Думаю, всі чули про правило Парето. У будь-якій сфері 20% зусиль дають 80% результату. Наприклад, 20% свого гардеробу ви носите 80% часу, 20% ваших клієнтів приносять 80% прибутку. Так само і в Google Таблицях: знаючи 20% функцій, ви зможете вирішити 80% всіх можливих завдань.
Я вважаю Query однією з наибільш корисних функцій Google Таблиць. Але в довідці Google вона описується дуже поверхово, і всі можливості цієї функції не розкрито. При більш детальному знайомстві зрозуміло, що вона здатна замінити більшу частину функцій.
Для роботи з QUERY вам знадобляться базові знання SQL. Для тих, хто не в темі: лякатися не треба, функція QUERY насправді підтримує найпростіші можливості SQL.
Вебаналітика лежить в основі оптимізації конверсії. Що вам дасть CRO? Дізнайтеся за допомогою калькулятора Netpeak.

Синтаксис QUERY
QUERY(дані; запит; [заголовки])Де:
- дані — діапазон, який буде базою даних для SQL-запиту;
- запит — текст SQL-запиту;
- заголовки — необов'язковий аргумент, у якому ви можете вказати, скільки перших рядків масиву містять заголовки.
Для максимальної зручності пропоную відкрити та скопіювати собі наступну Google Таблицю. Щоб створити копію, відкрийте меню «Файл» та оберіть у ньому пункт «Створити копію».
У Google Docs, копію якого ви щойно створили, існує декілька листів. Лист DB — це база даних, до якої ми будемо звертатися за допомогою функції QUERY. Листи Level містять приклади, які ми розглядатимемо у цій статті. З кожним новим рівнем приклад ускладнюватиметься.
План SQL-запита у функції Query
Будь-який SQL-запит складається з окремих блоків, які часто називають кляузами. У SQL для функції Query закладено синтаксис мови запитів API-візуалізації Google, який підтримує такі кляузи:
- select — перелік полів, які будуть повернені запитом;
- where — містить перелік умов, за допомогою яких буде відфільтровано масив даних, що обробляється запитом;
- group by — містить перелік полів, за якими ви хочете групувати результат;
- pivot — допомагає будувати перехресні таблиці, використовуючи значення одного стовпця як назви стовпців фінальної таблиці;
- order by — відповідає за сортування результатів;
- limit — за допомогою цієї частини запиту ви можете встановити обмеження кількості рядків, що повертаються запитом;
- offset — за допомогою цієї кляузи ви можете задати число перших рядків, які не потрібно опрацьовувати запитом;
- label — ця кляуза відповідає за назву полів, що повертаються запитом;
- format — відповідає за формат даних, що виводяться;
- options — дає можливість ставити додаткові параметри виведення даних.
Hello World для функції Query (Select)
Перейдемо на лист Level_1 і подивимося формулу в клітці A1.
=query(DB!A1:L1143;"select * limit 100")Частина формули «DB!A1:L1143» відповідає за базу даних, з якої ми робитимемо вибірку. Друга частина «select * limit 100» містить безпосередньо текст запиту. Символ «*» у цьому контексті відповідає за повернення усіх полів, що є у базі даних. З допомогою «limit 100» ми обмежуємо вивід даних у 100 рядків максимум. Це приклад найпростішого запиту. Ми обрали 100 перших рядків з бази даних. Це у своєму роді «Hello world» для функції Query.
Використовуємо фільтри та сортування (Where, Order by)
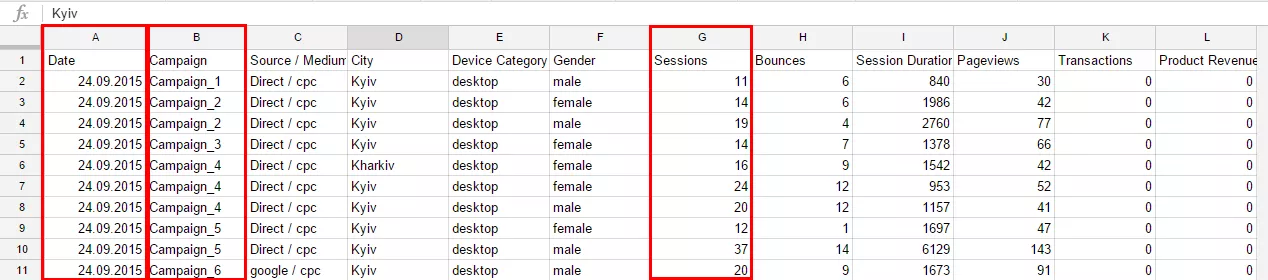
Переходимо на аркуш Level_2. Оберемо лише деякі потрібні нам поля та задамо умови фільтрації та сортування. Наприклад, використовуємо дані лише за кампанією Campaign_1 та Campaign_2 за період 22-25 жовтня 2015 року. Відсортуємо їх у порядку зменшення за сумою сеансів. Для фільтрування та сортування до тексту запиту необхідно додати опис кляуз Where та Order. Для виведення в таблицю описаного вище прикладу нам знадобляться поля Campaign, Date та Sessions. Саме їх і потрібно перерахувати у кляузі Select.
Звернення до полів бази даних здійснюється через назви стовпців робочого аркуша, на якому розташовується база даних.
У нашому випадку дані, розташовані на аркуші DB, та звернення до певних полів прописуються як назва стовпців аркуша. Отже, потрібні поля в наступних стовпцях:
- поле Date — стовпець A;
- поле Campaign — стовпець B;
- поле Sessions — стовпець G.
Відповідно, частина запиту, яка відповідає за перелік даних у результаті, виглядатиме так:
Select A, B, GДалі в запиті йде кляуза Where. При написанні запиту кляузи обов'язково повинні розташовуватись у такому порядку, в якому були описані у першому розділі цієї статті. Після оголошення Where нам необхідно перелічити умови фільтрації.
У цьому випадку ми фільтруємо дані за назвою кампанії (Campaign) та датою (Date). Ми використовуємо декілька умов фільтрації. У тексті запиту між усіма умовами має стояти логічний оператор OR чи AND. Фільтрація за датами трохи відрізняється від фільтрації за числовими та текстовими значеннями, для її застосування необхідно використовувати оператор Date.
Частина запиту, яка відповідає за фільтрацію даних, виглядатиме так:
WHERE(A >= date'2015-10-22'AND A <= date'2015-10-25')AND (B = 'Campaign_1'OR B = 'Campaign_2')Ми розбили за допомогою дужок фільтрацію даних на дві логічні частини: перша фільтрує за датами, друга — за назвою кампанії. На даному етапі формула, що описує дані, які необхідно вибрати, та умови фільтрації даних, виглядає так:
=query(DB!A1:L1143;"Select A, B, GWHERE(A >= date'2015-10-22'AND A <= date'2015-10-25')AND (B = 'Campaign_1'OR B = 'Campaign_2')")Ви можете скопіювати її та вставити, наприклад, на новий аркуш документа, який використовується як приклад у цьому пості, та отримати наступний результат:
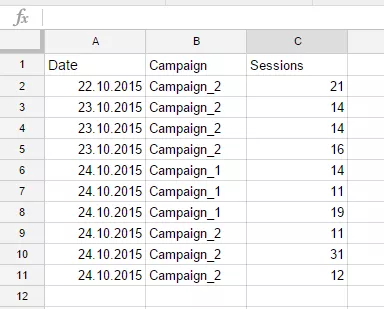
Окрім звичайних логічних операторів (=, <, >), блок WHERE підтримує додаткові оператори фільтрації:
- contains — перевіряє зміст певних символів у рядку. Наприклад, WHERE A contains ‘John’ поверне у фільтр усі значення зі стовпця A, в яких зустрічається John, наприклад, John Adams, Long John Silver;
- starts with — фільтрує значення префіксу, тобто перевіряє символи на початку рядка. Наприклад, starts with ‘en’ поверне значення engineering и english;
- ends with — фільтрує значення після закінчення рядка. Наприклад, рядок ‘cowboy’ повернеться з конструкцією «ends with ‘boy’» або «ends with ‘y’»;
- matches — відповідає регулярному виразу. На кшталт where matches ‘.*ia’ поверне значення India та Nigeria.
- like — спрощена версія регулярних виразів перевіряє відповідність рядка заданому виразу з використанням символів підстановки. На даний момент like підтримує два символи підстановки: «%» позначає будь-яку кількість будь-яких символів у рядку, а «_» — відповідає за будь-який один символ. Наприклад, «where name like ‘fre%’» відповідатиме рядкам ‘fre’, ‘fred’, та ‘freddy’.
Запит вже відфільтрував дані за певний період та залишив лише потрібні нам кампанії. Залишається тільки відсортувати результат за спаданням залежно від кількості сеансів. Сортування в цих запитах здійснюється традиційно для SQL за допомогою кляузи Order by. За синтаксисом вона досить проста: необхідно лише перерахувати поля, за якими потрібно відсортувати результат, а також вказати порядок сортування. За замовчуванням — порядок asc, тобто за зростанням. Якщо вкажете після назви поля параметр desc, запит поверне результат у порядку зменшення зазначених у кляузі Order by полів.
У нашому випадку за фільтрацію відповідатиме рядок у тексті запиту:
Order by G descВідповідно, остаточний результат формули на аркуші Level_2, який вирішує потрібне нам завдання, виглядає так:
=query(DB!A1:L1143;"SELECT A, B, GWHERE(A >= date'2015-10-22'AND A <= date'2015-10-25')AND (B = 'Campaign_1'OR B = 'Campaign_2')ORDER BY G DESC")Тепер ви вмієте за допомогою найпростішого SQL синтаксису та функції QUERY фільтрувати та сортувати дані.
Агрегуючі функції, угруповання даних та перейменування стовпців (Group by, Label)
Переходимо на аркуш Level_3 та ускладнюємо завдання. У запитах ви можете не тільки робити вибірки, а й проводити різні обчислення та агрегації даних. Для цього в SQL функції Query існує ряд функцій, що агрегують, і кляуза Group by. Агрегуючі функції:
| Функція | Опис | Тип даних, що підтримується | Тип даних, що повертається |
| avg() | Повертає середнє значення для групи | Числовий | Числовий |
| count() | Повертає кількість значень у групі | Будь-який | Числовий |
| max() | Повертає максимальне знаення для групи | Будь-який | Аналогічний полю, до якого застосовується |
| min() | Повертає мінімальне значення для групи | Будь-який | Аналогічний полю, до якого застосовується |
| sum() | Повертає суму значень у групі | Числовий | Числовий |
Отже, підрахуємо дані за кожною кампанією:
- середньодобова кількість сеансів;
- максимальна кількість сеансів за добу;
- мінімальна кількість сеансів за добу;
- кількість днів, коли за кампанією було здійснено хоча б один сеанс;
- сума всіх сеансів з кожної кампанії за період.
Для вирішення цього завдання нам знадобляться дані лише з двох полів: Campaign (перебуває у стовпці B) та Sessions (знаходиться у стовпці G). Всі функції, що агрегують, прописуються разом зі списком полів для виведення даних у кляузі Select. У разі застосування функцій, що агрегують, всі поля, до яких не застосовується цей тип функцій, є групуючими полями. Їх необхідно перерахувати у кляузі Group by. Агрегуючі функції працюють обов'язково у парі з Group by. Опис кляузи Select буде наступним:
SELECT B, avg(G), max(G), min(G), count(G), sum(G)Далі необхідно згрупувати дані: у нашому випадку потрібнe групування лише за одним полем Campaign, але ви можете групувати дані за будь-якою кількістю стовпців.
Опис кляузи Group by дуже простий:
GROUP BY BУ кляузі достатньо вказати лише стовпець B, що містить інформацію про назву кампанії. Тому що він єдиний, до якого ми не застосували жодної функції, що агрегує. Наша формула:
=query(DB!A1:L1143;"SELECTB,avg(G),max(G),min(G),count(G),sum(G)GROUP BY B")Отримаємо наступний результат:
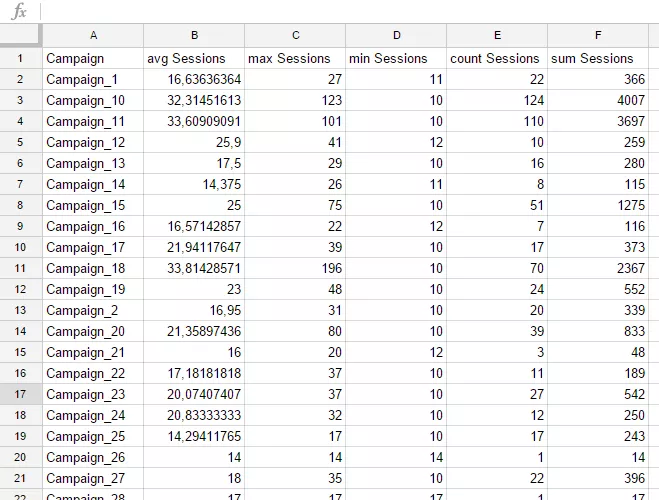
Ми отримали бажаний результат, але назви стовпців можна підкоригувати за допомогою кляузи Label. Результат буде краще, якщо ми відсортуємо звіт за назвою кампанії. Опис кляузи Order by ми вже розглянули вище.
Для потрібного сортування достатньо додати наступний рядок після опису:
Order by BЩоб перейменувати стовпці в таблиці, яку повертає запит, необхідно додати опис кляузи Label. Синтаксис досить простий: спочатку вказуєте стовпець, що виводиться, або функцію, яка повертатиме значення в таблицю, і далі в одинарних лапках вказуєте потрібну назву.
Це виглядатиме так:
LABEL B ‘Кампанія’, avg(G) ‘Середня’, max(G) ‘Максимальна’, min(G) ‘Мінімальна’, count(G) ‘Кіклькість’, sum(G) ‘Загальна сума’Нова формула:
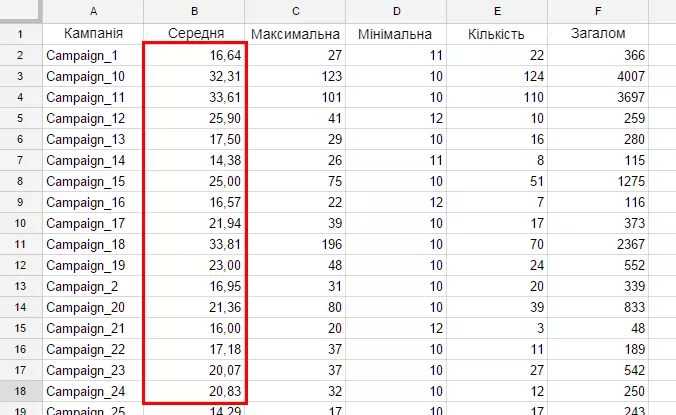
=query(DB!A1:L1143;"SELECT B, avg(G), max(G), min(G), count(G), sum(G)GROUP BY BORDER BY BLABEL B 'Кампанія', avg(G) 'Середня', max(G) 'Максимальна', min(G) 'Мінімальна', count(G) 'Кількість', sum(G) 'Загальна сума'")А результат, який поверне формула, виглядатиме так:
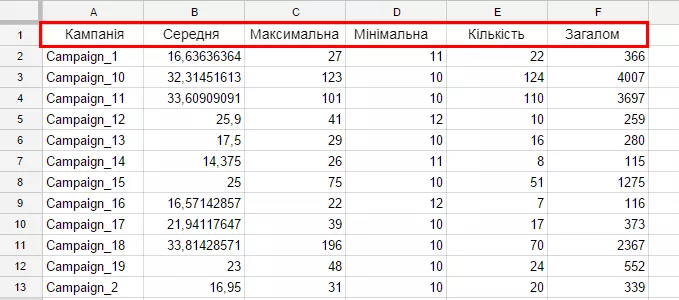
Всі поля променовані відповідним чином згідно з описом кляузи Label. Останнє, що ріже око у таблиці, що повертається, — формат, в якому виводяться дані в стовпці «Середня». Для коригування форматів, що виводяться запитом даних, потрібно описати кляузу Format. Її опис схожий з описом Label, але замість назви поля потрібно прописати маску демонстрації даних (також у одинарних лапках).
Округлимо числа у стовпці «Середня» до двох знаків після коми. Для округлення даних до двох знаків після коми маска повинна виглядати як ‘0.00’.
Опис кляузи Format
FORMAT avg(G) ‘0.00’Відповідно, остаточна формула на аркуші Level_3 виглядатиме так:
=query(DB!A1:L1143;"SELECT B, avg(G), max(G), min(G), count(G), sum(G)GROUP BY BORDER BY BLABEL B 'Кампания', avg(G) 'Среднее', max(G) 'Максимальное', min(G) 'Минимальное', count(G) 'Количество', sum(G) 'Общая сумма'FORMAT avg(G) '0.00'")В результаті:
Створення перехресних таблиць (Pivot, скалярні функції)
Щоб за лічені секунди за допомогою функції QUERY створити перехресну таблицю, слід додати у запит опис кляузи Pivot. Побудуємо звіт, у якому в рядках буде номер дня тижня, у стовпцях — тип пристрою, а як значення, що виводяться, розрахуємо показник відмов. Якщо ви уважно вивчили структуру бази даних, що знаходиться на аркуші DB, то, напевно, помітили, що у нас немає поля з інформацією про день тижня, як і поля, що містить інформацію про показник відмов.
Щоб обчислити день тижня, доведеться скористатися однією з багатьох скалярних функцій. У нашій базі є необхідна інформація для розрахунку показника відмов. Далі досить просто застосувати арифметичний оператор «Ділення».
Скалярні функції
На момент написанния статті SQL в Google Таблицях підтримує 14 скалярних функцій.
| Функція | Опис |
| year() | Повертає рік з «дати» або «дати і часу». Приклад: year(date ‘2009-02-05’) поверне 2009. Необхідні параметри: один параметр з типом дати або дати і часу. Тип даних, що повертаються: число. |
| month() | Повертає номер місяця з «дати» або «дати і часу». Але у цьому випадку січень повертатиме 0, лютий — 1 і так далі. Початком відліку для номера місяця є 0. Приклад: month(date ‘2009-02-05’) поверне 1. Щоб функція повернула номер місяця у звичному вигляді, додайте до результату 1, month(date "2009-02-05")+1 поверне 2. Необхідні параметри: один параметр з типом дата чи дата і час. Тип даних, що повертаються: число. |
| day() | Повертає номер дня у місяці з «дати» або «дати і часу». Приклад: day(date ‘2009-02-05’) поверне 5. Необхідні дані: один параметр з типом дати або дати і часу. Тип даних, що повертаються: число. |
| hour() | Повертає номер години дня з «дати та часу» або «часу». Приклад: hour(timeofday ‘12:03:17') поверне 12. Необхідні параметри: один параметр з типом часу або дати і часу. Тип даних, що повертаються: число. |
| minute() | Повертає номер хвилини у годині з «дати та часу» або «часу». Приклад: minute(timeofday ‘12:03:17') поверне 3. Необхідні параметри: один параметр з типом часу або дати і часу. Тип даних, що повертаються: число. |
| second() | Повертає номер секунди у хвилині з «дати та часу» або «часу». Приклад: second(timeofday ‘12:03:17') поверне 17. Необхідні параметри: один параметр з типом часу або дати та часу. Тип даних, що повертаються: число. |
| millisecond() | Повертає номер мілісекунди у секунді з «дати та часу» або «часу». Приклад: millisecond(timeofday ‘12:03:17.123') поверне 123. Необхідні параметри: один параметр з типом часу або дати та часу. Тип даних, що повертаються: число. |
| quarter() | Повертає номер кварталу у році з «дати та часу» або «часу». Базовим значенням або початком відліку є 1, відповідно, для першого кварталу функція поверне значення 1, для другого 2 і так далі. Приклад: quarter(date ‘2009-02-05’) поверне 1. Необхідні параметри: один параметр з типом дати або дати та часу. Тип даних, що повертаються: число. |
| dayOfWeek() | Повертає номер дня тижня у тижні з «дати» або «дати та часу». Початком тижня вважається неділя, для неділі функція поверне значення 1, для понеділка 2 і так далі. Приклад: dayOfWeek(date ‘2015-11-10’) поверне 3, бо 10 листопада 2015 року — вівторок. Необхідні параметри: один параметр з типом дати або дати та часу. Тип даних, що повертається: число. |
| now() | Повертає поточну дату і час у часовому поясі GTM. Необхідні параметри: не потрібні. Тип даних, що повертаються: дата і час. |
| dateDiff() | Повертає різницю у днях між двома датами. Приклад: dateDiff(date ‘2008-03-13’ , date ‘2008-02-12’) поверне 29, бо 10 листопада 2015 року вівторок. Необхідні параметри: два параметри з типом «дата» або «дата і час». Тип даних, що повертаються: число. |
| toDate | Повертає перетворене у дату значення з «дати» або «дати і часу» чи «числа». Приклад:
|
| upper() | Перетворює всі значення у рядку на верхній регістр. Приклад: upper( ‘foo') поверне рядок ‘FOO’. Необхідні параметри: один параметр з текстовим типом даних. Тип даних, що повертаються: текст. |
| lower() | Перетворює всі значення у рядку на нижній регістр. Приклад: upper( ‘Bar') поверне рядок ‘bar’. Необхідні параметри: один параметр з текстовим типом даних. Тип даних, що повертаються: текст. |
Арифметичні оператори
| Оператор | Опис |
| + | Складання кількох числових значень |
| - | Різниця між числовими значеннями |
| / | Розподіл числових значень |
| * | Множення числових значень |
Для вирішення нашого завдання потрібно використовувати скалярну функцію dayOfWeek для обчислення дня тижня, а також арифметичний оператор «/» для підрахунку показника відмов.
Визначимо поля, які використовуватимемо у запиті:
- Для обчислення дня тижня нам знадобляться дані поля Date у стовпці A.
- Дані про типи пристроїв зберігаються у полі Device category у стовпці E.
- Для розрахунку показника відмов потрібні дані полів Bounces та Sessions — в стовпцях H і G.
Опишемо кляузу Select для нашого запиту. Оскільки в рядках ми матимемо дані за днями тижня, нам достатньо прописати скалярну функцію, яка обчислюватиме день тижня, а також формулу обчислення показника відмов.
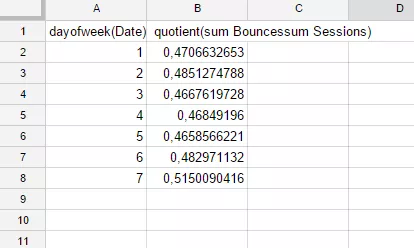
SELECT dayOfWeek(A), sum(H)/sum(G)Саме так виглядатиме опис потрібних нам полів. Тепер за допомогою кляузи Group by згрупуємо рядки за днями тижня. Для цього допишемо в запит наступний рядок:
GROUP BY dayOfWeek(A)Вже бачимо, як змінюється показник відмов у залежності від дня тижня:
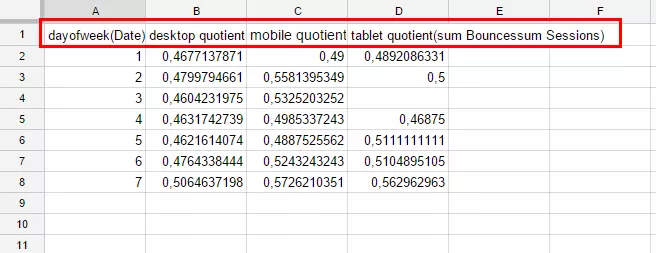
Щоб побудувати перехресну таблицю, достатньо прописати кляузу Pivot із зазначенням стовпця, значення з якого будуть додані. У нашому випадку це стовпець E, тому що саме він містить інформацію про тип пристроїв. Дописуємо рядок:
PIVOT EТепер запит повертає результат:
Нам залишається лише додати останні штрихи: змінити назви стовпців та формат чисел за допомогою пунктів LABEL та FORMAT. Остаточна формула на аркуші Level_4:
=query(DB!A1:L1143;"SELECT dayOfWeek(A), sum(H)/sum(G)GROUP BY dayOfWeek(A)PIVOT ELABELdayOfWeek(A) 'День недели',sum(H)/sum(G) ''FORMAT sum(H)/sum(G) '0.00%'")Отримуємо звіт:
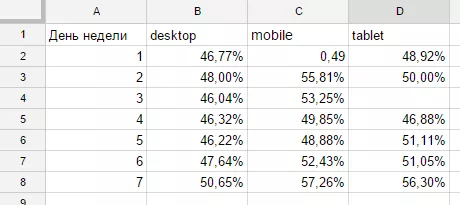
Рядком LABEL sum(H)/sum(G) ‘’ ми прибрали з підписів стовпця напис, що містить формулу розрахунку. Рядком FORMAT sum(H)/sum(G) ‘0.00%’ ми передали процентний формат показнику відмов у звіті. Загалом описаного в прикладах вище синтаксису цілком достатньо, щоб почати активно використовувати функцію QUERY, але далі хочу показати ще кілька цікавих прийомів, які можна взяти на озброєння.
Імпорт даних за допомоги QUERY з іншої Google Таблиці
За допомоги QUERY ви можете використовувати як базу даних іншу Google Таблицю. Це можна зробити за допомги поєднання функцій ImportRange та QUERY. Я створив нову Google Таблицю, в яку продублював дані з листа DB з приведеного на початку статті документу. Щоб у якості бази даних використовувати дані з іншої таблиці Google, як перший аргумент функції Query виступить імпортований функцією ImportRange діапазон.
Різниця в тому, що при написанні запиту до даних, що імпортуються функцією ImportRange, замість назви стовпців ми вказуємо їхній порядковий номер у діапазоні, що повертається функцією ImportRange. На аркуші DataImport перепишемо запит, поданий у Level_4 так, щоб він звертався до даних, у новій таблиці на аркуші DB_Transfer. Синтаксис функції ImportRange достатньо простий:
IMPORTRANGE(ключ, диапазон)Де ключ — частина URL Google Таблиці:

А діапазон — лінк на аркуш та діапазон. У нашому випадку діапазоном буде DB_Transfer!A1:L1143. Формула ImportRange:
importrange(“1aBytZCYsZF0-3RozYviSrMqVLtqtb49yxY9KBgT4pVo”;”DB_Transfer!A1:L1143”)Саме її ми повинні вказати як дані функції Query. Далі залишається переписати запит так, щоб посилатися на стовпці бази даних не за назвою, а за порядковим номером. Визначимо, до яких стовпців ми зверталися за допомогою запиту на аркуші Level_4.
| Назва | Зміст | Ім’я у таблиці | Порядковий номер |
| Date | Дата | A | 1 |
| Device type | Тип пристрою | E | 5 |
| Sessions | Кількість сеансів | G | 7 |
| Bounces | Кількість відмов | H | 8 |

Текст запиту після заміни назв стовпців на їхній порядковий номер:
SELECT dayOfWeek(Col1), sum(Col8)/sum(Col7)GROUP BY dayOfWeek(Col1)PIVOT Col5LABEL dayOfWeek(Col1) 'День недели', sum(Col8)/sum(Col7) ''FORMAT sum(Col8)/sum(Col7) '0.00%'Як бачите, текст запиту практично не змінився, але замість стовпця A ми тепер вказуємо Col1, замість стовпця E — Col5, замість G — Col7 і замість H, відповідно, Col8. Отримуємо формулу:
=query(IMPORTRANGE("1aBytZCYsZF0-3RozYviSrMqVLtqtb49yxY9KBgT4pVo";"DB_Transfer!A1:L1143");"SELECT dayOfWeek(Col1), sum(Col8)/sum(Col7)GROUP BY dayOfWeek(Col1)PIVOT Col5LABEL dayOfWeek(Col1) 'День недели', sum(Col8)/sum(Col7) ''FORMAT sum(Col8)/sum(Col7) '0.00%'")В якості першого аргументу функції Query виступає функція ImportRange з посиланням на ключ потрібної таблиці Google, яку ви можете скопіювати з URL Google Таблиці, і посилання на діапазон, що включає назву аркуша, а також першого і останнього осередку потрібного діапазону.
Номера стовпців в запиті йдуть не зі стовпця A, а з того, який йде першим у вказаному діапазоні в функції ImportRange. Наприклад, якщо б у якості діапазона, що імпортується, виступає DB_Transfer!C1:L1143, то дані з стовпця C запитуються лінком Col1, бо в масиві, що імпортується, цей стовпець — перший.
Остаточну формулу можна подивитися на аркуші DataImport.
Створюємо запит на основі об’єднання даних із кількох таблиць з однаковою структурою
Ще одна досить потужна можливість функції QUERY — побудова запиту на основі декількох масивів даних. Єдиною умовою для об’єднання даних є однакова структура вхідних таблиць. Принцип об’єднання вхідних даних: перший аргумент функції QUERY може приймати або посилання на діапазон, або опис масиву.
Масив — це віртуальна таблиця, яка містить рядки та стовпці.
Масив завжди описується всередині фігурних дужок, при цьому необхідно дотримуватись наступної пунктуації:
- зворотня скісна риска «\» — розділяє стовпці. Наприклад, {1 \ A}. Число 1 знаходитиметься у верхній лівій клітці масиву, літера «A» в клітці справа. Так ми описали діапазон, який містить два стовпці та один рядок.
- крапка з комою «;» використовуэться для переходу на наступний рядок. Візьмемо {1;A}. Цей масив складатиметься з одного стовпця та двох рядків, у першому рядку міститься значення 1, у другому — літера «A».
Так ви можете два і більше діапазони описати в одному масиві, наприклад:
=query({Table1!A1:B5; Table2!A1:B5; Table3!A1:B5};"SELECT * WHERE Col2 > 4")У цьому випадку ми звертаємось із запитом до трьох діапазонів даних, що знаходяться на різних аркушах, об’єднавши масив за допомогою «;» так, що друга таблиця стає продовженням першої, а третя таблиця — продовженням другої. Дивіться приклад за посиланням.
Запит з динамічними параметрами
Синтаксис запитів функції QUERY складний для непідготовленого користувача. Тому ви можете додати на робочий лист різні інтерактивні елементи у вигляді списку, створеного за допомогою функції «Перевірка даних». А в тексті запиту — зробити посилання на клітки з потрібними даними. Наприклад, ми можемо динамічно задати діапазон дат, який хочемо вивести в динамічну таблицю, або зробити можливість динамічно додавати та прибирати різні поля фінальної таблиці. Подивитися, як це виглядає, можете на аркуші DinamicQuery.
Ви можете змінити всі поля, зафарбовані зеленим кольором, і таким чином обрати діапазон дат, що цікавить, ввести зручні для вас назви полів, а також позначити, які з п’яти запропонованих полів потрібно вивести до звіту.
При використанні даного конструктора звіту для відображення обов’язково має бути обраний хоча б один параметр та один вимір.
Вкажіть інтервал дат, що цікавить вас, в межах від 24.09.2015 по 25.10.2015, оскільки дані, які згенеровані для тестової бази і зберігаються на аркуші DB, містять тільки цей діапазон. Далі в конструкторі звітів ви можете змінити назви полів і вони відображатимуться у фінальній таблиці. Також можете вказати, які поля потрібно візуалізувати у звіті. Ще раз нагадаю, що необхідно вказати як мінімум один параметр та один вимір. Під час зміни будь-яких параметрів звіт під конструктором динамічно змінюватиметься.
Формула, яка змінює запит у залежності від налаштованих параметрів, виглядає так:
=query(DB!A1:L1143;"Select "&join(",";filter(C7:C11;B7:B11="Да"))&"WHERE(A >= date'"&C2&"-"&D2&"-"&E2&"'AND A <= date'"&C3&"-"&D3&"-"&E3&"')GROUP BY "&join(",";filter(C7:C11;B7:B11="Да";D7:D11="Измерение"))&"LABEL "&join(",";filter(E7:E11;B7:B11="Да")))Насправді функція Query може розростатися до розмірів програми і динамічно змінювати інформацію, що виводиться залежно від зазначених на робочому аркуші даних.
Сподіваюся, мені вдалося пояснити, як користуватися однією з найскладніших і в той же час корисних функцій Google Таблиць. Якщо хочете познайомитися з усіма можливостями Таблиць Google, рекомендую звернути увагу на курс «Google Sheets» від Choice31: він буде корисний проджектам, маркетологам, фінансовим аналітикам та всім, хто давно збирався розібратися в цьому інструменті.

 43
43
 2
2
 39
39
Більше за темою
Як передача конверсій із CRM у рекламні кабінети допомагає покращити performance-рекламу
Олександр Конівненко розповідає, як передача конверсій із CRM у Google Ads і Meta допомагає покращити якість сигналів і масштабувати performance-рекламу
Як об’єднати дані з Meta, TikTok, Google Ads і DV360 в одному звіті: кейс із медійної аналітики
Об'єднали дані з чотирьох систем в єдиний простір, автоматизували звітність і побудували коректний підхід до розрахунку охоплення та частоти показів
Свіжі
Зростання продажів магазину інженерного обладнання в Німеччині на 77%: кейс Shopping-Kobolde
Просування технічного ecommerce з обмеженою CMS і потребою конкурувати за органічний трафік із маркетплейсами
Медичне SEO в епоху AI Overviews: як клінікам, лабораторіям і аптекам адаптувати сайт
Медичним сайтам недостатньо працювати тільки над позиціями, адже тепер між запитом і кліком часто з’являється AI-відповідь
Google Ads Editor: 7 помилок новачків і як їх уникнути
Найпоширеніші помилки, їх причини і шляхи вирішення