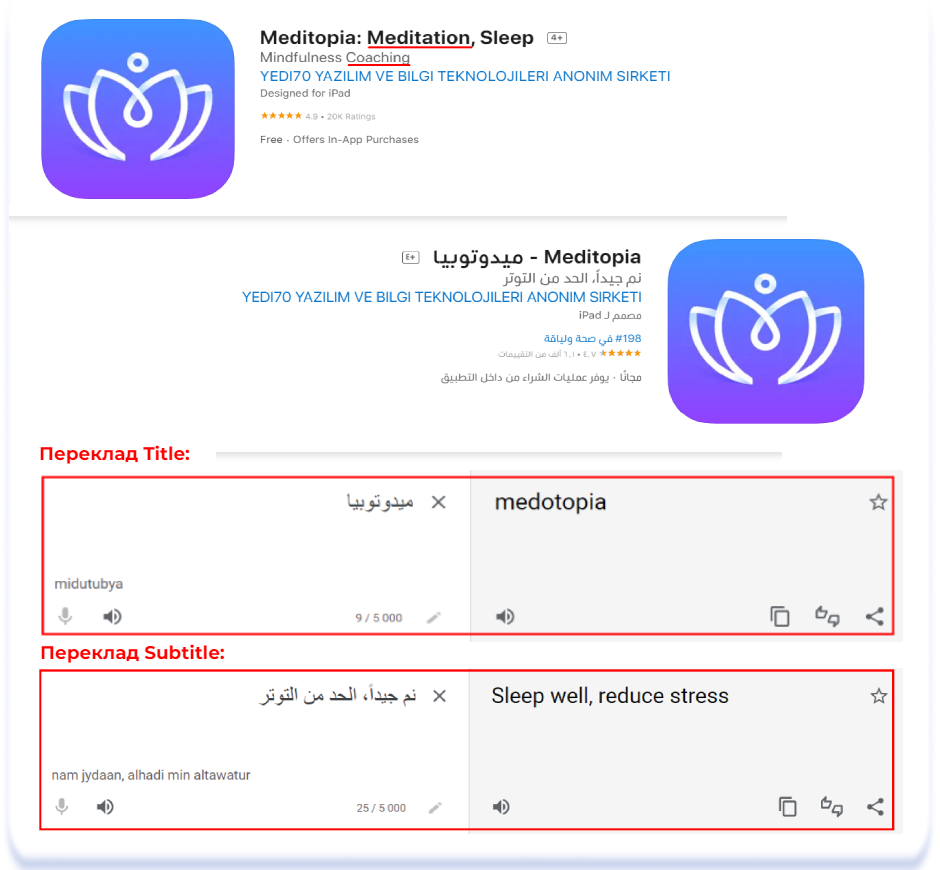
Positive — Daily Affirmations (English [U.S.]) & التأكيدات والدوافع
Moodnotes — Mood Tracker (English [U.S.]) & Moodnotes — مذكرات المزاج
![]()
Світ поступово стає дедалі більш глобалізованим, і кількість табуйованих тем в арабському світі з часом зменшується. Але дотримання у текстових і графічних метаданих культурних особливостей арабських країн, як і раніше, є запорукою успішного просування додатків на їхніх ринках.
На завершення
Важливі пункти, про які необхідно пам’ятати, працюючи над складанням текстових метаданих (рекомендації справедливі в рівній мірі як для App Store, так і для Google Play):
- Починаючи роботу, ознайомтеся з тим, як складені метадані у додатків-конкурентів. Навіть таке швидке мінідослідження допоможе розкрити важливі культурні нюанси локалізації у цільових регіонах.
- Відмінності у культурі, менталітеті і навіть юридичній системі різних країн величезні. Врахувати всі ці особливості під силу лише носію мови, зануреному в культурне середовище своєї країни.
- Використовуйте англійську семантику у видимих текстових метаданих не англомовних країн обережно. Вивчення конкурентів підкаже, як це зробити доречно.
- Регіональні відмінності найпоширеніших світових мов: англійської, французької, іспанської, португальської, китайської та арабської досить великі. Складаючи метадані, використовуйте семантичне ядро, зібране для тієї країни, яка є для вас цільовою. Не забувайте, що в App Store для багатьох з цих мов існує кілька локалей (ми зібрали дані про покриття країн локалями у таблиці).
- Збираючи метадані для різних країн, використовуйте популярні локальні запити місцевими мовами: нижча конкуренція у видачі підвищує шанси зайняти добрі позиції по цим запитам.
І, звичайно, пам’ятайте, що добре локалізована сторінка застосунку — це не тільки грамотно зібрані текстові метадані. Тільки комплексна робота над текстовими та графічними метаданими допоможе отримати хороші позиції додатку у пошуку, високу конверсію в установки та, як наслідок, відмінні фінансові показники.
Читайте також про 10 відмінностей у графіці App Store і Google Play.
Локалізація тексту: Катерина Кальнова, RadASO.

 15
15
 0
0
 13
13
Свіжі
Єдина аналітична система для Yogoda: витрати, продажі та окупність в одному просторі
Видимість реального внеску кожного каналу в дохід ecommerce
Оновлювальний дайджест змін в AI-пошуку
Дайджест головних оновлень AI і їхнього впливу на ринок
Meta (Facebook) Pixel Helper: що це таке і як його налаштувати?
У цій статті детально розгляну, що це за інструмент, принцип його роботи та як за його допомогою перевірити встановлення Pixel і передачу подій із сайту в кабінет Meta